一、前言
走近 ElasticSearch (一)—— 基本概念与架构设计
走近 ElasticSearch (二)—— Document概念、倒排索引原理与分词
走近 ElasticSearch (三)—— Mapping设计与 Search API 介绍
走近 ElasticSearch (四)—— 搜索机制与聚合分析
二、ES Search 的运行机制
ES的搜索过程如下: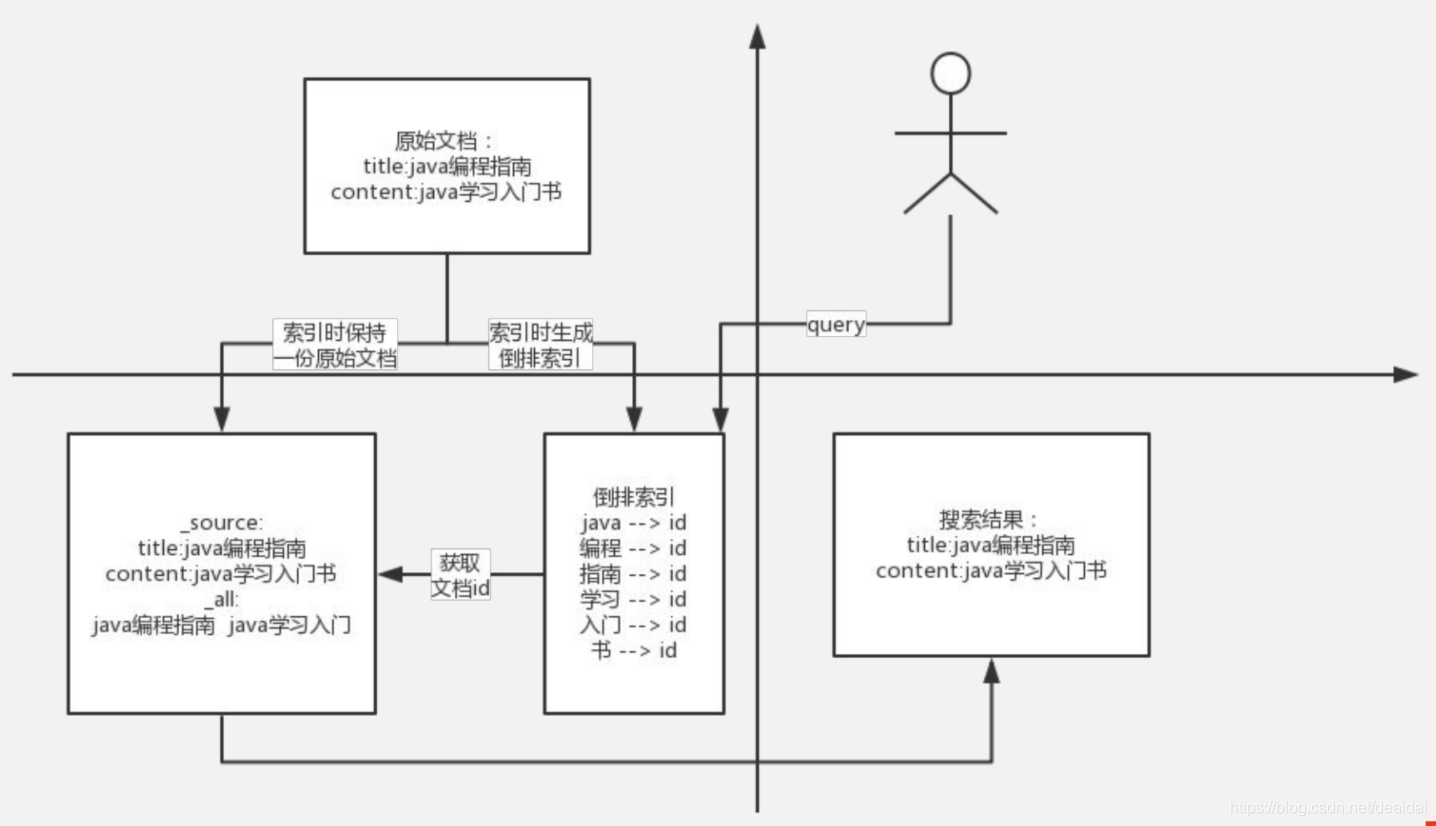
看起来很简单的图,在我们 ES 集群中进行搜索,其实并没有那么简单。
1. 搜索过程分解
Search 执行的时候实际分两个步骤运作的:查询(Query) 和 获取(Fetch)
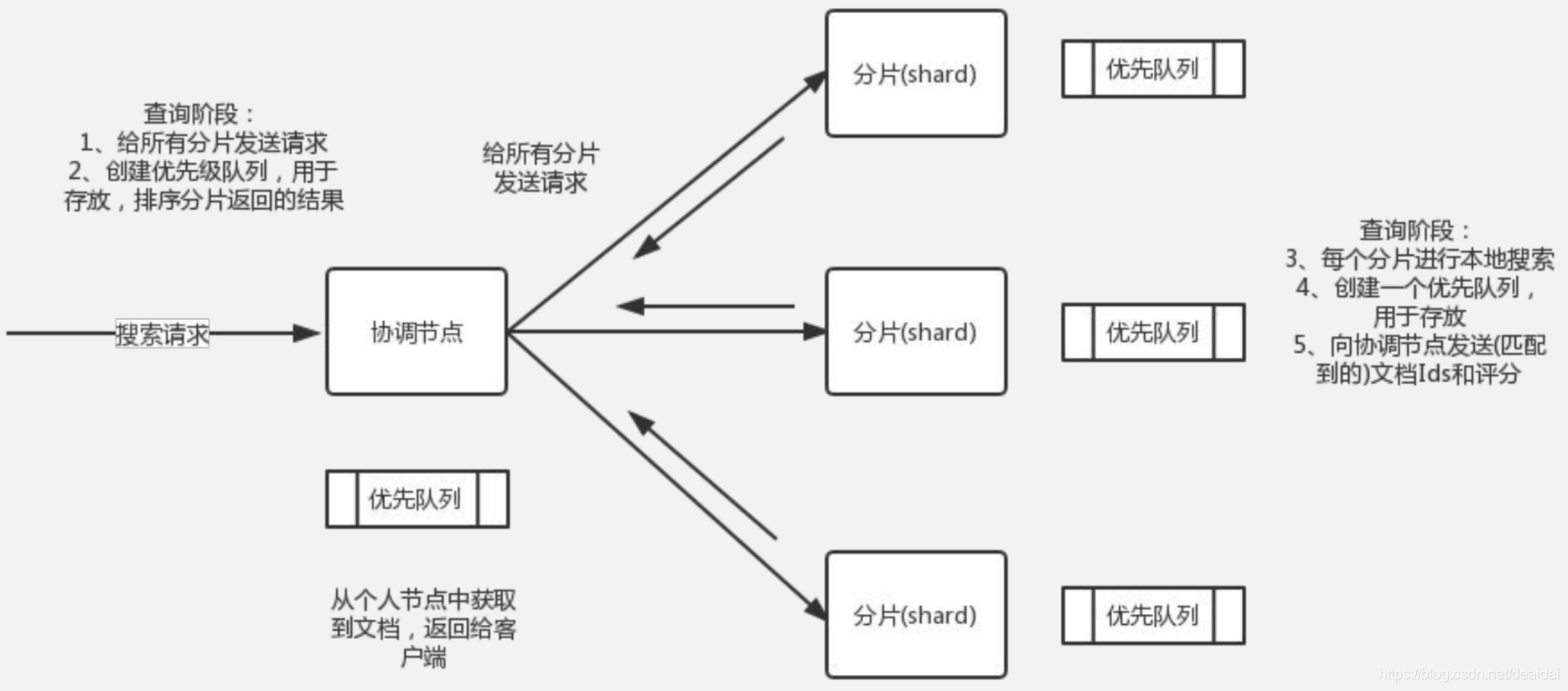
- 查询阶段(Query Phase):在此阶段,协调节点(Coordinating Node)将搜索请求路由到索引(index)中的所有分片(shards)(包括:主要或副本)。分片独立执行搜索,并根据相关性分数创建一个优先级排序结果。所有分片将匹配的文档和相关分数的文档ID返回给协调节点。协调节点创建一个新的优先级队列,并对全局结果进行排序。可以有很多文档匹配结果,但默认情况下,每个分片将前10个结果发送到协调节点,协调创建优先级队列。
- 获取阶段(Fetch Phase):在协调节点对所有结果进行排序,并通过文档id,从分片中得到原始文档,再返回
2. 再谈相关性算分
相关性算分在 shard 与 shard 间是相互独立的,也就意味着同一个 Term的 IDF等值在不同 shard 上是不同等。文档的相关性算分和它所处的 shard 相关
所以在文档数量不多时,会导致相关性算法严重不准的情况发生
解决思路有两个:
- 1)设置分片数为1个,从根本上排除问题,在文档数量不多的时候可以考虑该方案,比如百万到千万级别的文档数量
- 2)使用DFS Query-then-Fetch 查询方式:拿到所有文档后再重新完整的计算一次相关性算法,耗费更多 cpu 和内存,执行性能也比较低下,一般不建议使用。使用方式如下:
GET test_search_relevance/_search?search_type=dfs_query_then_fetch {
“query”: {
"match": { "name": "hello" }
}
}
3. 排序
es 默认会采用相关性算分排序,用户可以通过设定sorting参数来自行设定排序规则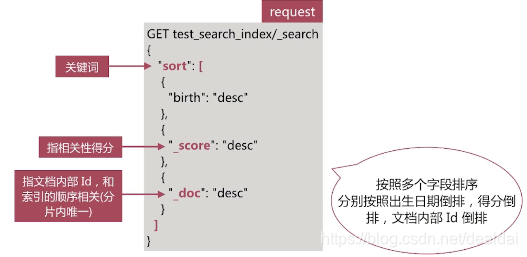
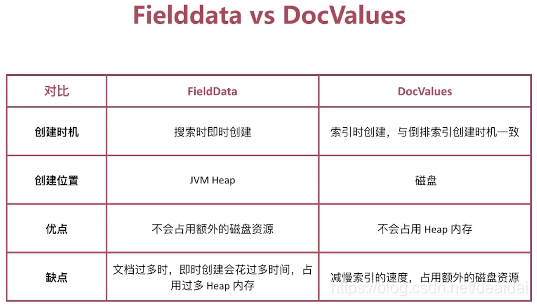
排序的过程实质是对字段原始内容排序的过程,这个过程中倒排索引无法发挥作用,需要用到正排索引,也就是通过文档Id和字段可以快速得到字段原始内容。
es 对此提供来2种实现方式:
- fielddata 默认禁用
- doc values 默认启用,除来 text 类型
4. 分页与遍历
es 提供了3种方式来解决分页与遍历的问题:from/size、scroll、search_after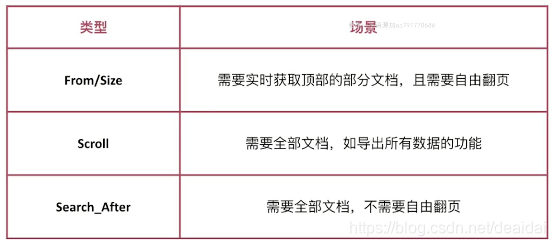
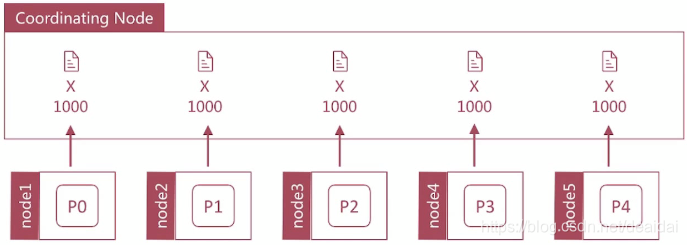
- from/size:存在深度分页问题。获取from~size的数据,我们需要把每个Node节点的前size个数据取出来然后排序。所以,页数越深,处理文档越多,占用内存越多,耗时越长
- scroll:以快照的方式来避免深度分页。不能用来做实时搜索。尽量不要使用复杂的 sort 条件
- search_after:避免深度分页的性能问题(通过唯一排序值定位将每次要处理的文档数都控制在 size 内),提供实时的下一页文档获取功能。缺点是不能使用 from 参数,即不能指定页数,只能下一页,不能上一页。
将50个文档排序后返回前10个文档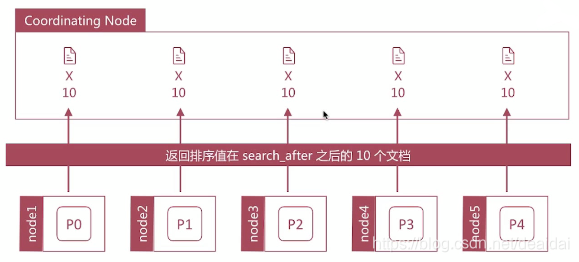
三、聚合分析
英文 Aggregation,是 es 除搜索功能外提供的针对 es 数据做统计分析的功能
- 功能丰富,提供 Bucket、Metric、Pipeline 等多种分析方式,可以满足大部分的分析需求
- 实时性高,所有的计算结果都是即时返回的,而 hadoop 等大数据系统一般都是 T + 1 级别的

为了便于理解,es 将聚合分析主要分为如下 4 类 - Bucket,分桶类型,类似 SQL 中的 GROUP BY 语法
- Metric,指标分析类型,如计算最大值、最小值、平均值
- Pipeline,管道分析类型,基于上一级的聚合分析结果进行再分析
- Matrix,矩阵分析类型
1. Metric 聚合分析
主要分如下两类:
- 单值分析,只输出一个分析结果:min,max,sum,cardinality
- 多值分析,输出多个分析结果:stats,extended stats,percentile,percentile rank,top hits
2. Bucket 聚合分析
Bucket,意为桶,即按照一定的规则将文档分配到不同的桶中,达到分类分析的目的。
按照 Bucket 的分桶策略,常见的 Bucket 聚合分析如:Terms、Range、Date、Range、Histogram
3. Bucket + Metric 聚合分析
分桶之后在分桶
4. Pipeline 聚合分析
针对聚合分析的结果再次进行聚合分析,而且支持链式调用
5. 作用范围
es 聚合分析默认作用范围是 query 的结果集,可以通过这些的方式改变其作用范围:filter、post_filter、global
6. Terms 并不永远准确
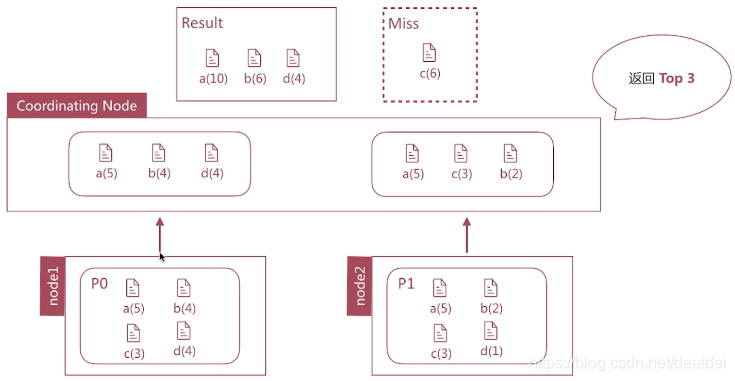
解决办法:
- 设置 Shard 数为1,消除数据分散的问题,但无法承载大数据量
- 合理设置 Shard_Size 大小,即每次从 SHard 上额外多获取数据,以提升准确度