1 二叉树的建立
我们要建立一个左图这样的树,为了能让每个结点确认是否有左右孩子,我们需要对它进行扩展,将每个结点的空指针引出一个虚节点,其值为一特定值,如“#”,我们称这种处理后的二叉树为原二叉树的扩展树,如图所示。
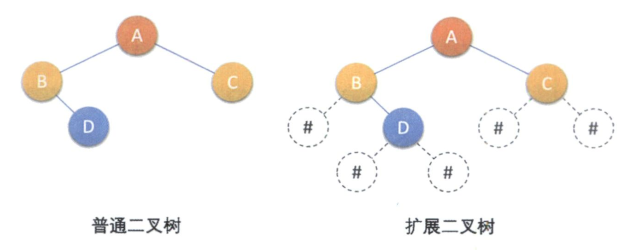
假设二叉树的结点均为一个字符,我们把刚才前序遍历序列AB#D##C##用键盘挨个输入,实现算法如下:
// 按前序输入二叉树中结点的值(一个字符)
// #表示空树,构造二叉链表表示二叉树T
void CreateBiTree(BiTree *T){
TElemType ch;
scanf("%c",&ch);
ch = str(index++);
if(ch=="#"){
*T=NULL;
}else{
*T = (BiTree)malloc(sizeof(BiTNode));
if(!*T){
exit(OVERFLOW);
}
(*T)->data = ch; // 生成根结点
CreateBiTree(&(*T)->lchild); // 构造左子树
CreateBiTree(&(*T)->rchild); // 构造右子树
}
}
建立二叉树利用了递归原理,只是在原来应该是打印结点的地方,改成了生成结点、给结点复制的操作。
2 线索二叉树
我们能够发现在传统二叉树的定义中,
- 指针域没有充分利用,有许许多多的“^”,也就是空指针域的存在。
- 在二叉链表上,我们只能知道每个结点指向其左右孩子结点的地址,而不知道某个结点的前驱是谁,后继是谁。要想知道,就必须遍历一次。以后每次需要知道,都必须先遍历一次。
综合两个角度的分析,我们可以考虑利用空地址,存放指向地址在某种遍历次序下的前驱和后继结点的地址。把这种前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树称为线索,相应的二叉树称为线索二叉树(Threaded Binary Tree)。
线索二叉树其实就相当于是把一棵二叉树转变成了一个双向链表,这样为插入删除结点、查找结点都带来了极大的方便,我们把对二叉树以某种次序遍历使其变为线索二叉树的过程称作是线索化。
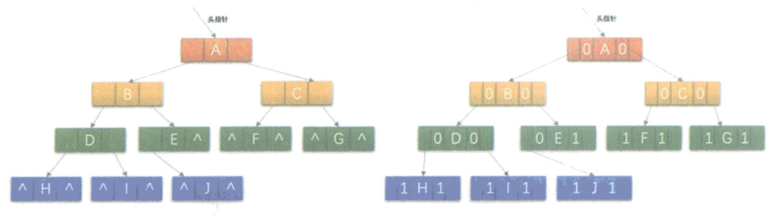
我们再决定lchild是指向左孩子还是前驱,rchild是指向右孩子还是后继上是需要一个区分标志。所以我们需要在增设两个ltag和rtag,注意ltag和rtag只是存放0或1的布尔型变量。结点结构如图所示。

其中:
ltag为0时指向该结点的左孩子,为1时指向该结点的前驱。rtag为0时指向该结点的右孩子,为1时指向该结点的后继。
二叉链表图可以修改为如图所示:
3 线索二叉树结构的实现
3.1 线索二叉树的定义及线索化的实现
二叉树的线索存储结构定义代码如下:
typedef char TElemType;
typedef enum {Link,Thread} PointerTag; // Link==0表示指向左右孩子指针,Thread==1表示指向前驱或后继的线索
typedef struct BiThrNode{
TElemType data; // 结点数据
struct BiThrNode *lchild,*rchild; // 左右孩子指针
PointerTag LTag;
PointerTag RTag; // 左右标志
}BiThrNode,*BiThrTree;
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索,由于前驱和后继的信息只有在遍历二叉树时才能得到,所以线索化的过程就是在遍历的过程中修改空指针的过程。
中序遍历线索化的递归函数代码如下:
BiThrTree pre; /* 全局变量,始终指向刚刚访问过的结点 */
/* 中序遍历进行中序线索化 */
void InThreading(BiThrTree p){
if(p){
InThreading(p->lchild); /* 递归左子树线索化 */
if(!p->lchild){ /* 没有左孩子 */
p->LTag=Thread; /* 前驱线索 */
p->lchild=pre; /* 左孩子指针指向前驱 */
}
if(!pre->rchild){ /* 前驱没有右孩子 */
pre->RTag=Thread; /* 后继线索 */
pre->rchild=p; /* 前驱右孩子指针指向后继(当前结点p) */
}
pre=p; /* 保持pre指向p的前驱 */
InThreading(p->rchild); /* 递归右子树线索化 */
}
}
if(!p->lchild)表示如果某结点的左指针域为空,因为其前驱结点刚刚访问过,赋值给pre,所以可将pre赋值给p->lchild,并修改p->LTag=Thread(也就是定义为1)以完成前驱结点的线索化。
由于p结点的后继还没有访问到,只能对它的前驱结点pre的右指针rchild做判断,if(!pre->rchild)表示如果为空,则p就是pre的后继,于是pre->rchild=p,并设置pre->RTag=Thread,完成后继结点的线索化。
3.2 线索二叉树的遍历
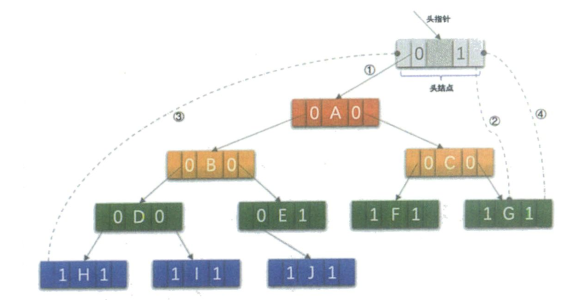
在二叉树线索链表上添加一个头结点,令其lchild域的指针指向二叉树的根结点,其rchild域的指针指向中序遍历时访问的最后一个结点。反之,令二叉树的中序序列中的第一个结点中,lchild域指针和最后一个结点的rchild域指针均指向头结点。
这样定义的好处就是我们既可以从第一个结点起顺后继进行遍历,也可以从最后一个结点起顺前驱进行遍历,如图所示。
遍历代码如下:
/* 中序遍历二叉线索树T(头结点)的非递归算法 */
Status InOrderTraverse_Thr(BiThrTree T){
BiThrTree p;
p=T->lchild; /* p指向根结点 */
while(p!=T){ /* 空树或遍历结束时,p==T */
while(p->LTag==Link){
p=p->lchild;
}
if(!visit(p->data)){ /* 访问其左子树为空的结点 */
return ERROR;
}
while(p->RTag==Thread&&p->rchild!=T){
p=p->rchild;
visit(p->data); /* 访问后继结点 */
}
p=p->rchild;
}
return OK;
}
从这段代码可以看出类似于链表的扫描,时间复杂度为O ( n ) O(n)O(n)。这种方法充分利用了空指针域的空间,又保证了创建时的一次遍历就可以终生受用后继信息。如果所用的二叉树需要经常遍历或查找结点时需要某种遍历序列中的前驱和后继,完全可以采用线索二叉链表的存储结构。