用python写渗透测试脚本——信息收集之爬取邮箱
这是本人第一次写博客,本人作为网络安全初学者,希望通过写博客的形式,记录、巩固、强化自己学习到的东西。同时希望在写博客的过程中能够发现自己的不足,逐渐提高自己。
本人在学习过程中主要参考书籍为《Python安全攻防——渗透测试指南》
渗透测试的过程主要分为:
- 明确目标
- 信息收集
- 漏洞检测
- 漏洞验证
- 信息分析
- 获取所需信息
- 清楚痕迹
- 撰写报告
最近的任务就是使用python完成第二项:信息收集
邮件钓鱼攻击是非常常见的一种攻击手法,在使用这种手法进行攻击时,通常会结合社会工程学原理进行。大致方法为:收集大量邮箱,对目标邮箱发送批量钓鱼邮件,诱骗、欺诈目标用户或者管理员,使其点击执行或者输入关键信息,进而获取目标系统权限等
本次实验内容为:编写一个可以大量收集邮箱的工具,具体思路为:从bing和百度上爬取邮箱信息
具体函数调用关系,如图所示: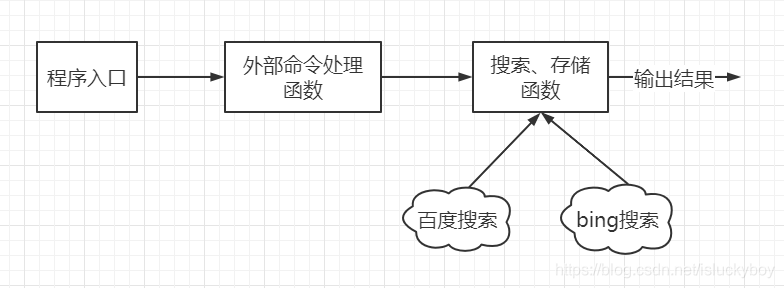
程序需使用命令行操作,如图所示:

程序源码如下:
import sys
import getopt
import requests
import re
from bs4 import BeautifulSoup
#banner信息
def banner():
print(" .__.__ \n"
" ___.__.|__| | _____ ____ ____ \n"
"< | || | | \__ \ / \ / ___\ \n"
" \___ || | |__/ __ \| | \/ /_/ >\n"
" / ____||__|____(____ /___| /\___ / \n"
" \/ \/ \//_____/ \n")
#使用规则
def usage():
print("-h: --help 帮助;")
print("-u: --url 域名;")
print("-p: --pages 页数;")
print('eg: python -u "www.baidu.com" -p 10' + '\n')
# 调用bing_search()和baidu_search()函数,将搜索的到的邮箱去重,存储
def launcher(url,pages):
email_num = [] #此数组用于存储爬取到底邮箱
key_words = ['email','mail','mailbox','邮件','邮箱','postbox'] #关键字表用于搜索
for page in range(1,int(pages)+1): #根据输入的页数进行循环爬取
for key_word in key_words: #根据不同关键字进行循环爬取
bing_email = bing_search(url,page,key_word) #使用bing搜索
baidu_email = baidu_search(url, page, key_word) #使用百度搜索
sum_email = bing_email + baidu_email #将两次搜索的结果合并
for email in sum_email: #去重、存储
if email in email_num:
pass
else:
print(email)
with open('emailData.txt','a+') as f: #建立txt文件存入爬取到的email
f.write(email + '\n')
email_num.append(email)
# 定义获取邮箱的正则表达式
def search_email(html):
emails = re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+",html,re.I)
return emails
# 定义请求头,referer根据搜索引擎不同传入不同参数
def headers(referer):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.56',
'accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Accept-Encoding': 'gzip, deflate, br',
'referer': referer
}
return headers
#bing搜索
def bing_search(url,page,key_word):
referer = "http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsite%3abaidu.com&first=1&FORM=PERE1"
conn = requests.session()
bing_url = "http://cn.bing.com/search?q=" + key_word + "+site%3a" + url + "&qs=n&sp=-1&pq=" + key_word + "site%3a" + url + "&first=" + str(
(page - 1) * 10) + "&FORM=PERE1"
conn.get('http://cn.bing.com', headers=headers(referer))
r = conn.get(bing_url, stream=True, headers=headers(referer), timeout=8)
emails = search_email(r.text)
return emails
#百度搜索
def baidu_search(url,page,key_word):
email_list = []
emails = []
referer = "https://www.baidu.com/s?wd=email+site%3Abaidu.com&pn=1"
baidu_url = "https://www.baidu.com/s?wd="+key_word+"+site%3A"+url+"&pn="+str((page-1)*10)
conn = requests.session()
conn.get(referer,headers=headers(referer))
r = conn.get(baidu_url, headers=headers(referer))
soup = BeautifulSoup(r.text, 'html.parser')
tagh3 = soup.find_all('h3')
for h3 in tagh3:
href = h3.find('a').get('href')
try:
r = requests.get(href, headers=headers(referer),timeout=8)
emails = search_email(r.text)
except Exception as e:
pass
for email in emails:
email_list.append(email)
return email_list
#命令行参数处理函数
def start(argv):
url = ""
pages = ""
if len(sys.argv) < 2: #判断是否有命令输入,sys.argv[0]表示代码本身丝袜文件路径,sys.argv[1:]表示第一个命令行参数到最后一个命令行参数,存储形式为list类型。
print("-h 帮助信息;\n")
sys.exit() #若无参数输入,则输出帮助信息,停止程序
try:
banner()
#解析命令行选项与形参列表。
# args 为要解析的参数列表,不包含最开头的对正在运行的程序的引用。 通常这意味着 sys.argv[1:]。
opts,args = getopt.getopt(argv,"-u:-p:-h")
except getopt.GetoptError:
print('命令解析错误!')
sys.exit()
#循环判断输入参数,根据参数的不同对url和pages进行不同操作
for opt,arg in opts:
if opt == '-u': #如果参数为-u 则将其值赋给url
url = arg
elif opt == '-p': #如果参数为-p 则将其值赋给pages
pages = arg
elif opt == '-h':
print(usage())
# 将url和pages传入launcher参数,进行处理
launcher(url,pages)
#程序入口,若程序执行时没有异常则执行start函数,
#sys.argv[]实现外部指令接收,sys.argv[0]表示代码本身丝袜文件路径,sys.argv[1:]表示第一个命令行参数到最后一个命令行参数,存储形式为list类型。
if __name__ =='__main__':
try:
start(sys.argv[1:])
except KeyboardInterrupt:
print("被用户中断,终止所有线程")
此次实验中,首先就是学到了如何去编写一个使用命令行的工具,在过程中还是遇到不少麻烦的,比如程序存储路径不可以包含中文,否则会导致计算机找不到程序。另外还有一点,就是这个程序在使用的时候速度太慢,爬取大概不到20条数据,竟然用了小三分钟,造成相应时间太长的因素可能时搜索页面太慢,对爬取到的页面源码处理太慢,我还在思考该如何优化一下这个程序
版权声明:本文为isluckyboy原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。