1.深层、浅层、BP
| 出现背景 | 优点 | 缺点 | |
|---|---|---|---|
| 浅层神经网络 | 为了解决非线性问题 | 可以拟合任何函数 | 参数多,神经元多,需要更多的计算资源和数据 |
| BP算法(对p(label | input)建模 | 为了计算神经网络 | 损失回传 |
| 深度神经网络(>=5) | (时代背景数据爆炸,计算资源提升,希望自动学习特征(有个好的初始值)) | 1.比浅层更好的表达性(计算单元少,高层可利用低层,高层全局,低层局部,更有语义化),2.层次化地学习特征,3.多层隐变量允许统计上的组合共享;4.有效 | - |
| 改进的BP(对p(input)建模 | 为了让BP适应深度神经网络,建立产生输入的生成式模型,调整参数使得p最大 | - | - |
- 训练
- 监督
- 误差自顶向下,对网络微调
- 微调特征,使之与问题更相关
- 非监督
- 自下向上(greedy layer-wise traing
- 监督
自动编码器
- 自动编码器
- 无监督
- loss:重构误差(输入,输出)最小–>尽可能复现输入
- 输入=输出——尽可能复现输入
- input–encoder–>code–decoder–>output
- code:输入的特征表达
- 若有多层,则有多个code,多个不同的表达
- 网络结构:
- 三层
- 输入x->y
- 隐藏y->z
- 输出z
- 公式
- y=sigmoid(Wx+b)
- z=sigmoid(W’y+b’)
- 条件
- 输入神经元数量=输出(因为要一样
- 隐藏<输入
- 想要得到输入的一个压缩表示、抽象表示
- 三层
- 简化:W ′ = W T W'=W^TW′=WT——这样只要训练一组权值向量就可以
- 再加一个约束,若不考虑sigmoid的话:
- 若W − 1 = W T W^{-1}=W^TW−1=WT:正交矩阵,也就是说W是可以训练成正交矩阵的
- 再加一个约束,若不考虑sigmoid的话:
- 深度结构
- 预测时,只看encoder:encoder1–>encoder2–>encoder3
- 逐层训练(训练时才看解码过程)
- 将input–encoder1–>code1–decoder1–>input’,训练好后,去除decoder1
- 将input–>encoder1–>code1–encoder2–>code2–decoder2–>code1’
- 依次让每一层都得到最小的重构误差,每一层都一个好的表达
- 监督学习
- encoder(已经得到了一个很好地表达,有一个好的初始值)+分类器
- 有监督微调训练
- 只调整分类器
- 整体调整(端对端,更好)
- 扩展(通过增加约束来发现输入数据的结构
- 稀疏自编码器
- 约束:限制使得得到的表达code尽量稀疏
- L1范数项
- y = w T x y=w^Txy=wTx
- l o s s ( x , w ) = ∣ ∣ w y − x ∣ ∣ 2 + λ Σ j ∣ y j ∣ loss(x,w)=||wy-x ||^2+\lambda\Sigma_j|y_j|loss(x,w)=∣∣wy−x∣∣2+λΣj∣yj∣–>y长度小,loss要最小化,
- z=wy
- 稀疏容易得到更好的表达
- 约束:限制使得得到的表达code尽量稀疏
- 降噪自编码器
- 存在噪声
- 提高鲁棒性
- 操作
- x–>x’:以一定概率分布擦除x中项(置0)
- x’->y–>z:loss(z,x)做误差迭代—>这样就学习到了x’(破损数据)
- 破损数据的优点
- 破损数据训练出来的w噪声小
- 破损数据一定程度减轻了训练数据与测试数据的代购(去除了噪声)
- 破损数据不影响记忆(人脑也是如此,虽然是随意擦除)
- 稀疏自编码器
- 栈式自编码器的优点
- 有强大的表达能力
- 深度神经网络的所有优点
- 可以获得输入的层次型分组/部分-整体分解结构
- 学习方式:逐层训练(前一层的输出是后一层的输入–依次训练
深度玻尔兹曼机DBM(deep boltzmann machine(DBM)
| 网络结构 | 状态 | …目标函数… | 特点 | |
|---|---|---|---|---|
| Hopfield网络 | 单层,全连接(有权,无向图)wij=wji,wii=0 | 1,-1(0),确定性地取1、0 | E = − 1 2 S T ω S E=-\frac{1}{2}S^T\omega SE=−21STωS | 1.确定性地接受能量下降方向;2.会达到局部极小(模拟退火解决,以一定概率接受能量上升) |
| Boltzman机器 | p(v)符合玻尔兹曼分布,生成模型,有隐层(与外部无连接),有可见层(输入层、输出层)(与外部有链接,收到外部约束),全连接(同层也有)(有权无向图)wij=wji,wii=0 | 1(on),0(off),状态满足boltzman分布,以p取1(二值神经元) | P α P β = e x p ( − ( E ( S α ) − E ( S β ) ) / T ) \frac{P_\alpha}{P_\beta}=exp(-(E(S^\alpha)-E(S^\beta))/T)PβPα=exp(−(E(Sα)−E(Sβ))/T) | 1.接受能量下降,以p(p ( s i = 1 ) = 1 1 + e x p ( − b i − Σ j s j w j i ) p(s_i=1)=\frac{1}{1+exp(-b_i-\Sigma_js_jw_{ji})}p(si=1)=1+exp(−bi−Σjsjwji)1)接受能量上升(模拟退火)2.训练时间长,3.结构复杂,4.也可能局部极小;5.功能强大 |
| RBM(受限Boltzman机 | p(v)符合玻尔兹曼分布,生成模型,区别:同层无连接,其他全连接,可见层1(输入v)、隐藏层1(h,给定可视层下,条件独立)(二部图) | vi,hj,{0,1},以p取1(二值神经元) | 联合组态能量函数E ( v , h ; θ ) = − Σ i j w i j v i h j − Σ i b i v i − Σ j a j h j , p θ ( v , h ) = 1 Z ( θ ) e x p ( − E ) , 目 标 函 数 l o g ( p θ ( v ) ) ( 极 大 似 然 ) E(v,h;\theta)=-\Sigma_{ij}w_{ij}v_ih_j-\Sigma_{i}b_{i}v_i-\Sigma_{j}a_{j}h_j, p_\theta(v,h)=\frac{1}{Z(\theta)}exp(-E),目标函数log(p_\theta(v))(极大似然)E(v,h;θ)=−Σijwijvihj−Σibivi−Σjajhj,pθ(v,h)=Z(θ)1exp(−E),目标函数log(pθ(v))(极大似然) | |
| DBN | 生成模型,多层,顶层无向图(RBM)(hn-1-hn),低层(v<-hn-1),去除上层,下层是个RBM | (二值神经元) | 从下到上逐层当做RBM训练 | 低层是单向的与RBM不一致,所以提出了DBM |
| DBM | p(v)符合玻尔兹曼分布,生成模型,多层,全无向图 | (二值神经元) | 双向,每层需要考虑上下层神经元(多层)E ( v , h 1 , h 2 ; θ ) = − v T W 1 h 1 − h 1 T W 2 h 2 ; p ( v ) = Σ h 1 , h 2 1 Z e x p ( − E ) E(v,h^1,h^2;\theta)=-v^TW^1h^1-h^{1T}W^2h^2;p(v)=\Sigma_{h1,h2}\frac {1}{Z}exp(-E)E(v,h1,h2;θ)=−vTW1h1−h1TW2h2;p(v)=Σh1,h2Z1exp(−E) | 低层是单向的与RBM不一致,所以提出了DBM |
- Hopfield网络
- 以确定的方式,确定神经元输出是1/0:
- 输入>0:1,输入<0:0
- BM
- 二值神经元:以不确定性的方式决定输出是1/0
- sigmoid:p ( s i = 1 ) = 1 1 + e x p ( − b i − Σ j s j w j i ) p(s_i=1)=\frac{1}{1+exp(-b_i-\Sigma_js_jw_{ji})}p(si=1)=1+exp(−bi−Σjsjwji)1
- 状态分布;P α P β = e x p ( − ( E ( S α ) − E ( S β ) ) / T ) \frac{P_\alpha}{P_\beta}=exp(-(E(S^\alpha)-E(S^\beta))/T)PβPα=exp(−(E(Sα)−E(Sβ))/T)
- 状态:P α = e x p ( − ( E ( S α ) ) / T ) {P_\alpha}=exp(-(E(S^\alpha))/T)Pα=exp(−(E(Sα))/T)
- 二值神经元:以不确定性的方式决定输出是1/0
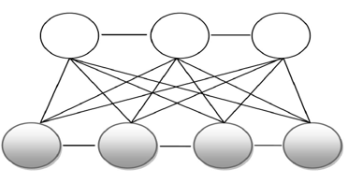
- RBM(生成模型)
- 二部图,层内无连接,层间全连接
- 能量函数:E ( v , h ; θ ) = − Σ i j w i j v i h j − Σ i b i v i − Σ j a j h j E(v,h;\theta)=-\Sigma_{ij}w_{ij}v_ih_j-\Sigma_{i}b_{i}v_i-\Sigma_{j}a_{j}h_jE(v,h;θ)=−Σijwijvihj−Σibivi−Σjajhj
- (v,h)联合分布(满足boltzman):
- p θ ( v , h ) = 1 Z ( θ ) e x p ( − E ) = 1 Z ( θ ) Π i j e w i j v i h j Π i e b i v i Π j e a j h j = e x p ( − E ) Σ v , h e x p ( − E ) p_\theta(v,h)=\frac{1}{Z(\theta)}exp(-E)=\frac{1}{Z(\theta)}\Pi_{ij}e^{w_{ij}v_ih_j}\Pi_{i}e^{b_{i}v_i}\Pi_je^{a_{j}h_j} =\frac{exp(-E)}{\Sigma_{v,h}exp(-E)}pθ(v,h)=Z(θ)1exp(−E)=Z(θ)1ΠijewijvihjΠiebiviΠjeajhj=Σv,hexp(−E)exp(−E)
- Z ( θ ) = Σ v , h e x p ( − E ) Z(\theta)=\Sigma_{v,h}exp(-E)Z(θ)=Σv,hexp(−E)
- ==>可以得到其他分布
- p θ ( v , h ) = e x p ( − E ) Σ v , h e x p ( − E ) p_\theta(v,h)=\frac{exp(-E)}{\Sigma_{v,h}exp(-E)}pθ(v,h)=Σv,hexp(−E)exp(−E)
- p θ ( v ) = Σ h e x p ( − E ) Σ v , h e x p ( − E ) p_\theta(v)=\frac{\Sigma_{h}exp(-E)}{\Sigma_{v,h}exp(-E)}pθ(v)=Σv,hexp(−E)Σhexp(−E)
- p θ ( h ) = Σ v e x p ( − E ) Σ v , h e x p ( − E ) p_\theta(h)=\frac{\Sigma_{v}exp(-E)}{\Sigma_{v,h}exp(-E)}pθ(h)=Σv,hexp(−E)Σvexp(−E)
- p θ ( h ∣ v ) = e x p ( − E ) Σ h e x p ( − E ) p_\theta(h|v)=\frac{exp(-E)}{\Sigma_{h}exp(-E)}pθ(h∣v)=Σhexp(−E)exp(−E)
- p θ ( v ∣ h ) = e x p ( − E ) Σ v e x p ( − E ) p_\theta(v|h)=\frac{exp(-E)}{\Sigma_{v}exp(-E)}pθ(v∣h)=Σvexp(−E)exp(−E)
- 目标函数:l o g ( p θ ( v ) ) log(p_\theta(v))log(pθ(v))——极大似然
- N个样本
- m a x Σ i = 1 N l o g ( p θ ( v ) ) max \Sigma_{i=1}^N log(p_\theta(v))maxΣi=1Nlog(pθ(v))
- l o g ( p θ ( v ) ) = l o g Σ h e x p ( − E ) − l o g Σ v ′ , h ′ e x p ( − E ) log(p_\theta(v))=log{\Sigma_{h}exp(-E)}-log{\Sigma_{v',h'}exp(-E)}log(pθ(v))=logΣhexp(−E)−logΣv′,h′exp(−E)
- 求导(梯度法、CD算法
- ∂ l o g ( p θ ( v ) ) ∂ θ = Σ h ( e x p ( − E ) − ∂ E ∂ θ ) Σ h e x p ( − E ) − Σ v ′ , h ′ ( e x p ( − E ) − ∂ E ∂ θ ) Σ v ′ , h ′ e x p ( − E ) \frac{\partial {log(p_\theta(v))}}{\partial \theta}=\frac{\Sigma_{h}(exp(-E)\frac{- \partial E}{\partial \theta})}{\Sigma_{h}exp(-E)}-\frac{\Sigma_{v',h'}(exp(-E)\frac{- \partial E}{\partial \theta})}{\Sigma_{v',h'}exp(-E)}∂θ∂log(pθ(v))=Σhexp(−E)Σh(exp(−E)∂θ−∂E)−Σv′,h′exp(−E)Σv′,h′(exp(−E)∂θ−∂E)
- = Σ h ( p ( h ∣ v ) − ∂ E ∂ θ ) − Σ v ′ , h ′ ( p ( v ′ , h ′ ) − ∂ E ∂ θ ) =\Sigma_h(p(h|v)\frac{- \partial E}{\partial \theta})-\Sigma_{v',h'}(p(v',h')\frac{- \partial E}{\partial \theta})=Σh(p(h∣v)∂θ−∂E)−Σv′,h′(p(v′,h′)∂θ−∂E)
- = E p ( h ∣ v ) ( − ∂ E ∂ θ ) − E p ( v ′ , h ′ ) ( − ∂ E ∂ θ ) =E_{p(h|v)}(\frac{- \partial E}{\partial \theta})-E_{p(v',h')}(\frac{- \partial E}{\partial \theta})=Ep(h∣v)(∂θ−∂E)−Ep(v′,h′)(∂θ−∂E)(期望)
- =正面-负面
- 观测分布:E p ( h ∣ v ) ( − ∂ E ∂ θ ) E_{p(h|v)}(\frac{- \partial E}{\partial \theta})Ep(h∣v)(∂θ−∂E):给定观测数据之后,隐变量对于可视层的在这个状态之下的一个期望获得的结果
- 真实分布$E_{p(v’,h’)}(\frac{- \partial E}{\partial \theta}) $:整体的学习期望,在整个网络,所有变化之下的期望的求导
- 对于具体的参数W,a,b
- E = − v T W h − b T v − a T h E=-v^TWh-b^Tv-a^ThE=−vTWh−bTv−aTh
- p ( v , h ) = 1 z e v T W h e b T v e a T h p(v,h)=\frac{1}{z}e^{v^TWh}e^{b^Tv}e^{a^Th}p(v,h)=z1evTWhebTveaTh
- p ( h ∣ v ) = Π j p ( h j ∣ v ) = Π j = e ( a j + Σ i w i j v i ) h j 1 + e ( a j + Σ i w i j v i ) p(h|v)=\Pi_jp(h_j|v)=\Pi_j=\frac{e^{(a_j+\Sigma_iw_{ij} v_i)h_j}}{1+e^{(a_j+\Sigma_iw_{ij}v_i)}}p(h∣v)=Πjp(hj∣v)=Πj=1+e(aj+Σiwijvi)e(aj+Σiwijvi)hj
- p ( v ∣ h ) = Π j p ( v i ∣ h ) = Π i = e ( b i + Σ j w i j h j ) v i 1 + e ( b i + Σ j w i j h j ) ) p(v|h)=\Pi_jp(v_i|h)=\Pi_i=\frac{e^{(b_i+\Sigma_jw_{ij} h_j)v_i}}{1+e^{(b_i+\Sigma_jw_{ij} h_j))}}p(v∣h)=Πjp(vi∣h)=Πi=1+e(bi+Σjwijhj))e(bi+Σjwijhj)vi
- − ∂ E ∂ w i j = − v i h j \frac{- \partial E}{\partial w_{ij}}=-v_ih_j∂wij−∂E=−vihj
- − ∂ E ∂ b i = − v i \frac{- \partial E}{\partial b_{i}}=-v_i∂bi−∂E=−vi
- − ∂ E ∂ a j = − h j \frac{- \partial E}{\partial a_{j}}=-h_j∂aj−∂E=−hj
- ∂ l o g ( p θ ( v ) ) ∂ θ = E p ( h ∣ v ) ( − ∂ E ∂ θ ) − E p ( v ′ , h ′ ) ( − ∂ E ∂ θ ) \frac{\partial {log(p_\theta(v))}}{\partial \theta}=E_{p(h|v)}(\frac{- \partial E}{\partial \theta})-E_{p(v',h')}(\frac{- \partial E}{\partial \theta})∂θ∂log(pθ(v))=Ep(h∣v)(∂θ−∂E)−Ep(v′,h′)(∂θ−∂E)
- ∂ l o g ( p θ ( v ) ) ∂ w i j = Σ h j ( p ( h j ∣ v ) v i h j ) − Σ v ′ ( p ( v ′ ) Σ h j ′ ( p ( h j ′ ∣ v ′ ) v i ′ h j ′ ) ) \frac{\partial {log(p_\theta(v))}}{\partial w_{ij}}=\Sigma_{h_j}(p(h_j|v)v_ih_j)-\Sigma_{v'}(p(v')\Sigma_{h'_j}(p(h'_j|v')v'_ih'_j))∂wij∂log(pθ(v))=Σhj(p(hj∣v)vihj)−Σv′(p(v′)Σhj′(p(hj′∣v′)vi′hj′))
- 进一步简化= p ( h j = 1 ∣ v ) v i − Σ v ′ ( p ( v ′ ) p ( h j ′ = 1 ∣ v ′ ) v i ′ ) ) =p(h_j=1|v)v_i-\Sigma_{v'}(p(v')p(h_j'=1|v')v'_i))=p(hj=1∣v)vi−Σv′(p(v′)p(hj′=1∣v′)vi′))
- 取值0就没有了,hj=0了都
- ∂ l o g ( p θ ( v ) ) ∂ b i = Σ h j ( p ( h j ∣ v ) v i ) − Σ v ′ ( p ( v ′ ) Σ h j ′ ( p ( h j ′ ∣ v ′ ) v i ′ ) ) \frac{\partial {log(p_\theta(v))}}{\partial b_{i}}=\Sigma_{h_j}(p(h_j|v)v_i)-\Sigma_{v'}(p(v')\Sigma_{h'_j}(p(h'_j|v')v'_i))∂bi∂log(pθ(v))=Σhj(p(hj∣v)vi)−Σv′(p(v′)Σhj′(p(hj′∣v′)vi′))
- = v i − Σ v ′ ( p ( v ′ ) v i ′ ) ; Σ h j p ( h j ′ ∣ v ′ ) = 1 =v_i-\Sigma_{v'}(p(v')v'_i);\Sigma_{h_j}p(h_j'|v')=1=vi−Σv′(p(v′)vi′);Σhjp(hj′∣v′)=1
- ∂ l o g ( p θ ( v ) ) ∂ a j = Σ h j ( p ( h j ∣ v ) h j ) − Σ v ′ ( p ( v ′ ) Σ h j ′ ( p ( h j ′ ∣ v ′ ) h j ′ ) ) \frac{\partial {log(p_\theta(v))}}{\partial a_{j}}=\Sigma_{h_j}(p(h_j|v)h_j)-\Sigma_{v'}(p(v')\Sigma_{h'_j}(p(h'_j|v')h'_j))∂aj∂log(pθ(v))=Σhj(p(hj∣v)hj)−Σv′(p(v′)Σhj′(p(hj′∣v′)hj′))
- = p ( h j = 1 ∣ v ) − Σ v ′ ( p ( v ′ ) p ( h j ′ = 1 ∣ v ′ ) ) ) =p(h_j=1|v)-\Sigma_{v'}(p(v')p(h_j'=1|v')))=p(hj=1∣v)−Σv′(p(v′)p(hj′=1∣v′)))
- ∂ l o g ( p θ ( v ) ) ∂ w i j = Σ h j ( p ( h j ∣ v ) v i h j ) − Σ v ′ ( p ( v ′ ) Σ h j ′ ( p ( h j ′ ∣ v ′ ) v i ′ h j ′ ) ) \frac{\partial {log(p_\theta(v))}}{\partial w_{ij}}=\Sigma_{h_j}(p(h_j|v)v_ih_j)-\Sigma_{v'}(p(v')\Sigma_{h'_j}(p(h'_j|v')v'_ih'_j))∂wij∂log(pθ(v))=Σhj(p(hj∣v)vihj)−Σv′(p(v′)Σhj′(p(hj′∣v′)vi′hj′))
- 计算
- v是已知的,第一项可以计算,但第二项不好计算
- 计算第二项:采样:E ( f ( x ) ) = Σ x f ( x ) p ( x ) = 1 L σ x f ( x ) p ( x ) E(f(x))=\Sigma_xf(x)p(x)=\frac{1}{L}\sigma_{x~f(x)}p(x)E(f(x))=Σxf(x)p(x)=L1σx f(x)p(x)
- CD-K采样(与吉布斯采样存在差异
- v0输入定
- v0-p(h|v)->h0通过二值神经元计算
- sigmoid:p ( s i = 1 ) = 1 1 + e x p ( − b i − Σ j s j w j i ) p(s_i=1)=\frac{1}{1+exp(-b_i-\Sigma_js_jw_{ji})}p(si=1)=1+exp(−bi−Σjsjwji)1
- h0-p(v|h)->v1(采样)
- CD-1就已经能够得到足够的精度了
- $v={v_i},v^{(0)}=vn $
- 初始化Δ w i j = 0 , Δ a i = 0 , Δ b j = 0 \Delta w_{ij}=0,\Delta a_i=0,\Delta b_j=0Δwij=0,Δai=0,Δbj=0
- 迭代:
- 所有j,h j ( 0 ) p ( h j ∣ v ( 0 ) ) h_j^{(0)}~p(h_j|v^{(0)})hj(0) p(hj∣v(0))
- 所有i,v i ( 0 ) p ( v i ∣ h ( 0 ) ) v_i^{(0)}~p(v_i|h^{(0)})vi(0) p(vi∣h(0))
- 计算梯度取平均值(批处理,每个样本都叠加
- CD-K采样(与吉布斯采样存在差异
- E = − v T W h − b T v − a T h E=-v^TWh-b^Tv-a^ThE=−vTWh−bTv−aTh
- N个样本
版权声明:本文为weixin_40485502原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。