原文作者:蓦风星吟
目录
正态分布(德语:Normalverteilung;英语:normal distribution)又名高斯分布(德语:Gauß-Verteilung;英语:Gaussian distribution, 以德国数学家卡尔·弗里德里希·高斯的姓冠名)。想必这个大名鼎鼎的分布,跟高斯这个名字一样,如雷贯耳,只要稍有数学常识,都应该不陌生吧,即便你已经记不太清楚它的密度函数具体长什么样子了,没关系,密度函数长这样:
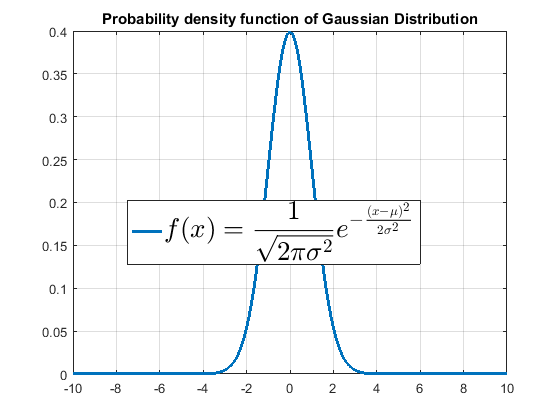
“对对对”,想必你立刻就会说:“我就记得长这个样子!”确实,正态分布太有名了,也确实有用的很,本质上讲正态分布是整个概率论与数理统计的核心,讲的广一点呢,也是现代科学,包括迄今为止被广泛应用在各类工程中的公式、定理、模型的基石。说的彻底一点呢,若是没有这样完美的正态分布,或许说不定这个世界现在你所看到的美好也就荡然无存了。比如,“什么?”,“对,说你的呢,你的Dota中最钟爱的混沌骑士CK妥妥是没有了,混沌的世界,电脑真的好难懂啊!”再比如,“什么?”,“没错,说的就是你,你的美图你的PS都没有了,滤波器都找不到了,你还想要美颜?小心分分钟变贞子哦!”当然我还是比较相信,大多数的你们还是对这个正态分布分布的重要是还是略知一二的,不过你们可曾细细的了解过正态分布呢?下面先来看这个所谓的高斯分布正态分布的前世今生吧。
正态分布的前世今生
正态分布最早是由一个叫亚伯拉罕·棣莫弗(Abraham de Moivre,简称棣莫弗,法语发音为(IPA)[də mwavʀ])(1667年5月26日-1754年11月27日)的法国人在其对二项分布的研究中提出的。什么?棣莫弗,这是谁,怎么那么陌生呢?想想你学过的复数,想想三角函数!哦,好像,好像记得上学的时候有学过什么棣莫弗公式,貌似它把三角函数跟复数联系起来了。对,就是这个棣莫弗。准确的来讲,正是他给出了复数的三角表达式,这个东西的对后世基于复变函数的各种学科的发展来说,这个意义那大大的!当然或许你关注的点并不是,这个叫棣莫弗的人,而是二项分布,正在脑海中苦苦搜寻什么是二项分布。想想那个无聊的投硬币游戏,想想那个一次两次的数数经历。对,就是这个n次重复投硬币游戏里面傻傻地数出现k次正面的,这个概率分布就是服从所谓的二项分布[2]。当然这里还有有趣的二项式系数的,国人也叫杨辉三角的东西哦!
东西好像扯的有点远了,回来回来!回到正题,这个所谓的二项分布跟正态分布有什么关系呢?这就是棣莫弗这人的主要成就之一啦,他1734年发表的一篇关于二项分布文章中提出的,当二项随机变数的位置参数n很大及形状参数p为1/2时,则所推导出二项分布的近似分布函数就是正态分布。当然这个其实就是个极限问题,有兴趣之后我们可以具体讨论。但是这个结果确实是我们直观上可以相像的,当然你还是无法想像,那我们来看看这个计算机的模拟试验。
clc
clear
close all
R3 = binornd(100,0.5,100,1);
R4 = binornd(1000,0.5,1000,1);
R5 = binornd(10000,0.5,10000,1);
figure
subplot(1,3,1)
histfit(R3)
title('N = 100')
subplot(1,3,2)
histfit(R4)
title('N = 1000')
subplot(1,3,3)
histfit(R5)
title('N = 10000')
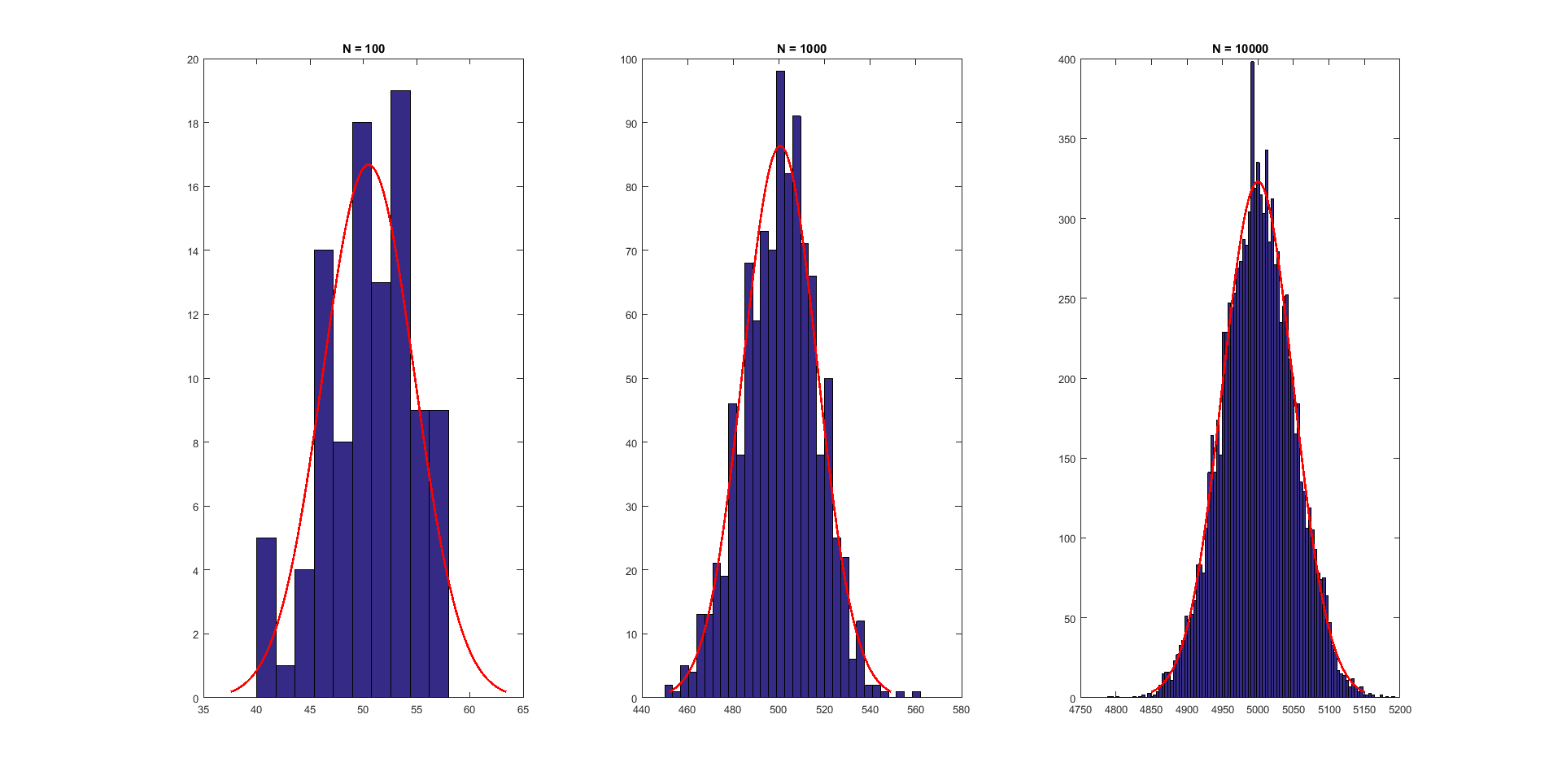
我们的R3,R4,R5分别是从N=100,1000,10000次二项分布中生成的,清晰的看到随着N的增加,这个分布越来越接近我们这个具有代表性的的这个正态分布了。事实上,这个东西的严格的讲还有特别厉害的名字,中心极限定理, wiki上有一段有趣的历史。Tijms (2004, p.169) 写到:
中心极限定理有着有趣的历史。这个定理的第一版被 法国 数学家 棣莫弗发现,他在1733年发表的卓越论文中使用 正态分布去估计大量抛掷硬币出现正面次数的分布。这个超越时代的成果险些被历史遗忘,所幸著名法国数学家 拉普拉斯在1812年发表的巨著 Théorie Analytique des Probabilités中拯救了这个默默无名的理论。
拉普拉斯扩展了 棣莫弗的理论,指出二项分布可用正态分布逼近。但同 棣莫弗一样, 拉普拉斯的发现在当时并未引起很大反响。直到十九世纪末中心极限定理的重要性才被世人所知。1901年,俄国数学家 里雅普诺夫用更普通的随机变量定义中心极限定理并在数学上进行了精确的证明。如今, 中心极限定理被认为是(非正式地) 概率论 中的首席定理。
然而,正态分布真正走入人们视线的并不是由这个无聊的投硬币试验所得的二项分布的逼近,而是实实在在的工程误差分析中应用。据说wiki说,拉普拉斯在误差分析试验中使用了正态分布。勒让德于1805年引入最小二乘法这一重要方法;而高斯则宣称他早在1794年就使用了该方法,并通过假设误差服从正态分布给出了严格的证明。(看来大牛们为了版权也是的撕厉害,不过事实似乎表明,最后还是高斯赢了,毕竟现在也叫高斯分布)
高斯对正态分布的导出准备
之前我们说到高斯在测量误差研究中发现了正态分布,并且这项研究也成为了当代统计学的中重要的思想--最大似然的源头。下面我们来仔细看看,他是如何导出这个完美的分布的。
首先我们要解释几个概念,第一个是似然(Likelihood)。什么是似然,简单通俗的来讲就是,一系列的概率密度函数的乘积,说白了也就是还是一种特别的复合的“概率”。比如对于正态分布,如果有独立同分布的观察值,则其的似然为:
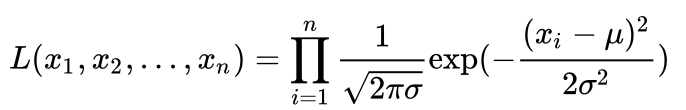
当然,我们也可以看到对于正态分布,这里还依赖于两个参数,就是,
。所以我们其实也可以将这个似然看成关于
,
的二元函数。当然在给其中一个参数的情况下,我们也可以将其看成关于另一个的函数。另外,从数值上讲概率是在[0,1],所以n个连乘之后也还是在[0,1]。
第二点是最大似然(Maximum Likelihood),刚才说到对正态这个似然,当然在给其中一个参数的情况下,我们也可以将其看成关于另一个的函数。因而,如果我们给定一个标准,那么是不是可以基于观测值对其中的未知参数进行估计呢?这是个非常朴素想法,就好比方程的思想,原本一个函数,给定自变量,那么对应的函数值自然可以计算。反过来,若是给定一定函数值,理论上我们也希望试图找到对应的自变量。这个想法再进一步就是,给定一个标准,比如最大,最小,我们基于这个标准,也试图去寻找对应达到标准 (比如最大,最小函数值)所对应的自变量,这就是参数估计的思想。回到最大似然法的核心,在这里这个标准就是使得似然函数(关于某一或某一些参数的)最大,然后去估计对应的参数(基于观测值)的值。至于为什么选择似然函数呢,其实主要也是因为似然函数朴素简单的表达出一种概率,一个基于n次观测的整体的概率,这样的情况下,我们自然朴素的认为或者是希望,似然中包含的合理的参数应该使得我们整体的概率最大的一个或者是一组,因此才被我们观测到。
好了,介绍这个这个,我们继续重新回到正题,如何基于一些假设导出正态分布。实际的测量中,若是分布均值的真实值,当然真实值我们永远都不可能知道,因为我们活在一个误差的世界,然后现在希望根据观测值尽可能的去估计它。首先我们记观察误差的分布密度函数为,然后给以下假设(数学的世界充满假设,没有假设的数学,如没有根的浮萍,毫无意义)。
- 关于对称,且对于一切成立.
- 具有连续的导函数。
下面我们来考察这两个假设的合理性,首先关于对称,这个非常合理,因为我们的似然误差分布密度为,也就是观测值与真实均值的查,这个自然在左在右可能性一样喽,不然这个观测试验也就有偏颇了,当然另一个理由也就是经验了。再说非负性要求,这个也是必须的,概率么自然是非负的啦。第二条,连续的导函数,这个自然主要是为了推倒的方便啦。什么?不知道什么是导函数,这个你只能回去看基础的课本了。。。
由于我们的观察误差的分布密度函数为,那么此时的似然函数就是
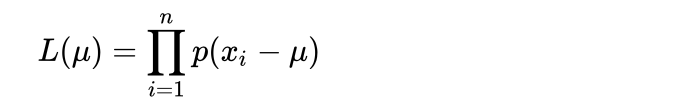
实际上,这个似然函数刻画了这组观测值落在真实均值附近的可能性大小。当然此处高斯还给出了一个重要的假设:
观察值的平均值作为未知参数的估计值时使得似然最大。
事实上,下面的推导主要还是依赖于这个假设。回头看看这个假设,其实也是符合逻辑和直观感受的,这表明观测的均值作为一个理论均值可以让似然函数最大。