前言
- 在工作中当我们使用了性能较差的CPU时,总会发现其软中断很容易偏高。
这是因为当软中断事件的频率过高时,由于CPU使用率偏高而导致内核线程的软中断处理不及时,从而引发网络收发延迟、调度缓慢等性能问题。其实,软中断CPU使用率过高也是一种最常见的性能问题,因此才需要我们做一些调优的方法,以便更合理的使用CPU来进行工作。 - 声明:以下所有展示的图片,都是经过性能调优后给出的(Linux默认软中断只绑定到CPU0处理)。
一、什么是中断?
- 在解决软中断偏高的问题之前,我们先来简单的了解一下中断的概念的吧。顾名思义,“中断”就是字面意思,是指CPU在执行某一项工作时突然被其他事情打断而被迫处理优先级更高的事务。比如,当你在愉快的享受假期时突然被领导强制要求回公司加班赶项目,而你此时不得不做出停止休假并赶回去加班的决定,这个过程就叫做中断。
- LInux 中断是一种异步的事件处理机制,用来提高系统的并发处理能力。中断事件的发生会触发执行中断处理程序,而中断处理程序被分为上半部和下半部两个部分:
1、上半部对应硬中断,用来快速处理中断
2、下半部对应软中断,用来异步处理上半部未完成的工作 - Linux软中断包括网络收发、定时、调度、RCU 锁等各种类型,可以通过查看 /proc/softirqs 观察软中断的运行情况。
- Linux默认每个CPU都对应一条软中断内核进程,进程名是:ksoftirqd/n(n等于cpu编号。例如:ksoftirqd/0, ksoftirqd/1, …)。
- ksofttrip是一直循环运行的,只要系统发生了软中断,哪个CPU空闲了它就会去获取来处理。
二、如何查看系统运行以来的累积中断次数?
软中断CPU使用率(softirq)升高是一种很常见的性能问题。虽然软中断的类型很多,但多数情况下网络收发产生的软中断才是性能的瓶颈。那么,怎样查看CPU的软中断次数呢?

方法一:
可通过 /proc/softirqs 观察软中断的运行情况:# watch -d cat /proc/softirqs /* 定期查看中断次数变化 */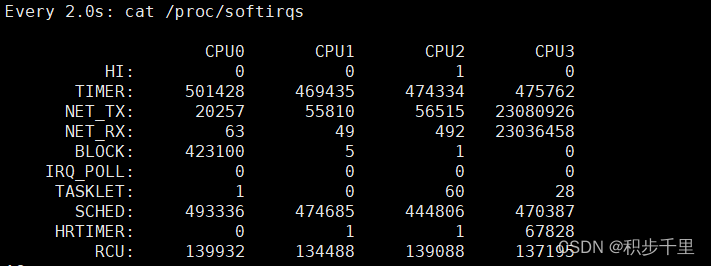
通过上边的 /proc/softirqs 内容变化情况来看:
发现 TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁) 等这几个软中断都在不断的变化。
其中,NET_RX 网络数据包接收软中断的变化速率是最快的,而其他几种类型的软中断有一定的变化是正常的,因为它们是保证Linux调度、时钟和临界区保护等正常工作所必需的。方法二:
# cat /proc/interrupts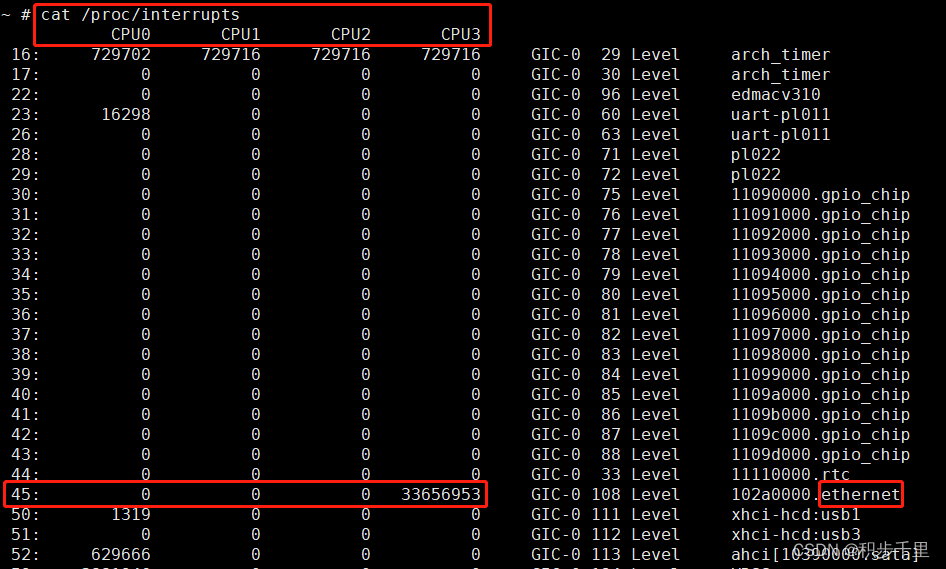
其中,可以看出
信号量:45 ethernet网卡软中断过高,为什么会这样呢?这是因为当网卡收到数据包时会产生中断,通知内核有新数据包,然后内核调用中断处理程序进行响应,把数据包从网卡缓存拷贝到内存。
三、CPU软中断性能调优
- Linux默认情况下,所有网卡的软中断都是由CPU0来处理的,当你发现 ksoftrip/0 总是占比很高,说明可能是网卡问题了。
- 通过以上方法分析软中断的产生原因,会发现确实是网络接收的软中断过高导致的CPU性能下降,那么如何调优呢?
- 要想优化,必须先确认你的网卡是多通道队列的。如何确认网卡是否为多队列的呢? 查看网卡通道队列的数量方式:
# cat /proc/interrupts | grep ethernet | wc -l注意:当队列数量 > 1,才说明你的网卡是支持多通道队列的
方法1:smp irq affinity技术
smp irq affinity技术,也称为信号量分布技术,就是把特定信号量的处理放到固定的CPU上,每个网卡的通道队列都有一个自己的信号量(
如下图的 ethernet网卡,对应了信号量45)。查看网卡通道队列的信号量方法:cat /proc/interrupts | grep ethernet
*注意: 不同的Linux平台网卡名称不一定相同。比如我的网卡名是ethernet,而有的平台又是eth0,或者名命为其他的。如果是实在不知自己的网卡名称,直接通过 cat /proc/interrupts 查看通道队列的信号量亦可。当我们知道了网卡信号量"num"后,就可以开始信号量进行绑定了,在 /proc/irq/num/ 下面有两个文件分别是 smp_affinity 和 smp_affinity_list。 smp_affinity是通过bitmask算法绑定CPU的,smp_affinity_list则是通过数字指定CPU编号的。
均衡配置: 将网络收发数据导致过高的软中断均摊到各个CPU来承担,以达到CPU整体性能提升的目的。使用以下任意一种绑定方法均可(以4核CPU为例):1. smp_affinity:
# echo f > /proc/irq/45/smp_affinity2. smp_affinity_list:
# echo 0-3 > /proc/irq/45/smp_affinity_list
方法2:RPS/RFS技术
RPS 全称是 Receive Packet Steering,这是Google工程师 Tom Herbert (therbert@google.com )提交的内核补丁,在2.6.35进入Linux内核。这个patch采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载,把软中断分到各个CPU处理,而不需要硬件支持,大大提高了网络性能。
RFS 全称是 Receive Flow Steering,这也是Tom提交的内核补丁,它是用来配合RPS补丁使用的,是RPS补丁的扩展补丁,它把接收的数据包送达应用所在的CPU上,提高cache的命中率。
通俗点来说,单个网卡通道队列的软中断会平均到所有CPU上,中断会发生在处理数据包的那个CPU上,从而节省了cpu cache。
那么如何配置RPS/RFS呢?
(以4核CPU为例):1. 配置RPS,如果CPU核数是4个,可以设置成 f:
# echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus2. 配置内核参数 rps_sock_flow_entries(官方文档推荐设置:N=32768):
# echo 32768 > /proc/sys/net/core/rps_sock_flow_entries3. 配置 rps_flow_cnt,单队列网卡可设置成 rps_sock_flow_entries(N=32768):
# echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt特别说明:
eth0:网卡设备(可能多个)
rx-0:接收队列(可能多个)
N:如果是多队列网卡,那么就按照队列数量设置成: N = rps_sock_flow_entries / 接收队列的数量
接收队列数量查看:cat /proc/interrupts | grep ethernet | wc -l配置后效果展示,每个CPU都能接收软中断:

四、经验总结
- 如果是多队列网卡性能调优,优先推荐使用方法1。
- 如果是单网卡队列性能调优,优先推荐使用方法2(因为RPS/RFS能模拟多网卡工作)。
- 另外说明一点,如果方法1和方法2都不能达到理想效果,也可以尝试将网卡软中断单独绑定到固定的一个CPU上处理,因为这样也可以提高cpu cache的命中率,从而达到提升CPU整体性能的目的。