分类算法
1. 简介
- 10 种监督学习简介
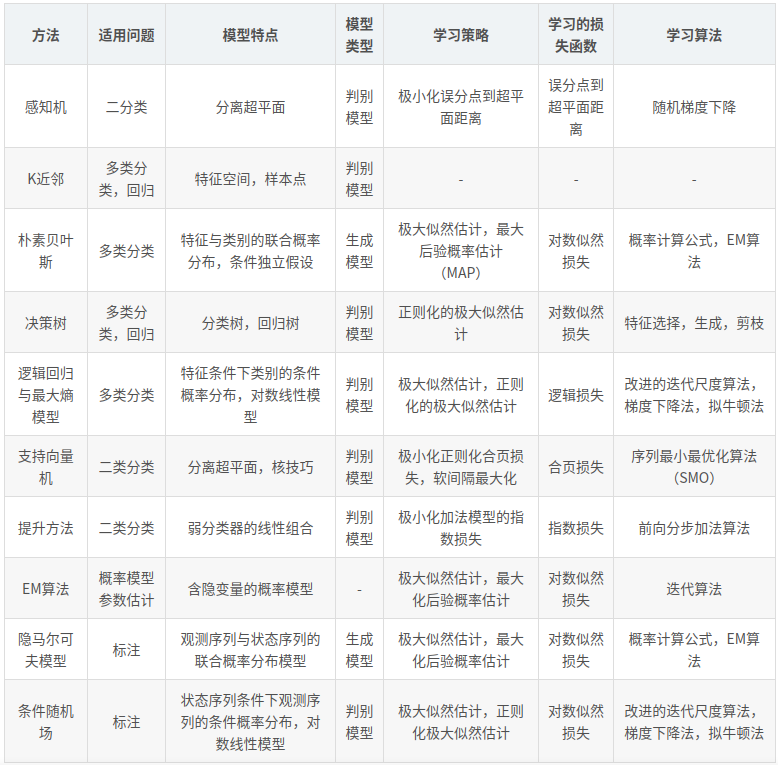
- 按问题类型分类:
(1)简单分类方法:感知机、k 近邻法、朴素贝叶斯法、决策树。
(2)复杂分类方法:逻辑回归模型、最大熵、支持向量机、提升方法。
(3)标注方法:隐马尔科夫模型、条件随机场
- 概率模型和非概率模型:
(1)概率模型(由条件概率表示的模型):朴素贝叶斯、隐马尔科夫模型。
(2)非概率模型(由决策函数表示的模型):感知机、k近邻、支持向量机、提升方法。
(3)概率模型和非概率模型:决策树、逻辑回归模型、最大熵模型、条件随机场。
- 线性模型和非线性模型:
(1)线性模型:感知机
(2)对数线性模型:逻辑回归模型、最大熵模型、条件随机场
(3)非线性模型:k 近邻、决策树、支持向量机(核函数)、提升方法
- 监督学习模型特点
(1)最近邻:适用于小型数据集,是很好的基准模型,很容易解释
(2)线性模型:非常可靠的首选算法,适用于非常大的数据集,也适用于高维数据。
(3)朴素贝叶斯:只适用于分类问题,适用于非常大的数据集和高维数据
[1] 对比线性模型:速度快,精度通常低。
(4)决策树:速度很快,不需要数据缩放,可以可视化,很容易解释
(5)随机森林:鲁棒性很好,不需要数据缩放。不适用于高维稀疏数据
(6)梯度提升决策树:训练速度慢,预测速度快,所需内存少
(7)支持向量机:适用于特征含义相似的中等大小数据集,需要数据缩放,参数敏感
(8)神经网络:可以构建非常复杂的模型,特别是对于大型数据集而言。
[1] 大型网络需要很长训练时间
[2] 数据缩放敏感,参数选取敏感。
- 生成模型和判别模型:
(1)判别模型(直接学习条件概率分布P(Y|X)或者决策函数Y=f(X)):感知机,k 近邻,决策树,逻辑回归模型,最大熵模型,支持向量机,提升方法,条件随机场。
(2)生成模型(先学习联合概率分布 P(X,Y),从而求得条件概率分布P(Y∣X)):朴素贝叶斯,隐马尔科夫模型。
2. k 近邻算法,kNN
- 采用测量不同特征值之间的距离方法进行分类
(1)只选择样本数据集中前k个最相似的数据,这就是 k-近邻算法中k的出处,通常k<20;
(2)选择k个最相似数据中出现次数最多的分类,作为新数据的分类;
(3)适用数据范围:数值型和标称型;
- 优缺点
(1)优点:精度高、对异常值不敏感、无数据输入假定。
(2)缺点:计算复杂度高、空间复杂度高,无法给出数据的内在含义。
- 对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的 k 个点;
(4)确定前 k 个点所在类别的出现频率;
(5)返回前 k 个点出现频率最高的类别作为当前点的预测分类。
2.1 sample code(基于mimist手写数字数据集)
import numpy as np
import struct
from numpy import *
import operator
import matplotlib.pyplot as plt
from os import listdir
feature_num = 3
dataSetNum = 1000
"""
训练集文件 60000个
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit int 0x00000803(2051) magic number
0004 32 bit int 60000 number of images
0008 32 bit int 28 number of rows
0012 32 bit int 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
"""
train_images_idx3_ubyte_file = 'MNIST_data/train-images.idx3-ubyte'
"""
训练集标签文件
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit int 0x00000801(2049) magic number (MSB first)
0004 32 bit int 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
"""
train_labels_idx1_ubyte_file = 'MNIST_data/train-labels.idx1-ubyte'
# 测试集文件 10000个
test_images_idx3_ubyte_file = 'MNIST_data/t10k-images.idx3-ubyte'
# 测试集标签文件
test_labels_idx1_ubyte_file = 'MNIST_data/t10k-labels.idx1-ubyte'
"""
解析idx3文件的通用函数
param idx3_ubyte_file: idx3文件路径
return: 数据集
"""
def decode_idx3_ubyte(idx3_ubyte_file):
bin_data = open(idx3_ubyte_file, 'rb').read() # 读取二进制数据
# 解析文件头信息,依次为魔数、图片数量、每张图片高、每张图片宽
offset = 0
fmt_header = '>iiii' #因为数据结构中前4行的数据类型都是32位整型,所以采用i格式,但我们需要读取前4行数据,所以需要4个i。我们后面会看到标签集中,只使用2个ii。
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, offset)
if 1:
num_images = dataSetNum
print('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
# 解析数据集
image_size = num_rows * num_cols
offset += struct.calcsize(fmt_header) #获得数据在缓存中的指针位置,从前面介绍的数据结构可以看出,读取了前4行之后,指针位置(即偏移位置offset)指向0016。
fmt_image = '>' + str(image_size) + 'B' #像素值类型:unsigned char,format格式为B, 784是读取784个B格式数据,如没有则只会读取一个像素值
print(fmt_image, offset, struct.calcsize(fmt_image))
images = np.empty((num_images, num_rows* num_cols))
for i in range(num_images):
if (i + 1) % 10000 == 0:
print('已解析 %d, offset:%d' % (i + 1, offset))
images[i] = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((1, 784))
offset += struct.calcsize(fmt_image)
return images
"""
解析idx1文件的通用函数
:param idx1_ubyte_file: idx1文件路径
:return: 数据集
"""
def decode_idx1_ubyte(idx1_ubyte_file):
# 读取二进制数据
bin_data = open(idx1_ubyte_file, 'rb').read()
offset = 0
fmt_header = '>ii'
magic_number, num_images = struct.unpack_from(fmt_header, bin_data, offset)
if 1:
num_images = dataSetNum
print('魔数:%d, 图片数量: %d张' % (magic_number, num_images))
# 解析数据集
offset += struct.calcsize(fmt_header)
fmt_image = '>B'
labels = np.empty(num_images)
for i in range(num_images):
if (i + 1) % 10000 == 0:
print('已解析 %d, offset:%d' % (i + 1, offset))
labels[i] = struct.unpack_from(fmt_image, bin_data, offset)[0]
offset += struct.calcsize(fmt_image)
return labels
"""
:param idx_ubyte_file: idx文件路径
:return: n*row*col维np.array对象,n为图片数量
"""
def load_train_images(idx_ubyte_file=train_images_idx3_ubyte_file):
return decode_idx3_ubyte(idx_ubyte_file)
"""
:param idx_ubyte_file: idx文件路径
:return: n*1维np.array对象,n为图片数量
"""
def load_train_labels(idx_ubyte_file=train_labels_idx1_ubyte_file):
return decode_idx1_ubyte(idx_ubyte_file)
def load_test_images(idx_ubyte_file=test_images_idx3_ubyte_file):
return decode_idx3_ubyte(idx_ubyte_file)
def load_test_labels(idx_ubyte_file=test_labels_idx1_ubyte_file):
return decode_idx1_ubyte(idx_ubyte_file)
def classify0 (inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
#计算欧氏距离
diff1 = tile(inX, (dataSetSize,1)) - dataSet
diff2 = diff1**2
diff3 = diff2.sum(axis=1)
diff4 = diff3**0.5
diff = diff4.argsort()
classCount={}
#选择最小的距离
for i in range (k):
voteIlabel = labels[diff[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#排序
sortedClassCount = sorted( classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def handwritingClassTest():
train_images = load_train_images()
train_labels = load_train_labels()
test_images = load_test_images()
test_labels = load_test_labels()
#初始化错误计数
errorCount = 0.0
mTest = len(test_labels)
for i in range(mTest):
classifierResult = classify0(test_images[i], train_images, train_labels, feature_num)
print("the classifier came back with: %d, the real answer is: %d" %(classifierResult, test_labels[i]))
if (classifierResult != test_labels[i]): errorCount += 1.0
print("\nthe total number of errors is: %d, error rate is: %f" % (errorCount, (errorCount/float(mTest))))
if __name__ == '__main__':
if 1:
handwritingClassTest()
else:
train_images = load_train_images()
train_labels = load_train_labels()
test_images = load_test_images()
test_labels = load_test_labels()
# 查看前几个数据及其标签以读取是否正确
for i in range(2):
print(test_labels[i])
image_array=np.array(test_images[i]).reshape(28,28)
plt.imshow(image_array, cmap='gray')
plt.pause(0.000001)
plt.show()
print('done')
3. 决策树
- 通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。
(1)决策树的典型算法有ID3,C4.5,CART等
(2)适用数据范围:数值型和标称型;
- 优缺点
(1)优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
(2)缺点:可能会产生过度匹配问题。
- 决策树构造:
(1)特征的选择:划分数据集
[1] 划分数据集原则:通过信息增益将无序的数据变得更加有序
(2)决策树的生成:由训练样本集生成决策树的过程。
(3)决策树的剪枝:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程
[1] 主要是用测试数据集中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除。
3.1 重要概念
- 熵(Ent):表示随机变量不确定性的度量
(1)当数据量一致时,系统越有序/集中,熵值越低;系统越混乱或者分散,熵值越高。
(2)熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大
(3)当熵的概率由数据估计得到时,所对应的熵称为经验熵,
- 信息增益:以某特征划分数据集前后的熵的差值,信息增益 = entroy(前) - entroy(后)
(1)信息增益越大,熵被消除,不确定性越小,有更强的分类能力,应作为最优特征
3.2 sample code
from math import log
def creatDataSet():
# 数据集
dataSet=[
[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
#分类属性
labels=['年龄','有工作','有自己的房子','信贷情况']
return dataSet,labels
# 计算给定数据集的经验熵
def calcShannonEnt(dataSet):
numEntries=len(dataSet) # 数据集个数,行数
print("numEntries: ", numEntries)
labelCounts={} #保存每个标签出现次数的字典
#对每组特征向量进行统计
for featVec in dataSet:
currentLabel=featVec[-1] #提取标签信息
if currentLabel not in labelCounts.keys(): #如果标签没有放入统计次数的字典,添加进去
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 # label计数
print("labelCounts:", labelCounts)
shannonEnt=0.0 # 经验熵
#计算经验熵
for key in labelCounts:
prob=float(labelCounts[key])/numEntries # 选择该标签的概率
shannonEnt-=prob*log(prob,2) # 利用公式计算
print("key:", key, ",\t shannonEnt 经验熵:", shannonEnt)
return shannonEnt # 返回经验熵
# 选择最优特征
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 # 特征数量
print("numFeatures:", numFeatures)
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最优特征的索引值
#遍历所有特征
for i in range(numFeatures):
featList = [example[i] for example in dataSet] # 获取dataSet的第i个所有特征
print("featList:", featList)
uniqueVals = set(featList) # 创建set集合{},去掉重复元素
print("uniqueVals:", uniqueVals)
newEntropy = 0.0 # 经验条件熵
#计算信息增益
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
print("subDataSet:", subDataSet)
prob = len(subDataSet) / float(len(dataSet)) # 计算子集的概率
#根据公式计算经验条件熵
newEntropy += prob * calcShannonEnt((subDataSet))
print("newEntropy:", newEntropy )
infoGain = baseEntropy - newEntropy
print("第%d个特征的增益为%.3f" % (i, infoGain)) # 打印每个特征的信息增益
#计算信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain # 更新信息增益,找到最大的信息增益
bestFeature = i # 记录信息增益最大的特征的索引值
return bestFeature
# 按照给定特征划分数据集
def splitDataSet(dataSet, axis, value):
retDataSet=[]
print("[splitDataSet] axis:", axis, " ,value:", value)
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
print("[splitDataSet] reducedFeatVec:", reducedFeatVec)
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
print("[splitDataSet] retDataSet:", retDataSet)
return retDataSet
if __name__=='__main__':
dataSet,features = creatDataSet()
print("最优索引值:"+str(chooseBestFeatureToSplit(dataSet)))
4. 朴素贝叶斯
- 基于贝叶斯定理与特征条件独立假设的分类方法,多用于文本分类,如垃圾邮件等
(1)结合先验概率和后验概率,即避免了只使用先验概率的主观偏见,也避免了单独使用样本信息的过拟合现象
(2)对于给定的训练集,首先基于特征条件独立假设 学习输入输出的联合概率分布;然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y。
(3)通过学习得到模型的机制,所以属于生成模型
(4)适用数据范围:标称型;
- 优缺点
(1)优点
[1] 适用于大的数据集,数据较少的情况下仍然有效
[2] 可以处理多类别问题。
[3] 有稳定的分类效率
[4] 适合增量式训练
(2)缺点
[1] 对于输入数据的准备方式较为敏感
[4] 如果分类变量具有在训练数据集中未观察到的类别,则模型将指定0概率并且将无法进行预测。
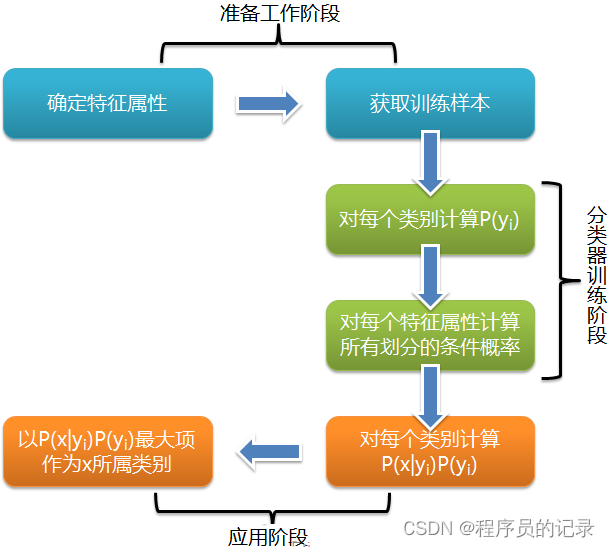
- 朴素贝叶斯流程:
(1)零概率问题
[1] 原因:对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,如果其中有一个为0,则最后的结果也为0。
[2] 解决方法:拉普拉斯平滑,将所有词的出现次数初始化为1,并将分母初始化为2
(2)下溢出
[1] 原因:太多很小的数相乘,越乘越小,造成下溢出。在相应小数位置进行四舍五入,计算结果可能就变成0了。
[2] 解决方法:对乘积结果取自然对数
- 算法对比
逻辑回归:通过拟合曲线实现分类
决策树:通过寻找最佳划分特征进而学习样本路径实现分类
支持向量机:通过寻找分类超平面进而最大化类别间隔实现分类
朴素贝叶斯:通过特征概率来预测分类
4.1 重要概念
- 先验概率 P(Y):事件发生前的预判概率。可以是基于历史数据的统计,可以由背景常识得出,也可以是人的主观观点给出
- 后验概率 P(Y∣X): 事件发生后求的反向条件概率
(1)后验概率的计算要以先验概率为基础
- 条件概率 / 似然概率 P(X∣Y) :一个事件发生后另一个事件发生的概率
4.2 sample code
import numpy as np
def loadDataSet():
dataSet=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] # 类别标签向量,1,侮辱性词汇,0,非侮辱性词汇
return dataSet,classVec
# 创建无重复词汇表
def createVocabList(dataSet):
vocabSet = set() # 创建一个空的集合
for doc in dataSet: # 遍历dataSet中的每一条言论
vocabSet = vocabSet | set(doc) # 取并集
vocabList = list(vocabSet)
return vocabList
# 根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0.
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则变为1
returnVec[vocabList.index(word)] = 1
else:
print(f" {word} is not in my Vocabulary!" )
return returnVec # 返回文档向量
def get_trainMat(dataSet):
trainMat = [] # 初始化向量列表
vocabList = createVocabList(dataSet) # 生成词汇表
for inputSet in dataSet: # 遍历样本词条中的每一条样本
returnVec=setOfWords2Vec(vocabList, inputSet) # 将当前词条向量化
trainMat.append(returnVec) # 追加到向量列表中
print("get_trainMat, trainMat:", trainMat)
return trainMat
def trainNB(trainMat,classVec):
n = len(trainMat) # 计算训练的文档数目
m = len(trainMat[0]) # 计算每篇文档的词条数
# 拉普拉斯平滑,将所有词的出现次数初始化为1,并将分母初始化为2
pAb = sum(classVec)/n # 文档属于侮辱类的概率
p0Num = np.ones(m) # 词条出现数初始化为1
p1Num = np.ones(m) # 词条出现数初始化为1
p0Denom = 2 # 分母初始化为2
p1Denom = 2 # 分母初始化为2
for i in range(n): # 遍历每一个文档
if classVec[i] == 1: # 属于侮辱类的条件概率所需的数据
p1Num += trainMat[i] # 每个词的数量
p1Denom += sum(trainMat[i]) # 词的总数
else: # 统计属于非侮辱类的条件概率所需的数据
p0Num += trainMat[i]
p0Denom += sum(trainMat[i])
p1V = np.log(p1Num/p1Denom) # 避免下溢出,对乘积结果取自然对数
p0V = np.log(p0Num/p0Denom)
return p0V,p1V,pAb # 返回属于非侮辱类,侮辱类和文档属于侮辱类的概率
def classifyNB(vec2Classify, p0V, p1V, pAb):
p1 = sum(vec2Classify * p1V) + np.log(pAb) # 对应元素相乘
p0 = sum(vec2Classify * p0V) + np.log(1- pAb) # 对应元素相乘
print("sum(vec2Classify * p1V):", sum(vec2Classify * p1V), "np.log(pAb):", np.log(pAb))
if p1 > p0:
return 1
else:
return 0
def testingNB(testVec):
dataSet,classVec = loadDataSet() # 创建实验样本
vocabList = createVocabList(dataSet) # 创建词汇表
trainMat= get_trainMat(dataSet) # 将实验样本向量化
p0V,p1V,pAb = trainNB(trainMat,classVec) # 训练朴素贝叶斯分类器
thisone = setOfWords2Vec(vocabList, testVec) # 测试样本向量化
if classifyNB(thisone, p0V, p1V, pAb)==1:
print(testVec,'属于侮辱类') # 执行分类并打印分类结果
else:
print(testVec,'属于非侮辱类') # 执行分类并打印分类结果
testVec1 = ['love', 'my', 'dalmation']
testingNB(testVec1)
testVec2 = ['stupid', 'garbage']
testingNB(testVec2)
5. Logistic 回归
- 分类模型,假设数据服从 Logistic 分布,使用极大似然估计做参数的估计,常用于二分类
(1)损失函数:可通过极大似然估计或交叉熵损失函数构建
(2)适用数据范围:数值型和标称型;
(3)sigmoid函数:h θ ( x ) = g ( θ T x ) h_\theta(x)=g(\theta^Tx)hθ(x)=g(θTx) = y = 1 1 + e − θ T x \frac{1}{1 + e^{-\theta^{T}x}}1+e−θTx1
[1] 自变量任意实数;值域 [0, 1], 预测值转为概率;
[2] θ 0 \theta_0θ0 + θ 1 \theta_1θ1x_1 + … + θ n \theta_nθnx_n= θ T x \theta^TxθTx
- 优缺点
(1)优点:
[1] 训练速度较快,分类时 计算量只和特征的数目相关;
[2] 简单易理解,模型的可解释性好
[3] 适合二分类问题,不需要缩放输入特征;
[4] 内存资源占用小,因为只需要存储各个维度的特征值;
(2)缺点:
[1] 特征空间很大时,性能不好。
[2] 数据特征有缺失或特征空间很大时效果不会很好
- 逻辑回归构造:
(1)先拟合决策边界
(2)建立边界与分类的概率联系,从而得到二分类情况下的概率。
5.1 重要概念
- P (x | θ \thetaθ) :x, 某一个具体的数据;θ \thetaθ, 模型的参数
(1)概率函数: θ \thetaθ 是已知确定,x 是变量,描述对于不同的样本点 x 出现的概率
(2)似然函数:x 是已知确定,θ \thetaθ 是变量,描述对于不同的模型参数,出现 x 样本点的概率
- 决策边界(决策面): 是用于在N维空间,将不同类别样本分开的平面或曲面。
(1)在逻辑回归中,决策边界由 θ T x \theta^{T}xθTx = 0 定义
(2)决策边界是假设函数的属性,由参数决定,而不是由数据集的特征决定。
- 逻辑回归模型 P ( Y = 1 ∣ x ) P(Y=1|x)P(Y=1∣x) = 1 1 + e − ( w T x + b ) \frac{1}{1 + e^{-(w^Tx+b)}}1+e−(wTx+b)1, Y是 x 为正例的概率
(1) l n ( o d d s ) ln(odds)ln(odds) = l n y 1 − y ln \frac{y}{1 - y}ln1−yy = w T x + b w^Tx + bwTx+b = l n P ( Y = 1 ∣ x ) 1 − P ( Y = 1 ∣ x ) ln \frac{P(Y=1|x)}{1 - P(Y=1|x)}ln1−P(Y=1∣x)P(Y=1∣x)
a. 将 Y 视为后验概率估计
(2)Odds (几率, 可能性): 指某事件发生的概率与不发生的概率之比,即 odds = p 1 1 − p 1 \frac{p_1}{1 - p_1}1−p1p1.
(3)当 w T x + b w^Tx+bwTx+b 的值越接近正无穷, P ( Y = 1 ∣ x ) P(Y=1|x)P(Y=1∣x) 概率值越接近 1
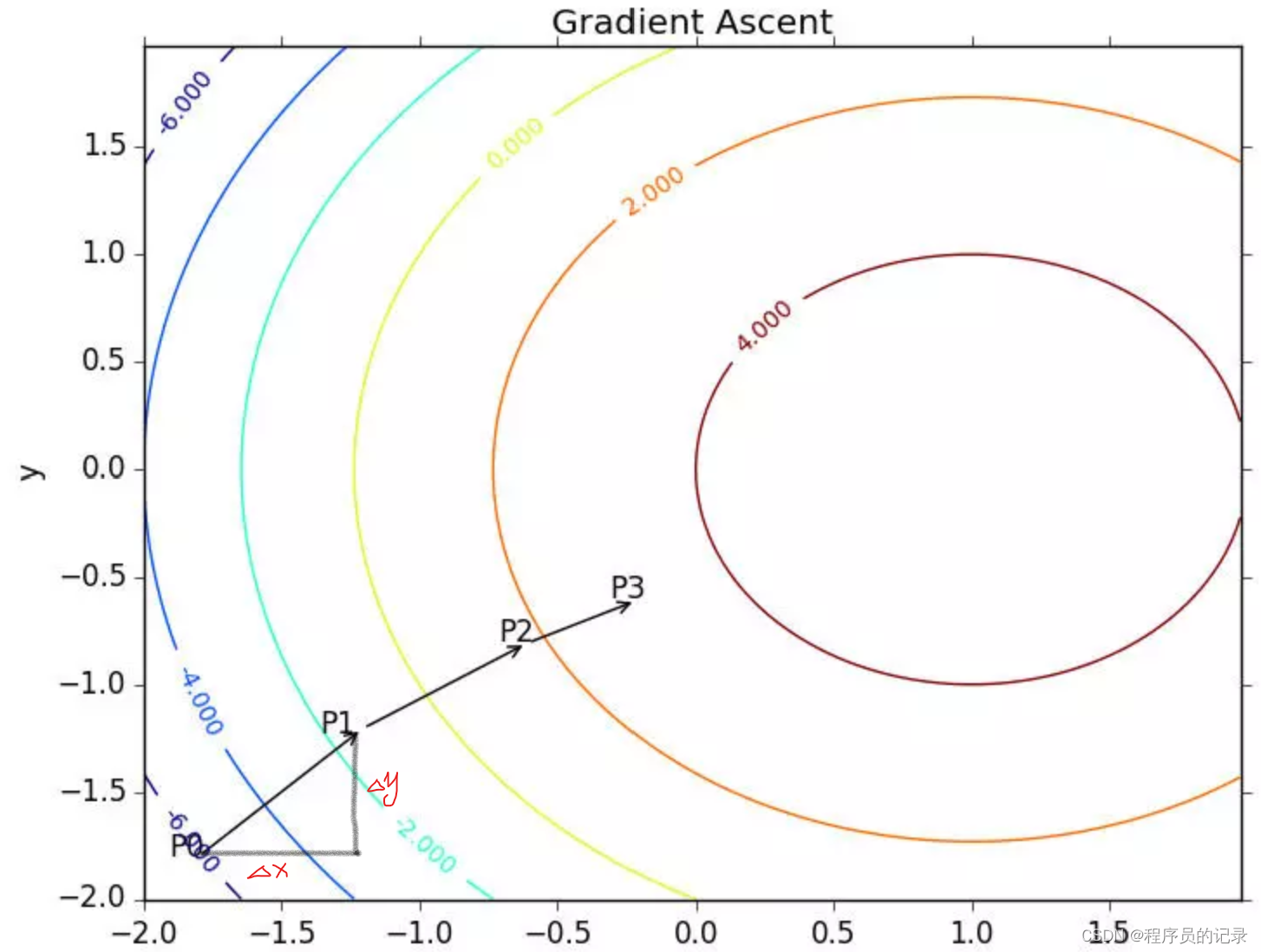
- 梯度上升法:找到函数最大值的最好方法,是沿着该函数的梯度方向探寻
(1)梯度:沿x的方向移动 ∂ f ( x , y ) ∂ x \frac{∂f(x,y)}{∂x}∂x∂f(x,y),沿y的方向移动 ∂ f ( x , y ) ∂ y \frac{∂f(x,y)}{∂y}∂y∂f(x,y),函数f(x,y)必须要在待计算的点上有定义并且可微
(2)梯度算子总是指向函数值增长最快的方向- 随机梯度下降:通过 J(w) 对 w 的一阶导数来找下降方向,并且以迭代的方式来更新参数
(1)J ( w ) J(w)J(w) = - 1 n \frac{1}{n}n1 (∑ 1 n ( y i l o g ( y ∗ ) + ( 1 − y i ) l o g ( 1 − y ∗ ) ) ) \sum_1^n(y_i log(y^*) + (1 - y_i)log(1 - y^*)))∑1n(yilog(y∗)+(1−yi)log(1−y∗)))
(2)g i g_igi = ∂ J ( w ) ∂ w i \frac{∂J(w)}{∂w_i}∂wi∂J(w) = ( P ( x i ) − y i ) x i (P(x_i) - y_i) x_i(P(xi)−yi)xi
(3)w i k + 1 w_i^{k+1}wik+1 = w i k w_i^{k}wik - α \alphaα * g i g_igi
sample code
# -*- coding:UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
import numpy as np
import random
""" y = -x^2 + 4x"""
def Gradient_Ascent_test():
def f_prime(x_old): #f(x)的导数
return -2 * x_old + 4
x_old = -1 #初始值,给一个小于x_new的值
x_new = 0 #梯度上升算法初始值,即从(0,0)开始
alpha = 0.01 #步长,也就是学习速率,控制更新的幅度
presision = 0.00001 #精度,也就是更新阈值
while abs(x_new - x_old) > presision:
x_old = x_new
x_new = x_old + alpha * f_prime(x_old) #上面提到的公式
print("max value trend to 2:", x_new)
""" 函数说明:加载数据 """
def loadDataSet():
dataMat = [] #创建数据列表
labelMat = [] #创建标签列表
fr = open('testSet.txt') #打开文件
for line in fr.readlines(): #逐行读取
lineArr = line.strip().split() #去回车,放入列表
# 1.0 对应 W0,X^T = (1, X1, X2, ...Xn); W = (W0, W1, ...Wn)
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #添加数据
labelMat.append(int(lineArr[2])) #添加标签
fr.close() #关闭文件
return dataMat, labelMat #返回
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
def error_rate(h, label_data):
''' 计算当前损失函数值: h, 预测值 '''
m = np.shape(h)[0]
sum_error = 0.0
for i in range(m):
if h[i, 0] > 0 and (1 - h[i, 0]) > 0:
# loss = -(ylog(y*) + (1 - y)log(1 - y*)), log 在(0,1)取值为负,为了使损失为正,所以在最前面加一个负号
sum_error -= (label_data[i, 0] * np.log(h[i, 0]) + \
(1 - label_data[i, 0]) * np.log(1 - h[i, 0]))
else:
sum_error -= 0
return sum_error / m
""" 函数说明:梯度上升算法 """
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
alpha = 0.001 #移动步长,也就是学习速率,控制更新的幅度。
maxCycles = 500 #最大迭代次数
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式, 100*3, 3*1
error = labelMat - h
# 权值修正, w(k+1) = w(k) - 学习率 * error * 特征值 = w(k) - alpha *(P(Xi)-Yi) * Xi
weights = weights + alpha * dataMatrix.transpose() * error
if k % 100 == 0:
print("train error rate = ", str(error_rate(h, label_data)), "w:", w)
print("weight:", weights)
return weights.getA() #将矩阵转换为数组,返回权重数组
""" 函数说明:改进的随机梯度上升算法 """
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
weights = np.ones(n) #参数初始化
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #降低alpha的大小,每次减小1/(j+i)。
randIndex = int(random.uniform(0,len(dataIndex))) #随机选取样本
h = sigmoid(sum(dataMatrix[dataIndex[randIndex]]*weights)) #选择随机选取的一个样本,计算h
error = classLabels[dataIndex[randIndex]] - h #计算误差
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]] #更新回归系数
del(dataIndex[randIndex]) #删除已经使用的样本
return weights
""" 函数说明:绘制数据集 """
def plotBestFit(weights):
dataMat, labelMat = loadDataSet() #加载数据集
dataArr = np.array(dataMat) #转换成numpy的array数组
n = np.shape(dataMat)[0] #数据个数
xcord1 = []; ycord1 = [] #正样本
xcord2 = []; ycord2 = [] #负样本
for i in range(n): #根据数据集标签进行分类
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) #1为正样本
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) #0为负样本
fig = plt.figure()
ax = fig.add_subplot(111) #添加subplot
ax.scatter(xcord1, ycord1, s = 20, c = 'red', marker = 's',alpha=.5)#绘制正样本
ax.scatter(xcord2, ycord2, s = 20, c = 'green',alpha=.5) #绘制负样本
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0] - weights[1] * x) / weights[2]
ax.plot(x, y)
plt.title('BestFit') #绘制title
plt.xlabel('X1'); plt.ylabel('X2') #绘制label
plt.show()
""" 函数说明:分类函数 """
def classifyVector(weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def save_model(file_name, w):
f_w = open(file_name, "w")
w_array = []
m = np.shape(w)[0]
for i in range(m):
w_array.append(str(w[i, 0]))
f_w.write("\t".join(w_array))
f_w.close()
if __name__ == '__main__':
print("---------- 0. 梯度趋近理解 ------------")
Gradient_Ascent_test()
print("---------- 1.load data ------------")
dataMat, labelMat = loadDataSet()
print("---------- 2.training LR model------------")
weights = gradAscent(dataMat, labelMat)
print("---------- 3.save model ------------")
save_model("weights", weights)
plotBestFit(weights)
weights = stocGradAscent1(np.array(dataMat), labelMat)
plotBestFit(weights)
参考信息
版权声明:本文为qq_25439881原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。