1.select语句
1.1 指定列
1.select * from dealer_leads;
2.select leads_id,dealer_id,create_time from dealer_leads;
3.select e.leads_id,e.dealer_id,e.create_time from dealer_leads e;
--2和3是等价的当选择的列是数据集合类型时,Hive会使用json语法输出,如数组类型[...],json map格式{...},hive可以引用数据类型中的元素
select name,subordinates[0] from employees;select name,subordinates['State Taxes'] from employees;select name,address.city from employees;使用正则表达式指定列
select symbol,'price.*' from stocks;
--选择symbol列,和所有列名以price为前缀的列1.2 函数列
select companyid,upper(host),UUID(32) from dealer_action_log;
--可以使用hive自带的函数,也可以使用自定义函数,如upper()是自带函数,UUID()是自定义函数hive内置函数可参考官方文档 :
Apache Software Foundationcwiki.apache.org中文文档:
Hive函数大全_wisgood的专栏-CSDN博客_hive函数blog.csdn.net
1.3算数运算列
selcet companyid,userid,(companyid + userid) as sumint from dealer_action_log;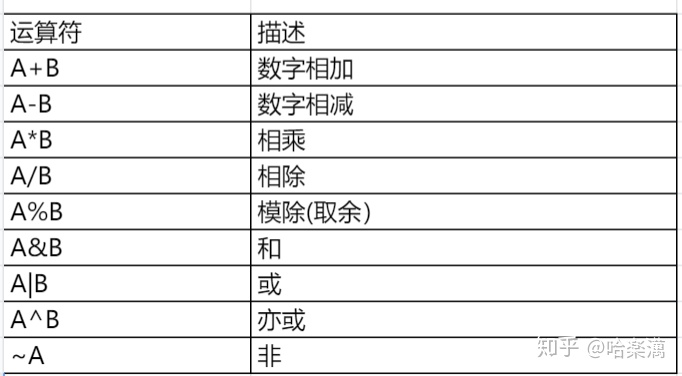
2. limit语句
select * from dealer_action_log limit 10;3.嵌套select语句
from(
selcet upper(name),salary,deductions['Federal Taxes'] as fed_taxes,round(salary*(1-deductions['Federal Taxes'])) as salary_minus_fed_taxes
from employees) e
select e.name,e.salary_minus_fed_taxes
where e.salary_minus_fed_taxes > 70000;4.case...when...then语句
case
when salary < 50000 then 'low'
when salary >= 50000 and salary <70000 then 'middle'
when salary >= 70000 and salary < 100000 then 'hight'
else 'very hignt'
end as bracket from employee;5.where语句
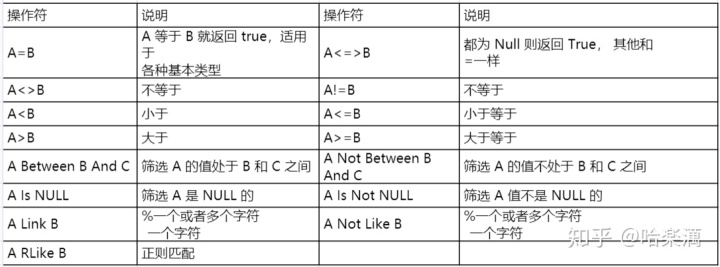
- 使用 WHERE 子句, 将不满足条件的行过滤掉
- WHERE 子句紧随 FROM 子句
select * from employees where country = 'us' and state = 'CA';where 筛选操作:
6.子查询:
Hive 对子查询的支持有限,只允许在from 后面出现。比如:
--只支持如下形式的子查询
select * from (
select dealerid,dealername from dealer_info i where i.dealerid='10595'
) a;
--子查询必须有名字(别名),否则报错- 子查询相当于表名,使用 from 关键字需要指定真实表名或表别名。
- hive 不支持union ,只支持union all
- 子查询中使用union all 时,在子查询里不能使用count、sum 等 聚合函数
- 两表直接进行union all 可以使用count、sum 等聚合函数
- 两张表进行union all 取相同的字段名称,可正常输出指定数据内容,且结果为两张表的结果集
7.like与Rlike
1) 使用 LIKE 运算选择类似的值
2) 选择条件可以包含字符或数字:
% 代表零个或多个字符(任意个字符)。
_代表一个字符。
3) RLIKE 子句是 Hive 中这个功能的一个扩展, 其可以通过 Java 的正则表达式这个更强大的语言来指定匹配条件
# 查找以 2 开头薪水的员工信息
select * from emp where sal LIKE '2%';
# 查找第二个数值为 2 的薪水的员工信息
select * from emp where sal LIKE '_2%';
# 查找薪水中含有 2 的员工信息
select * from emp where sal RLIKE '[2]';8.group by语句
group by语句通常会和聚合函数一起使用, 按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作
# 计算 emp 表每个部门的平均工资
select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
# 计算 emp 每个部门中每个岗位的最高薪水
select t.deptno, t.job, max(t.sal) max_sal from emp t group byt.deptno, t.job;9.having语句
having 与 where 不同点
(1) where 针对表中的列发挥作用, 查询数据; having 针对查询结果中的列发挥作用,筛选数据。
(2) where 后面不能写分组函数, 而 having 后面可以使用分组函数。
(3) having 只用于 group by 分组统计语句
# 求每个部门的平均薪水大于 2000 的部门
select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;