目录
9.2 判断是否是 NaN还是 None,.isnull()、.notnull()、.isna()、
9.2.1 .isnull() 和 .notnull() 使用方法,不区分 NaN 和 None值
9.2.2 .isna() 和 .notna() 使用方法,也不区分 NaN 和 None 值
9.2.4 Pandas 模块为什么很多函数不区分 np.NaN 和 None 值?
9.5 统计数据量大时统计 NaN 的个数 .isnul().sum().sum()
9.6 统计数据量大时统计非 NaN 的个数 .count().sum()
9. 分清楚 None 和 NaN 值,处理好 NaN
9.1 分清楚 None 和 NaN 值
9.1.1 Python 中特殊的常量 None
None 和 False 不同,它不表示 0,也不表示空字符串,而表示没有值,也就是空值。
可以看到,它就是 None 类型,也是 None 对象。


可以用 is,not is,或者 == 去判断某个值是不是 None。
9.1.2 numpy 模块引入的特殊常量 NaN
首先,numpy 模块中有三个常量 np.NAN 、np.nan 、np.NaN,这三个常量其实是一个东西。后面我们就只说 np.NaN 即可。

np.NaN 可以解释为 not a number,不是一个数字,但是它的类型却是一个 float 类型!

所以可以看出,None 和 np.NaN 类型就不一样!但是在 Pandas 模块中,有些地方他们都被视作表示空值,处理起来的结果也是一样的。
9.2 判断是否是 NaN还是 None,.isnull()、.notnull()、.isna()、
.notna() 都无效
9.2.1 .isnull() 和 .notnull() 使用方法,不区分 NaN 和 None值
.isnull() 和 .notnull() 是一对判断对象是不是丢失数据的函数,但是可惜的是它们不区分 NaN 和 None 值,对这两者的操作结果是一样的。
Help on function isna in module pandas.core.dtypes.missing:
isna(obj)
Detect missing values for an array-like object.
This function takes a scalar or array-like object and indicates
whether values are missing (``NaN`` in numeric arrays, ``None`` or ``NaN``
in object arrays, ``NaT`` in datetimelike).
Parameters
----------
obj : scalar or array-like
Object to check for null or missing values.
9.2.2 .isna() 和 .notna() 使用方法,也不区分 NaN 和 None 值
.isna() 和 .notna() 也是一对判断对象是不是丢失数据的函数,但是可惜的是它们不区分 NaN 和 None 值,对这两者的操作结果也是一样的。这对函数看起来和 .isnull() 和 .notnull() 用途是一样的。
Help on function isna in module pandas.core.dtypes.missing:
isna(obj)
Detect missing values for an array-like object.
This function takes a scalar or array-like object and indicates
whether values are missing (``NaN`` in numeric arrays, ``None`` or ``NaN``
in object arrays, ``NaT`` in datetimelike).
Parameters
----------
obj : scalar or array-like
Object to check for null or missing values.
Returns
-------
bool or array-like of bool
For scalar input, returns a scalar boolean.
For array input, returns an array of boolean indicating whether each
corresponding element is missing.
9.2.3 区分 np.NaN 和 None 值
区分 np.NaN 和 None 值,只能依靠 is,not 命令和 == 了。

9.2.4 Pandas 模块为什么很多函数不区分 np.NaN 和 None 值?
笔者思考过这个问题,很简单的说,大概这两个值含义是非常接近的,都是表示数据丢失。Pandas 主要做数据分析工作,既然这两者含义相同,也没有必要区分,徒然增加代码量。此外,如果真要区分,也可以按照 9.2.3 小节方式区分。
9.3 丢弃有 NaN 的数据项,.dropna()
9.3.1 .dropna() 语法
语法结构:DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:{0 or 'index', 1 or 'columns'},axis 默认为 0,即指删除行;axis 设置为 1,即删除列。
- how:值可以是'any' 或者 'all', 默认是 'any'。这个值决定了是根据一个 NaN 还是 所有 NaN 来删除行或者列。
- thresh:数值,可选,指达到多少个 非 NaN 才可以保留
- subset:可选。默认值是None。subset 的含义由 axis 来决定。例如 axis 是0 即删除行时候, subset 指定了考虑的列。
- inplace:布尔值,默认为 False。决定是否原地改变还是返回一个 None 。
备注:虽然标题是丢弃有 NaN 的数据项,但是.dropna() 中 np.NaN 和 None 是一样看待的。
Help on method dropna in module pandas.core.frame:
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) method of pandas.core.frame.DataFrame instance
Remove missing values.
See the :ref:`User Guide <missing_data>` for more on which values are
considered missing, and how to work with missing data.
Parameters
----------
axis : {0 or 'index', 1 or 'columns'}, default 0
Determine if rows or columns which contain missing values are
removed.
* 0, or 'index' : Drop rows which contain missing values.
* 1, or 'columns' : Drop columns which contain missing value.
.. versionchanged:: 1.0.0
Pass tuple or list to drop on multiple axes.
Only a single axis is allowed.
how : {'any', 'all'}, default 'any'
Determine if row or column is removed from DataFrame, when we have
at least one NA or all NA.
* 'any' : If any NA values are present, drop that row or column.
* 'all' : If all values are NA, drop that row or column.
thresh : int, optional
Require that many non-NA values.
subset : array-like, optional
Labels along other axis to consider, e.g. if you are dropping rows
these would be a list of columns to include.
inplace : bool, default False
If True, do operation inplace and return None.
Returns
-------
DataFrame or None
DataFrame with NA entries dropped from it or None if ``inplace=True``.9.3.2 .dropna() 范例
1)首先,.dropna() 不区分 NaN 和 None 值。看下面的结果就可以看出。
准备数据
dict_data={"a":list("abcdaaa"),"b":list("abfcccc"),"c":list("ggijggg")}
df=pd.DataFrame.from_dict(dict_data)
df2=df.reindex(["A",0,"B",1,"C",3])
df2# 此时 axis = 0, 即删除行
# how = 'any',即有一个 NaN 值就删除
# thresh 为空,未指定
# subset 为空
# inplace 为 False,即不原地改变数据
df2.dropna()
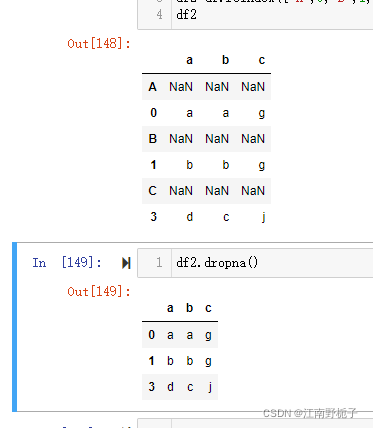
而修改 NaN 为 None后
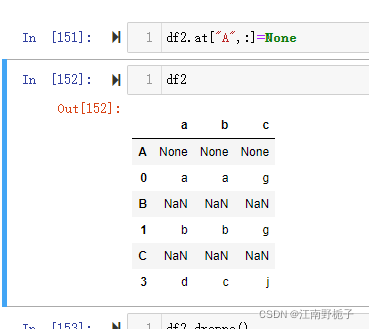
可以看到,无论是 None 还是 NaN,相应的行 都被删除了。
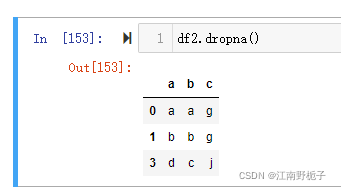
2)现在调整一下数据,再看

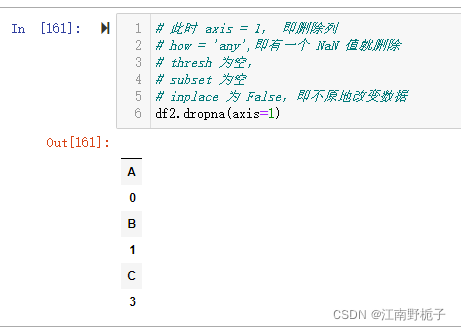
# 此时 axis = 1, 即删除列
# how = 'any',即有一个 NaN 值就删除
# thresh 为空,
# subset 为空
# inplace 为 False,即不原地改变数据
df2.dropna(axis=1)当 axis =1 时候,因为每列都有 NaN 或者 None 值,且此时 how = 'any',所以事实上将全部数据都删除了。
当 axis =1 时候,how = 'all', 即有所有都是 NaN 值才删除,没有符合条件的列,所以未删除。
# 此时 axis = 1, 即删除列
# how = 'all',即有所有都是NaN 值才删除
# thresh 为空,
# subset 为空
# inplace 为 False,即不原地改变数据
df2.dropna(axis=1,
how = 'all')
当 axis =0 时候,thresh 为 2,即有两个非 NaN 值才保留。
# 此时 axis = 0, 即删除行
# how = 'any',即有一个 NaN 值就删除
# thresh 为 2,即有两个非 NaN 值才保留
# subset 为空
# inplace 为 False,即不原地改变数据
df2.dropna(thresh = 2)
当 axis =1 时候,subset=['A'],即删除 ‘A’ 中有 NaN 值的列。
# 此时 axis = 1, 即删除列
# how = 'any ',即有一个 NaN 值就删除
# thresh 为空,
# subset 为‘A’,即检测 'A' 上数据是否有NaN
# inplace 为 False,即不原地改变数据
df2.dropna(axis=1,
subset = ['A'])
9.4 将 NaN 填充为其他值,.fillna()
9.4.1 .fillna() 语法
语法结构:DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
参数说明:
- value:用于填充丢失数据的值:可以是标量、dict、Series 或 DataFrame。不符合条件的 value 将不会被填充,例如列表 list 就不会被填充。(不同的数据类型意味着不同的填充方式,请注意!更详细的请看 9.4.2 范例)
- method:{默认 None,'backfill','bfill', 'pad', 'ffill'}, 用于在 DataFrame 中填充 NaN 值的方法。
1) None (default): 默认不做处理,由 value 来决定填充值。
2) pad / ffill: 将上一个有效值向前填充到下一个有效值。
3) backfill / bfill: 使用下一个有效值填充空白。
- axis:{0 or 'index', 1 or 'columns'}, 默认为 0,即沿着行进行填充,如果设置为 1 或者 'columns' 则沿着列进行填充。
- inplace:布尔值,默认为 False。决定是否原地填充还是返回一个副本。
- limit: int, 默认 None。向前或向后填充的连续元素的最大数量。
- downcast:字典数据,默认为 None。如果可能的话,一个item->dtype类型的命令,
或者字符串 “infer” 将尝试向下转换到适当的相同类型(如可能,从float64到int64)。
Help on method fillna in module pandas.core.frame:
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) -> 'Optional[DataFrame]' method of pandas.core.frame.DataFrame instance
Fill NA/NaN values using the specified method.
Parameters
----------
value : scalar, dict, Series, or DataFrame
Value to use to fill holes (e.g. 0), alternately a
dict/Series/DataFrame of values specifying which value to use for
each index (for a Series) or column (for a DataFrame). Values not
in the dict/Series/DataFrame will not be filled. This value cannot
be a list.
method : {'backfill', 'bfill', 'pad', 'ffill', None}, default None
Method to use for filling holes in reindexed Series
pad / ffill: propagate last valid observation forward to next valid
backfill / bfill: use next valid observation to fill gap.
axis : {0 or 'index', 1 or 'columns'}
Axis along which to fill missing values.
inplace : bool, default False
If True, fill in-place. Note: this will modify any
other views on this object (e.g., a no-copy slice for a column in a
DataFrame).
limit : int, default None
If method is specified, this is the maximum number of consecutive
NaN values to forward/backward fill. In other words, if there is
a gap with more than this number of consecutive NaNs, it will only
be partially filled. If method is not specified, this is the
maximum number of entries along the entire axis where NaNs will be
filled. Must be greater than 0 if not None.
downcast : dict, default is None
A dict of item->dtype of what to downcast if possible,
or the string 'infer' which will try to downcast to an appropriate
equal type (e.g. float64 to int64 if possible).
Returns
-------
DataFrame or None
Object with missing values filled or None if ``inplace=True``.9.4.2 .fillna() 范例
先准备好数据
dict_data={"a":list("abcdaaa"),"b":list("abfcccc"),"c":list("ggijggg")}
data=pd.DataFrame.from_dict(dict_data)
data=data.reindex(["A",0,"B",1,"C",3])
data 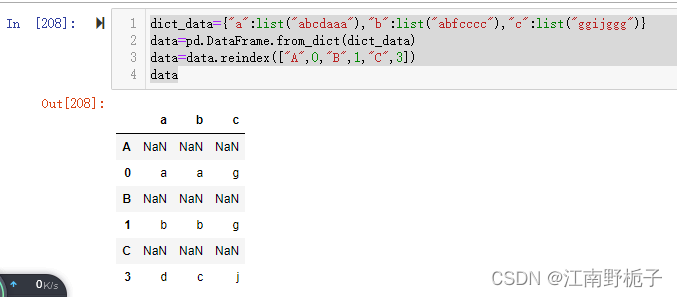
9.4.2.1 value
value 是标量的时候,在需要填充的地点填充该标量
data.fillna("to_fillna")运行结果

value 是字典的时候,指示某列填充某个特定的值
data.fillna({"a":"AAA","b":"BBB","c":"CCC"})
value 是 Series 的时候,指示按照 Series 中的元素值对某行或者某列进行填充
先准备 Series 数据,这时候准备的 series 是 根据 index 来的,所以在后面的代码运行后,没有发生数据填充
#备注,这时候准备的series 是 根据 index 来的
a_series=pd.Series(list(range(6)))
a_series.index=["A",0,"B",1,"C",3]
a_series
再准备的 Series 是按照 columns 的标识来的,这次代码运行后发生了数据填充,index 为 “a” 的 Series 元素 被填充到 DataFrame "a" 列 中。
#备注,这时候准备的series 是 根据 column 来的
b_series=pd.Series(list(range(3)))
b_series.index=["a","b","c"]
b_series
value 是DataFrame 的时候,指示按照 DataFrame 中相应位置进行填充
准备要填充的 DataFrame
data2=data.copy(deep=True)
data2.at["A","b"]="Ab"
data2.at["B","b"]="Bb"
data2
填充之后的结果可以看到,被填充的 DataFrame 数据来源于 value 指定的 DataFrame 所在位置的数值。
data.fillna(data2) 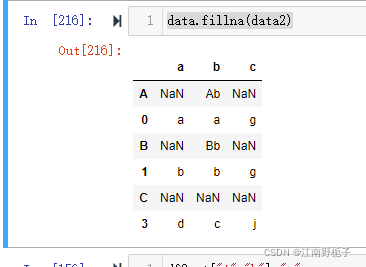
2)method 请参看 Pandas 模块-操纵数据(2)-重新索引-reindex()函数 中 method 的用法,非常雷同,不在赘述。
3)axis、limit、inplace 都和 .dropna() 中用法非常类似,不再赘述。
9.5 统计数据量大时统计 NaN 的个数 .isnul().sum().sum()
.isnul() 列出所有的 NaN 值
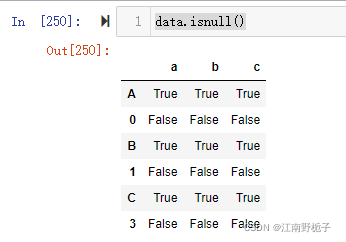
.isnul().sum() 按照列进行进行 sum 计算 NaN 数目

.isnul().sum().sum() 把每列的 NaN 值进行 sum 计算

9.6 统计数据量大时统计非 NaN 的个数 .count().sum()
.count() 就会列出每列非 NaN 值的数目,.count().sum() 则会得到 DataFrame 中所有非 NaN 的数目。