System.out.println("toLower : " + str);
}
public int toInt(String str){
System.out.println("toInt : " + str);
return 1;
}
}
复制代码
用::提取的函数,最主要的区别在于静态与非静态方法,非静态方法比静态方法多一个参数,就是被调用的实例。
// 使用双冒号::来构造非静态函数引用
String content = “Hello JDK8”;
// public String substring(int beginIndex)
// 写法一: 对象::非静态方法
Function<Integer, String> func = content::substring;
String result = func.apply(1);
System.out.println(result);
// 写法二:
IntFunction intFunc = content::substring;
result = intFunc.apply(1);
System.out.println(result);
// 写法三: String::非静态方法
BiFunction<String,Integer,String> lala = String::substri
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
ng;
String s = lala.apply(content, 1);
System.out.println(s);
// public String toUpperCase()
// 写法一: 函数引用也是一种函数式接口,所以也可以将函数引用作为方法的参数
Function<String, String> func2 = String::toUpperCase;
result = func2.apply(“lalala”);
System.out.println(result);
// 写法二: 可以改写成Supplier: 入参void, 返回值String
Supplier supplier = “alalal”::toUpperCase;
result = supplier.get();
System.out.println(result);
复制代码
数组引用
// 传统Lambda实现
IntFunction<int[]> function = (i) -> new int[i];
int[] apply = function.apply(5);
System.out.println(apply.length); // 5
// 数组类型引用实现
function = int[]::new;
apply = function.apply(10);
System.out.println(apply.length); // 10
复制代码
Optional的用法
c static void main(String[] args) {
// Optional类已经成为Java 8类库的一部分,在Guava中早就有了,可能Oracle是直接拿来使用了
// Optional用来解决空指针异常,使代码更加严谨,防止因为空指针NullPointerException对代码造成影响
String msg = “hello”;
Optional optional = Optional.of(msg);
// 判断是否有值,不为空
boolean present = optional.isPresent();
// 如果有值,则返回值,如果等于空则抛异常
String value = optional.get();
// 如果为空,返回else指定的值
String hi = optional.orElse(“hi”);
// 如果值不为空,就执行Lambda表达式
optional.ifPresent(opt -> System.out.println(opt));
复制代码
Stream的一些操作
有些Stream可以转成集合,比如前面提到toList,生成了java.util.List 类的实例。当然了,还有还有toSet和toCollection,分别生成 Set和Collection 类的实例。
final List list = Arrays.asList(“jack”, “mary”, “lucy”);
// 过滤 + 输出
System.out.println("过滤 + 输出: ");
Stream stream = list.stream();
stream.filter(item -> !item.equals(“zhangsan”))
.filter(item -> !item.equals(“wangwu”))
.forEach(item -> System.out.println(item));
// 限制为2
System.out.println("limit(2): ");
list.stream().limit(2).forEach(System.out::println);
// 排序
System.out.println("排序: ");
list.stream().sorted((o1, o2) -> o1.compareTo(o2)).forEach(System.out::println);
// 取出最大值
System.out.println("max: ");
String result = list.stream().max((o1, o2) -> o1.compareTo(o2)).orElse(“error”);
System.out.println(result);
// toList
System.out.println("toList: ");
List collectList = Stream.of(1, 2, 3, 4)
.collect(Collectors.toList());
System.out.println("collectList: " + collectList);
// 打印结果
// collectList: [1, 2, 3, 4]
// toSet
System.out.println("toSet: ");
Set collectSet = Stream.of(1, 2, 3, 4)
.collect(Collectors.toSet());
System.out.println("collectSet: " + collectSet);
// 打印结果
// collectSet: [1, 2, 3, 4]
复制代码
list 转 map(通过 stream)
List list = new ArrayList<>();
list.add(new Person(1, “mary”));
list.add(new Person(2, “lucy”));
Map<Integer, Person> map = list.stream().collect(Collectors.toMap(Person::getId, Function.identity()));
System.out.println(map);
// 输出: {1=Main3P e r s o n @ 42 f 30 e 0 a , 2 = M a i n 3 Person@42f30e0a, 2=Main3Person@42f30e0a,2=Main3Person@24273305}
Map<Integer, String> map2 = list.stream().collect(Collectors.toMap(Person::getId, Person::getName));
System.out.println(map2);
// 输出: {1=mary, 2=lucy}
复制代码
分割数据块
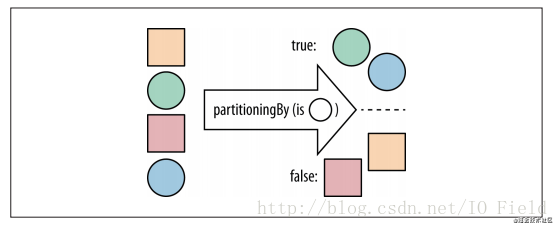
Map<Boolean, List> map = Stream.of(1, 2, 3, 4)
.collect(Collectors.partitioningBy(item -> item > 2));
System.out.println(map);
// 输出: {false=[1, 2], true=[3, 4]}
复制代码
函数的返回值只能将数据分为两组也就是ture和false两组数据。
数据块分组
数据分组是一种更自然的分割数据操作, 与将数据分成true和false两部分不同,可以使用任意值对数据分组。
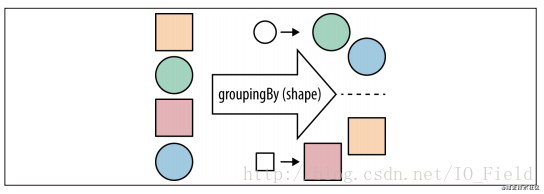
groupingBy是都集合进行分组,分组之后的结果形如Map<key,List>。其中,key是进行分组的字段类型,比如按Ussr类中的type(用户类型:1、2、3、4)进行分组,type的类型为Integer,分组之后的Map的key类型就是Integer。并且最多会分成四组,所以最后的结果即Map<Integer,List>。 假设我们想用户类型为1的集合,首先先进行分组,如: Map<Integer,List<User>> userMap = allUserList.parallelStream().collect(Collectors.groupingBy(User::getType)); 接下来直接从Map中get(1)即可,如: List<User> userList = userMap.get(1);
groupingBy与partitioningBy之间的坑
1.必须要提的一点是:在进行get时,groupingBy分组若key不存在则返回null,partitioningBy则会返回空数组,groupingBy分组注意判空。