利用依存分析完成开放领域关系抽取
1 问题描述
对于大规模的自由文本内容,完成开放领域三元组的抽取。即在不知道文本内容存在什么关系的情况下,抽取各种各样的关系,以三元组的形式表示出来。就是说,我们的目标是星辰大海!!
这里推荐一篇有关开放关系抽取的研究综述,开放关系抽取研究综述 - Jet Hu的文章 - 知乎
2 依存分析介绍
具体学习可参考论文:基于依存分析的开放式中文实体关系抽取方法,下面只进行简单阐述。
目的
通过分析句子中各个成分之间的依赖关系,揭示句子的语法结构。依存句法认为句子的支配者是核心动词,识别句子中类似“主谓宾”、“定状补”这些语法成分。
示例
对“上海市公安局和上海海关缉私局成立联合专案组,迅速开展案件侦查。”进行依存分析。
涉及到的词性说明: ns地名 n名词 c连词 v动词 wp标点符号
涉及到的关系说明
HED :整个句子的核心是 成立
ATT : 定中关系 上海市公安局、上海海关、缉私局、联合专案组
COO:并列关系 公安局和海关 成立和开展
SBV:主谓关系 缉私局成立
LAD:左附加关系
ADV:状中结构 迅速开展
VOB:动宾短语 开展侦查
FOB:前置宾语 案件侦查
核心过程
- 借助哈工大的语言云平台pyltp对自由文本进行分词。
- 词性标注
- 命名实体识别
- 依存分析
- 三元组抽取
关系表述
状语* 动词+ 补语?宾语?
说明:状语出现0次或任意多次 动词出现1次或任意多次 补语和宾语出现0次或者1次
3 代码实现
代码链接:实例参考
以下主要是对这个代码进行调通和理解,能力有限,可能之后会根据自己的需求再进行调整吧!!!
步骤如下:
3.1 pyltp安装
参考了这篇博客:安装pyltp模块详细教程
操作步骤如下:
1、在conda中新建项目环境
注意此次pyltp安装是在Windows下的python安装,且python版本为3.6或3.5,具体不同可以参考上述博客,笔者环境是python3.6。
conda create -n py3.6 python=3.6
py3.6是环境的名字(可任意),为了区分python用的是3.6版本的采用了py3.6。
在命令行下进入环境
conda activate py3.6
2、下载相关wheels
链接:https://pan.baidu.com/s/1qy1xrJzM6CGh9aaaMva6Lg
提取码:w0m1
把下载好的文件放在指定目录下,我放在了命令行的指定目录下,
执行安装命令:
pip install pyltp-0.2.1-cp36-cp36m-win_amd64.whl
3、模型下载
下载模型即可(ltp_data_v3.4.0.zip),LTP模型下载地址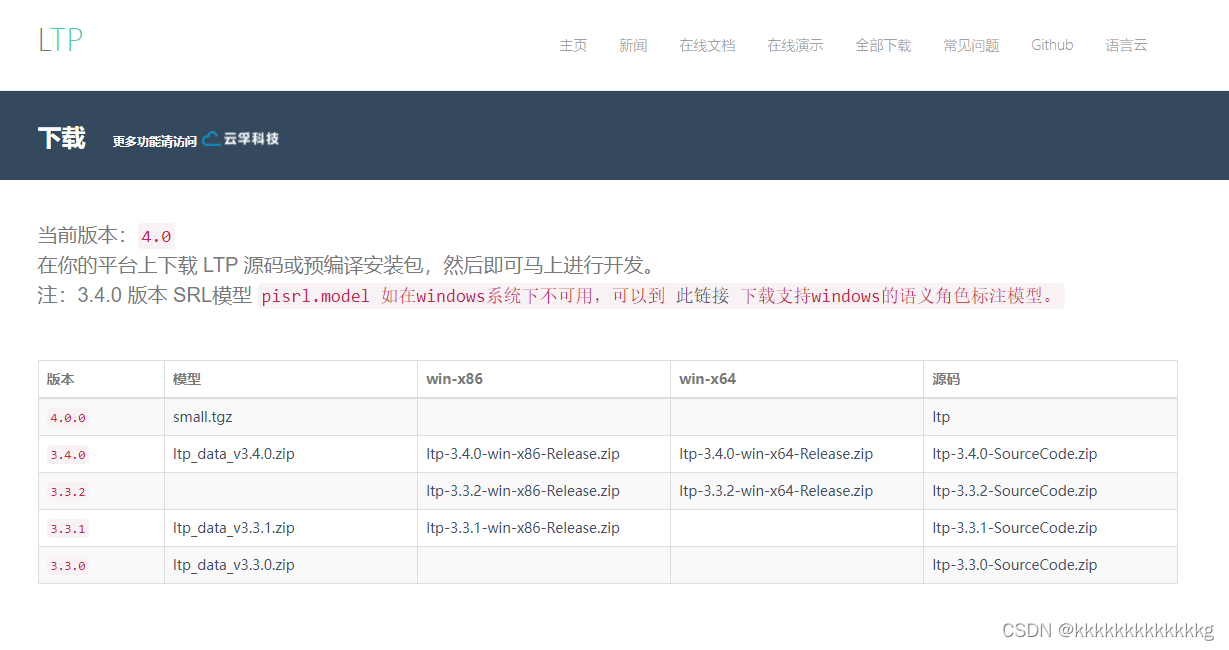
注意页面提示!!!!尤其是3.4.0版本的模型!!!
把下载好的模型放在自己的项目里。
3.2 相关代码
代码下载下来基本不用修改,只需要将输入文本文件换成自己的。
下面是fact_triple_extraction.py,我将自己的理解写在了代码行的注释里。
一点需要注意的是:
Python 3.X 里不包含 has_key() 函数,被 __contains__(key) 替代
# 修改成3.1中的第三步模型的安装路径
MODELDIR="E:\PycharmProjects\\fact_triple_extraction-master\ltp_data_v3.4.0"
import sys
import os
from pyltp import Segmentor, Postagger, Parser, NamedEntityRecognizer
print("正在加载LTP模型... ...")
# cws.model 分词模型 pos.model 词性标注模型 parser.model 依存句法分析模型 ner.model 命名实体识别模型
segmentor = Segmentor()
segmentor.load(os.path.join(MODELDIR, "cws.model"))
postagger = Postagger()
postagger.load(os.path.join(MODELDIR, "pos.model"))
parser = Parser()
parser.load(os.path.join(MODELDIR, "parser.model"))
recognizer = NamedEntityRecognizer()
recognizer.load(os.path.join(MODELDIR, "ner.model"))
print("加载模型完毕。")
# 这里的输入文件改成自己的数据 输出文件自己指定
in_file_name = "input.txt"
out_file_name = "output.txt"
begin_line = 1
end_line = 0
# sys.argv是一个字符串的列表,包含了命令行的参数的列表,即可以使用命令行传递给程序参数
# 在命令行运行代码时,例如 python a.py b c d ,a.py是sys.argv[0],依次类推
if len(sys.argv) > 1:
in_file_name = sys.argv[1]
if len(sys.argv) > 2:
out_file_name = sys.argv[2]
if len(sys.argv) > 3:
begin_line = int(sys.argv[3])
if len(sys.argv) > 4:
end_line = int(sys.argv[4])
# 定义三元组抽取的总方法 参数为(输入文件,输出文件,读取文件的起始行,读文件的终止行)
def extraction_start(in_file_name, out_file_name, begin_line, end_line):
# 这里源代码是‘r’, 运行会报错,改成‘rb’
in_file = open(in_file_name, 'rb')
out_file = open(out_file_name, 'a')
line_index = 1
sentence_number = 0
# 按行读取输入文件
text_line = in_file.readline()
while text_line:
# 循环条件 保证操作的行在开始行和结束行之间
if line_index < begin_line:
text_line = in_file.readline()
line_index += 1
continue
if end_line != 0 and line_index > end_line:
break
# .strip()方法用于移除字符串头尾指定的空格和换行符
sentence = text_line.strip()
# 分析的句子长度在0-1000之间
if sentence == "" or len(sentence) > 1000:
text_line = in_file.readline()
line_index += 1
continue
try:
# 调用三元组抽取方法
fact_triple_extract(sentence, out_file)
# out_file.flush() 将缓冲区的数据立刻写入文件,同时清空缓冲区
out_file.flush()
except:
pass
sentence_number += 1
if sentence_number % 5 == 0:
print("%d done" % (sentence_number))
text_line = in_file.readline()
line_index += 1
in_file.close()
out_file.close()
def fact_triple_extract(sentence, out_file):
"""
对于给定的句子进行事实三元组抽取
Args:
sentence: 要处理的语句
"""
# words是对每个句子进行分词后的结果,words类型是<class 'pyltp.VectorOfString'>
words = segmentor.segment(sentence)
#print(type(words))
#print("\t".join(words)) 这行语句可以看到分词结果长什么样子
postags = postagger.postag(words) # 词性标注
netags = recognizer.recognize(words, postags) # 命名实体识别
arcs = parser.parse(words, postags) # 句法分析
# print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs)) 句法分析的结果具体表示的是句子中的结构,如主谓宾SBV ,具体可以自己查询
# 为句子中的每个词维护一个保存句法依存儿子节点的字典
child_dict_list = build_parse_child_dict(words, postags, arcs)
# 遍历词性标注列表,以动词为核心,抽取三元组
for index in range(len(postags)):
if postags[index] == 'v':
child_dict = child_dict_list[index]
# SBV主谓关系 VOB动宾关系
if child_dict.__contains__('SBV') and child_dict.__contains__('VOB'):
e1 = complete_e(words, postags, child_dict_list, child_dict['SBV'][0])
r = words[index]
e2 = complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
print(e1)
out_file.write("主语谓语宾语关系\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()
# 定语后置,动宾关系
if arcs[index].relation == 'ATT':
if child_dict.__contains__('VOB'):
e1 = complete_e(words, postags, child_dict_list, arcs[index].head - 1)
r = words[index]
e2 = complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
temp_string = r+e2
if temp_string == e1[:len(temp_string)]:
e1 = e1[len(temp_string):]
if temp_string not in e1:
out_file.write("定语后置动宾关系\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()
# 含有介宾关系的主谓动补关系
if child_dict.__contains__('SBV') and child_dict.__contains__('CMP'):
#e1 = words[child_dict['SBV'][0]]
e1 = complete_e(words, postags, child_dict_list, child_dict['SBV'][0])
cmp_index = child_dict['CMP'][0]
r = words[index] + words[cmp_index]
if child_dict_list[cmp_index].__contains__('POB'):
e2 = complete_e(words, postags, child_dict_list, child_dict_list[cmp_index]['POB'][0])
out_file.write("介宾关系主谓动补\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()
# 尝试抽取命名实体有关的三元组
if netags[index][0] == 'S' or netags[index][0] == 'B':
ni = index
if netags[ni][0] == 'B':
while netags[ni][0] != 'E':
ni += 1
e1 = ''.join(words[index:ni+1])
else:
e1 = words[ni]
if arcs[ni].relation == 'ATT' and postags[arcs[ni].head-1] == 'n' and netags[arcs[ni].head-1] == 'O':
r = complete_e(words, postags, child_dict_list, arcs[ni].head-1)
if e1 in r:
r = r[(r.index(e1)+len(e1)):]
if arcs[arcs[ni].head-1].relation == 'ATT' and netags[arcs[arcs[ni].head-1].head-1] != 'O':
e2 = complete_e(words, postags, child_dict_list, arcs[arcs[ni].head-1].head-1)
mi = arcs[arcs[ni].head-1].head-1
li = mi
if netags[mi][0] == 'B':
while netags[mi][0] != 'E':
mi += 1
e = ''.join(words[li+1:mi+1])
e2 += e
if r in e2:
e2 = e2[(e2.index(r)+len(r)):]
if r+e2 in sentence:
out_file.write("人名//地名//机构\t(%s, %s, %s)\n" % (e1, r, e2))
out_file.flush()
# 为句子中的每个词维护一个保存句法依存儿子节点的字典 参数:words: 分词列表 postags: 词性列表arcs: 句法依存列表
def build_parse_child_dict(words, postags, arcs):
child_dict_list = []
# 一句话的每一个词依存父节点id,参照本篇第2节的示例,ROOT是0,词语从1开始编号
for index in range(len(words)):
child_dict = dict() # 每个词语与其他词语的关系字典
# arc_index==0时,表示ROOT
for arc_index in range(len(arcs)):
# arcs[arc_index].head表示arcs[arc_index]所代表的词语依存弧的父节点的索引
if arcs[arc_index].head == index
if child_dict.__contains__(arcs[arc_index].relation):
# arcs[arc_index].relation表示依存弧的关系
# 添加 child_dict = {'ATT': [4]}----> child_dict = {'ATT': [4, 5]} 与当前词语依存关系是ATT的有词语4和5
child_dict[arcs[arc_index].relation].append(arc_index)
else:
# 新建依存关系字典
child_dict[arcs[arc_index].relation] = []
child_dict[arcs[arc_index].relation].append(arc_index)
child_dict_list.append(child_dict)
return child_dict_list
# 对描述进行补充
def complete_e(words, postags, child_dict_list, word_index):
child_dict = child_dict_list[word_index]
prefix = '' # 前缀加上定语描述,即与词语是ATT依存关系的词语
if child_dict.__contains__('ATT'):
for i in range(len(child_dict['ATT'])):
prefix += complete_e(words, postags, child_dict_list, child_dict['ATT'][i])
postfix = '' # 后缀加上宾语
# 补充关系描述 加上主语、宾语?这里不是很清楚
if postags[word_index] == 'v':
if child_dict.__contains__('VOB'):
postfix += complete_e(words, postags, child_dict_list, child_dict['VOB'][0])
if child_dict.__contains__('SBV'):
prefix = complete_e(words, postags, child_dict_list, child_dict['SBV'][0]) + prefix
return prefix + words[word_index] + postfix
if __name__ == "__main__":
extraction_start(in_file_name, out_file_name, begin_line, end_line)
大概理解就这么多。结束!