纠结这个问题很久了,期间主要去了gensim的google论坛,以及在StackOverflow、StackexChange用关键词topic number perplexity搜了下,得到这些很模糊的认识:
1. gensim的log_perplexity()解读:
根据gensim3.8.3的源码,log_perplexity()输出的是perwordbound,perwordbound计算步骤如下:
先调用bound(),通过一个chunk的语料W ⃗ \vec{W}W计算整个语料库的对数似然值l o g p ( W ⃗ ) logp(\vec{W})logp(W)的下界,即E q [ l o g p ( W ⃗ ) ] − E q [ l o g q ( W ⃗ ) ] Eq[logp(\vec{W})]-Eq[logq(\vec{W})]Eq[logp(W)]−Eq[logq(W)] 。
然后用l o g p ( W ⃗ ) logp(\vec{W})logp(W)的bound除以整个语料库的大小N,得出perwordbound,作为log_perplexity()的返回值。
调用函数期间还会将2 − p e r w o r d b o u n d 2^{-perwordbound}2−perwordbound 作为perplexity打印输出,这个perplexity以2为底数,与:
D. Blei, A. Ng, and M. Jordan. Latent Dirichlet allocation. Journal of Machine Learning Research,3:993–1022, January 2003
Hoffman, Blei, Bach: Online Learning for Latent Dirichlet Allocation, NIPS 2010.
这两篇论文定义的以e为底数的perplexity有所差别,但思想基本一致。
这里的问答也有类似说明:
https://stats.stackexchange.com/questions/322809/inferring-the-number-of-topics-for-gensims-lda-perplexity-cm-aic-and-bic?r=SearchResults
2. 关于困惑度和主题数之间关系的解读:
首先,log_perplexity()这个函数没有对主题数目做归一化,因此不同的topic数目不能直接比较:
传送门:https://groups.google.com/g/gensim/c/krs1Uytq5bY/m/ePZXIKfwGwAJ
其次,gensim包的作者Radim现身回答说perplexity不是一个好的评价topic质量的指标: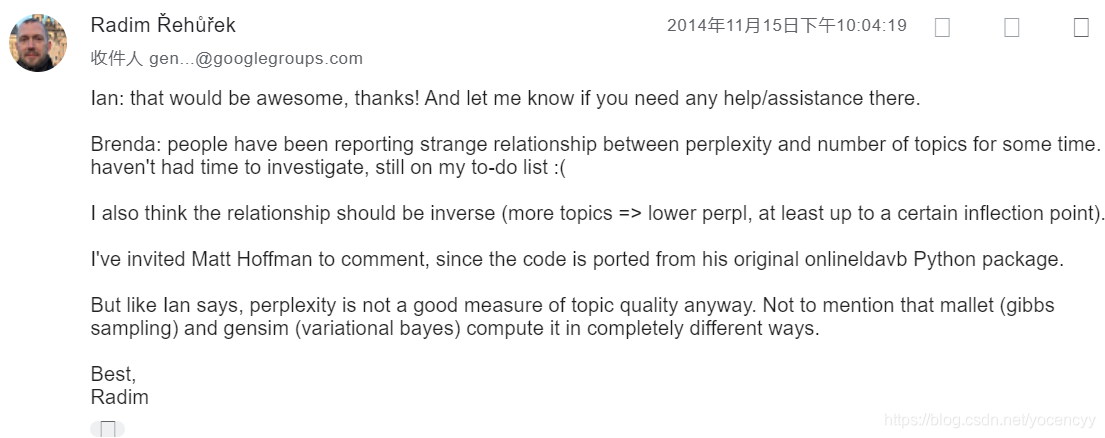
传送门:https://groups.google.com/g/gensim/c/TpuYRxhyIOc