prometheus监控k8s集群
1.监控方式
node-expoter部署在k8s节点收集当前节点资源,Prometheus用来分析处理收集汇总的数据,grafana用来进行图形展示。
2.部署Prometheus和grafana
我本地已经在k8s中部署了Prometheus和grafana,可参考https://blog.csdn.net/lucky_ykcul/article/details/128965441?spm=1001.2014.3001.5502
3.部署node-expoter
1)使用daemonset方式部署,这样能确保k8s各节点都会分布node-expoter服务
vim node-expoter.yml
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: work
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
spec:
containers:
- image: prom/node-exporter
name: node-exporter
ports:
- containerPort: 9100
protocol: TCP
name: http
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: node-exporter
name: node-exporter
namespace: work
spec:
ports:
- name: http
port: 9100
nodePort: 31310
protocol: TCP
type: NodePort
selector:
k8s-app: node-exporter
kubectl apply -f node-expoter.yml -n work


2)在浏览器中查看metric数据
但是在Prometheus中没有看到k8s集群的metrics数据
3)修改Prometheus的configmap用于获取k8s节点metrics
cat pro_cm.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: work
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
kubernetes_sd_configs:
- role: node
relabel_configs:
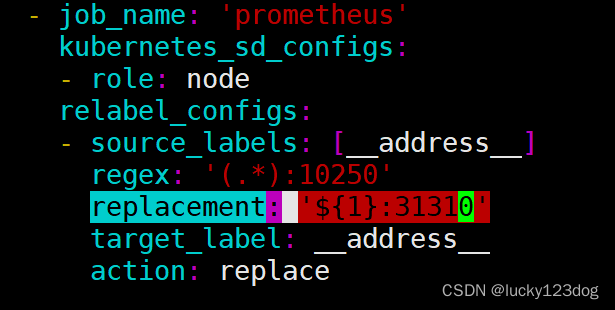
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
Prometheus在监控时,可以通过API获取到我们的Node节点信息,但是由于我们的metrics默认监听的端口是10250而不是9100,因此如果没有进行上述端口替换的配置,我们的Prometheus的Node监控就一直处于DOWN的状态。在上述relabel的配置中,我们通过Target示例的Metadata信息,动态重新写入Label的值,并且将__address__标签从10250替换成9100,这样我们的Prometheus就可以正常监控了。
4)重新部署Prometheus服务
[root@master prometheus]# kubectl apply -f pro_cm.yml
configmap/prometheus-config configured
[root@master prometheus]# kubectl delete deployment -n work prometheus
deployment.apps "prometheus" deleted
[root@master prometheus]# kubectl apply -f pro_deploy.yml
deployment.apps/prometheus created
5)在浏览器中查看Prometheus的master,node节点的metric数据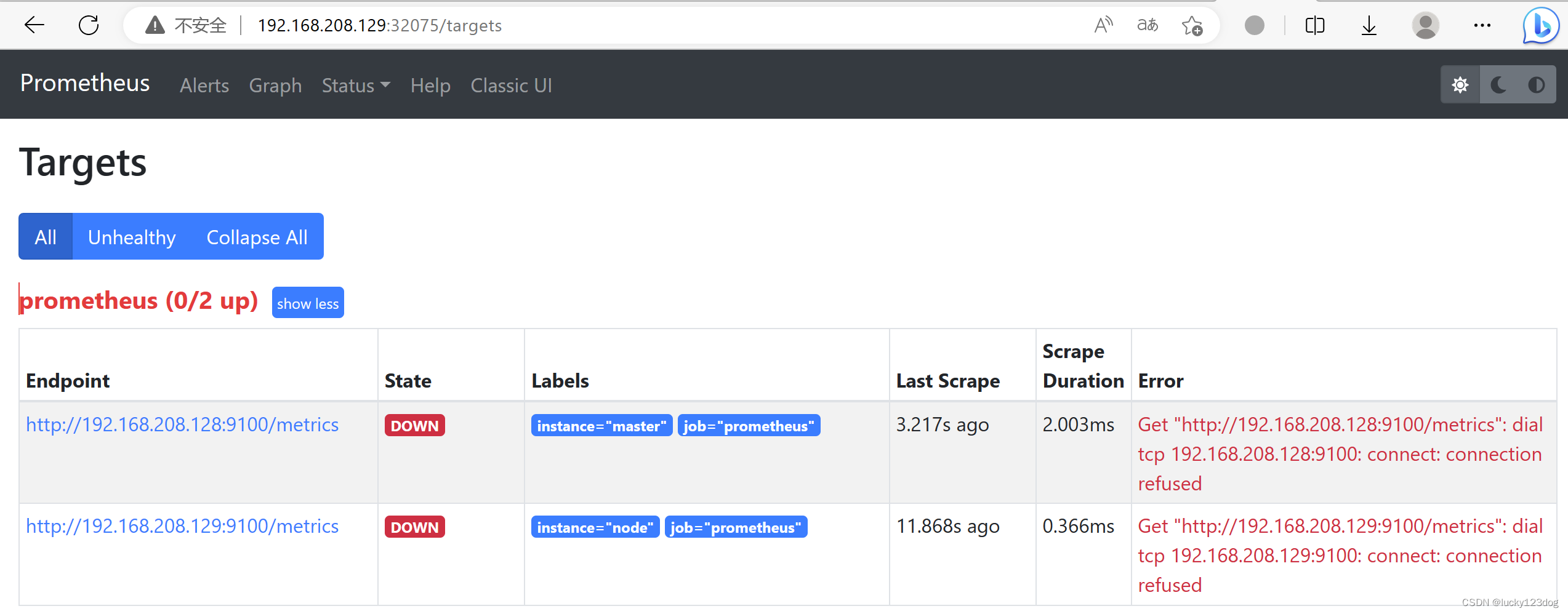
已经可以看到master,node的metric,但状态却是DOWN
Telnet本机的9100端口是connection refused的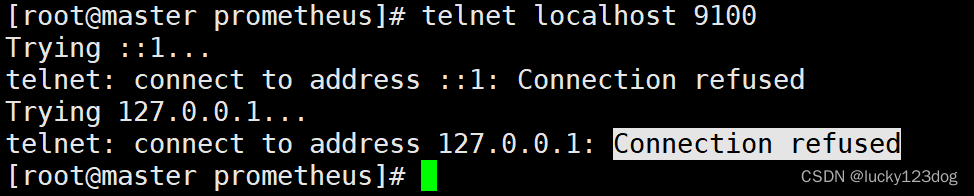
查看node-exporter的端口发现是31310
这里我把Prometheus的监听9100端口改成nodeport的端口
重新apply configmap,重启Prometheus服务
[root@master prometheus]# kubectl apply -f pro_cm.yml
configmap/prometheus-config configured
[root@master prometheus]# kubectl get pod -n work
NAME READY STATUS RESTARTS AGE
grafana-5b86ddbbff-sq5nx 1/1 Running 10 37d
node-exporter-l7nv2 1/1 Running 2 8d
prometheus-5f58d57f4c-pdcbg 1/1 Running 0 52m
[root@master prometheus]# kubectl delete pod -n work prometheus-5f58d57f4c-pdcbg
pod "prometheus-5f58d57f4c-pdcbg" deleted
再次查看Prometheus,master,node状态已经up了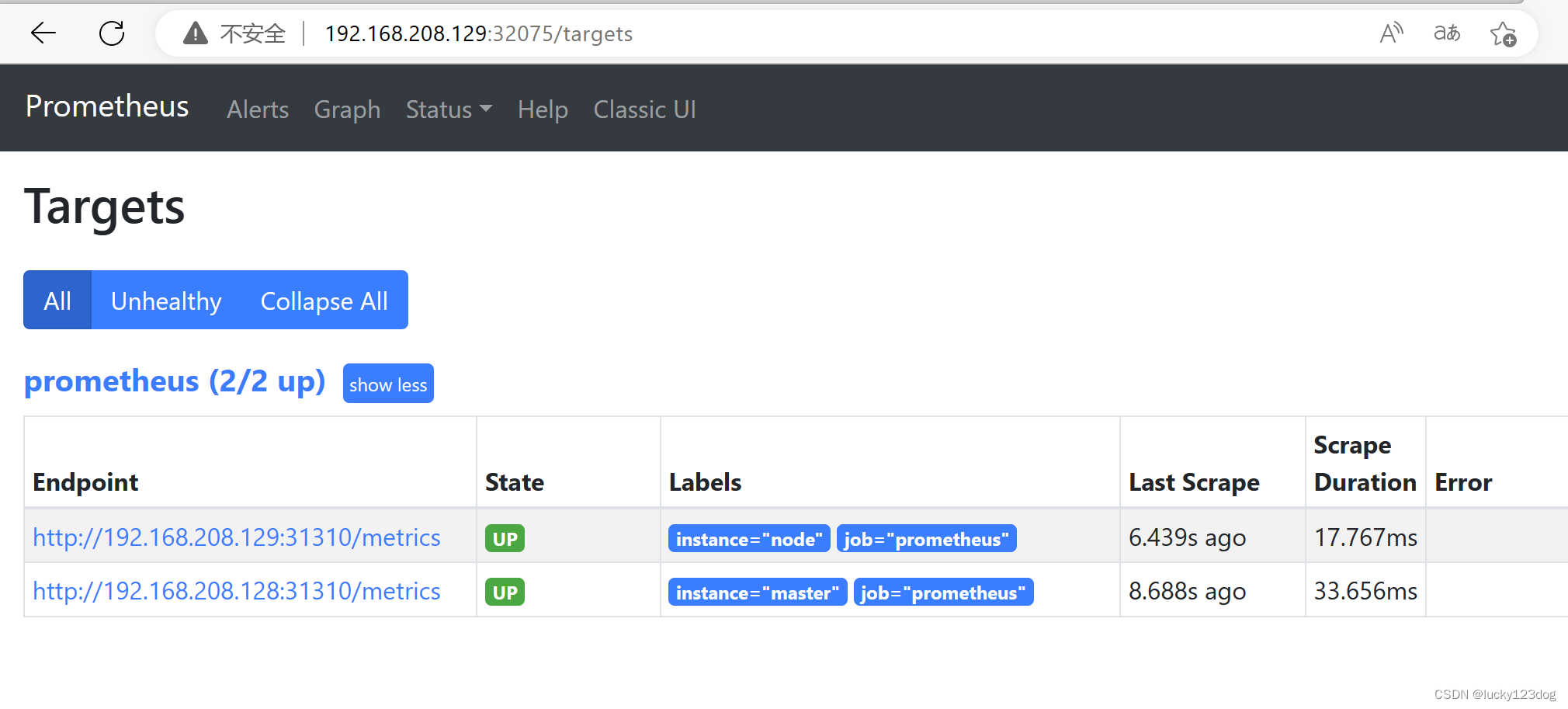
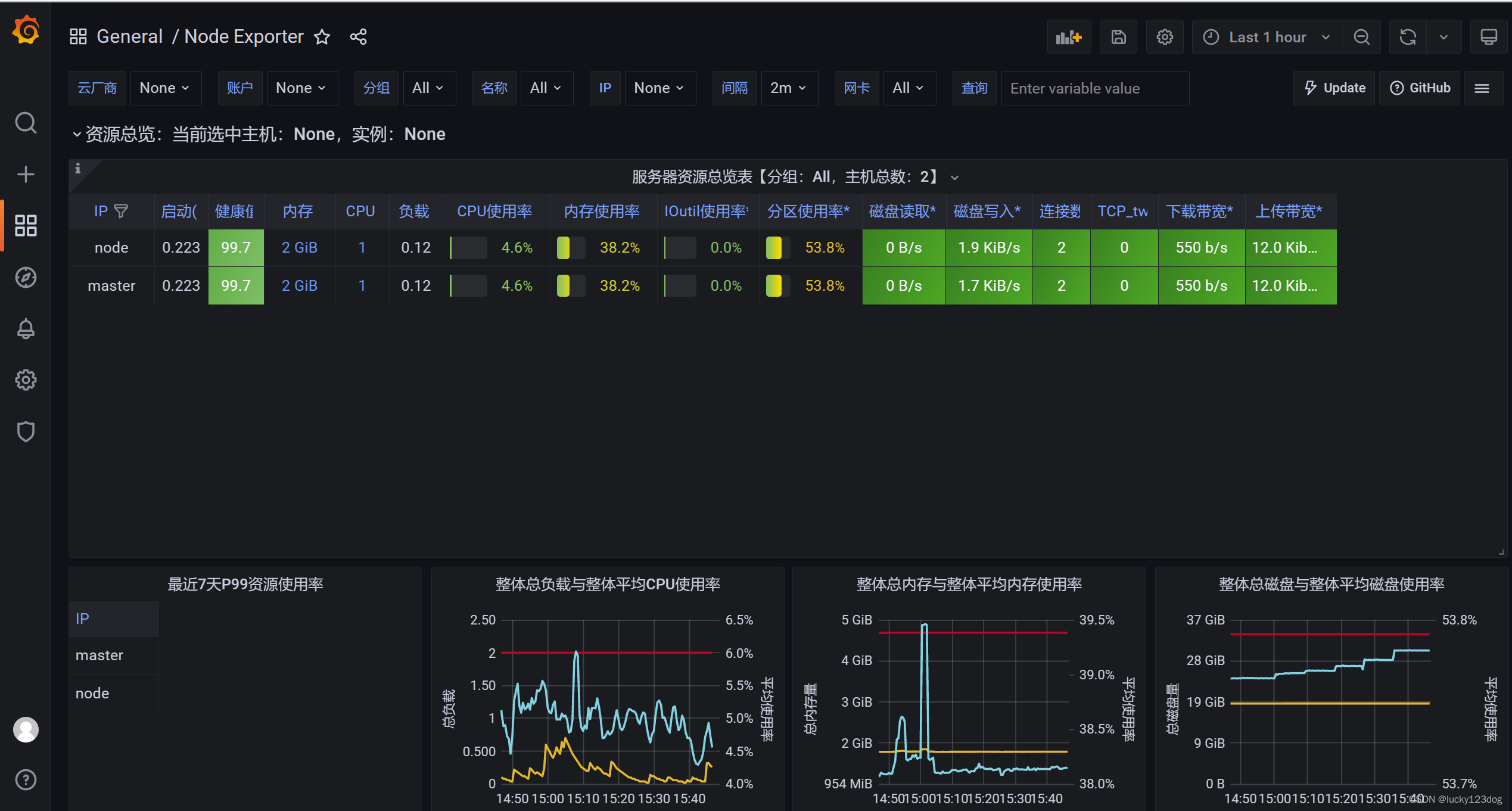
4.配置grafana
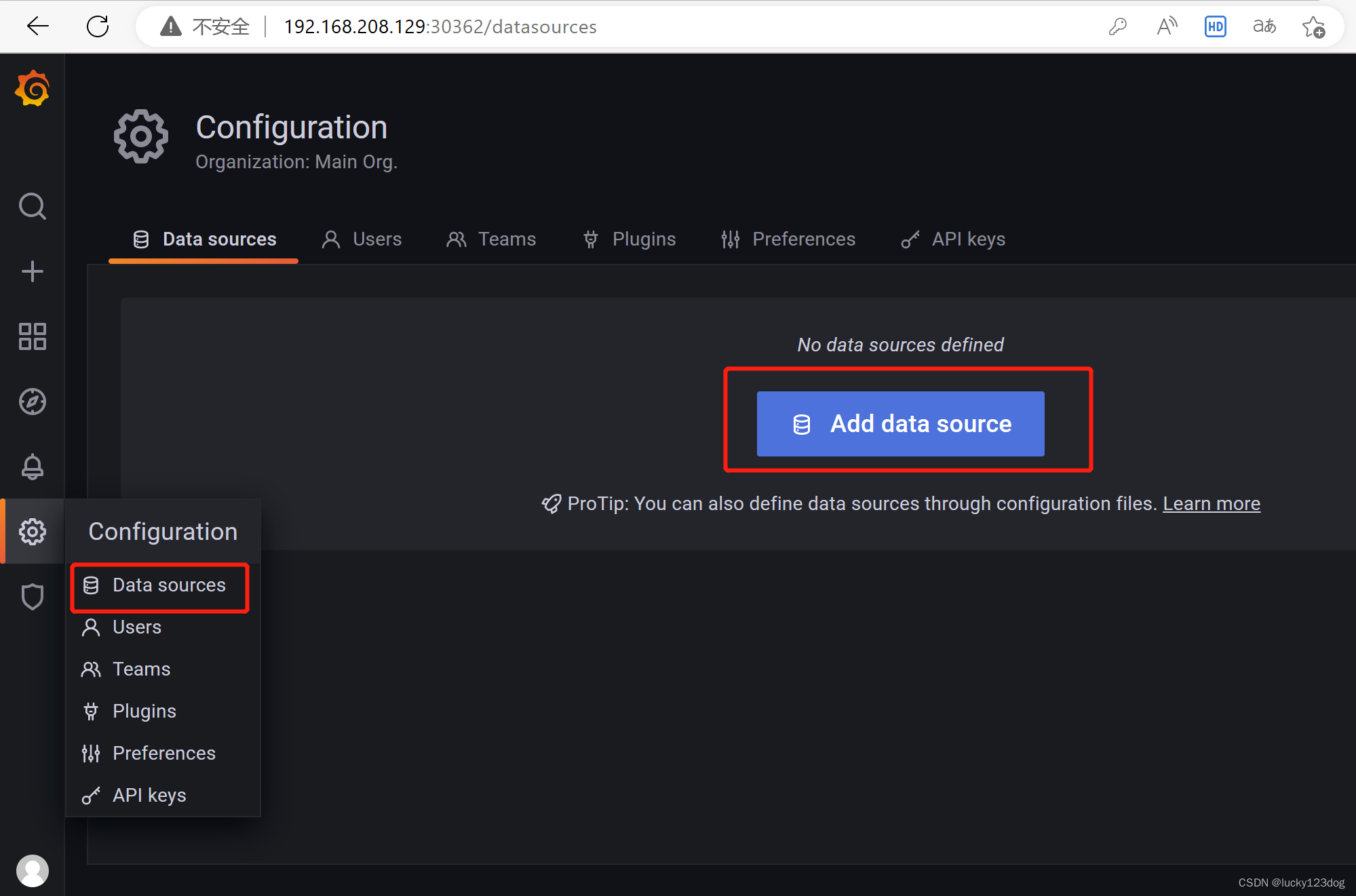
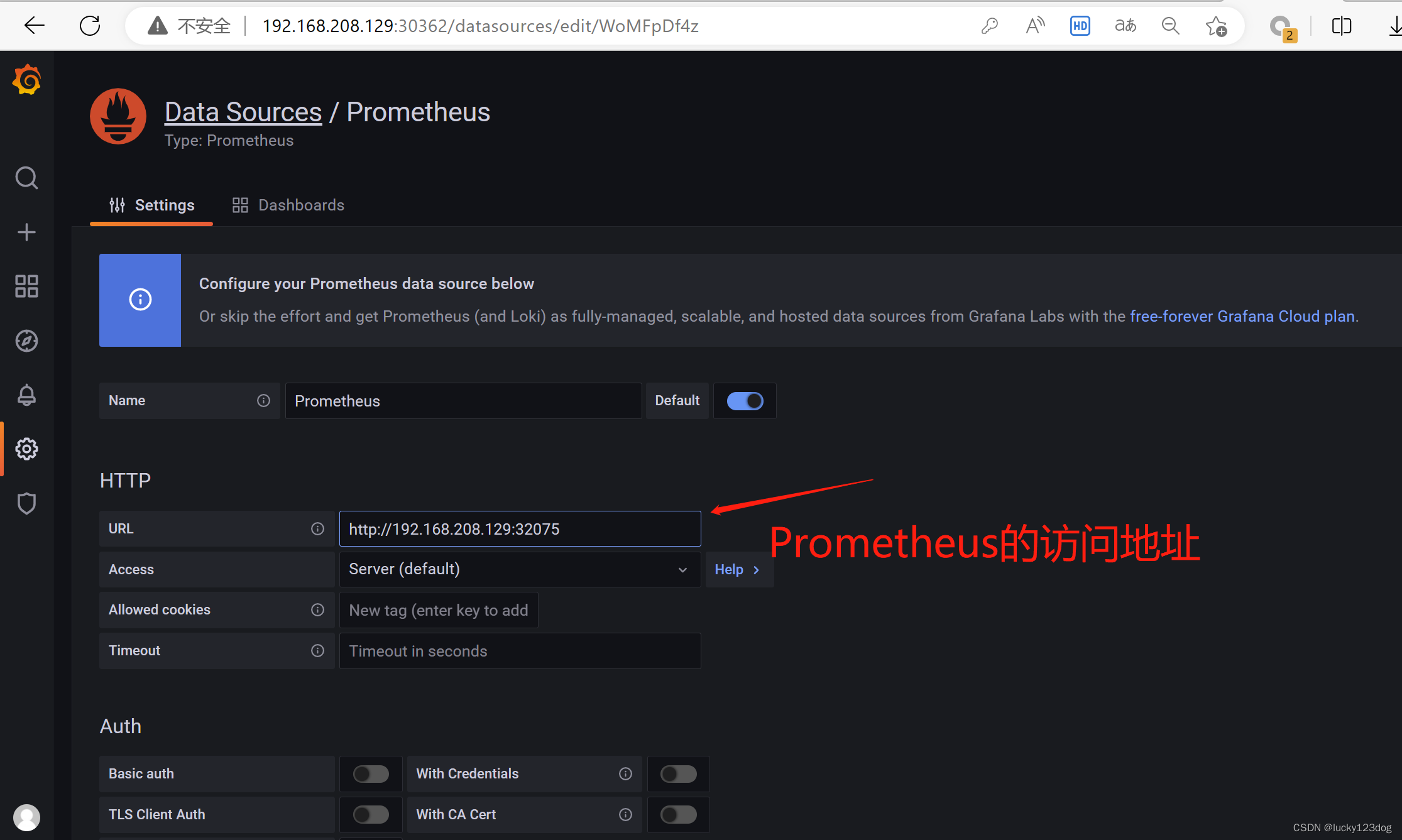
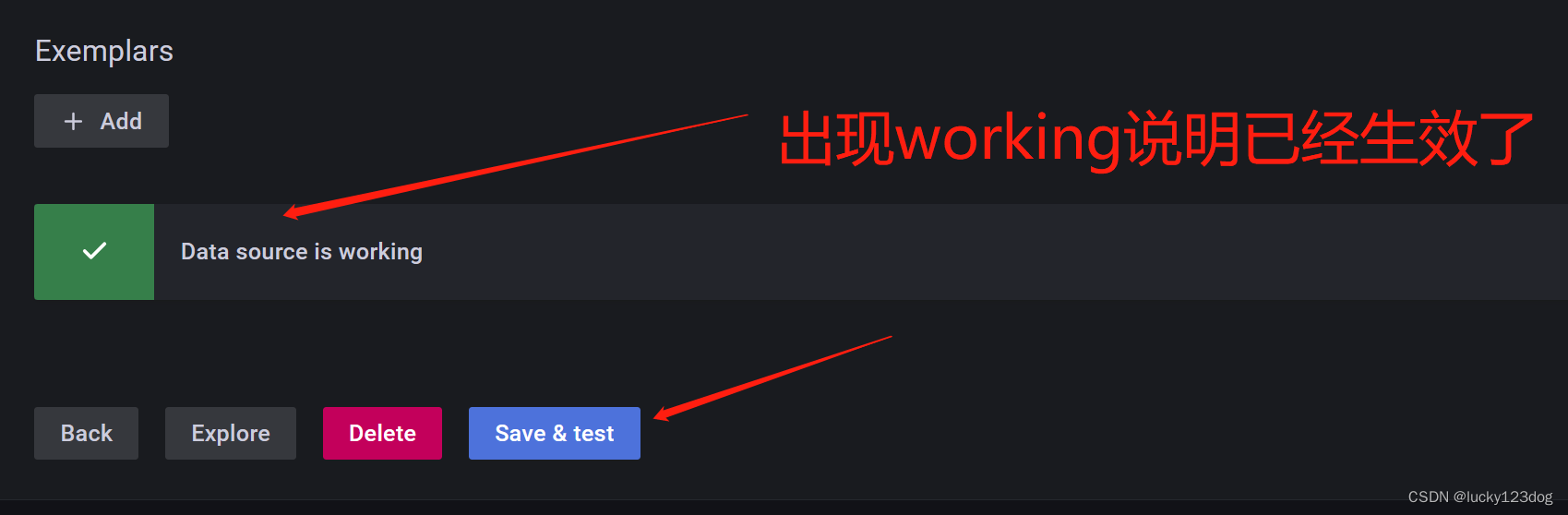
grafana展示监控数据
这里输入8919,是grafana官方id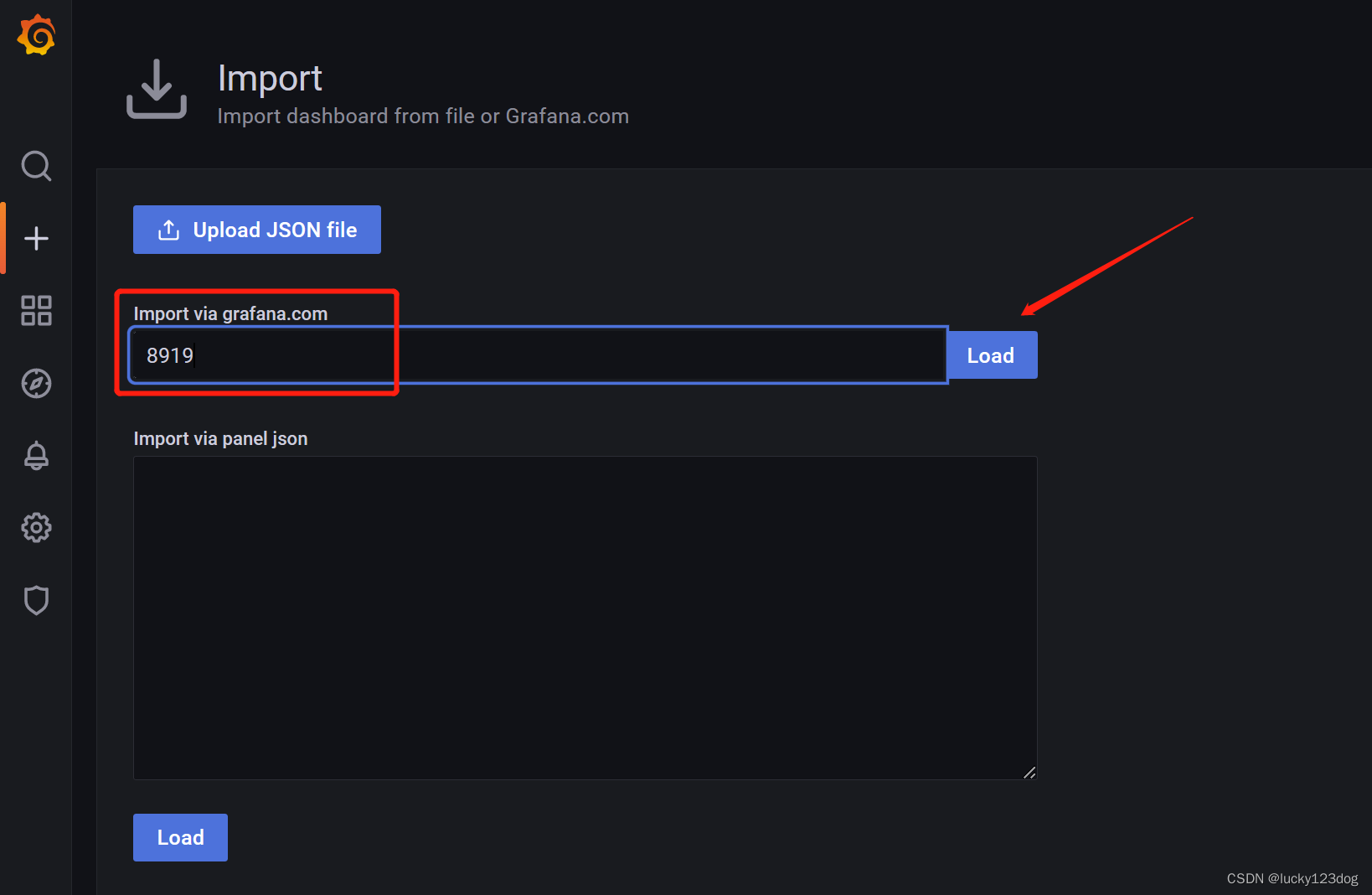
自定义一个名字,数据源选择之前创建的Prometheus,点击import
import之后跳转到master和node的监控页面,可以看到监控数据