小样本学习(Few-shot Learning)
定义
小样本学习(Few-shot Learning)是元学习的一种(Meta Learning),其目的是learn to learn。简单的说就是让模型具有自己学习的能力,而这个自己学习的能力就是能区分出两种图片的异同。
小样本学习与监督学习的区别
小样本学习与普通的监督学习不一样的点在于普通的监督学习把数据分为train_set与test_set,利用训练集训练卷积神经网络,再通过测试集评估模型的准确度,注意这里测试集中的所有样本都是在训练集中出现过的。
而小样本学习将数据分为train_set,support_set,query_set,利用train_set训练模型让模型具有区分不同样本异同的能力,利用support_set为模型提供更多信息来保证可以预测出query_set中的样本的类别。support_set与query_set都不存在于train_set中,这里query_set中的样本只出现在support_set中,而不出现在train_set中。
k-way n-shot
在小样本学习中,要明确几个名词:
- k-way: 表示k个类别
- n-shot: 表示每个类别有n个样本
Siamese Network
Siamese Network为孪生神经网络,主要是用来比较两个输入的差别,两个输入利用共享权重提取特征。其中的网络结构可以是一般的CNN也可以是ResNet等。Pytorch实现代码如下:
import torch.nn as nn
class Siamese(nn.Module):
def __init__(self):
super(Siamese, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(1, 128, kernel_size=(5, 5), stride=(3, 3), padding=2),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=4, stride=2),
nn.Dropout(0.5)
)
self.fc = nn.Sequential(
nn.Linear(2048, 512),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Linear(128, 2)
)
def forward_once(self, x):
x = self.layers(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def forward(self, first_img, second_img):
y1 = self.forward_once(first_img)
y2 = self.forward_once(second_img)
return y1, y2
损失函数ContrastiveLoss
首先对于前面说的孪生神经网络,两个输入x1,x2,分别利用同一个神经网络f提取特征,然后利用全连接层+sigmoid激活函数进行输出,如果两个样本为不同类别,那么希望输出的值尽可能接近0,如果为相同类别那么输出希望尽可能接近1,然后利用梯度下降反向传播,相关流程如下图所示:
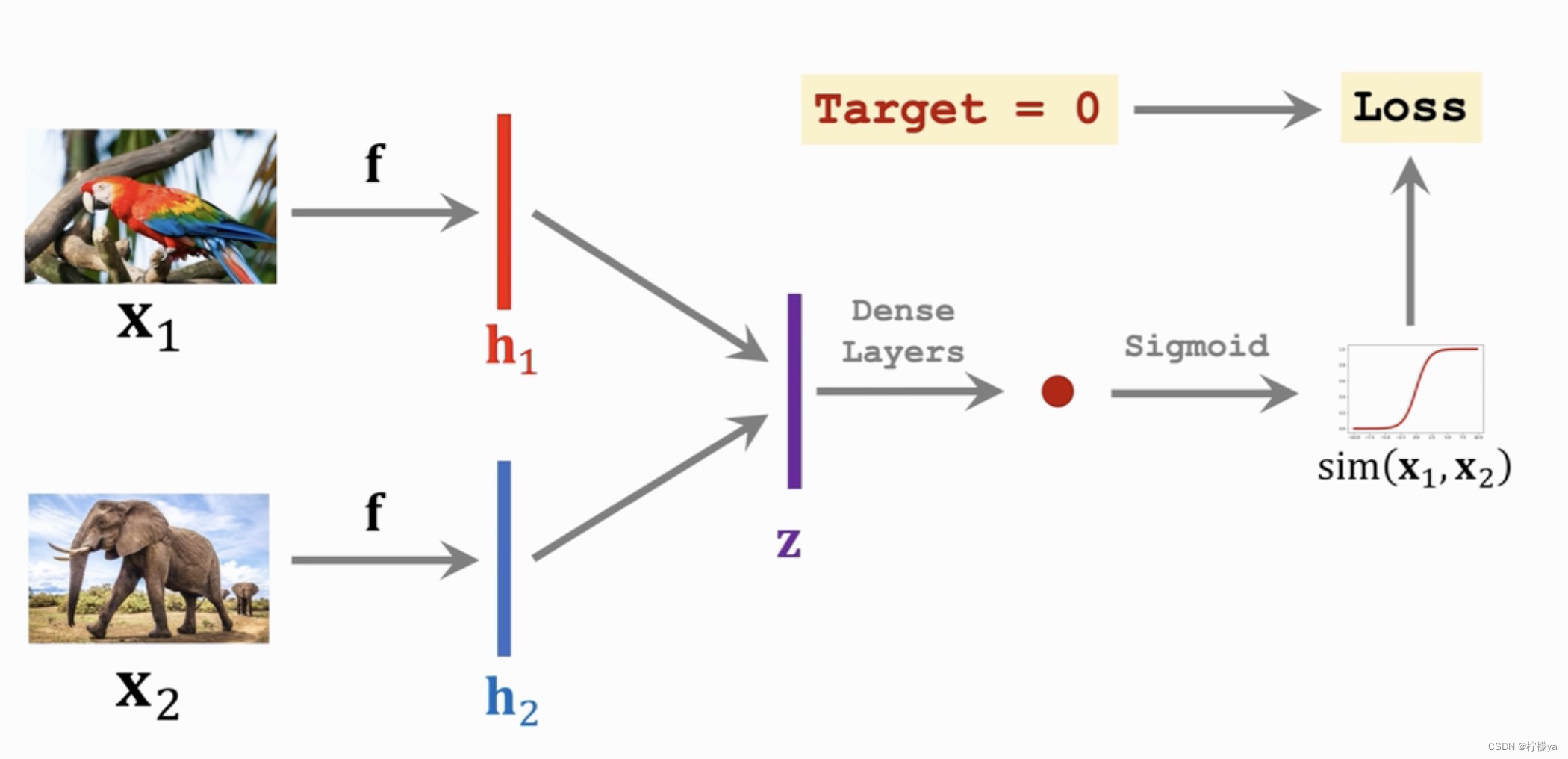
因此,定义损失函数ContrastiveLoss,
L o s s = 1 2 N ∑ n = 1 N y d 2 + ( 1 − y ) m a x ( m a r g i n − d , 0 ) 2 Loss = \frac{1}{2N}\sum_{n=1}^{N}yd^2 + (1-y)max(margin-d, 0)^{2}Loss=2N1n=1∑Nyd2+(1−y)max(margin−d,0)2
其中:
- N表示成对的样本(pair)数量
- d表示孪生神经网络两个输出的欧几里得距离
- y的值为0或1,0表示不同类别,1表示相同类别
- margin是设置的一个阈值超过margin即为不相似,在[ 0 , m a r g i n ] [0,margin][0,margin]之间表示相似
Pyorch实现代码如下:
import torch.nn as nn
import torch
import torch.nn.functional as F
class ContrastiveLoss(nn.Module):
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, y1, y2, label):
euclidean_distance = F.pairwise_distance(y1, y2, keepdim=True)
loss_contrastive = torch.mean((1 - label) * torch.pow(euclidean_distance, 2) +
label * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
Triplet Network
Triplet Loss每次从每个类别中随机抽样一个样本记做anchor(X a X^{a}Xa),然后再从该类别中随机抽样一个样本记做positive(X + X^{+}X+),然后排除该类别,从其他的类别中随机抽样一个样本记做negative(X − X^{-}X−),然后将这三个样本送入神经网络中提取特征分别记做f ( x a ) , f ( x + ) , f ( x − ) f(x^{a}),f(x^{+}),f(x^{-})f(xa),f(x+),f(x−)。分别计算postive和negative于anchor在特征空间上的距离,分别记做d + , d − d^{+},d^{-}d+,d−,如下图所示: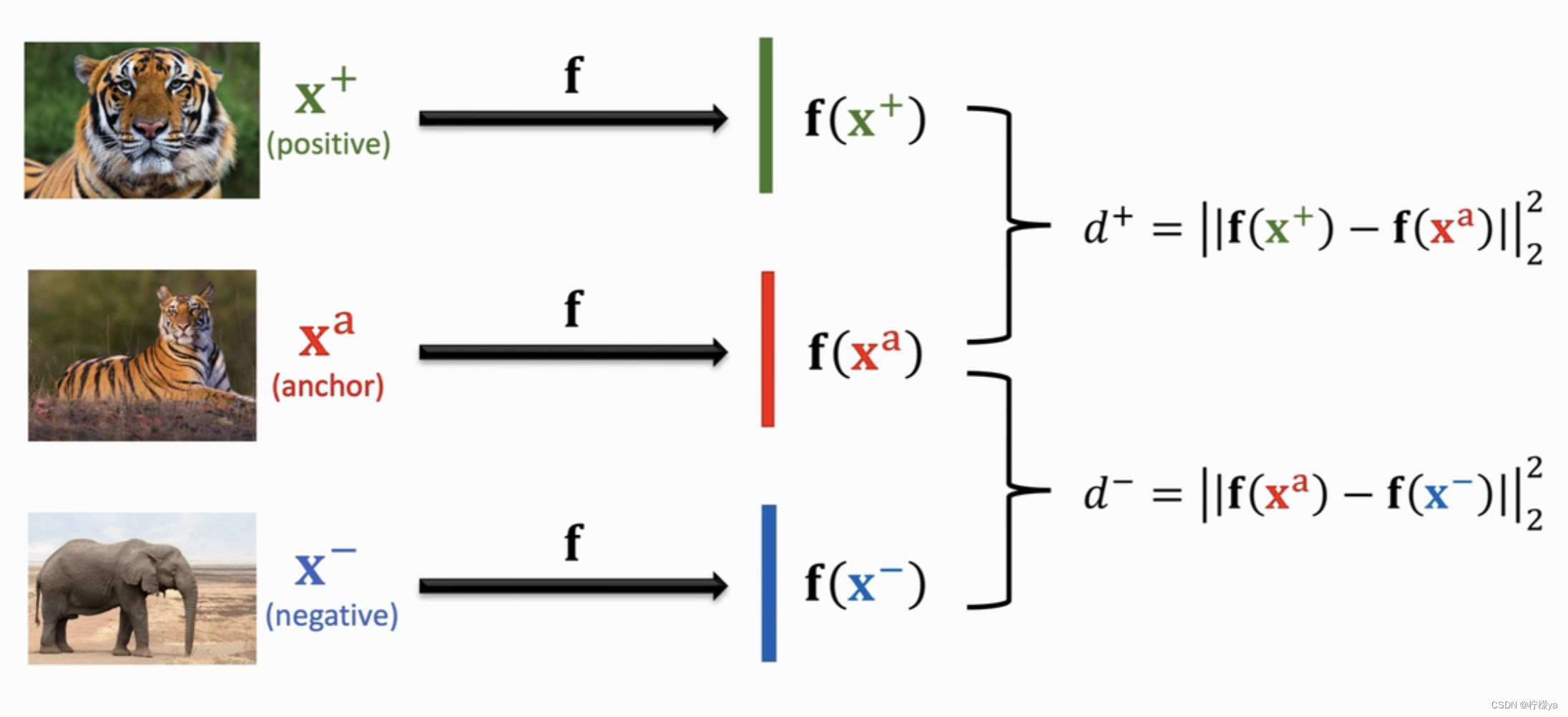
损失函数Triplet Loss
因此,根据上面描述的Triplet Network,我们希望d + d^{+}d+尽可能小,而d − d^{-}d−尽可能大,这样才能更清楚准确的描述样本。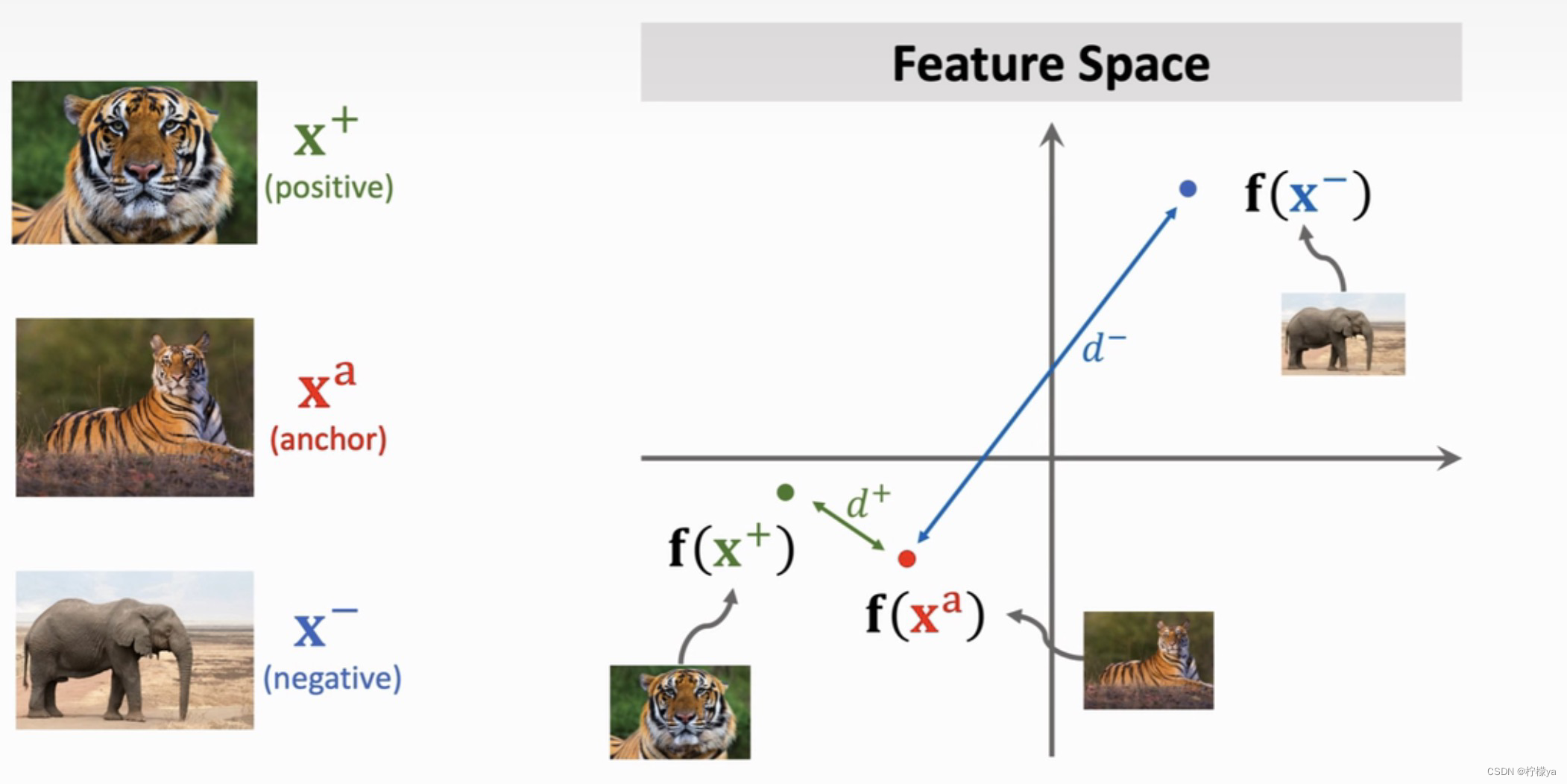
因此,我们的损失函数就变为
L o s s = m a x ( 0 , d + − d − + α ) Loss=max(0, d^{+}-d^{-}+\alpha)Loss=max(0,d+−d−+α)
其中α \alphaα用来描述d + d^{+}d+与d − d^{-}d−差值