现在越来越多的同学在使用 SIMCA 软件来进行主成分分析了,这个软件的好处就是可视化界面方便,出图也还可以。但是也遇到很多同学不太理解得到的一些结果,所以这里我就以自己的一些经验和查询的资料来帮大家入个门吧!!
主成分也许不是你想象中的那个主成分
在最开始接触到主成分分析(Principal Component Analysis)的时候,我想很多同学都和我有一个疑问:主成分分析,到底那一个是主成分?我最开始也是这样的去理解,以为是从众多的变量(指标)中去挑选一个“主成分”。
然而实际却并不是这样的,其实这里的主成分,不是要从我们已经测量得到的变量中选择一个,而是我们要“从众多的变量中拟合出尽可能代替众多变量的“变量”",即实现从“多”到“少”过程,也就是大家经常听说的“降维”。这里的“维”,可以看成我们实验中的变量,也就是你测定的指标,比如说代谢组里面不同的代谢物,一株植物不同的农艺性状,样品中的元素含量等等。
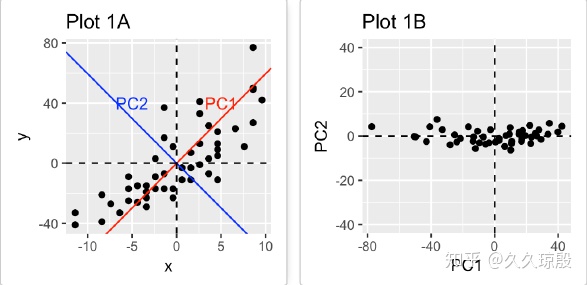
这里从网上找了一张图片来表示。在图A中,要表示左下角和右上角两处差异较大的数据,我们就需要 X-Y 两个坐标来表示,而当我们把图A中的 X-Y 坐标轴旋转到图示的 PC1和 PC2 时,就得到了图B,在图B中,只需要 X 轴的坐标就能够表示出数据之间的差异。这就是主成分分析,而在实际运用中,变量更多,所以更复杂一些,但整体的原理是类似的。
SIMCA 中 PCA 结果参数解读
我们这里用 R 包 factoextra 中自带的数据 decathlon2,然后我们取前23行和前10列在 SIMCA 软件中进行分析说明。
把数据导入后直接用默认参数来分析,默认参数给出项目概览结果如下:

Model:当前窗口中模型列表,在创建多个模型后会以 M1, M2 命名。
Type:对应模型中的具体类型,如 PCA, PLS-DA, OPLS-DA 等等,本例中选用的是 PCA 分析。
A:该模型中 Q2(cum) 值最高时主成分对应的数量,此时只显示出第 1 个;需要着重一提的是,A 这里的数值并不是表示该模型中所有主成分的数量,实际是有多少个变量,就可以有多少个主成分,但是软件根据 Q2(cum) 指标判断后得出只有第一个主成分才是最有效的。
N:该模型中参与分析的样本数量。
R2X(cum):在当前主成分数量 (A) 时解释方差的累积值,在增加主成分数量时 (A),R2X(cum) 也会随之增加。
Q2(cum):Q2 表明的是随着主成分数量增加时该模型的预测能力(goodness of prediction),Q2X 则表明的是当前变量的预测能力,而 Q2(cum) 则表明的是当前主成分数量时总的模型预测能力。当增加的 1 个主成分但并不能提升交叉验证的数据质量时,就会 Q2X 则会为负值,此时Q2(cum)[A+1] < Q2(cum)[A],即 Q2(cum) 在 A 个主成分时达到最高,软件会在 A 列显示此时 Q2(cum) 对应的主成分数量。
在 SIMCA 中采用的是 7-fold 交叉验证(Cross-validation),7-fold 的意思是把数据分为 7 份,选择 1 份拿来作为预测数据,其余 6 份用于训练模型,然后重复 7 次,使得每份数据都能被用作预测数据。关于交叉验证,如果想要了解更多的话,可以观看一下这个关于交叉验证的视频:StatQuest - 机器学习——交叉验证(中英字幕)。
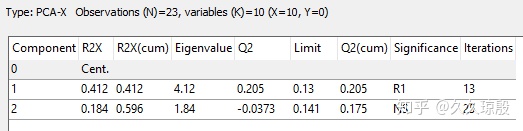
此时大家可能也注意到了,A 列的数值为 1,那是为啥呢?原因就是 Q2(cum) 的限制。当我们双击模型所在的行时,我们可以得到更多的细节,得到图 3 结果。默认的结果只有数字 1 那一行,这里是我再让软件再增加(图4)一个主成分时的结果(图3),具体就是点一下这个里面的 add,此时我们就能看到更多的信息(图3)。然后我们就会看到第 2 个主成分的 Q2 是负值,因此 Q2(cum)才会降低,软件就会“舍弃”这个主成分。
这里我们对图 3 中的具体参数进行了一个大概的解释。
Component:成分数量
R2X:每个成分对应的解释率
R2X(cum):在第 n 个成分时的累积解释率
Eigenvalue:每个成分对应的载荷值。载荷值表示的是每个主成分持有的变量的多少,所有主成分的载荷值的和等于变量数量。细心的同学可能就会发现,在数值上,载荷值(Eigenvalue)/总变量数量 (k)= 解释率(R2X),即 4.12/10=0.412,也就是说,主成分 1 能够解释 10 个变量中的 4.12 个变量。Eigenvalue > 1 也可以用来大概判断选取多少个主成分。
Q2:每个成分对应的预测能力,具体信息上面已经提了一下。
Limit:对应主成分的 Q2 不显著时的临界值,大概意思就是高于这个值时就表明显著,结果对应于 Significance 列
Q2(cum):整体模型的预测能力,刚刚提到的
Significance:交叉验证是否显著
Iterations:这个我也不知道是啥……
我觉得你关心的得分图和载荷图
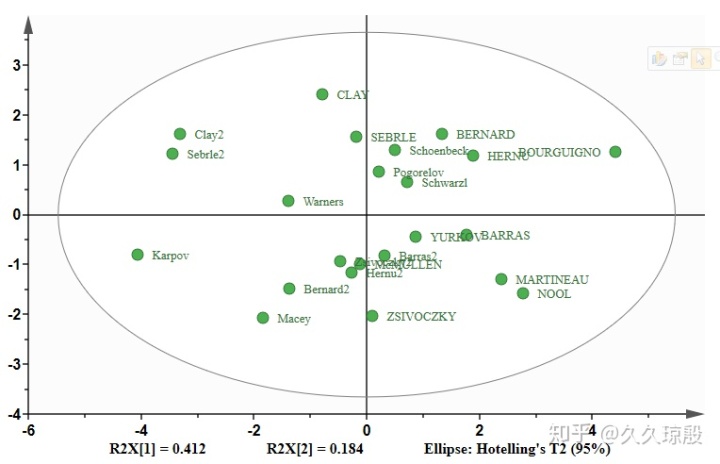
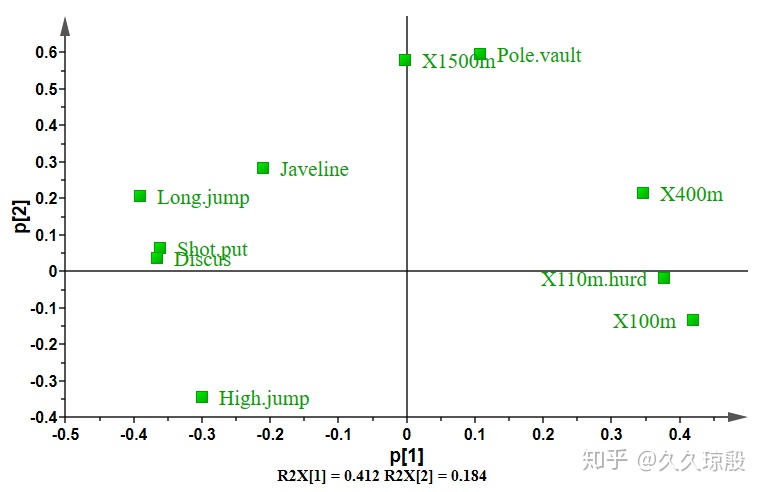
以上展示的是关于模型的一些结果,然后我们还关心的是 score plot(图5)。由于在默认参数时,软件只给出了 1 个主成分,这不足以来显示得分图,所以我增加(图4)了 1 个主成分来做得分图(图5)。得分图最下面一排的 R2X[1],R2X[2] 就是对应主成分 1,2 的解释率,可以和上图模型结果匹配上。再一个是 Hotelling's T2(95%),表明的是图中样本强异常值的诊断方法,可以简单的看成灰色圆圈(Ellipse)外的就是强异常值。
以上介绍的是 PCA 的得分图,下面介绍的是 PCA 中的载荷图 (图 6, Loading plot)。SIMCA 中的载荷图又可被称为相关性图 (correlation plot),相关性强的变量聚合在一起,相关性相反的变量在通过原点的线的两端分布。图中每个变量的坐标分别对应于与 PC1 和 PC2 的相关性(有待进一步确定)和方向性。每个变量在所有主成分方向上的坐标的平方和等于 1。
通过在图上右键-create list 就能得到每个变量的坐标(相关性),比如 Javeline (-0.211, 0.285) ,X400(0.345, 0.214)和 X100(0.419, -0.132),Javeline 和 X100 在两个主成分方向上都呈负相关,X400 和 X100 在 PC1 上呈正相关,PC2 上呈负相关。
同时载荷图与得分图是互相补充说明的,进一步解释的话,就是得分图(图5)上给定方向上的样本的位置是受到载荷图(图6)上同样方向上的变量影响的。举个例子,得分图 (图 5) 左上方的样本 Clay2 和 Sebrle2 在载荷图 (图6) 对应位置和方向上有变量 Long.jump 和 Javeline,说明该两样本与这两个变量呈正相关,也可得该两样本与变量 X100 成负相关。而变量对样本在得分图上影响的“大小或品质”可通过求变量与原点之间的距离来评估。
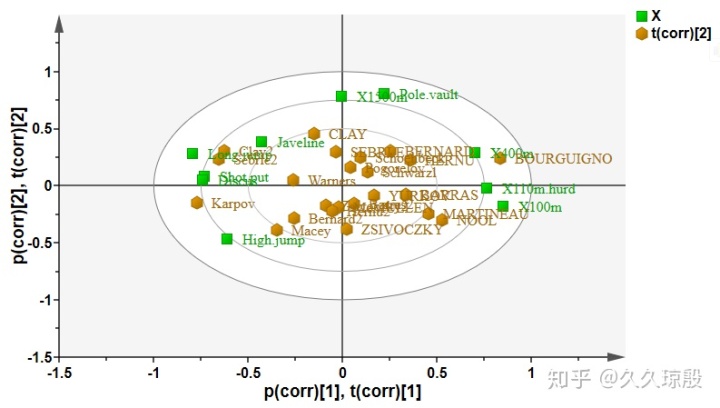
另一个更直观点的图就是 Bioplot,这个图把得分图和载荷图整合在一起。这个图的解读和上面基本一致,坐标数值由于是经过变换后的,所以和上面的所提到的不同了,但最主要的是理解到样本和变量在“方向”上所表达的意义。
这次关于 SIMCA 软件的 PCA 结果解读就暂时告一段落,以上内容都是通过阅读一些网页的介绍和基于平时知识的理解和积累形成的,旨在与大家分享知识,当然本文中可能存在对一些参数理解错误、偏差,表述不清楚的地方,希望比较熟悉的小伙伴能够指出来,我会马上更正。
在主成分分析当中,SIMCA 软件带给我的印象更偏重于模型方面的应用,而在 PCA 基础信息方面介绍的相对较少,这里给大家推荐一个网页,里面对 PCA 有着更详细的一下描述,希望对大家有所帮助:
Principal Component Methods in R: Practical Guidewww.sthda.com