延迟初始化
有时候一些高开销的对象,需要在使用时再初始化,以减轻初始化时的消耗,这时就需要延迟初始化,常见的就是单例模式的懒汉模式。
懒汉模式也算是面试常考问题吧,写法如下:
public class SingleLazy {
public static SingleLazy instance;
private SingleLazy(){}
public static SingleLazy getInstance() {
if(instance==null){
synchronized (SingleLaze.class){
if(instance==null){
instance = new SingleLazy();
}
}
}
return instance;
}
}
加锁的目的防止重复初始化,两次判断的原因是因为减少加锁的开销(如果instance对象已经初始化好了再去获取锁等待锁的,岂不是很浪费资源(空转也是转啊))。
可是这么写对吗?细心的朋友肯定已经发现了,俺没将instance声明为一个volatile。
那么为啥需要将它声明为volatile呢?
那是因为,new操作并不是在一瞬间完成的,而且判断它的引用是为为null并不能作为它已经完成实例化的标志。
它本质上分为三步:
- 在堆上为对象分配内存
- 将对象写入内存
- 将引用指向内存
可是第二三步是能重排序的,写读重排序是被JMM所允许的,而且两者也没有数据依赖,且单线程下执行结果是一样的,所以出于性能,就可能导致2,3顺序重排,如果在这两者之间,正好有第二个线程来调用instance就会读到没有完全初始化的对象(对象逸出)。这时了解volatile的朋友就会知道,只要将引用声明为volatile就可以保证2,3不会重排序(普通写之后的volatile写是不允许重排序的)。
private static volatile SingleLazy instance;
是不是有点好奇volatile为啥就能实现这种功能还有volatile具体的含义(内存语义)呢?
volatile内存语义
理解volatile的一个好方法就是对volatitle变量的读写看成是加了同一个锁的同步操作。
volatile int i;
i = 1;//读
int k= i;//写
//等价于
int i;
synchronized(obj){
i =1;
}
synchronized(obj){
k = i;
}
volatile的特性:
- 可见性,对一个volatile变量的读总是能看到最后一次对其的写(上次讲的锁缓存行迫使修改刷新到主存)。
- 原子性:任意单个volatile变量的读/写具有原子性。(通过内存屏障)
内存语义:
- 读:JMM会把该线程对应的本地内存置为无效,迫使其去主内存读取。
- 写:JMM会把该线程对应的本地内存中的共享变量刷新到主存。
| 第一个操作 | 第二个操作 | 普通读/写 | volatile读 | volatile写 |
|---|---|---|---|---|
| 普通读/写 | \ | N | ||
| volatile读 | \ | N | N | N |
| volatile写 | \ | N | N |
总结:
- volatile写不会重排序到其他操作之前。
- volatile读不会重排序到其他操作之后。
- volatile写不会重排序到volatile读之后。
内存语义的实现:
为了实现volatile写的语义,看过前面内容的都知道肯定是用内存屏障实现的。
JMM采用保守策略 , 编译器会根据具体情况进行优化。只要保证内存语义不会被破坏即可:
写:
- 写前插入一个StoreStore屏障,保障了在volatile写之前写缓冲区已经刷新到了主内存(比如当前面根本写操作时就不需要)
- 写后插入一个StoreLoad屏障,保障后续读操作之前,所有写缓冲区变量刷新到主存(比如当后面没有读或者后面有volatile写操作时就不需要)
读:
- 读后插一个LoadLoad屏障,确保该volatile变量读后才让其他操作读(比如后面读操作无法与其重排序时就不需要)
- 读后插入一个LoadStore屏障,确保读后其他操作才写到内存。(比如后面的写操作无法其重排序时就不需要)
不过这也得看具体的处理器,比如X86处理器仅支持写-读重排序(缓存区的存在),所以可以只留下StoreLoad屏障即可。
既然了解了volatile的语义再了解下锁的吧。
锁的内存语义
锁的特性相信大家都很清楚保证临界区代码(同步代码块)互斥执行。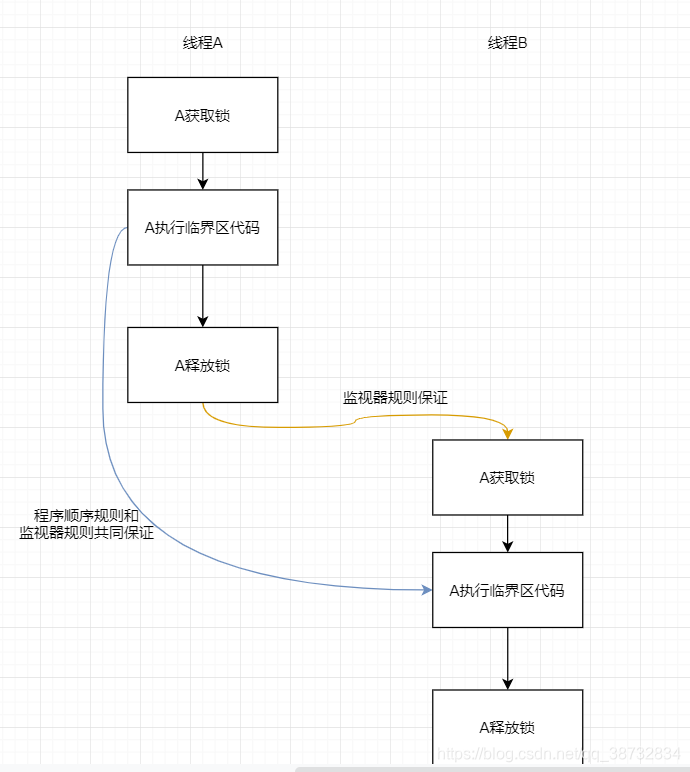
锁的获取:
- 获取上一个获得锁的线程(或者默认状态)对共享变量的修改。
- 修改共享变量
锁的释放:
- 使向下一个获取锁的线程获取共享变量的新状态
本质上是释放锁的线程向获得锁的线程传递信息 。
内存语义的实现:
synchronized的底层实现
这里主要是通过ReentrantLock来讲锁的内存语义的实现机制。
(ReentrantLock与synchronized区别在于一个由JVM直接控制,是否需要主动释放锁,以及竞争激烈时ReentrantLock性能优于synchronized等)
从它的源码分析可知,它主要是通过在内部类NonfairSync和FairSync继承抽象内部类Sync,然后Sync再继承AbstractQueuedSynchronizer(AQS)的路径来实现的。其中AQS中维护一个waitStatus(volatile变量)来表示锁的状态。
锁的获取
//公平锁
@ReservedStackAccess
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();//获取状态
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
//用CAS比较是否与预期值一致
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
//就是当前线程
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);//更新锁的状态
return true;
}
return false;
}
//非公平锁唯一不同的地方,公平锁会查询是否有更长等待时间的线程,而非公平锁不会。
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
其中那个compareAndSetState(0, acquires) 方法,是这里面的关键它保证了状态值等于预期值时,以原子方式将同步状态设置为给定的更新值。此操作具有与volatile读写同样的内存语义。具体的实现是一个native方法 ,那个方法在单核处理器则不做处理,如果是多核则为cmpxchg指令加上look指令.
锁的释放
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {//确定为当前线程
free = true;
setExclusiveOwnerThread(null);
}
setState(c);//更新状态
return free;
}
实现总结:
- 利用volatile的写读所具有的内存语义
- 利用CAS(look)所附带的volatile读和写的内存语义
concurrent包的实现:
一个通用化模式:
- 声明共享变量为volatile
- CAS的原子条件更新来实现线程之间的同步
- 配合volatile的读/写,CAS所具有的volatile读写的内存语义实现线程之间的通信
final内存语义
三大原语还有一个就是final了。
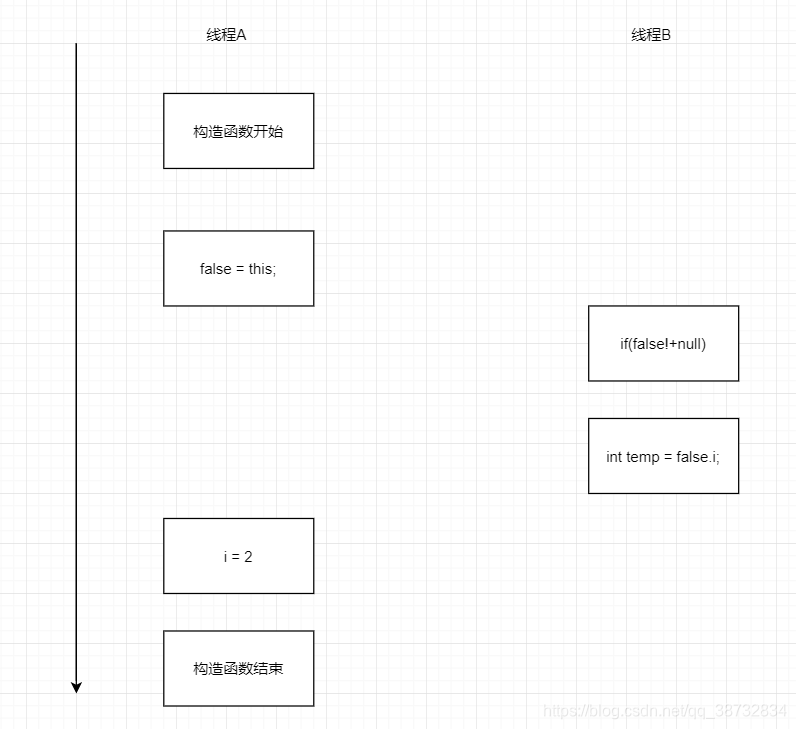
final的重排序规则:
- 在构造函数内对final域的写,与随后把这个构造对象的引用赋值给一个引用的操作不能重排序(不能在对final域写之前将对象提前发布(逸出))
- 初次读一个包含final域的引用与随后初次读这个final域不能重排序(如果重排可能就没有初始化,当然静态不算)
具体到写操作实现:
- 编译器通过在final域的写后,构造函数return之前插入storestore屏障 ,来阻止final写重排序代构造函数之外。
- 如果是对final引用的初始化,那么对final的对象的实例化和对对象的赋值时不能重排序的。
不能从构造函数中逸出保证了,在引用变量对任何线程可见时,已经被完全初始化。不过还是注意不要将为初始化完全的引用提前发布。比如:
final int i;
static False false;
public False(){
i = 2;
false = this;
}
具体到读操作实现:
- 大多数的处理器是不会重排序这种有间接依赖的操作的,不过个别处理器如果允许这种操作,编译器就会在读引用之后读final之前插入一个loadload屏障
hapens-before
这是JMM的核心概念,理解JMM的关键。
大概来说它的保证具有两个方面:
- 面向程序员: 如果前一个操作结果对后一个操作结果可见
- 面向编译器和处理器: 如果不影响结果,可以进行重排序来优化
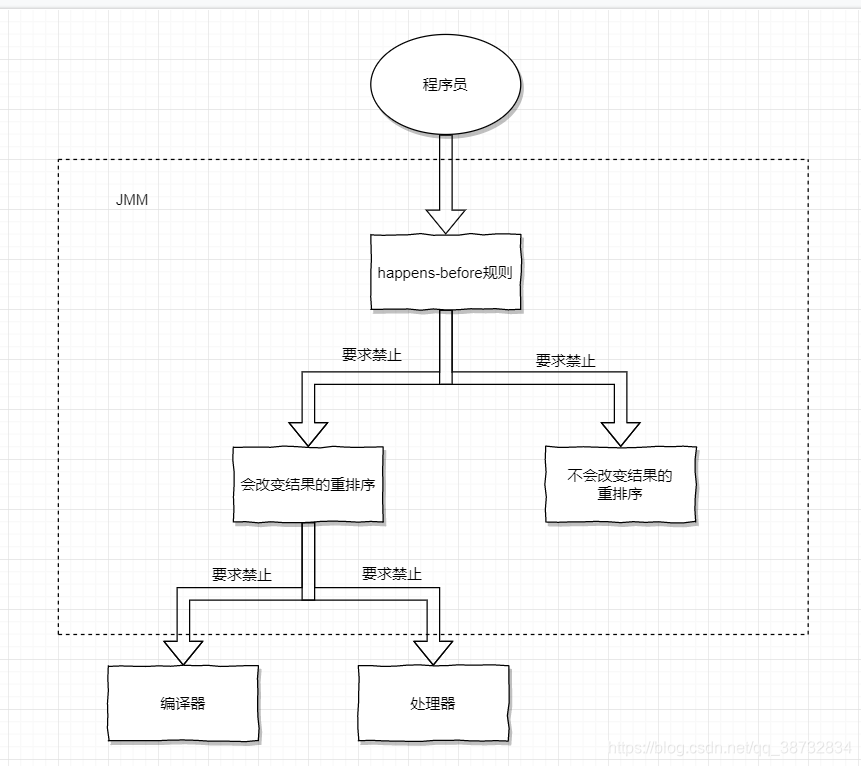
hapens-before具体规则如下:
- 程序顺序规则:同一线程内,每个操作hapens-before它的后续操作
- 监视器锁规则:锁的释放hapens-before于随后锁的获取
- volatile规则:对一个volatile的写hapens-before任意后续操作对该volatile的读
- 传递性:A hapens-before B,B hapens-before C=A hapens-before C
- start()规则:线程A中执行B的start,那么A中的B.start优先于B中任意操作
- join()规则:线程A执行B.join后,B中任意操作hapens-beforeA中任意后续操作(join之后)
其他解决延迟加载的方法
如果仅仅需要将静态属性延迟加载,那么可以写一个私有静态内部类来初始化对象。
public class InstanceFactory{
private static class InstanceHolder{
public static Instance instance = new Instance;
}
public static Instance getInstance(){
return InstanceHolder.instance;
}
}
原理:
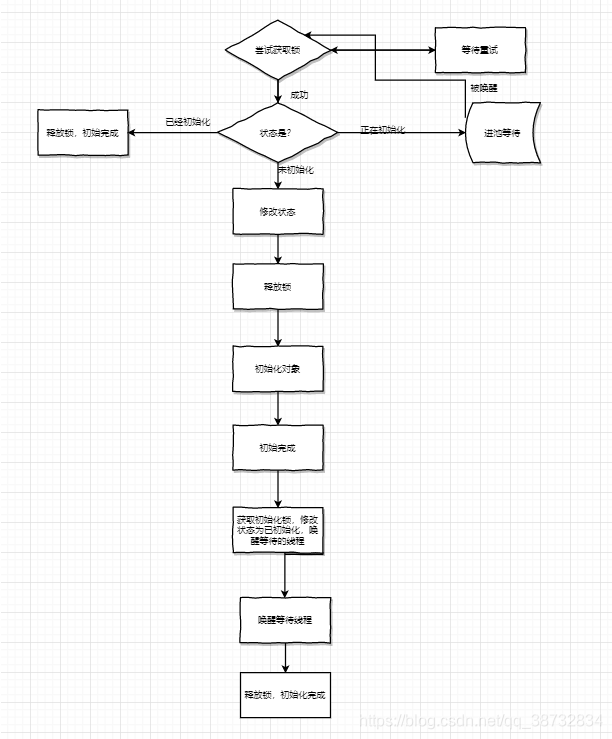
由于每个类或者接口的都有个一个初始化锁与之对应。初始化过程大概如图所示
首先A(1),B(1.2)线程尝试获取初始化锁,A成功后,A将状态由原来的未初始化修改正在初始化(2),然后释放锁(3),开始初始化对象(4)。在此期间B一直在等待尝试获取初始化锁(1.2)。等到锁释放后,获取锁(3.1),查看状态已经为正在初始化(3.1),这时释放锁(3.6),进入对应的线程池等待(3.7)。
(图上的数字表示大致时间顺序。)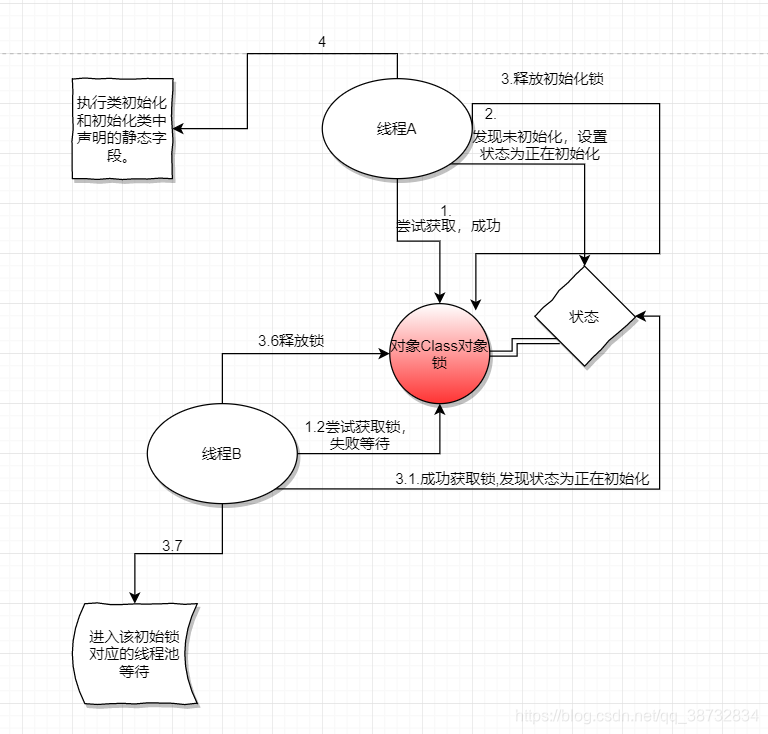
当A初始化完毕后,获取锁(5)修改状态为已初始化(6),唤醒线程池中的其他线程(7),释放锁(8),A的初始化工作就完成了,B收到通知(7.1),尝试获取锁(8.1),发现锁状态为已初始化(8.6),释放锁(9),B的初始化工作也完成了。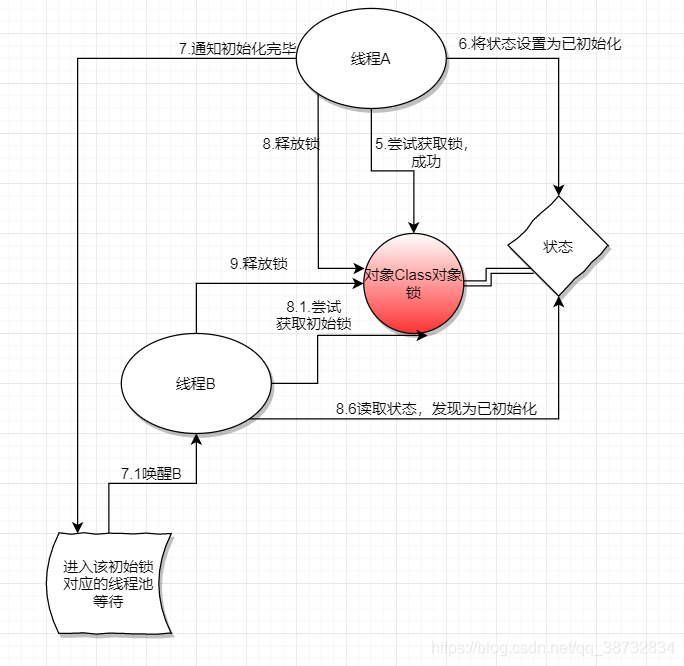
如果这时有其他线程尝试初始化对象,就会发现状态为已初始化,这时其他线程的初始化工作直接完成,不会有二次访问和进池中等待的过程。
也就是说整个初始化流程大概可以分为三个角色。初始化的,一起尝试初始化的,初始化完全后尝试初始化的。