一,计算各列数据总和并作为新列添加到末尾。
df['Col_sum'] = df.apply(lambda x: x.sum(), axis=1)
或:
#定义获取各科成绩最大值的函数
def getMax(row):
return max(row["Chinese"],row["Math"],row["English"],row["PE"])
df["max"]=df.apply(lambda row:getMax(row),axis=1)
二,计算各行数据总和并作为新行添加到末尾
df.loc['Row_sum'] = df.apply(lambda x: x.sum())
注:也可以用其他的聚合函数。
原文:https://www.cnblogs.com/wuzhiblog/p/python_new_row_or_col.html
三;pandas 使用apply同时处理两列数据
df = pd.DataFrame ({'a' : np.random.randn(6),
'b' : ['foo', 'bar'] * 3,
'c' : np.random.randn(6)})
def my_test(a, b):
return a + b
df['Value'] = df.apply(lambda row: my_test(row['a'], row['c']), axis=1)
print df
原文:https://blog.csdn.net/leokingszx/article/details/78266559
四:分组运算
可以结合groupby与transform来方便地实现类似SQL中的聚合运算的操作:
聚合函数
结合groupby与agg实现SQL中的分组聚合运算操作,需要使用相应的聚合函数:
详见:https://blog.csdn.net/zwhooo/article/details/79696558
五,Pandas 操作多个列进行运算,并生成新列的方法
df.eval('new1 = 气温 + 湿度 + PM2P5' , inplace=True)
inplace参数: 是否在原数据上操作。
inplace=False 将会生成新的DataFrame
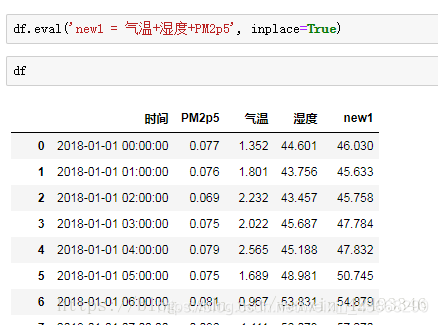
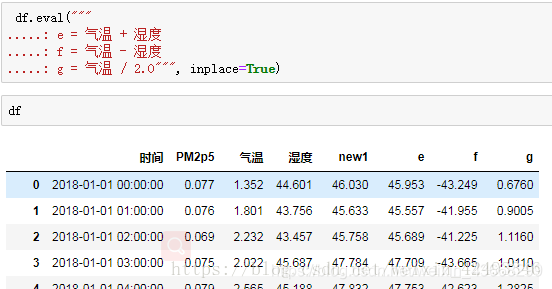
一次新增多个列可以使用
df.eval("""
.....: e = 气温 + 湿度
.....: f = 气温 - 湿度
.....: g = 气温 / 2.0""", inplace=True)
六,查询函数 query。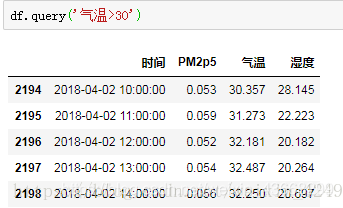
也可以使用inpalce参数。
详见:https://blog.csdn.net/weixin_42493346/article/details/80744159
版权声明:本文为weixin_43668299原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。