这里了解一下libevent中使用的队列 TAILQ
参考博客: http://blog.csdn.net/luotuo44/article/details/38374009
以下是队列使用的两个结构体:头节点和节点
//虽然官方给了注释,但是之前看的时候愣是没看懂,看了他人博客才清楚
//节点中的tgh_last并不是指最后一个节点,而是指最后一个节点的next元素地址
//还要注意的是tgh_last是二级指针
#define TAILQ_HEAD(name,type) \
struct name { \
structtype *tqh_first; /* first element */ \
structtype **tqh_last; /* addr of last nextelement */ \
}//关于节点中的tge_prev,并不是指前一个节点,不是与next相对的
//tge_prev指的是前一个节点的next元素地址
#define TAILQ_ENTRY(type) \
struct { \
structtype *tqe_next; /* next element */ \
structtype **tqe_prev; /* address of previousnext element */ \
}可以看出来的是,下面是匿名结构体
该类型结构体一般是作为另一个结构体或是联合体的成员出现
队列的具体结构看这两个结构体虽然能看出些端倪,但不如让我们深入观察,看清这个结构体是如何操作的
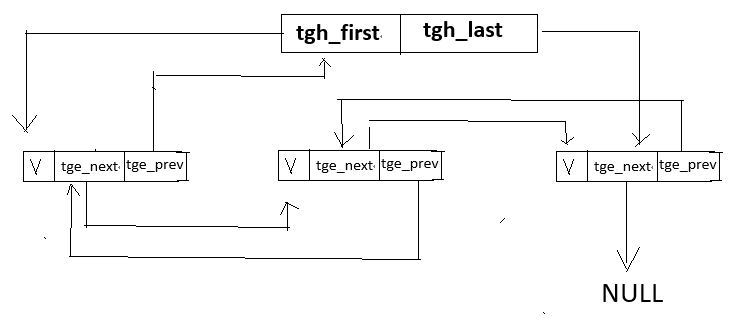
所以接下来对几个关键/难懂的操作进行一一解释
首先,让我们看看插入操作的源代码:
#define TAILQ_INSERT_TAIL(head, elm, field) do{ \
(elm)->field.tqe_next = NULL; \
(elm)->field.tqe_prev = (head)->tqh_last; \
*(head)->tqh_last = (elm); \
(head)->tqh_last = &(elm)->field.tqe_next; \
}while (0)
很明显,宏读起来并不容易
想要理解插入操作是如何进行的,我们先来看看是如何使用这个函数的:
#include"queue.h"
#include<malloc.h>
#include<stdio.h>
//声明节点类型
structitem_t
{
int value;
TAILQ_ENTRY(item_t) entry;
};
//声明头节点
TAILQ_HEAD(item_h,item_t);
intmain()
{
struct item_h queue_head;
struct item_t *node;
//初始化头节点
TAILQ_INIT(&queue_head);
//插入几个节点
int i;
for(i=0; i<4; i++)
{
node = (struct item_t*)malloc(sizeof(struct item_t));
node->value = i;
TAILQ_INSERT_TAIL(&queue_head, node, entry);
}
//逐个访问
TAILQ_FOREACH(node, &queue_head, entry)
{
printf("the value is %d\n",node->value);
}
return 0;
}这里是简单的使用TAILQ,主要操作是声明头节点,以及插入3个元素
知道怎么操作后,我们仔细的看看代码,一大堆宏并不是那么好看,于是我们使用gcc的预编译功能gcc -E,展开所有宏得到如下内容:
其中省略了很多不需要的内容:
struct item_t
{
int value;
struct {
struct item_t *tqe_next;
struct item_t **tqe_prev;
} entry;
};
structitem_h {
struct item_t *tqh_first;
struct item_t **tqh_last;
};
intmain()
{
struct item_h queue_head;
struct item_t *node;
do {
//头节点的初始化
(&queue_head)->tqh_first = ((void *)0);
//last的定义是存最后一个元素的next指针的地址的,而first是指向第一个元素的
//现在没有元素那么last只能存指向first元素的指针的指针
(&queue_head)->tqh_last = &(&queue_head)->tqh_first;
} while (0);
int i;
for(i=0; i<4; i++)
{
node = (struct item_t*)malloc(sizeof(struct item_t));
node->value = i;
do {
//根据我们之前对此数据结构的理解,我们通过查看源代码来验证我们的判断是否是正确的
//既然此函数是插入元素在队列尾部,那么当前节点的next初始化为null
(node)->entry.tqe_next = ((void *)0);
//当前节点的前一个节点是之前队列的尾部元素,又根据我们对tqe_prev的含义的理解,其等于前一个节点的next;
//再根据我们对tqh_last的理解,tqh_last就是指向最后一个节点的next的,所以直接令当前节点的prev就等于头节点的last
(node)->entry.tqe_prev = (&queue_head)->tqh_last;
//因为last是二级指针,存的是最后一个元素的next指针的地址,为一层解引用赋值表示为原来队列最后一个元素的next赋值
*(&queue_head)->tqh_last = (node);
//调整完元素之间的关系后,改变头节点的last元素指向,现在存新节点的next指针的地址
(&queue_head)->tqh_last = &(node)->entry.tqe_next;
} while (0);
}
for((node) = ((&queue_head)->tqh_first); (node) != ((void *)0); (node) =((node)->entry.tqe_next))
{
printf("the value is %d\n",node->value);
}
return 0;
}
看完了具体的插入尾部是如何进行的,我们再简略的看看插入在头部是如何进行的,在了解了尾部插入操作后再来看这个操作,我想应该容易很多
首先贴上源代码:
#defineTAILQ_INSERT_HEAD(head, elm, field) do { \
if (((elm)->field.tqe_next = (head)->tqh_first) !=NULL) \
(head)->tqh_first->field.tqe_prev = \
&(elm)->field.tqe_next; \
else \
(head)->tqh_last =&(elm)->field.tqe_next; \
(head)->tqh_first = (elm); \
(elm)->field.tqe_prev = &(head)->tqh_first; \
}while (0)然后看看进行预编译后的内容:
do {
//首先我们肯定是令当前节点的next等于原来队列的首节点
if (((node)->entry.tqe_next = (&queue_head)->tqh_first) != ((void*)0))
//如果之前队列不为空,那么我们就需要处理原来队列首节点的prev部分,令它存当前节点的next指针的地址
(&queue_head)->tqh_first->entry.tqe_prev =&(node)->entry.tqe_next;
//如果队列本来是空的,那么表明在插入第一个元素时last元素也需要处理
else
(&queue_head)->tqh_last = &(node)->entry.tqe_next;
//令first指向当前节点
(&queue_head)->tqh_first = (node);
//处理当前节点的prev部分,因为是首节点,所以是存头节点的first指针的地址
//为什么我们会这样处理呢?并不是因为勉强处理,而是因为当我们把节点的value部分忽略后,节点与头节点是类似的,甚至可以相互转化
//这个思想将在下面解释清楚
(node)->entry.tqe_prev = &(&queue_head)->tqh_first;
}while(0);其他插入、删除操作就不再一一讲解了,因为思路搞明白了,除了技巧,其他并不需要多说明了
所以,下面我们看看两个比较难搞明白的函数:
#define TAILQ_LAST(head,headname) \
(*(((struct headname *)((head)->tqh_last))->tqh_last))仔细回顾队列的实现过程,我们发现,好像并没有准确的指向最后一个节点的指针或者元素,唯一有点关联的last却是存最后一个元素的next指针的地址的
当然,我们可以从头走到尾,最后返回队列的最后一个元素,但那样就失去了效率了
所以我们来理解一下这个函数的宏
//参数不过多考虑,这样传是因为是通过宏实现导致的,传入的是头节点,头节点类型的名字
(*(((struct headname *)((head)->tqh_last))->tqh_last))
//通过一层剥离可发现:
//是对
(((struct headname *)((head)->tqh_last))->tqh_last)
//解引用
//是对
(struct headname *)((head)->tqh_last)
//求tqh_last
//是对
(head)->tqh_last
//进行强制类型转换

而(head)->tqh_last存的是什么呢?存的是最后一个队列元素的next指针的地址,于是我们可以想象现在握着一根针,指向最后一个队列元素结构体的next项,虽然next是指针,但是next也是需要内存的,此时next内存中可能存着另一个队列元素的地址(说是可能,因为此结构体是最后一个队列元素,所以现在是空的)。
好了,现在我们有了next项的地址。往上推进,要对next的地址之后的一段内容进行强制转换。
在插入首节点的函数中,我们说过,头节点和节点之间若去除了value项那么是类似的,可以进行互相的强制转换。此刻进行的强制转换后,编译器把next地址和之后的一段内存认为是头节点类型
再向上推进,现在我们拥有了一个强制转换得到的头节点类型,它的first部分是原来节点的next部分,last部分则是原来节点的prev部分。求此结构体的last,表明求原来结构体的prev,而原来结构体的prev存的又是当前元素的前一个元素的next指针的地址
于是我们得到的前一个元素中next指针的地址,又因为前一个元素的next是指向现在讨论这个节点的,所以解引用后得到的就是我们现在讨论的节点的地址,也就是队列最后一个元素的地址
有了上面的基础,接下来再看另一个难懂的函数,其原理与上面类似:
#define TAILQ_PREV(elm, headname,field) \
(*(((struct headname *)((elm)->field.tqe_prev))->tqh_last))对
(*(((struct headname *)((elm)->field.tqe_prev))->tqh_last))
进行剥离后得到:
要对((elm)->field.tqe_prev)进行强制转换

而((elm)->field.tqe_prev)存的是前一个节点的next指针的地址,与上面的技巧基本一致
然后next元素地址之后的部分强制转换成为头节点类型
然后通过调用头节点中的last元素,相当与前一个节点中的prev元素,得到【前一个节点的前一个节点的next指针的地址】
最后通过解引用【前一个节点的前一个节点的next指针的地址】得到前一个【前一个节点的前一个节点的next指针中的值】,也就是【前一个节点的地址】
最后,回到libevent中,将来对于这个数据结构的运用,应该与我们的例子类似,比如在event-internal.h中的event_config定义:
struct event_config_entry {
TAILQ_ENTRY(event_config_entry) next;
const char *avoid_method;
};
structevent_config {
TAILQ_HEAD(event_configq, event_config_entry) entries;
int n_cpus_hint;
enum event_method_feature require_features;
enum event_base_config_flag flags;
};
现在,我们该对TAILQ有了更深入的了解了吧?
还是很感激文章开始处的博文的博主!