FASTA
1.FASTA存储什么?
fasta存储核酸序列(DNA/RNA),也存储蛋白质的核苷酸序列(Animo Acid sequence,简称AA序列)
2.FASTA包含什么内容?
第一行:以“>”开头主要存储的是序列的描述信息
第二行:序列
3.例子1: AA序列(核苷酸序列)
UniRef数据库中下载的人类血红蛋白α亚基的序列。
>sp|P69905|HBA_HUMAN Hemoglobin subunit alpha OS=Homo sapiens GN=HBA1
MVLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHFDLSHGSAQVKGHG
KKVADALTNAVAHVDDMPNALSALSDLHAHKLRVDPVNFKLLSHCLLVTLAAHLPAEFTP
AVHASLDKFLASVSTVLTSKYR从第一行看起:

第二行开始:核苷酸序列的信息,我们一般使用下面的对应表。

例子2:For 核酸序列
使用人类血红蛋白a亚基对应的mRNA序列,这个序列是从NCBI RefSeq数据库中下载的。
>gi|13650073|gb|AF349571.1| Homo sapiens hemoglobin alpha-1 globin chain (HBA1) mRNA, complete cds
CCCACAGACTCAGAGAGAACCCACCATGGTGCTGTCTCCTGACGACAAGACCAACGTCAAGGCCGCCTGG
GGTAAGGTCGGCGCGCACGCTGGCGAGTATGGTGCGGAGGCCCTGGAGAGGATGTTCCTGTCCTTCCCCA
CCACCAAGACCTACTTCCCGCACTTCGACCTGAGCCACGGCTCTGCCCAGGTTAAGGGCCACGGCAAGAA
GGTGGCCGACGCGCTGACCAACGCCGTGGCGCACGTGGACGACATGCCCAACGCGCTGTCCGCCCTGAGC
GACCTGCACGCGCACAAGCTTCGGGTGGACCCGGTCAACTTCAAGCTCCTAAGCCACTGCCTGCTGGTGA
CCCTGGCCGCCCACCTCCCCGCCGAGTTCACCCCTGCGGTGCACGCCTCCCTGGACAAGTTCCTGGCTTC
TGTGAGCACCGTGCTGACCTCCAAATACCGTTAAGCTGGAGCCTCGGTGGCCATGCTTCTTGCCCCTTTG
G从第一行看起:


gi号具有唯一性。
第二行开始:
发现在mRNA序列还是用T来表示,这是为了保证数据的统一性;U只是在RNA中替换了原来的T。
FASTQ
1.什么是FASTQ?
FASTQ是带有测序质量信息的存储格式。
2.FASTQ包含什么内容?
@ST-E00126:128:HJFLHCCXX:2:1101:7405:1133
TTGCAAAAAATTTCTCTCATTCTGTAGGTTGCCTGTTCACTCTGATGATAGTTTGTTTTGG
+
FFKKKFKKFKF<KK<F,AFKKKKK7FFK77<FKK,<F7K,,7AF<FF7FKK7AA,7<FA,,第一行:序列测序的坐标信息等。

第二行:测序得到的碱基序列,一般用ATGCN表示,N表示荧光信号干扰无法判断到底是哪个碱基。
第三行:“+”开头,一般为空(无用)
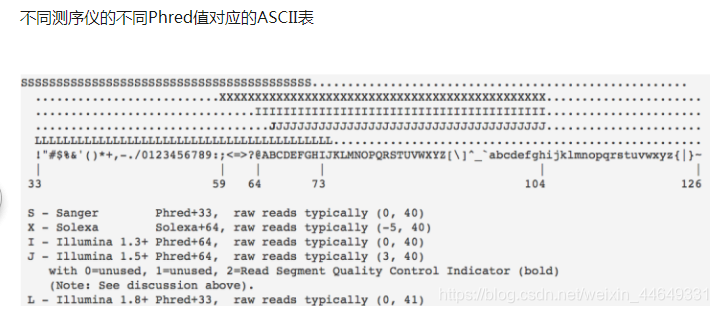
第四行:测序质量信息,与第二行的碱基序列是一一对应的。其中每一个符号对应的ASCII值成为phred值
phred值可以理解为对应碱基的质量值,越大说明测序质量越好。
3.FASTQ质量值的计算方法
P值:测序错误概率error probility;测序仪根据荧光信号强弱会给出的一个参考值。
Q=-10*log10(P)
Phred=Q+33/64(illumina:+33)
Phred对应的ASCII字符对应到这个碱基。

版权声明:本文为weixin_44649331原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。