目录
数据库的操作
显示当前的数据库
show databases;
创建数据库
书上的语法:
CREATE DATABASE [IF NOT EXISTS] 库名
[DEFAULT(默认值)] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
说明:
- 大写的表示关键字
- [ ]是可选项
- CHARACTER SET:指定数据库采用的字符集
- COLLATE:指定数据库字符集的校验规则
- [IF NOT EXISTS]:从字面理解就是假设创建这个数据库它是不存在,如果它是存在的,则不会发出错误,最多发出警告;如果它不存在,则会创建它。
- mySQL是不区分大小写的
实例:
- 创建名为 test 的数据库
create database test;

其中后面(0.00sec)的意思是计算机运行
这行代码的时间,sec是秒,而且0.00也并不代表它运行不需要时间,只是说明运行的时间小于10秒。
当我们创建数据库没有指定字符集和校验规则是,系统使用默认字符集:utf8(utf8),校验规则是:utf8_general_ci。
utf-8是什么编码?
答:UTF-8是针对Unicode(java语言所使用字符集)的一种长度可变字符编码,它可以用来表示Unicode标准中的任何字符,而且它和ASCll还有点关系,就是它编码中的第一字节仍与ASCll相容,使得原来处理ASCll字符的软件无须或只进行少部分修改后,便可继续使用。
[第一字节] 按照存储地址偏移量最小的字节,对应数据的最低位字节
[相容]同时并存,互相包含
if not exists的用法
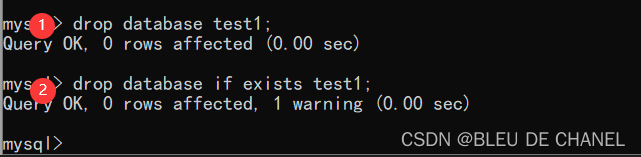
如果系统没有test2的数据库,则创建一个名为test2的数据库
create database if not exists test1;

但是如果系统已经有test2的数据库,再次创建这个名的数据库会发生什么呢?
其中0.00sec说明运行不要时间,只是运行时间小于10毫秒
发现不会发生错误,只发出了警告,若要是不加这个IF NOT EXISTS,就会发出错误
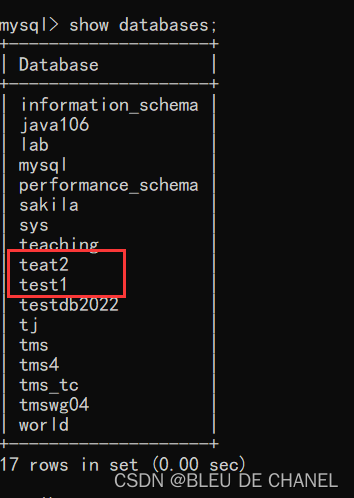
- 如果想创建一个使用utf8mb4字符集的test2数据库,如果有则不创建,无则创建
create database if not exists teat2 character set utf8mb4;
 说明:mySql的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。mySQL真正的utf8是使用utf8mb4,建议大家使用utf8mb4。
说明:mySql的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。mySQL真正的utf8是使用utf8mb4,建议大家使用utf8mb4。
使用数据库
use 数据库名
删除数据库
drop database [if exists] 数据库名
- if exists:字面意思是如果数据库存在,如果数据库不存在,则不会报出错误,只有警告;若数据库存在,则删除。(和if not existis作用一样)
- [×] 千万不要随意删除数据库!!!
非常危险!!!
如果一定要删除,请一定要记得备份!!!
说明:
数据库删除以后,内部看不到对应的数据库,库里表和数据全部被删除
删除完后: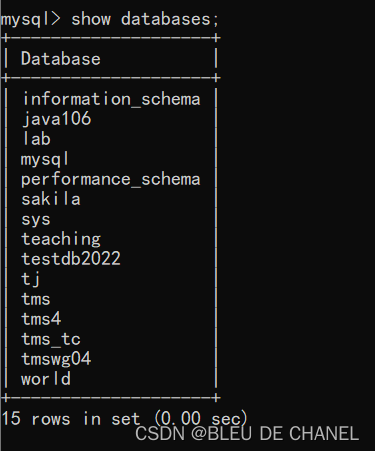
常用数据类型
数据类型
分为整型和浮点型:
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| bit(M) |
注意:
- SQL的单位是字符,不是字节
- 某些数据类型的长度是谁规定的?
在工作中,有专门的岗位负责做这个工作–产品经理。产品经理要负责公司的业务,调研对应的市场情况,提出产品需求,再由程序猿来实现。 - 常用的有哪些?
decimal(3,1):有效位数是3位,小数保留1位。若是大于或是小于这个范围 [0,100),系统是没法调整精度的,就直接报错了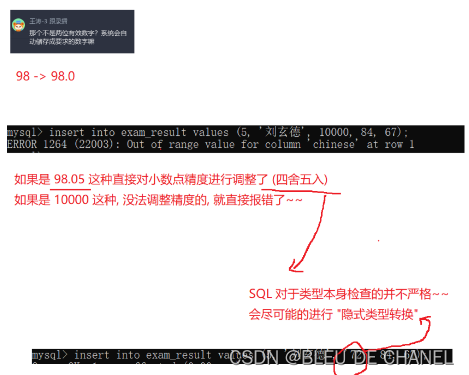
字符串类型
日期类型
日期类型最好使用timestamp,因为(千年虫),千年虫是什么?
表操作
需要操作数据库中的表是,需要先使用该数据库
use 数据库名;
查看表结构
desc 表名
比如:
创建表
create table 表名(
列名 类型 comment " ",
列名 类型 comment " ",
列名 类型
);
可以使用comment添加字段说明。
实例:
设计一张老师表,包含以下字段:姓名、年龄、身高、体重、性别、学历、生日、身份证号
create table teacher(
name varchar(10) comment "姓名",
age int(10) comment "年龄",
height double comment "身高",
weight double comment "体重",
sex enum('男','女') comment "性别",
educational varchar(20) comment "学历",
birthday date comment "生日",
ID int(30) comment "身份证号");
删除表
语法格式:
drop [TEMPORARY] table [if exists] 表名1[,表名2,表名3……]
- [ ]TEMPORARY:这个关键字用来标记这张表是临时表,与普通表区分
1.作用:临时表用来保存一些 '临时数据'
2. 注意:
(1) 临时表只在 '当前连接' 可见,当关闭连接时,Mysql 会 '自动删除表数据及表结构'
(2) 临时表 和 普通表 用法一样,用关键字 'temporary' 予以区别
- [ ]if exists:翻译成如果存在,如果删除不存在的表,则不会报错,只会有警报;删除存在的表,之后这个数据库没有这张表。
- 删除表往往比删除库更加危险!!!
因为删除一张表是不容易被发现,且SQL之间的资源是相交关系,可能牵一发而动一身的危险。
所以,删除的时候,一定一定要记得备份!!!
表的增删改查
CRUD:Create(增加)、Retrieve(查询)、Update(更新)、Delete(删除)
新增数据、查询数据、修改数据、删除数据
为了能使得代码具有可读性,必要时,我们需要加上注释,在SQL中可以使用“–空格+描述”来表示注释说明
新增
语法:
insert [into] 表名
[列名]
values (value_list) [, (value_list)] …
value_list: value,[,value]……
- into:可加可不加,都OK
- column:对应列的名称
- value_list:对应列传递的值
可能会出现的错误:
我用上面的teacher表来举例,如果大家想用这个例子试一下,就直接复制就可以了!
1、列数不匹配,插入报错 ! ! 意思就是列的数目不匹配值的数目。
意思就是列的数目不匹配值的数目。
一定要学会耐心阅读错误提示!!虽然提示是英文的,但是都是最简单的英文,只要耐性,都能看懂。
2、插入的值与规定的类型不匹配,插入报错!!
 当存入值到这个列为‘ID’的时候,出现错误,原本是int类型,但是存入了‘hehehe’字符串类型,因此插入报错。
当存入值到这个列为‘ID’的时候,出现错误,原本是int类型,但是存入了‘hehehe’字符串类型,因此插入报错。
3、当插入报错的原因是由于字符串是中文的时候,
说明你当前数据库的字符集是有问题的!!
正确的做法:是将系统的字符集设置为utf8/utf8mb4
或者是将数据库专门设置为utf8/utf8mb4
将数据库设置为utf8/utf8mb4
create database 数据库名 character set utf8mb4;
最好是一开始创建数据库的时候就设置,不要半路设置,会容易影响到其他表的数据,那简直就是卸磨杀驴,哈哈哈,没开玩笑,这是灾难性的。将系统的字符集设置为utf8
如何查看系统的字符集是否为utf8,命令为:
show variables like ‘%character%’;
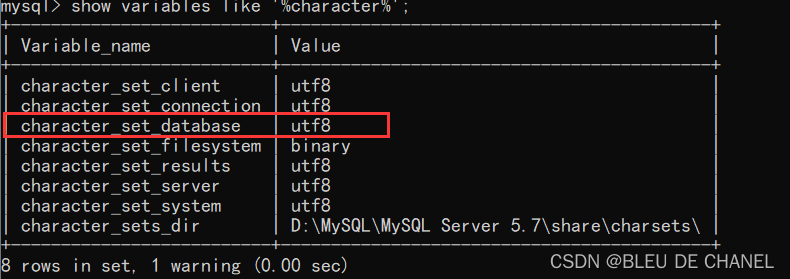 只要系统中character_set_database为utf8就可以,不用管其他的,别多管闲事!
只要系统中character_set_database为utf8就可以,不用管其他的,别多管闲事!
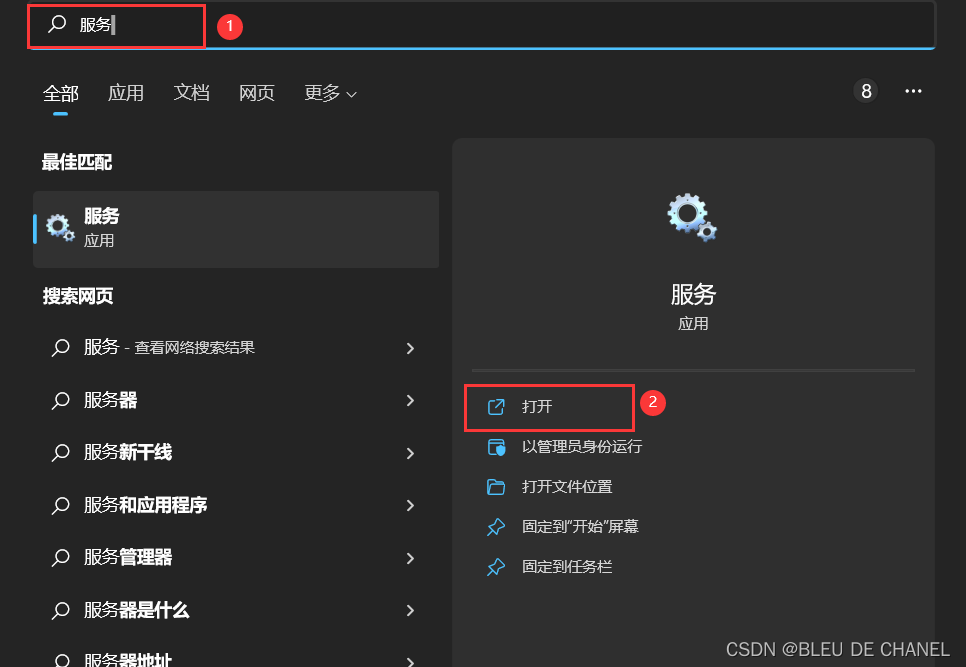
这里手把手教你如何更改数据字符集
- 找到自己文件目录下mysql中的my.int
如何找到呢?
先找到mysql.exe在哪?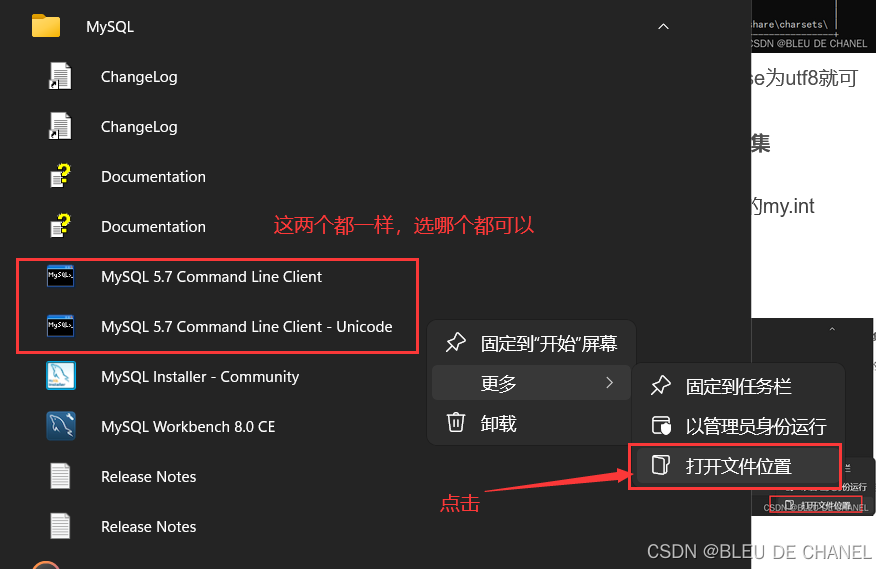 打开文件位置,再打开其中一个的属性:
打开文件位置,再打开其中一个的属性: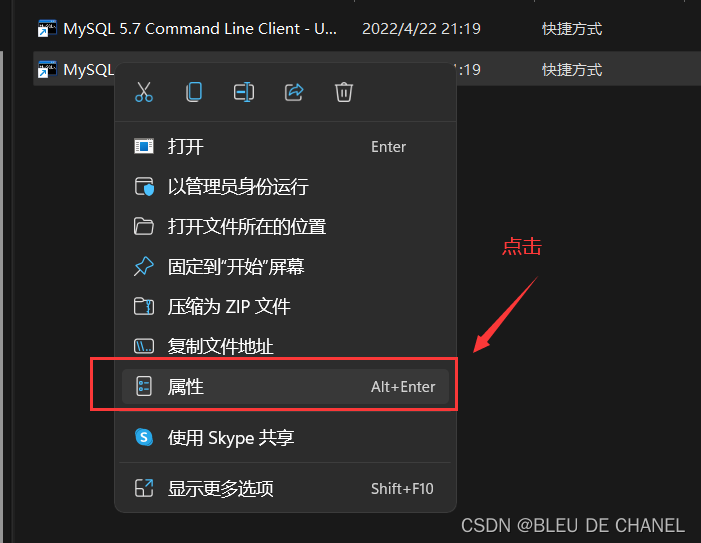 复制其中目标的位置:
复制其中目标的位置: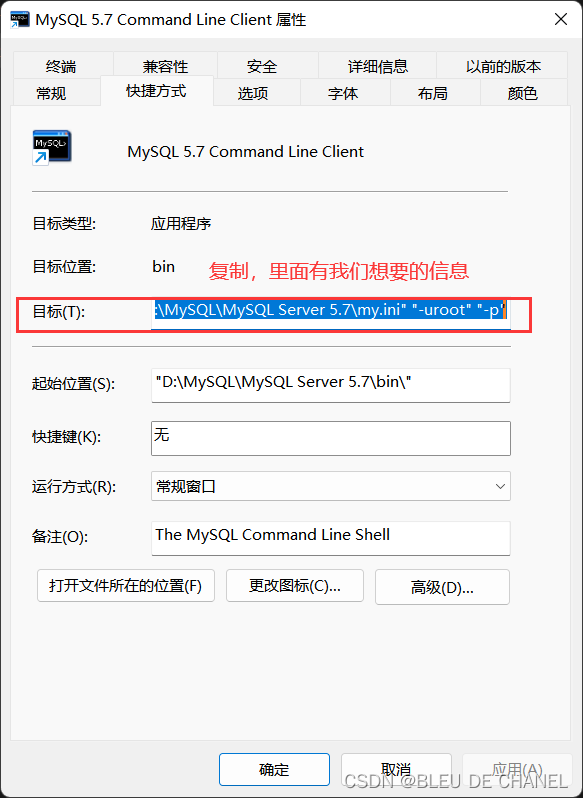 然后复制出来,发现我们my.ini文件的位置:
然后复制出来,发现我们my.ini文件的位置: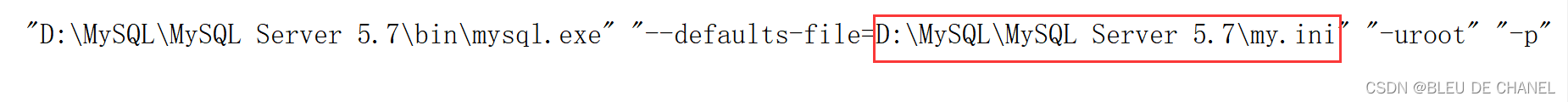
接着复制这个D:\MySQL\MySQL Server 5.7\my.ini在文件中查询:
- 打开 my.ini 记事本,找到[mysql]和[mysqld]结点,
找到default-character-set,改成default-character-set=utf8
如果是==#default-character-set=utf8==,把#删除(前面有==#号表示注释==,需要删除#)
最后呈现的结果这个样子: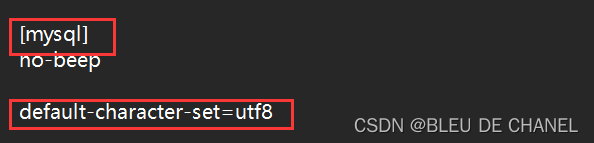
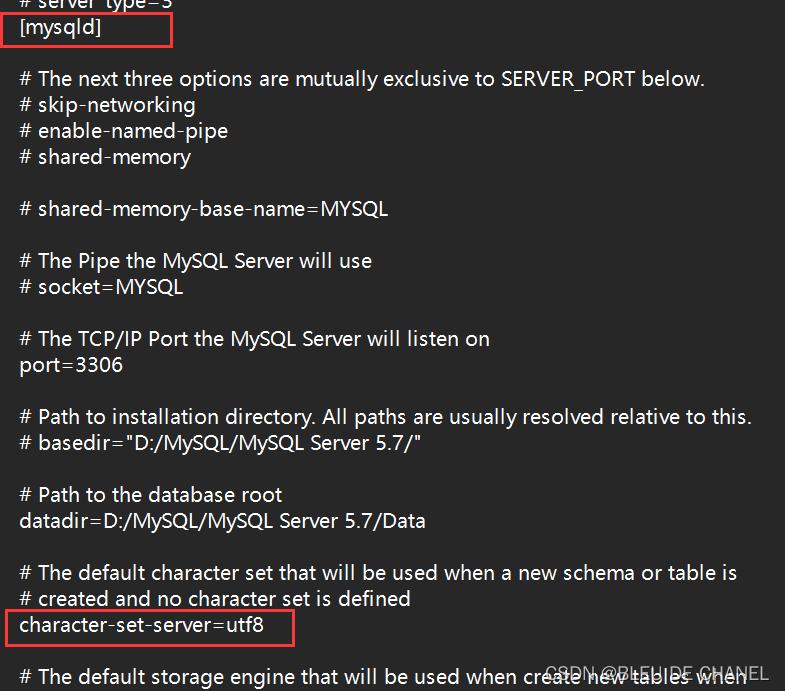
- 改完之后,一定要ctrl+s保存
- 重启mysql(让服务器重新加载配置文件)
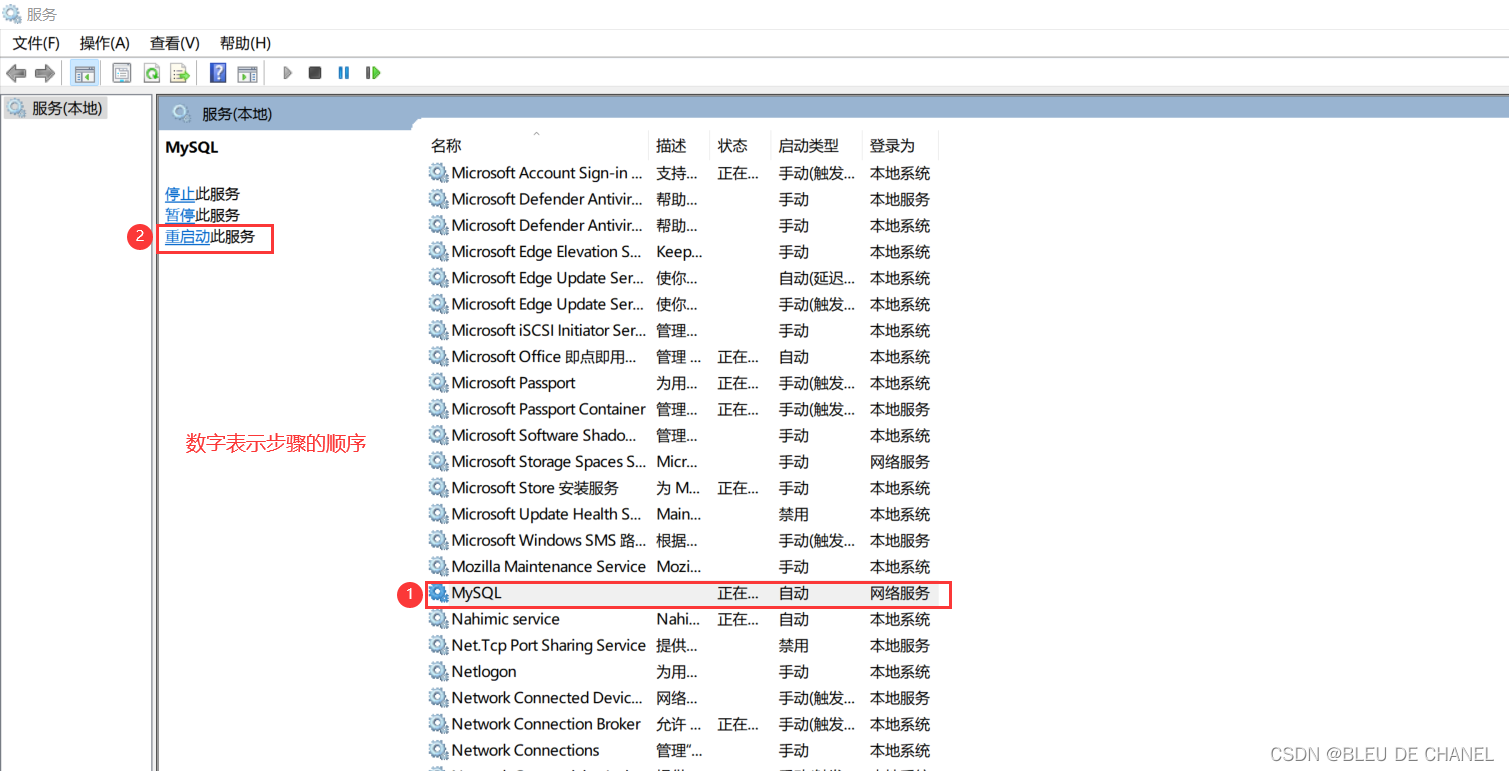 5. 查看
5. 查看
刚刚教的命令
show variables like ‘%character%’;
最终呈现出这个结果: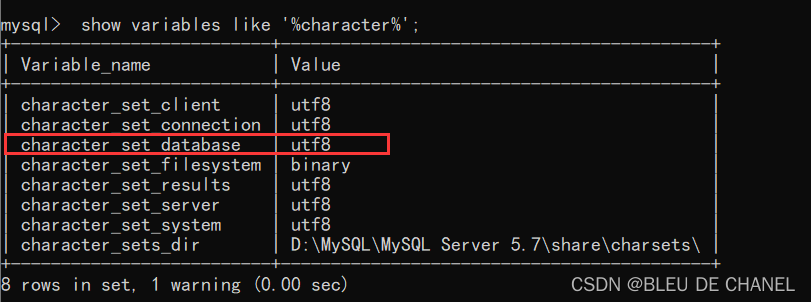 这样就可以了,不可以的话,你私信我。
这样就可以了,不可以的话,你私信我。
单行新增
insert into teacher values(“张山”,20,185,120,‘男’,“本科”,‘2022-11-3’,123456789);

在MySQL中,没有字符类型,只有字符串类型,其他的没有字符类型的编程语言,基本上也都是单引号或者双引号都行的。
多行新增
还可以一次指定插入多行,insert into 表名 values后面()可以指定多组,每一组就对应一行(一条记录),借助这个功能,就可以一个sql插入多条数据!! 反馈结果,你的数据库有几行受到了影响。
反馈结果,你的数据库有几行受到了影响。
在mysql中,当前一次插入一条记录,分10次插入,效率要低于一次把10个记录一起插入!!!
MySQL是一个“客户段服务器”结构的程序
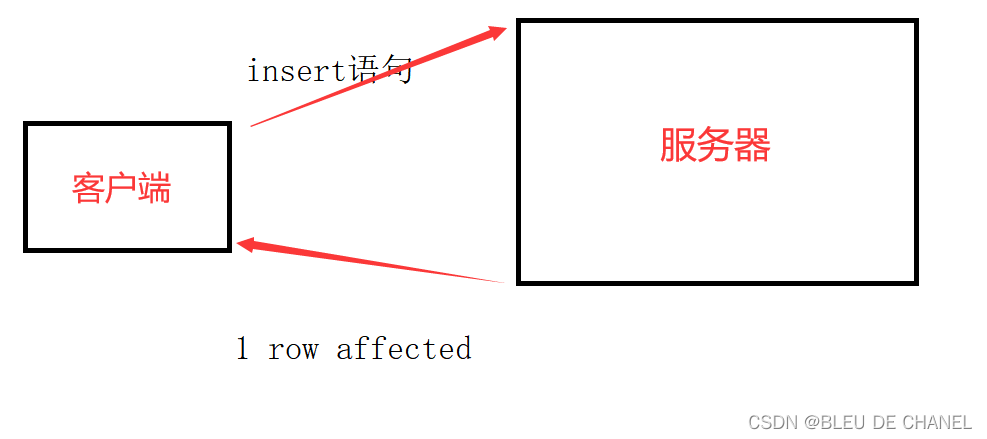 有以下几点原因:
有以下几点原因:
1.因为所有命令行操作都是通过网络访问的,发送请求返回网络响应都是时间的
2. 数据服务器是把数据保存在硬盘上的(硬盘读取要时间)
3. mysql关系型数据库,每次进行一次sql操作,内部都会开启一个事务(每次开启事务也有一定的开销)
4. 总结:既然是通过网络访问,发起网络请求和返回网络响应,每一次都是有一定的时间开销的。
新增1列或多列
可以新增1列或多列,但是绝对不能只新增半行(因为这个表是以列为单位的)
insert除了可以插入完整的一行数据之外,还可以指定列插入,此时,未被指定的列,则是以默认值来填充。
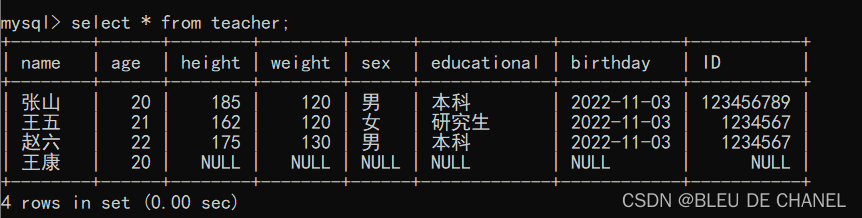
新增1列:
insert into teacher (name,age) values(“王康”,20);
 可以发现未被指定的列,则是以默认值来填充。
可以发现未被指定的列,则是以默认值来填充。
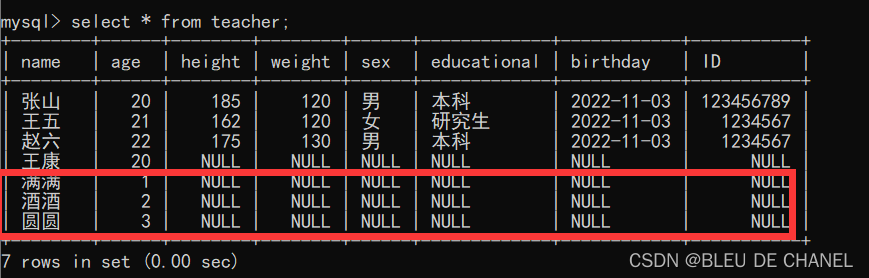
 新增多列
新增多列
insert into teacher (name,age) values(“满满”,1),(“酒酒”,2),(“圆圆”,3);

总结:
insert into 表名 values (值,值,值……);
insert into 表名 values (值1,值1,值1……),(值2,值2,值2……),(值3,值3,值3……);
insert into 表名(列1的字段,列2的字段)values (值1,值2)
无论是单行插入还是单列插入,都是可以多组一起插入滴!
记住插入的语法,是在into后面确定表名和列名,列名要加括号
查询
介绍一下查询:
select 是sql中最复杂的操作(变化多)
1.全列查询–查询表中所有的列
select * from 表名
select * from teacher;
==*==是通配符,代表所有列
实例:
创建考试成绩表
create table exam_result(
id int,
name varchar(20),
chinexe decimal(3,1),
math decimal(3,1),
english decimal(3,1)
);
插入测试数据
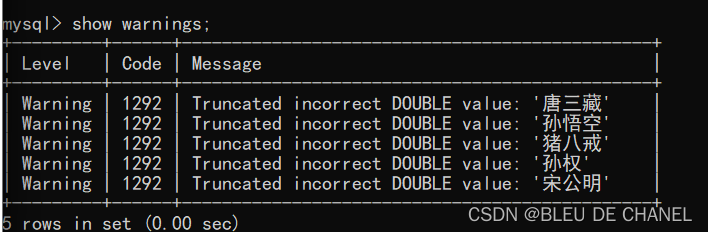
insert into exam_result values(1,'唐三藏',67,98,56);
insert into exam_result values(2,'孙悟空',87.5,78,77);
insert into exam_result values(3,'猪八戒',88,98.5,90);
insert into exam_result values(4,'曹孟德',82,84,67)
insert into exam_result values(5,'刘玄宗',55.5,85,45);
insert into exam_result values(6,'孙权',70,73,78.5);
insert into exam_result values(7,'宋公明',75,65,30);
全列查询的结果如下: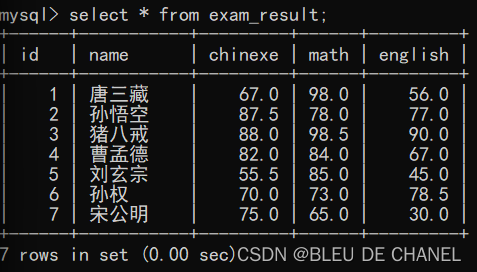
但是在工作中select操作非常危险,select *数据量非常大
- 数据是从硬盘读出来,通过网络带宽来进行发送,就容易,把硬盘IO吃满,或者把网络带宽吃满
服务器的硬件资源是很有限的!!
包括不限于CPU,内存,硬盘,网络带宽……
如果把某个资源吃光了,就会很容易导致程序出席那严重问题。
- 所以,一定要小心,工作中不要轻易使用这个查询!!!!
2.指定列查询
指定单列查询
题目:输出上述成绩表达的姓名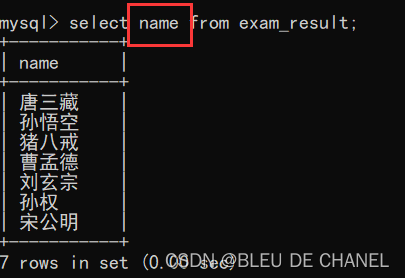
指定多列查询
题目:输出上述成绩表的姓名和其对应的语文成绩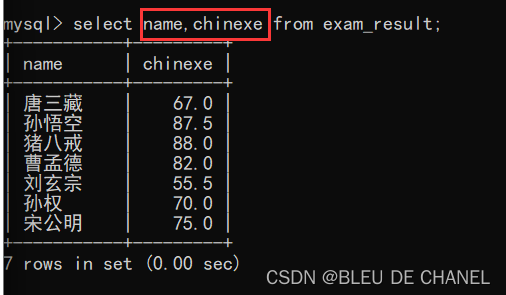
3.带表达式查询
select 表达式 from 表名
题目:由于电脑改错的原因,使得每个学生的英语成绩都少了10,现在让每个学生的英语成绩各加10分。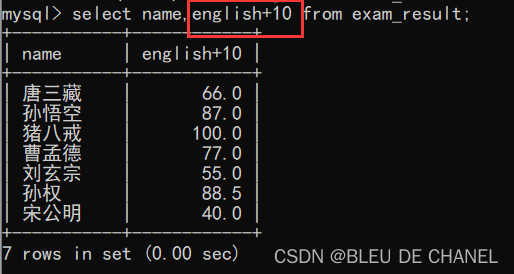 再查看一下表里的内容:
再查看一下表里的内容: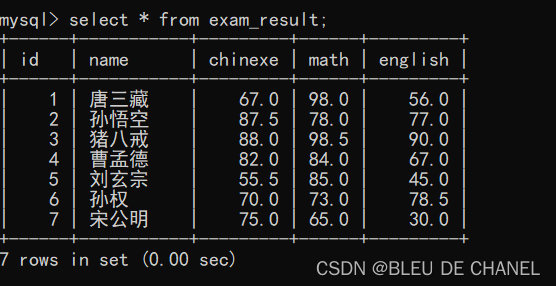
可以发现,表里的内容,并不会随着查询表达式的变化而变化,这是为什么呢?
进行表达式查询的时候,查询结果是一个 “临时表”,这个临时表,并不是写在硬盘中的,临时表的类型也不是和原始的表完全一致(会尽可能把数据给表示出来)
select只是查询,无论如何操作都不会改变硬盘上的数据
4.带别名查询
由上述的带表达式查询,可以发现新的列名是有表达式来表示的,会发现极其不美观,所以这里是给表达式取名字(咱取好听滴!哈哈哈)
select 表达式 [as] 别名 from 表名
虽然as可以省略,但是还是建议大家尽量加上!!
使得代码具有可读性,这样不会看错。
题目:查询每个学生语数英的总成绩,并用sum字段名表示总成绩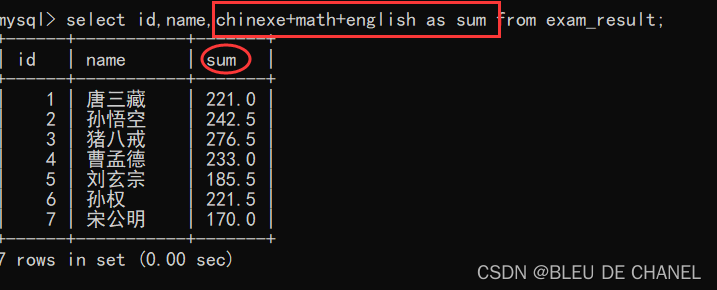
5.去重查询
去重查询:结果是将查询的列中的每一行没有重复的,操作是把重复的记录,给合并成一个(列去重)
可以去重单列和多列,但是多列要求每列的值要相同(字段可以不同)
select distinct 列名1,列名2…… from 表名
目前的表里面,没有重复的数据,这里再添加几条重复的数据。
insert into exam_result values(8,‘诸葛亮’,88,98,92);
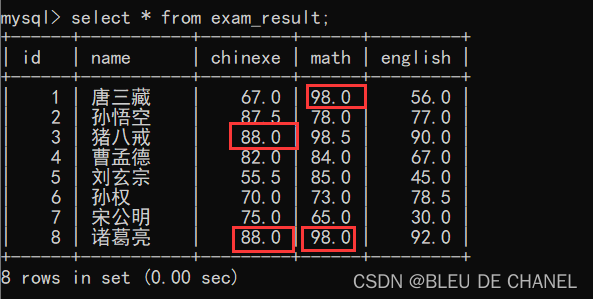 可以发现语文和数学这些列中都有重复的数字
可以发现语文和数学这些列中都有重复的数字
题目:将语文去重查询,显示语文成绩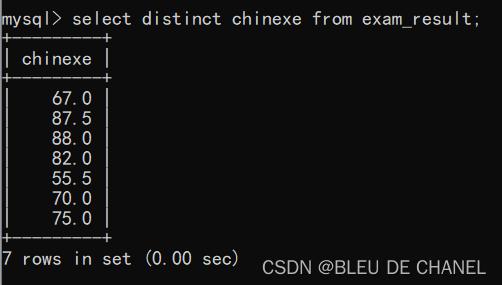
发现88只有一个了,去重成功!
题目:将语文和数学一起去重查询,显示语文和数学成绩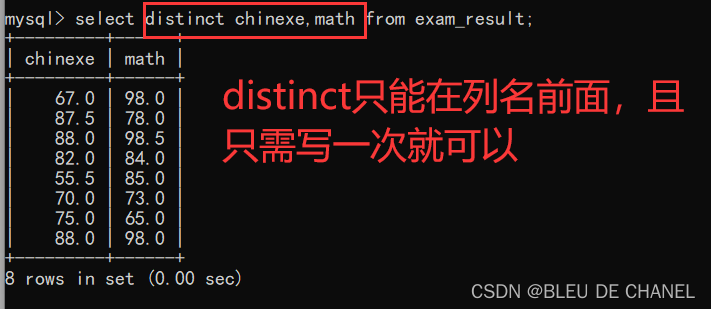 发现这样多列去重失败,那么多列要怎样才能去重成功呢?
发现这样多列去重失败,那么多列要怎样才能去重成功呢?
这里有个实例: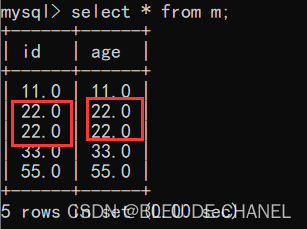
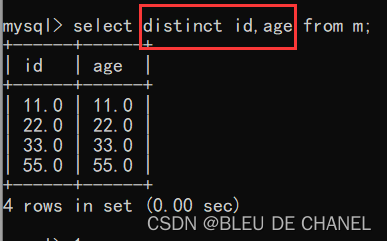 总结:当指定多个列的时候,则是要求每个列的值是相同,才算重复,并且去重成功。
总结:当指定多个列的时候,则是要求每个列的值是相同,才算重复,并且去重成功。
6.排序查询
select [列名1,列名2……] from 表名 order by 列名 asc(默认是升序) / desc(降序);
语法中有一个单词看起来好熟悉呀–desc
之前再学习查看表结构的时候也用到它,查看表结构的单词原型是describle,而这个升序的单词原型是descend。
单列排序查询
题目:查看成绩表按照语文成绩的升序进行排序
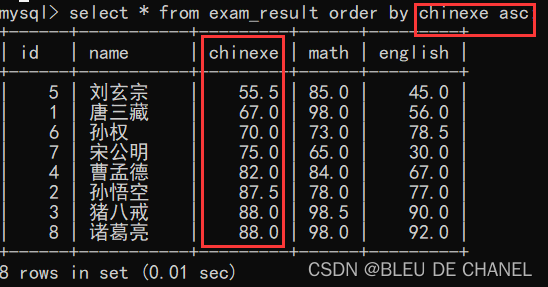 题目:查看成绩表按照语文成绩的降序进行排序
题目:查看成绩表按照语文成绩的降序进行排序
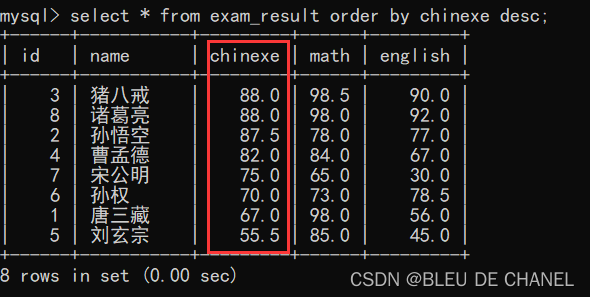 这里提一个小疑问:如果有个人的成绩为NULL,那又该如何排序呢?
这里提一个小疑问:如果有个人的成绩为NULL,那又该如何排序呢?
再添加一个人:
insert into exam_result values (9,'洪金宝',NULL,NULL,NULL);
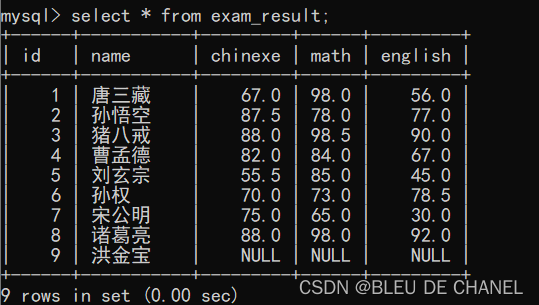
再按照语文成绩的升序进行排序一下: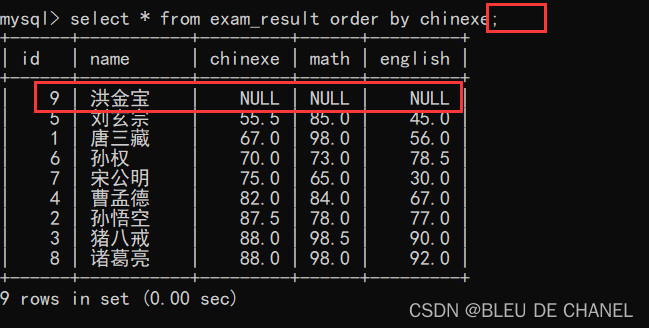
首先,发现输入的命令中缺少了降序还是升序的关键词,但是从结果看出,这个是升序排序滴,说明没有规定是升序还是降序排序时,系统是默认升序排序的,也就是asc。
其次,在排序的列中,有NULL,NULL视为“最小值”。在计算的列与列之间,有NULL,NULL和任何值计算,全部结果都是NULL(实例如下),计算只能发生在同一行的不同列中,不能发生不同行之间的计算。
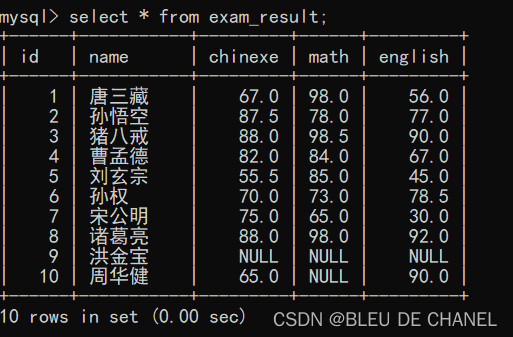
这里再新填一条记录:
insert into exam_result values (10,'周华健',65,NULL,90);
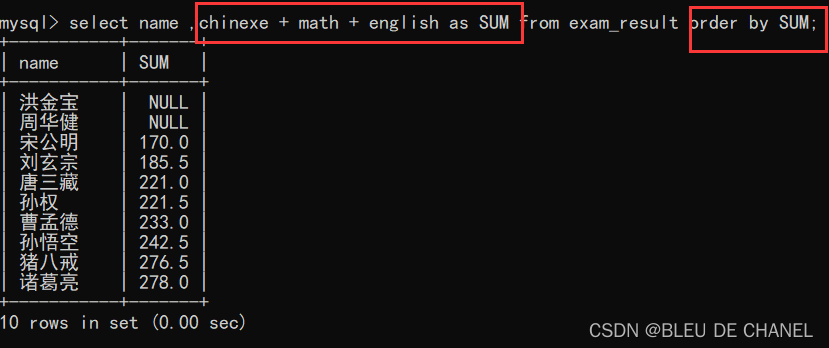 这里还可以发现排序也可以针对 表达式/别名来进行。
这里还可以发现排序也可以针对 表达式/别名来进行。
注意事项:如果SQL没有显式的写order by ,认为查询结果的顺序,是不可预期的!!写代码不能依赖自带的顺序!!
多列排序查询
排序指定多个列的时候,先以第一列为准,如果第一列值相同,再比较第二列。
首先,先比较语文 的成绩 以降序排序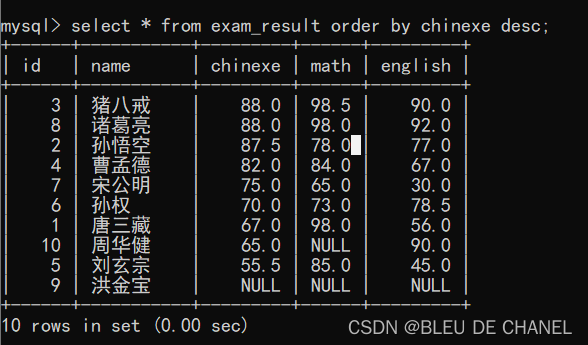 其次,再比较数学的成绩以升序排序
其次,再比较数学的成绩以升序排序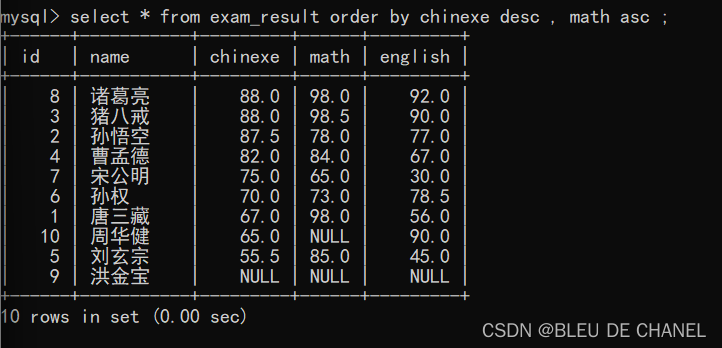 可以发现,第二次比较没有变化太大,只是第一第二名比较数学而已,因为他们的语文是相等的,然后再比较谁的数学分更高。
可以发现,第二次比较没有变化太大,只是第一第二名比较数学而已,因为他们的语文是相等的,然后再比较谁的数学分更高。
大家看到这里后,应该会好奇数据库中排序的实现,因为sql上面的数据量是可能非常大的,内存放不下,只要数据都能装进内存,其实咋排都行,更好的选择是归并,但也不一定真是归并,很多成熟的软件里面使用的一些具体策略会针对性的进行优化,具体还是看数据库里面的实现。
7.条件查询
关键词是where,根据查询的结果,按行,进行筛选
通过 where 指定一个‘条件’
把查询到的每一行,都带入到条件中,看条件是 真 还是 假 ,最后把条件为真的行保留(作为临时表的结果),条件为假的舍弃
我们知道select * 的危险,所以为了保证查询操作“不危险”的关键,在于控制一次查询,查出来的结果数量!
比较运算符:
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL不安全 例如 null=null的结果是null,这里的=,就相等于java或者c中==,就判断是否相等 |
| <=> | 等于,NULL安全,例如null<=>null的结果是true |
| !=,<> | 不等于 |
| between a0 and a1 | 范围匹配,[a0,a1],如果a0<=value<=a1,返回true,这里是左闭右闭 |
| in(value……) | 如果是value中的任意一个,返回true |
| is NULL | 是NULL |
| is not NULL | 不是NULL |
| like | 模糊匹配,%表示任意多个(包括0个)任意字符;_表示任意一个字符 |
- 这里‘=’,判断是否相等,相当于java和C语言中‘==’。
- 我相信大家在这里肯定有个疑惑,为什么都有‘=’了,为什么还有<=>
周公解梦了,<=>是针对NULL特殊处理了,使用 = 来比较某个值和NULL的相等关系,结果仍然是NULL,NULL又会被当成false.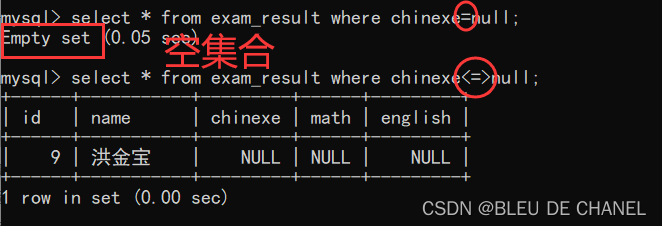
- like:模糊匹配,值不用完全相等,只要满足一部分相等就为true.
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| and | 多个条件必须都为true,结果才是true |
| or | 只要有一个条件是true,结果就是true |
| not | 条件为true,结果为false |
注意:
1、where条件可以使用表达式,但是不能使用别名
2、优先级:and>or,同时需要的时候,需要使用小括号()包裹优先执行的部分。
案例:
- =和<=>的区别:上述有讲述
- NULL的查询, is null和is not null的使用
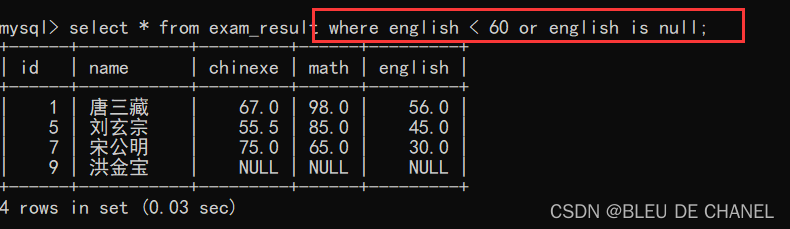
题目:查询英语成绩 < 60的同学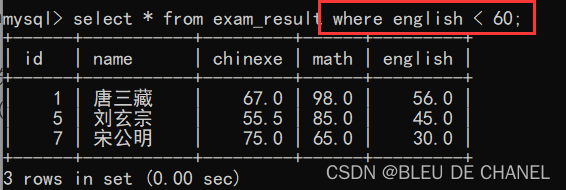 可以发现,其中没有英语成绩为NULL的记录,按理说,NULL比任何值相比都是最小的,因此也应该在记录里面的,那为什么不存在呢?
可以发现,其中没有英语成绩为NULL的记录,按理说,NULL比任何值相比都是最小的,因此也应该在记录里面的,那为什么不存在呢?
原因是NULL < 60 的结果还是NULL,NULL和任何数据进行运算都是NULL,因此被当成了false.
改进一下命令行:
以下两个都是一样的!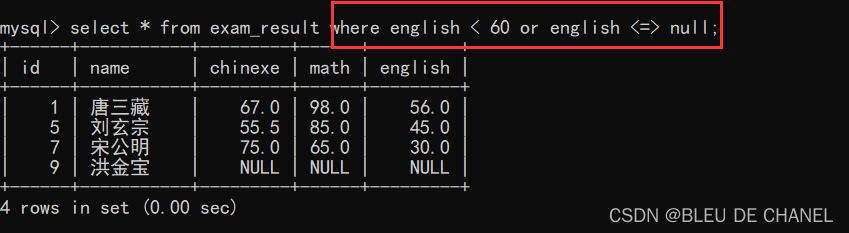
 == 但是 <=> 和 is null 是有区别的:==
== 但是 <=> 和 is null 是有区别的:==
is null 要求只能比较一个列,是否为空。
<=>可以直接比较两个列,万一两个列都有NULL,也能查询出来,而这样的场景is null是无法完成的。
题目:查询语文成绩和数学成绩都为空的同学和成绩
首先我们用 is null 试一下,看一下是否能一下子查询两个列
怕图片太小,看不清楚,所以我直接复制下来了
select * from exam_result where chinexe,math is null;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'math is null' at line 1
很显然这样的表达式是错误的! 然后我们用 <=> 来表示
然后我们用 <=> 来表示
select * from exam_result where chinexe <=> english and chinexe is null;
这样写查询条件,才可以!
只有<=>,才能将两个列都有的NULL给找出来。
- and和or
条件中,同时存在and和or,先计算and后算or,但是一般不建议去记优先级(没那么多脑子),最好办法,还是多加上()。
题目:查询 语文成绩 大于 80 或者 数学成绩 大于70 ,且 英语成绩 大于 70 的学生
select * from exam_result where (chinexe > 80 or math > 70) and english > 70;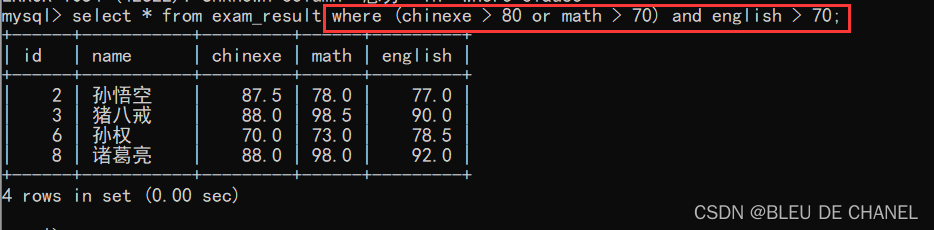
where子句不能使用表达式的别名来进行比较,应该是用表达式来比较
题目:查询总分 200 分以上的学生 正确做法:
正确做法: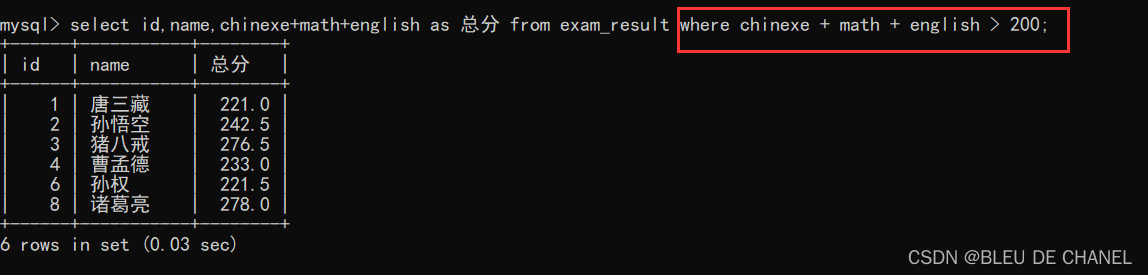 还可以发现这个别名也可以用中文来表示,不用单引号或双引号来引用。
还可以发现这个别名也可以用中文来表示,不用单引号或双引号来引用。范围查询
题目:查询语文成绩在 [80,90] 分同学及语文成绩
方法1:between …and…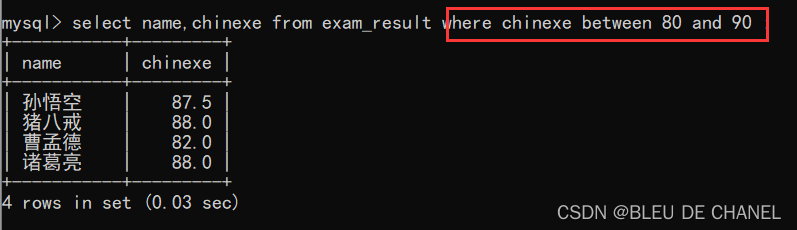
方法2:…>=…and…<=…
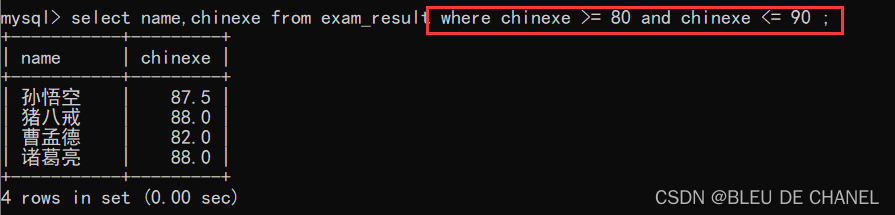 方法3:in
方法3:in
题目:查询数学成绩是78 或者 98 的学生及数学成绩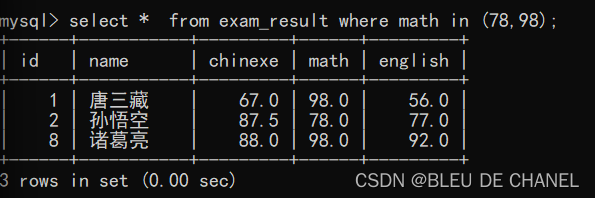 我觉得下面比上面表达式更加美观
我觉得下面比上面表达式更加美观
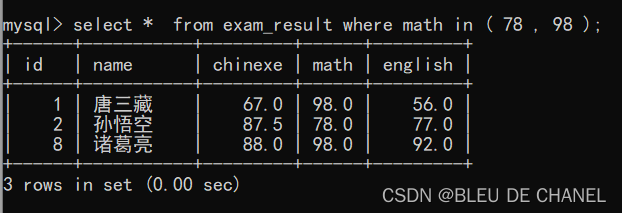 也可以用or来表示
也可以用or来表示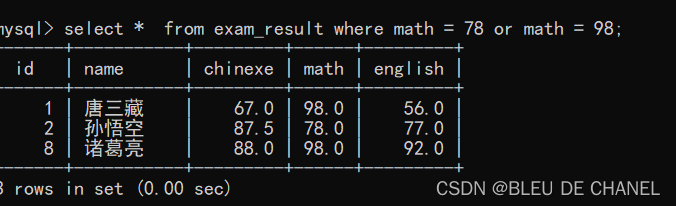
可以发现,sql的关系表达式可以灵活使用,只要说合理,都可以使用,灵活一些!不用那么死,也不要死记硬背!!理解!!
- 模糊查询
根据要求的规定,可以任意把 % 和 _ ,放在项目要求的位置上。
‘%’:匹配任意多个(包括0个)字符
题目:查询姓孙的学生的成绩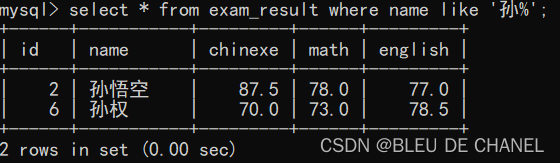
‘_':匹配一个任意字符
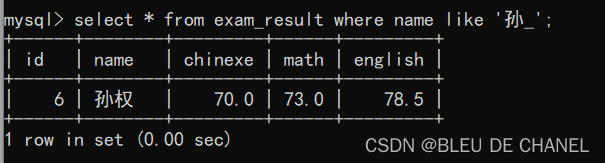 ** 正则表达式**
** 正则表达式**
来描述字符串的规则,使用一些特殊的规则,来描述一个字符串长啥样,查询/进行其他操作的时候,按照这套规则进行匹配
筛选字符串,也是描述几个规则出来
8.限制查询结果的数量
limit~~通过这个关键词来限制查询结果的数量,直接加到查询语句的末尾(where末尾…)——limit N(N就表示这次查询最大结果的数量,反正可以小于或等于N,绝对不能大于N)
为什么要限制结果数量呢?
咱可以联系实际生活,比如我们去查一些资料,会出现很多结果,给我们的感觉就是看不完,就算看完了,也不容易找到下一个(鼠标滚轮太敏感,一下子不知道滑到哪里了)。
如果我们限制每页的最大记录的数量,这样不是会好找一些对吧!
题目:查询成绩表的前5个记录。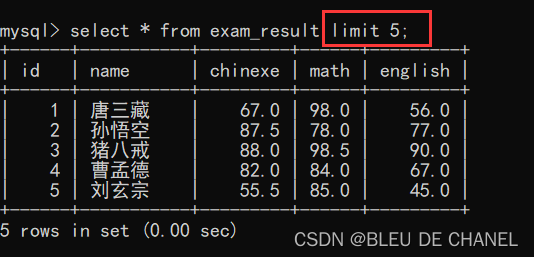
9.分页查询
在数据库中,针对分页查询的支持,主要就是通过limit来实现的。
上述limit N,查到的是前N(第一页)的东西,需要搭配 offset M 就可以指定从第几(M+1)条开始筛选了(注意:offset 的值从0开始计算的,可以把它比作数组的下标)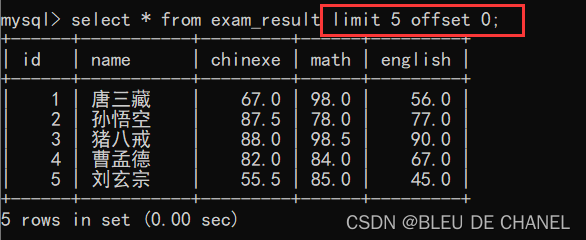
 limit 5 offset 0的意思是从第1(0+1)条数据开始数,总共输出5条数据。
limit 5 offset 0的意思是从第1(0+1)条数据开始数,总共输出5条数据。
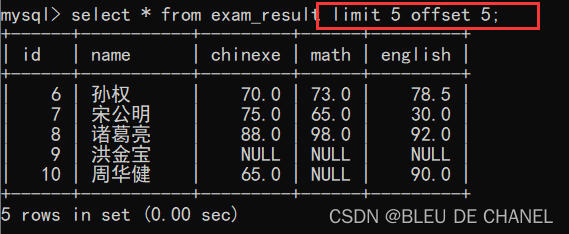
limit 5 offset 5:从第6(5+1)条数据开始数,总共输出5条数据。
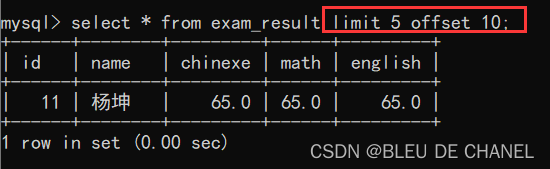
limit 5 offset 10:从第11(10+1)条数据开始数,虽然已经不够5条数据了,但是只要输出剩下的就好啦。(<=N即可)。
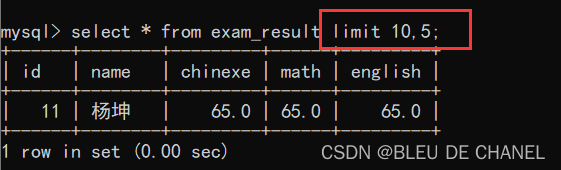
除了上述的表达之外,还有另一种表达,但是不推荐,容易混淆!
limit M(从第几条开始),N(一次最大输出多少记录)
修改
update 表名 set 列名1=值1,列名2=值2… [ where 条件;limit;order by ];
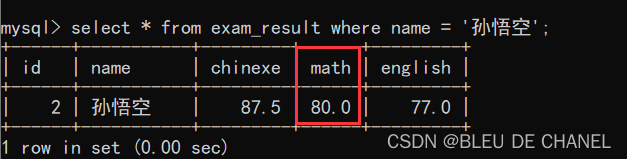
题目:将孙悟空的数学成绩改成80
 题目:将语文成绩和数学成绩中出现NULL,全部改成0
题目:将语文成绩和数学成绩中出现NULL,全部改成0
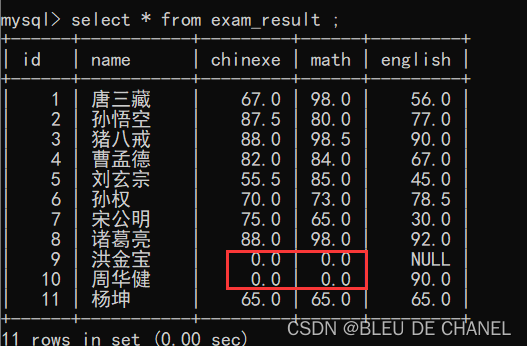 可以发现update 还可以同时去修改对个列,多个列要用 , 来隔开。
可以发现update 还可以同时去修改对个列,多个列要用 , 来隔开。
题目:将所有学生的语文成绩减5分
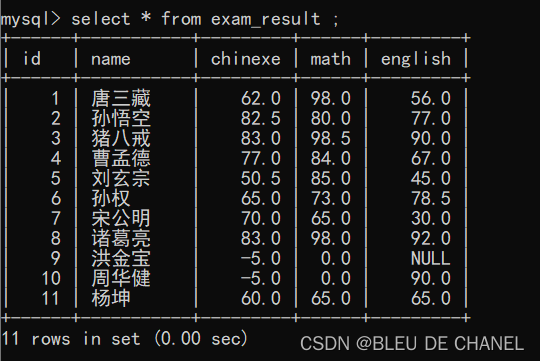 如果没写where子句,就是匹配所有的行,如果有的行是NULL,空值是没办法进行算术运算的
如果没写where子句,就是匹配所有的行,如果有的行是NULL,空值是没办法进行算术运算的
且也不要写成 chinexe-5=chinexe,错误的哈!
题目:给总成绩倒数四名的同学,数学成绩设置为10分
思路:先算总成绩,再按照总成绩进行排序,取结果的前4个

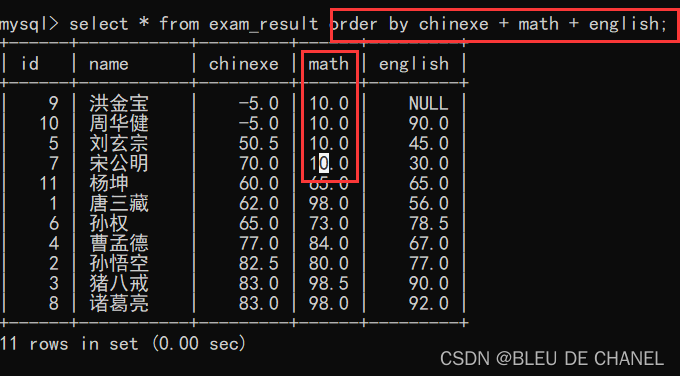 update 还可以搭配 order by /limit 等子句进行使用。
update 还可以搭配 order by /limit 等子句进行使用。
update操作也是非常危险滴!
删除表的内容
delete from 表名 [where 条件;limit ;order by];
这个删除也是在修改数据库服务器的硬盘,也是持久化删除。delete 也是危险操作,只要是操作生产环境的数据库,都是非常危险,一定要重视!!!
题目:删除总成绩在倒数前3名的同学和成绩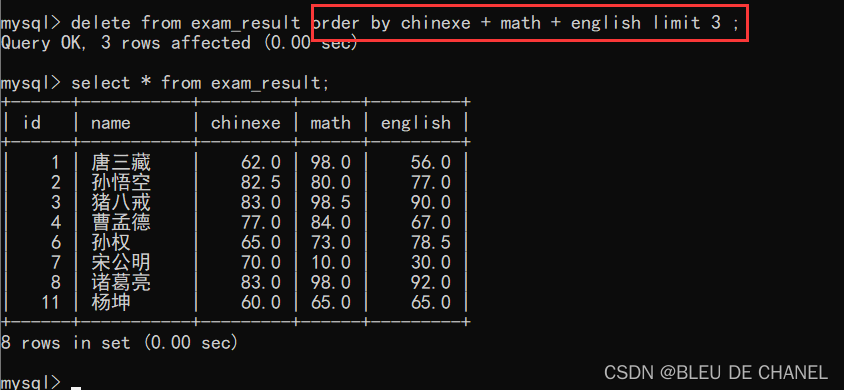
delete和drop的区别
delete只是把表达内容删除,表还是存在的 drop是直接把表删除,如果表中还有数据,则连同数据一起删除
drop是直接把表删除,如果表中还有数据,则连同数据一起删除
针对MySql的小操作
复制:首先选择需要复制的内容,最后点击鼠标右键.
粘贴: 如果是在SQL窗口中,点击Enter ; 否则直接常规处理ctrl+C.
终止输入:输入一般发现输入错误,想终止并不想报错错误,就直接 ctrl+C
查看警告:
show warnings;