第一章: 数据结构绪论
1.什么是程序:程序 = 数据结构 + 算法
2.逻辑结构&物理结构的区别用法
基本的目标就是将数据及其逻辑关系存储到计算机的内存中
一:逻辑结构:
逻辑结构是指数据对象中数据元素之间的相互关系
逻辑结构是面向问题的
A:集合结构:数据元素除了同属于一个集合外,它们之间没有其他关系
B:线性结构:数据元素之间是一对一关系
C:树形结构:数据元素之间呈现一对多关系
D:图形结构:数据元素是多对多关系
二:物理结构
物理结构是指数据的逻辑结构在计算机中的存储形式,因此也称为存储结构
物理结构是面向计算机的
A:什么是数据:
数据是数据元素的集合
那么根据物理结构的定义,实际上就是如何把数据元素存储到计算机的存储器中
B:什么是存储器
存储器主要是针对内存而言的,
像硬盘,软盘,光盘等外部存储器的数据组织通常用文件结构来描述
3.顺序存储&链式存储的区别用法
数据的存储结构应正确反映数据元素之间的逻辑关系
数据元素的存储结构形式有两种:顺序存储 和 链式存储
一:顺序存储结构
是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的
二: 链式存储结构
是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的
存储结构(数据和关系怎么存到计算机里)
- 顺序存储结构:按元素的顺序来存储,C语言-数组
- 链式存储结构:任意存储单元来存储,C语言-指针
- 索引存储结构:存储信息的同时,建立目录(索引表)
- 散列存储结构:节点关键字计算出节点存储位置
4.课程内容
1.数据结构=逻辑结构+存储结构+算法
2.基本的逻辑结构
线性结构
- 线性表
- 栈和队列
- 串
- 数组和广义表
非线性结构
- 树
- 图
3.存储结构
- 顺序存储
- 链式存储
4.基本的数据处理技术(算法)
- 查找技术
- 排序技术
5.数据结构在计算机中的地位
C语言学完后,先学基本的数据结构和算法,
包括 线性表,栈和队列,串,数组和广义表,树 , 图,和基本的查找排序操作,
然后学习C++,然后学习实现高级的数据结构和算法

6.数据结构研究内容
数据结构=逻辑结构(对象怎么表示)+存储结构(对象怎么存到计算机里)+算法(对计算机中的对象怎么增删查改等)
7.通常,用计算机解题一个问题的步骤
1.具体问题抽象成数学模型
- 分析问题
- 提取操作对象=>数据结构
- 找出操作对象之间的关系=>数据结构
- 用数学语言描述
2.设计算法
3.编程、调试、运行
8.基本概念
数据:是能输入计算机且能被计算机处理的各种符号的集合;包括:数值型的数据:整数、实数等 非数值型的数据.文字、图像、图形、声音等
数据元素:是数据的基本单位,用作整体考虑
数据对象:性质相同的数据元素的集合
数据结构:数据元素相互之间的关系
数据项:数据元素里面的最小单位
数据>数据元素>数据项
数据类型和抽象数据类型
数据类型:
数据类型 = 性质相同的一组值的集合 + 值集合上的一组操作(例如+ - * /)
数据类型规定:数据的取值范围和操作
例如C语言的int,char等
抽象数据类型:
抽象是从众多的事物中抽取出共同的、本质性的特征,而舍弃其非本质的特征的过程
抽象数据类型=数据对象+数据对象的关系集合+对关系集合基本操作
形式定义:简洁严谨的数学定义
抽象数据类型的定义格式:
ADT 抽象数据类型名{
数据对象:<数据对象的定义>//伪代码
数据关系:<数据关系的定义>//伪代码
基本操作:<基本操作的定义>
}ADT 抽象数据类型名
基本操作:
基本操作名(参数表)
初始条件:<描述>
操作结果:<描述>
参数表(类似C语言函数传参):
赋值参数:输入值,无结果(传值)
引用参数:输入值,有结果,&开头(传指针)
初始条件(对错误有处理能力):
描述操作执行之前数据结构和参数应该满足的条件
不满足:失败+错误信息
空:省略
操作结果:
操作正常,数据结构变化状况和结果
例子:圆
ADT Circle{
数据对象:D={r,x,y|r,x,y都是实数}
数据关系:R={<r,x,y>|r是半径,<x,y>是圆心坐标}
基本操作:
Circle(&C,r,x,y)
操作结果:构造一个圆
double Area(C)
初始条件:圆已存在
操作结果:计算面积
double Circumference(C)
初始条件:圆已存在
操作结果:计算周长
......
}代码实践:要求:定义圆,求圆的面积和周长
#include<stdio.h>
#include<assert.h>
#define PI 3.141592
typedef struct Circle {
double r;
double x;
double y;
}C;
void Circle(C* pc)
{
pc->r = 1;
pc->x = 0;
pc->y = 0;
}
double Area(const C* pc)
{
assert(pc!=NULL);
double ret = 0;
double r = pc->r;
ret = PI * r * r;
return ret;
}
double Circumference(C* pc)
{
assert(pc != NULL);
double ret = 0;
double r = pc->r;
ret = 2* PI * r;
return ret;
}
int main()
{
C c = {0};
//操作结果:构造一个圆
Circle(&c);
//操作结果:计算面积
double area = Area(&c);
//操作结果:计算周长
double cir = Circumference(&c);
printf("Area = %f \nCircumference = %f \n",area,cir);
return 0;
}
第二章:算法
1.定义
算法是描述解决问题的方法
算法的描述:
- 自然语言:英语、中文
- 流程图:传统流程图,NS流程图
- 伪代码:类语言:类C语言
- 程序代码:C语言,Java语言
2.特性
- 有穷性:有限步骤,每个步骤有限时间
- 确定性:相同输入,相同输出
- 可行性:目前技术可以达到
- 输入:大于等于0输入
- 输出:大于等于1个输出
好的算法:应该具有正确性,可读性,健壮性,高效率和低存储量的特征
- 正确性:精选测试的刁难数据,测试通过
- 可读性:别人读得懂
- 健壮性:输入非法数据,也可以很好执行
- 高效性:少时间,存储空间少
3.算法时间效率度量
时间效率:程序在计算机上执行所消耗的时间
- 时间效率两种度量算法:
- 事后统计:写出程序,跑起来;缺点:软硬件影响效率
- 事前分析:估算,大概花多少(常用) 算法运行时间=(赋值,比较,移动等)简单语句所需时间 * 次数(语句频度);简单语句所需时间与算法无关
算法时间效率用时间复杂度度量
- 时间复杂度:消耗时间的数量级
- 数量级:n的最高次方
- (1)可以忽略加法常数
- O(2n + 3) = O(2n)
- (2)与最高次项相乘的常数可忽略
- O(2n^2) = O(n^2)
- (3) 最高次项的指数大的,函数随着 n 的增长,结果也会变得增长得更快
- O(n^3) > O(n^2)
- (4)判断一个算法的(时间)效率时,函数中常数和其他次要项常常可以忽略,而更应该关注主项(最高阶项)的阶数
O(2n^2) = O(n^2+3n+1)O(n^3) > O(n^2)
4.时间复杂度&空间复杂度的区别用法
一:时间复杂度:大 O 阶推导方法
1.定义: 时间复杂度所需消耗的时间即基本操作执行次数
推荐网址了解:https://blog.csdn.net/qq_41523096/article/details/82142747
2.时间复杂度的计算
- 找到语句频度最大的基本语句
- 写出该语句的 f(n) (n为执行次数,n可以是表达式)
- 忽略低次幂项和最高次项的系数
- 去数量级用"O"表示
3.举例:
例1)
int i, j;
for (i = 0; i < n; ++i) {
for (j = i; j < n; ++j) {
/*时间复杂度为 O(1) 的程序步骤序列 */
}
}对于外循环,其时间复杂度为 O(n);
对于内循环环,当 i=0 时,内循环执行了 n 次,当 i=1 时,执行了 n-1 次,······当 i=n-1 时,执行了 1 次。
因此内循环总的执行次数为:
根据大 O 阶推导方法,最终上述代码的时间复杂度为 :
例2)
for(i=1;i<=n;i++)
for(j=1;j<=i;j++)
for(k=1;k<=j;k++)
x+=1;
j个1的和==j
高斯求和=(首相+末项)项数/2==i(i+1)/2
套公式化简
例3)
i=1;
while(i<=n)
i=i*2;循环x次 : i=2^x
i<=n 2^x<=n x<=log2(n)
f(n) = log2(n)
T(n)=O(log n)
4.常见的时间复杂度

5.n在不同问题中含义不同
n越大算法的执行时间越长
- 排序:n为记录数
- 矩阵:n为矩阵的阶数
- 多项式:n为多项式的项数
- 集合:n为元素个数
- 树:n为树的结点个数
- 图:n为图的顶点数或边数
6.输入数据集:算法中的基本操作重复执行的次数还随问题的输入数据集不同而不同
例1:顺序查找
最好时间复杂度 : 最好情况:1次
最坏时间复杂度(最常用) : 最坏情况:n次
平均时间复杂度:O(n)
7.复杂算法时间复杂度计算 :
分成几个容易估算的部分,通过加法取大和乘法相乘计算
加法:复杂度取大

乘法:复杂度相乘

二.空间复杂度
1.定义
算法的空间复杂度通过计算算法所需的存储空间实现,即运行完一个程序所需内存的大小
算法的时间复杂度和空间复杂度是可以相互转化的
2.空间复杂度的计算
利用程序的空间复杂度,可以对程序的运行所需要的内存多少有个预先估计
- 一个算法所需的存储空间用f(n)表示
空间复杂度的计算公式记作:S(n)=O(f(n))其中n为问题的规模S(n)表示空间复杂度
计算方法:
(1)忽略常数,用O(1)表示;举例1:
a = 0
b = 0
printf("%d %d",a,b);
它的空间复杂度O(n)=O(1);(2)递归算法的空间复杂度=递归深度N*每次递归所要的辅助空间 ;举例2:
int fun(int n)
{
int k = 10;
if (n == k)
return n;
else
return fun(++n);
}
递归实现,调用fun函数,每次都创建1个变量k。调用n次,空间复杂度O(n * 1) = O(n)(3)对于单线程来说,递归有运行时堆栈,求的是递归最深的那一次压栈所耗费的空间的个数
因为递归最深的那一次所耗费的空间足以容纳它所有递归过程;
一般情况下,一个程序在机器上执行时:
除了需要存储程序本身的指令,常数,变量和输入数据外
还需要存储对数据操作的存储单元的辅助空间
若输入数据所占空间只取决于问题本身,和算法无关
这样就只需要分析该算法在实现时所需的辅助单元即可。
若算法执行时所需的辅助空间相对于输入数据量而言是个常数,则称此算法为原地工作,空间复杂度为O(1)
3.需存储空间包括以下两部分
(1)固定部分
这部分属于静态空间
这部分空间的大小与输入/输出的数据的个数多少、数值无关
主要包括指令空间(即代码空间)、数据空间(常量、简单变量)等所占的空间
(2)可变空间
这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等
这部分的空间大小与算法有关
三:常用的算法的时间复杂度和空间复杂度

第三章:线性表

1.定义:零个或多个数据元素的有限序列
2.顺序存储结构&链式存储结构的区别和用法
一:线性表的顺序存储结构
1.定义:线性表的顺序存储结构是用一段地址连续的存储单元依次存储线性表的数据元
2.顺序存储示意图如下所示:线性表![]()

3.编号地址:存储器中的每个存储单元都有自己的编号,这个编号称为地址
4.存储位置公式
每个数据元素,不管它是整型,实型还是字符型,它都是需要占用一定的存储单元空间的
假设占用的是c 个存储单元,那么对于线性表的第 i 个数据元素 的存储位置都可以由
推导算出:

5.存取操作时间性能
通过该公式,就可以随时算出线性表中任意位置的地址
不管是第一个还是最后一个,都是相同的时间
也即对于线性表每个位置的存入或者取出数据
对于计算机来说都是相等的时间,也就是一个常数时间
因此,线性表的存取操作时间性能为 O(1)
6.随机存储结构
我们通常将存取操作具备常数性能(O(1))的存储结构称为随机存储结构
7.时间复杂度
(1)对于存取操作
线性表的顺序存储结构,对于存取操作,其时间复杂度为 O(1)
因为元素位置可以直接计算得到
(2)对于插入和删除操作
对于插入和删除操作,其时间复杂度为O(n)
因为插入或删除后,需要移动其余元素
8. 使用场景
因此,线性表顺序存储结构比较适用于元素存取操作较多,增删操作较少的场景
二:线性表的链式存储结构
1.什么是链表
一个或多个结点 组合而成的数据结构称为链表
结点在存储器中的位置是任意的,即逻辑上相邻的数据元素在物理上不一定相邻
这组存储单元既可以是连续的,也可以是不连续的,甚至是零散分布在内存中的任意位置上的
2.结点
结点 一般由两部分内容构成:
(1) 数据域:存储真实数据元素
(2)指针域:存储下一个结点的地址(指针)

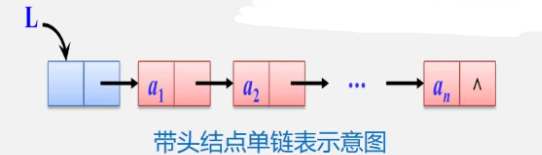
3.头指针&头结点
头结点的数据域可以不存储任何信息,其指针域存储指向第一个结点的指针(即指向头指针)
(1)头指针:一般把链表中的第一个结点称为 头指针,其存储链表的第一个数据元素
(2)头结点:为了能更加方便地对链表进行操作,会在单链表的第一个结点(即头指针)前附设一个结点,称为 头结点
空表:无头结点时,头指针为空时表示空表
头结点好处
1便于首元结点的处理
首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其它位置一致,无须进行特殊处理;
2便于空表和非空表的统一处理
无论链表是否为空,头指针都是指向头结点的非空指针,因此空表和非空表的处理也就统一了。
3.头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值


4.单链表
结点只有一个指针域的链表,称为单链表或线性链表
单链表是由头指针唯一确定,因此单链表可以用头指针的名字来命名。
在线性表的顺序存储结构(即数组)中,其任意一个元素的存储位置可以通过计算得到,因此其数据读取的时间复杂度为 O(1)
单链表的时间复杂度
(1)对于存取操作
而对于单链表结构,假设需要获取第 i 个元素,则必须从第一个结点开始依次进行遍历,直到达到第 i 个结点。因此,对于单链表结构而言,其数据元素读取的时间复杂度为 O(n)
(2)对于插入和删除操作
而对单链表结构来说,对其任意一个位置进行增删操作,其时间复杂度为 O(n)
因为需要先进行遍历找到目标元素,对头指针的增删操作其时间复杂度为 O(1)
5.线性表和单链表那个好
因此,如果只对一个元素进行增删操作,两种结构并不存在优劣之分,
但如果针对多个数据进行增删,由于线性表每一次增删都需要移动 n-i 个元素,即每个元素的操作都为 O(n)
而单链表只在第一次遍历定位目标元素时为O(n)
对后续元素的增删只需简单地赋值移动指针即可,其时间复杂度为O(1)
6. 循环链表
首尾相接的链表称为循环链表
将单链表中的终端结点的指针端由空指针改为指向头结点
就使整个单链表形成一个环
这种头尾相接的单链表称为单循环链表,简称 循环链表(circular linked list)
循环链表不一定需要头结点
优点:从表中任一结点出发均可找到表中其他结点
表的操作常常是在表的首尾位置上进行
一般使用尾指针表示单循环链表:因为时间复杂度比头指针表示单循环链表低
位置R->next->next
位置R
时间复杂度为O(1)

带尾指针循环链表的合并

struct Node* Connect(struct Node* Ta, struct Node* Tb)
{
//p存表头结点
struct Node* p = Ta->next;
//Tb表头连接到Ta表尾
Ta->next = Tb->next->next;
//释放Tb表头结点
free(Tb->next);
//修改指针
Tb->next = p;
return Tb;
}
7.单链表和循环链表的区别
为了使空链表与非空链表处理一致,我们通常设一个头结点(循环链表不一定需要头结点)
主要差异就在于循环的判断条件上
(1)单链表判断条件
为尾结点是否指向空:p->next == NULL
(2)循环链表判断条件
当前结点是否指向头结点:p->next == head 是则当前结点为尾结点
8.双向链表
结点有两个指针域的链表,称为L为双链表
双向链表(double linked list):在单链表的每个结点中,再设置一个指向其前驱结点的指针域prior


双链表插入

代码实现
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define OK 1
#define ERROR -1
//链表的数据域
struct student
{
char name[20];
int num;
};
//链表的样子
struct Node {
struct Node* prior;
struct student data;
struct Node* next;
};
//创建头节点,创建空表
struct Node* creatList_Dul()
{
struct Node* headNode = (struct Node*)malloc(sizeof(struct Node));
if (headNode == NULL)
{
printf("creatList::%s\n", strerror(errno));
}
else
{
headNode->prior = headNode;
headNode->next = headNode;
}
return headNode;
}
//创建节点
struct Node* creatNode_Dul(struct student data)
{
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL)
{
printf("creatNode::%s\n", strerror(errno));
}
else
{
newNode->prior = NULL;
newNode->data = data;
newNode->next = NULL;
}
return newNode;
}
//得到指向第i个节点的指针
struct Node* SearchPos(struct Node* headNode, int i)//头指针
{
//第一个节点为头结点
//第二个节点为首元结点
int j = 1;
struct Node* pMove = headNode;
while (1)
{
if (j == i)
return pMove;
else if (j < i)
{
if (pMove->prior != NULL)
{
pMove = pMove->prior;
j++;
}
}
}
}
//在带头结点的双向循环链表L中第i个位置之前插入元素e
int LisrInsert_Dul(struct Node* L, int i, struct student e)
{
struct Node* p = SearchPos(L, i);
struct Node* s = creatNode_Dul(e);
s->prior = p->prior;
p->prior->next = s;
s->next = p;
p->prior = s;
return OK;
}
int main()
{
struct Node* list = creatList_Dul();
struct student info = {"zhangsan",123456};
LisrInsert_Dul(list, 1, info);
LisrInsert_Dul(list, 2, info);
return 0;
}
双链表删除

1.p->prior->next=p->next;
2.p->next->prior=p->prior;
3.free(p)
9.线性表三例子
例1:一元多项式的计算




问题:如果指数很大,项数很少,会浪费大量的空间
#define _CRT_SECURE_NO_WARNINGS
#define MAX 100
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
int input = 0;
int arr1[MAX] = { 0 };
int arr2[MAX] = { 0 };
int arr3[MAX] = { 0 };
//InitList(&arr1[0]);
//InitList(&arr2[0]);
printf("请输入一元多项式的各项:>");
while (scanf("%d", &input) != EOF)
{
arr1[i] = input;
i++;
printf("输入成功\n");
}
printf("请输入下一个一元多项式的各项:>");
while (scanf("%d", &input) != EOF)
{
arr2[j] = input;
j++;
printf("输入成功\n");
}
int sz = (i > j ?i:j );
for (i = 0; i < sz; i++)
{
arr3[i] = arr1[i] + arr2[i];
}
for (i = 0; i < sz; i++)
{
printf("%d ",arr3[i]);
}
return 0;
}
/*
请输入一元多项式的各项:>1 2 3 4 5 6 7 8 9
输入成功
输入成功
输入成功
输入成功
输入成功
输入成功
输入成功
输入成功
输入成功
^Z
^Z
^Z
请输入下一个一元多项式的各项:>9 8 7 6 5
输入成功
输入成功
输入成功
输入成功
输入成功
^Z
^Z
^Z
10 10 10 10 10 6 7 8 9
C:\Users\93983\source\repos\many_1_20\Debug\many_1_20.exe (进程 8208)已退出,代码为 0。
要在调试停止时自动关闭控制台,请启用“工具”->“选项”->“调试”->“调试停止时自动关闭控制台”。
按任意键关闭此窗口. . .
*/例2 : 稀疏多项式(改进:减少存储空间)
1.数据表示

2.通过两个数据表示一项 , p为系数 , e为指数

![]()
![]()
3.创建新的数组c存储结果,遍历数组a,b

4.解决 "c的数组大小不知道要设置多大" 问题:使用链式存储结构,也是使用链表


例三:图书信息管理系统


解决方法:
1.图书顺序表
2.图书链表
10.以通讯录讲解----线性表的基本操作
如何描述线性表:

通讯录就是一个线性表,存放MAX个元素和当前已经初始化的元素的个数
数据对象:每个元素是一个人的结构体
数据关系:每个人都属于这个线性表
基本操作:增删查改等
静态通讯录
#define _CRT_SECURE_NO_WARNINGS
#define MAX 1000
#define MAX_NAME 20
#define MAX_TELE 12
#define MAX_SEX 5
#define MAX_ADDR 30
#include<stdio.h>
#include<string.h>
//人物定义
typedef struct PeoInfo
{
char name[MAX_NAME];
int age;
char sex[MAX_SEX];
char tele[MAX_TELE];
char addr[MAX_ADDR];
}PeoInfo;
//通讯录定义
typedef struct Contact
{
PeoInfo data[MAX];//创建1000个人物格子
int size;//记录当前已经有点元素个数
}Contact;
动态通讯录
#define _CRT_SECURE_NO_WARNINGS
//动态增加版本:默认可以存放3个人的信息
//当发现当前通讯录满的时候,我们进行扩容,一次增加2个人的信息
//3 5 7 9...
//#define MAX 1000
#define DEFAULT_SZ 3//默认可以存放3个人的信息
#define MAX_NAME 20
#define MAX_TELE 12
#define MAX_SEX 5
#define MAX_ADDR 30
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
//人物定义
typedef struct PeoInfo
{
char name[MAX_NAME];
int age;
char sex[MAX_SEX];
char tele[MAX_TELE];
char addr[MAX_ADDR];
}PeoInfo;
//通讯录定义
typedef struct Contact
{
PeoInfo* data;//创建指针
int size;//记录当前已经有点元素个数
int capacity;//当前通讯录最多可以放几个元素
}Contact;
线性表的基本操作
初始化

静态通讯录
//main函数中
InitContact(&con);
//函数主体
void InitContact(Contact* ps)
{
memset(ps->data, 0, sizeof(ps->data));
ps->size = 0;//通讯录最初只有一个元素
}动态通讯录
void InitContact(Contact* ps)
{
ps->data = (PeoInfo*)malloc(DEFAULT_SZ * sizeof(PeoInfo));
if (ps->data == NULL)
{
return;
}
ps->size = 0;//通讯录最初只有一个元素
ps->capacity = DEFAULT_SZ;
}
删除

动态通讯录
void DestroyContact(Contact* ps)
{
free(ps->data);
ps->data = NULL;
}判断是否为空

静态通讯录/动态通讯录
int IsEmpty(Contact* ps)
{
if (ps->size == 0)
return 1;
else
return 0;
}
求长度

静态通讯录/动态通讯录
int ContactLength(Contact* ps)
{
return ps->size;
}
得到元素

静态通讯录/动态通讯录
//通过名字找所对应人的下标
static int FindByName(const Contact* ps, char name[MAX_NAME])
{
int i = 0;
for (i = 0; i < ps->size; i++)
{
if (0 == strcmp(ps->data[i].name, name))
{
return i;
}
}
return -1;//找不到
}
得到第一个满足XX条件的元素

同得到元素,只不过将比较封装成compare函数
得到元素e的前一个元素

同得到元素下标-1
得到元素e的后一个元素

同得到元素下标+1
在元素 i 前插入一个元素 e


尾插法:在通讯录末尾增加一个元素
静态通讯录
void AddContact(Contact* ps)
{
if (ps->size == MAX)
{
printf("通讯录已满,无法添加\n");
}
else
{
printf("请输入添加人的名字:>");
scanf("%s", ps->data[ps->size].name);
printf("请输入添加人的年龄:>");
scanf("%d", &(ps->data[ps->size].age));
printf("请输入添加人的性别:>");
scanf("%s", ps->data[ps->size].sex);
printf("请输入添加人的电话:>");
scanf("%s", ps->data[ps->size].tele);
printf("请输入添加人的地址:>");
scanf("%s", ps->data[ps->size].addr);
ps->size++;
printf("添加成功\n");
}
}动态通讯录
void AddContact(Contact* ps)
{
//检测当前通讯录的容量
//1.如果满了,就增加空间
//2.如果没满,啥也不干
CheckCapacity(ps);
//增加数据
printf("请输入添加人的名字:>");
scanf("%s", ps->data[ps->size].name);
printf("请输入添加人的年龄:>");
scanf("%d", &(ps->data[ps->size].age));
printf("请输入添加人的性别:>");
scanf("%s", ps->data[ps->size].sex);
printf("请输入添加人的电话:>");
scanf("%s", ps->data[ps->size].tele);
printf("请输入添加人的地址:>");
scanf("%s", ps->data[ps->size].addr);
ps->size++;
printf("添加成功\n");
}
//增容函数
void CheckCapacity(Contact* ps)
{
if (ps->size == ps->capacity)
{
PeoInfo* ptr = realloc(ps->data, (ps->capacity + 2) * sizeof(PeoInfo));
if (ptr != NULL)
{
ps->data = ptr;
ps->capacity += 2;
printf("增容成功\n");
}
else
{
printf("增容失败\n");
}
}
}在下标为i之前插入元素
静态通讯录
void AddContact(Contact* ps)
{
if (ps->size == MAX)
{
printf("通讯录已满,无法添加\n");
}
else
{
int i = 0;
printf("请输入要插在第几个人之前:>");
scanf("%d",&i);
i--;
int j = ps->size;
//移动包括下标为i在内的之后的元素
while (j >= i)
{
strcpy(ps->data[j + 1].name, ps->data[j].name);
ps->data[j + 1].age = ps->data[j].age;
strcpy(ps->data[j + 1].sex, ps->data[j].sex);
strcpy(ps->data[j + 1].tele, ps->data[j].tele);
strcpy(ps->data[j + 1].addr, ps->data[j].addr);
j--;
}
//在i处插入
printf("请输入添加人的名字:>");
scanf("%s", ps->data[i].name);
printf("请输入添加人的年龄:>");
scanf("%d", &(ps->data[i].age));
printf("请输入添加人的性别:>");
scanf("%s", ps->data[i].sex);
printf("请输入添加人的电话:>");
scanf("%s", ps->data[i].tele);
printf("请输入添加人的地址:>");
scanf("%s", ps->data[i].addr);
ps->size++;
printf("添加成功\n");
}
}
动态通讯录
void AddContact(Contact* ps)
{
//检测当前通讯录的容量
//1.如果满了,就增加空间
//2.如果没满,啥也不干
CheckCapacity(ps);
int i = 0;
printf("请输入要插在第几个人之前:>");
scanf("%d", &i);
i--;
int j = ps->size;
//移动包括下标为i在内的之后的元素
while (j >= i)
{
strcpy(ps->data[j + 1].name, ps->data[j].name);
ps->data[j + 1].age = ps->data[j].age;
strcpy(ps->data[j + 1].sex, ps->data[j].sex);
strcpy(ps->data[j + 1].tele, ps->data[j].tele);
strcpy(ps->data[j + 1].addr, ps->data[j].addr);
j--;
}
//增加数据
printf("请输入添加人的名字:>");
scanf("%s", ps->data[ps->size].name);
printf("请输入添加人的年龄:>");
scanf("%d", &(ps->data[ps->size].age));
printf("请输入添加人的性别:>");
scanf("%s", ps->data[ps->size].sex);
printf("请输入添加人的电话:>");
scanf("%s", ps->data[ps->size].tele);
printf("请输入添加人的地址:>");
scanf("%s", ps->data[ps->size].addr);
ps->size++;
printf("添加成功\n");
}
void CheckCapacity(Contact* ps)
{
if (ps->size == ps->capacity)
{
PeoInfo* ptr = realloc(ps->data, (ps->capacity + 2) * sizeof(PeoInfo));
if (ptr != NULL)
{
ps->data = ptr;
ps->capacity += 2;
printf("增容成功\n");
}
else
{
printf("增容失败\n");
}
}
}
删除元素i

静态通讯录 / 动态通讯录
void DelContact(Contact* ps)
{
char name[MAX_NAME];
printf("请输入要删除人的名字:>");
scanf("%s", name);
//1.查找要删除的人在什么位置
//找到返回名字所在的元素的下标
//找不到返回-1
int pos = FindByName(ps, name);
if (pos == -1)
{
printf("要删除的人不存在\n");
}
else
{
//删除数据
int j = 0;
for (j = pos; j < ps->size - 1; j++)
{
ps->data[j] = ps->data[j + 1];
}
ps->size--;
printf("删除成功\n");
}
}
遍历线性表,对每一个元素进行visited函数的操作

静态通讯录 / 动态通讯录:打印通讯录
void ShowContact(const Contact* ps)
{
if (ps->size == 0)
{
printf("通讯录为空\n");
}
else
{
int i = 0;
printf("%-20s\t%-4s\t%-5s\t%-12s\t%-20s\n", "名字", "年龄", "性别", "电话", "住址");
for (i = 0; i < ps->size; i++)
{
printf("%-20s\t%-4d\t%-5s\t%-12s\t%-20s\n",
ps->data[i].name,
ps->data[i].age,
ps->data[i].sex,
ps->data[i].tele,
ps->data[i].addr
);
}
}
}静态通讯录的实现 https://blog.csdn.net/aiqq136/article/details/112980281
动态通讯录的实现 https://blog.csdn.net/aiqq136/article/details/113061034
文件动态通讯录的实现 https://blog.csdn.net/aiqq136/article/details/113096058
顺序表(线性表的顺序存储结构)的特点
(1)利用数据元素的存储位置表示线性表中相邻数据元素之间的前后关系即线性表的逻辑结构与存储结构一致
(2)在访问线性表时,可以快速地计算出任何一个数据元素的存储地址。因此可以粗略地认为,访问每个元素所花时间相等,这种存取元素的方法被称为随机存取法
优点:
- 存储密度大(结点本身所占存储量/结点结构所占存储量)
- 可以随机存取表中任一元素
缺点:
- 在插入、删除某一元素时,需要移动大量元素浪费存储空间
- 属于静态存储形式,数据元素的个数不能自由扩充
为克服这一缺点 : 链表
以学生信息为例子介绍单链表基本操作的实现
创建表头,即单链表的初始化,即返回头指针

创建节点

打印节点,遍历节点

表头法插入

链表的删除:指定位置的删除

#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
//链表的数据域
struct student
{
char name[20];
int num;
};
//链表的样子
struct Node {
struct student data;
struct Node* next;
};
//菜单
void menu()
{
printf("############1.ADD 2.DEV ################\n");
printf("############3.SEARCH 4.MODIFY################\n");
printf("############5.SHOW 6.CLEAR ################\n");
printf("############7.DESTROY 0.EXIT ################\n");
}
enum Option
{
EXIT,
ADD,
DEV,
SEARCH,
MODIFY,
SHOW,
CLEAR,
DESTROY
};
//创建表头,即单链表的初始化,即返回头指针
struct Node* creatList()
{
struct Node* headNode = (struct Node*)malloc(sizeof(struct Node));
//headNode 成为了结构体变量
if (headNode == NULL)
{
//打印错误原因的一个方式
printf("creatList::%s\n", strerror(errno));
//Not enough space
}
else
{
headNode->next = NULL;
}
return headNode;
}
//创建节点
struct Node* creatNode(struct student data)
{
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL)
{
printf("creatNode::%s\n", strerror(errno));
}
else
{
newNode->data = data;
newNode->next = NULL;
}
return newNode;
}
//打印节点,遍历节点
void printList(struct Node* headNode)
{
struct Node* pMove = headNode->next;
printf("name\tnum\n");
//当pMove不是空指针
while (pMove)
{
printf("%s\t%d\n", pMove->data.name, pMove->data.num);
pMove = pMove->next;
}
printf("\n");
}
//表头法插入
void insertNodeByHead(struct Node* headNode, struct student data)
{
//1.创建插入的结点
struct Node* newNode = creatNode(data);
newNode->next = headNode->next;
headNode->next = newNode;
}
//表尾法插入
void insertNodeByEnd(struct Node* headNode, struct student data)
{
struct Node* newNode = creatNode(data);
struct Node* pMove = headNode;
while (pMove->next)
{
pMove = pMove->next;
}
pMove->next = newNode;
}
//得到指向第i个节点的指针
struct Node* SearchPos(struct Node* headNode,int i)//头指针
{
//第一个节点为头结点
//第二个节点为首元结点
int j =1;
struct Node* pMove = headNode;
while (1)
{
if (j == i)
{
return pMove;
}
else if (j < i)
{
pMove = pMove->next;
j++;
if (pMove == NULL)
{
return pMove;
}
}
else
{
return NULL;
}
}
}
//第i个元素前插入
void insertNodeByAnywhere(struct Node* headNode, struct student data)
{
int i = 0;
printf("请输入你想在第几个元素前插入:>");
scanf("%d", &i);
struct Node* newNode = creatNode(data);
//查找第i+1个节点之前的一个节点
struct Node* posNode = SearchPos(headNode,i);
if (posNode == NULL)
{
printf("insertNodeByAnywher::%s\n", strerror(errno));
}
else
{
newNode->next = posNode->next;
posNode->next = newNode;
}
}
//增加元素
void Add(struct student* info, struct Node* list)
{
int input = 0;
printf("请输入学生的姓名:>");
setbuf(stdin, NULL);
scanf("%s", &(info->name));
printf("请输入学生的学号:>");
setbuf(stdin, NULL);
scanf("%d", &(info->num));
printf("请输入插入方式:1.头插法 2.尾插法 3.第i个元素前插入:>");
setbuf(stdin, NULL);
scanf("%d", &input);
switch(input)
{
case 1:
insertNodeByHead(list, *info);
break;
case 2:
insertNodeByEnd(list, *info);
break;
case 3:
insertNodeByAnywhere(list, *info);
break;
default:
printf("输入错误\n");
break;
}
return;
}
//链表的删除:指定位置的删除
void deleteNodeByAppoinNum(struct Node* headNode, int num)
{
struct Node* posNode = headNode->next;
struct Node* posNodeFront = headNode;
if (posNode == NULL)
printf("无法删除,链表为空\n");
else
{
while (posNode->data.num != num)
{
posNodeFront = posNode;
posNode = posNodeFront->next;
if (posNode == NULL)
{
printf("没有找到相关信息,无法删除\n");
return;
}
}
posNodeFront->next = posNode->next;
free(posNode);
}
}
//判断链表是否为空
int ListEmpty(struct Node* list)
{
//空表:链表中无元素,称为空链表(头指针和头结点仍然在)
//若L为空表,则返回1,否则返回0
if (list->next)//非空
return 0;
else
return 1;
}
//销毁单链表
void DestroyList_L(struct Node* list)
{
struct Node* p;
while (list)
{
p = list;
list = list->next;
free(p);
}
return;
}
//清空链表:链表-->空表
void ClearList(struct Node* list)
{
struct Node* p, * q;
p = list->next;
while (p)//没有到表尾
{
q = p->next;
free(p);
p = q;
}
//头指针设置为空
list->next = NULL;
return;
}
//求单链表的表长
int countList(struct Node* list)
{
struct Node* p = list->next;//p指向第一个节点
int count = 0;
while (p != NULL)//遍历
{
p = p->next;
count++;
}
return count;
}
//查找第i个元素
void Search(struct Node* headNode)//头指针
{
int j = 1;
int i = 0;
printf("请输入你想查找第几个元素:>");
scanf("%d", &i);
struct Node* pMove = headNode->next;
while (1)
{
if (j == i)
{
printf("姓名:%s 学号:%d\n", pMove->data.name, pMove->data.num);
return;
}
else if (j < i)
{
pMove = pMove->next;
j++;
if (pMove == NULL)
{
printf("超出链表长度\n");
return;
}
}
else
{
printf("输入错误\n");
return;
}
}
}
int main()
{
struct Node* list = creatList();
struct student info;
int input = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case ADD:
Add(&info,list);
break;
case DEV:
printf("请输入要删除学生的学号:>");
scanf("%d", &info.num);
deleteNodeByAppoinNum(list, info.num);
break;
case SEARCH:
Search(list);
break;
case MODIFY:
break;
case SHOW:
printList(list);
break;
case CLEAR:
ClearList(list);
break;
case DESTROY:
DestroyList_L(list);
break;
case EXIT:
printf("退出\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
第四章:栈与队列
1.什么是栈
是限定仅在表尾(栈顶)进行插入和删除操作的线性表
栈又称为 后进先出(Last In First Out) 的线性表,简称 LIFO 结构
(1) 栈顶(top):我们把允许插入和删除的一端称为 栈顶
(2)栈底(bottom):另一端称为 栈底
(3) 空栈:不含任何任何数据元素的栈称为 空栈

2. 顺序栈&链栈
栈 是线性表的特例,其具备先进后出 FILO 特性
(1) 顺序栈:可以使用线性表的顺序存储结构(即数组)实现栈,将之称之为 顺序栈
(2)链栈:可以使用单链表结构实现栈,将之称之为 链栈
(3)两者示意图如下所示:

(4)顺序栈&链栈的异同
A:同【时间复杂度】顺序栈和链栈的时间复杂度均为O(1)
B:异【空间性能】
a:顺序栈
顺序栈需要事先确定一个固定的长度(数组长度)
可能存在内存空间浪费问题,但它的优势是存取时定位很方便
b:链栈
要求每个元素都要配套一个指向下个结点的指针域
增大了内存开销,但好处是栈的长度无限
因此,如果栈的使用过程中元素变化不可预料,有时很小,有时很大,那么最好使用链栈
反之,如果它的变化在可控范围内,则建议使用顺序栈
3.栈的内部实现原理
栈的内部实现原理其实就是数组或链表的操作
而之所以引入 栈 这个概念,是为了将程序设计问题模型化
用高层的模块指导特定行为(栈的先进后出特性),划分了不同关注层次,使得思考范围缩小
更加聚焦于我们致力解决的问题核心,简化了程序设计的问题
4.递归
(1) 定义:在运行的过程中调用自己
每个递归定义必须至少有一个条件,使得当满足条件时,递归不再进行
(2)条件:1. 子问题须与原始问题为同样的事,且更为简单;2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理
(3)斐波那契数列(Fibonacci)
指的是这样一个数列:1、1、2、3、5、8、13、21、……,即当前位置的值为前面两项之和
用数学表达式表达如下:
如果我们直接将按上面的公式用代码进行翻译,如下所示:
int fbi(const int n){
int i;
int ret;
int last1 = 0;
int last2 = 1;
if (n == 0){
ret = 0;
}else if (n == 1){
ret = 1;
}else{
for(i = 2; i <= n; ++i){
ret = last1 + last2;
last1 = last2;
last2 = ret;
}
}
return ret;
}但是如果我们使用递归方式实现,则会更加简洁:
int fbi(const int n){
if (n < 2){
return n == 0 ? 0 : 1;
}
return fbi(n-1) + fbi(n-2);
}使用递归,简洁之余,还更加契合其数学公式的定义
5.栈的数学表达式的求值
其原理是通过将 中缀表达式(即标准的四则运算表达式) 以特定操作进行进栈出栈操作
得到一个对应的 后缀表达式(也称为逆波兰(Reverse Polish Notation,PRN)表示)
然后将该后缀表达式再次通过特定操作进行出栈入栈操作,即可得到运算结果
6.队列(queue)
(1)定义
队列是只允许在一端进行插入操作,而在另一端进行删除操作的线性表
队列 是一种 先进先出(First In First Out) 的线性表
(2)对头:允许删除的一端称为对头
(3)队尾:允许插入的一端称为队尾
线性表有顺序存储和链式存储,栈是线性表,所以有这两种存储方式
同样,队列作为一种特殊的线性表,也同样存在这两种存储方式
第五章:数组和广义表
数组和广义表,都用于存储逻辑关系为“一对一”的数据。
数组存储结构,99% 的编程语言都包含的存储结构,用于存储不可再分的单一数据;而广义表不同,它还可以存储子广义表。
本章重点从矩阵的角度讨论二维数组的存储,同时讲解广义表的存储结构以及有关其广度和深度的算法实现。
1. 什么是数组存储结构
前面学习数据结构的过程中,总是使用数组作为顺序表的底层实现,给我们一种 "数据结构中,数组的作用就是实现顺序表" 的错误认识。其实,数组的作用远不止于此。
本节将从数据结构的角度讲解数组存储结构。
本节所讲的数组,要将其视为一种存储结构,与平时使用的数组基本数据类型区分开。
一说起数组,我们的印象中数组往往是某一门编程语言中包含的具体数据类型,其实不然。
从本质上讲,数组与顺序表、链表、栈和队列一样,都用来存储具有 "一对一" 逻辑关系数据的线性存储结构。
只因各编程语言都默认将数组作为基本数据类型,使初学者对数组有了 "只是基本数据类型,不是存储结构" 的误解。
不仅如此,数组和其他线性存储结构不同,顺序表、链表、栈和队列存储的都是不可再分的数据元素(如数字 5、字符 'a' 等),而数组既可以用来存储不可再分的数据元素,也可以用来存储像顺序表、链表这样的数据结构。
比如说,数组可以直接存储多个顺序表。我们知道,顺序表的底层实现还是数组,因此等价于数组中继续存储数组。这与平时使用的二维数组类似。
根据数组中存储数据之间逻辑结构的不同,数组可细分为一维数组、二维数组、...、n 维数组:
- 一维数组,指的是存储不可再分数据元素的数组,如图 1 所示;

图 1 一维数组存储结构示意图
- 二维数组,指的存储一维数组的一维数组,如图 2 所示;

图 2 二维数组存储结构示意图
- n 维数组,指的是存储 n-1 维数组的一维数组;
注意,无论数组的维数是多少,数组中的数据类型都必须一致。
由此,我们可以得出这样一个结论,一维数组结构是线性表的基本表现形式,而 n 维数组可理解为是对线性存储结构的一种扩展。
2. 数组的顺序存储(C语言版)
数组作为一种线性存储结构,对存储的数据通常只做查找和修改操作,因此数组结构的实现使用的是顺序存储结构。
要知道,对数组中存储的数据做插入和删除操作,算法的效率是很差的。
由于数组可以是多维的,而顺序存储结构是一维的,因此数组中数据的存储要制定一个先后次序。通常,数组中数据的存储有两种先后存储方式:
- 以列序为主(先列后行):按照行号从小到大的顺序,依次存储每一列的元素
- 以行序为主(先行后序):按照列号从小到大的顺序,依次存储每一行的元素。
多维数组中,我们最常用的是二维数组。比如说,当二维数组 a[6][6] 按照列序为主的次序顺序存储时,数组在内存中的存储状态如图 1 所示:

图 1 以列序为主的二维数组存储状态
同样,当二维数组 a[6][6] 按照行序为主的次序顺序存储时,数组在内存中的存储状态如图 2 所示:

图 2 以行序为主的二维数组存储状态
C 语言中,多维数组的存储采用的是以行序为主的顺序存储方式。
通过以上内容,我们掌握了将多维数组存储在一维内存空间的方法。那么,后期如何对指定的数据进行查找和修改操作呢?
多维数组查找指定元素
当需要在顺序存储的多维数组中查找某个指定元素时,需知道以下信息:
- 多维数组的存储方式;
- 多维数组在内存中存放的起始地址;
- 该指定元素在原多维数组的坐标(比如说,二维数组中是通过行标和列标来表明数据元素的具体位置的);
- 数组中数组的具体类型,即数组中单个数据元素所占内存的大小,通常用字母 L 表示;
根据存储方式的不同,查找目标元素的方式也不同。如果二维数组采用以行序为主的方式,则在二维数组 anm 中查找 aij 存放位置的公式为:
LOC(i,j) = LOC(0,0) + (i*m + j) * L;
其中,LOC(i,j) 为 aij 在内存中的地址,LOC(0,0) 为二维数组在内存中存放的起始位置(也就是 a00 的位置)。
而如果采用以列存储的方式,在 anm 中查找 aij 的方式为:
LOC(i,j) = LOC(0,0) + (i*n + j) * L;
以下给出了采用以行序为主的方式存储三维数组 a[3][4][2] 的 C 语言代码实现,这里不再对该代码进行分析(代码中有详细注释),有兴趣的读者可以自行拷贝运行:
#include<stdarg.h>
#include<malloc.h>
#include<stdio.h>
#include<stdlib.h> // atoi()
#include<io.h> // eof()
#include<math.h>
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW 3
#define UNDERFLOW 4
typedef int Status; //Status是函数的类型,其值是函数结果状态代码,如OK等
typedef int Boolean; //Boolean是布尔类型,其值是TRUE或FALSE
typedef int ElemType;
#define MAX_ARRAY_DIM 8 //假设数组维数的最大值为8
typedef struct
{
ElemType *base; //数组元素基址,由InitArray分配
int dim; //数组维数
int *bounds; //数组维界基址,由InitArray分配
int *constants; // 数组映象函数常量基址,由InitArray分配
} Array;
Status InitArray(Array *A,int dim,...)
{
//若维数dim和各维长度合法,则构造相应的数组A,并返回OK
int elemtotal=1,i; // elemtotal是元素总值
va_list ap;
if(dim<1||dim>MAX_ARRAY_DIM)
return ERROR;
(*A).dim=dim;
(*A).bounds=(int *)malloc(dim*sizeof(int));
if(!(*A).bounds)
exit(OVERFLOW);
va_start(ap,dim);
for(i=0; i<dim; ++i)
{
(*A).bounds[i]=va_arg(ap,int);
if((*A).bounds[i]<0)
return UNDERFLOW;
elemtotal*=(*A).bounds[i];
}
va_end(ap);
(*A).base=(ElemType *)malloc(elemtotal*sizeof(ElemType));
if(!(*A).base)
exit(OVERFLOW);
(*A).constants=(int *)malloc(dim*sizeof(int));
if(!(*A).constants)
exit(OVERFLOW);
(*A).constants[dim-1]=1;
for(i=dim-2; i>=0; --i)
(*A).constants[i]=(*A).bounds[i+1]*(*A).constants[i+1];
return OK;
}
Status DestroyArray(Array *A)
{
//销毁数组A
if((*A).base)
{
free((*A).base);
(*A).base=NULL;
}
else
return ERROR;
if((*A).bounds)
{
free((*A).bounds);
(*A).bounds=NULL;
}
else
return ERROR;
if((*A).constants)
{
free((*A).constants);
(*A).constants=NULL;
}
else
return ERROR;
return OK;
}
Status Locate(Array A,va_list ap,int *off) // Value()、Assign()调用此函数 */
{
//若ap指示的各下标值合法,则求出该元素在A中的相对地址off
int i,ind;
*off=0;
for(i=0; i<A.dim; i++)
{
ind=va_arg(ap,int);
if(ind<0||ind>=A.bounds[i])
return OVERFLOW;
*off+=A.constants[i]*ind;
}
return OK;
}
Status Value(ElemType *e,Array A,...) //在VC++中,...之前的形参不能是引用类型
{
//依次为各维的下标值,若各下标合法,则e被赋值为A的相应的元素值
va_list ap;
Status result;
int off;
va_start(ap,A);
if((result=Locate(A,ap,&off))==OVERFLOW) //调用Locate()
return result;
*e=*(A.base+off);
return OK;
}
Status Assign(Array *A,ElemType e,...)
{
//依次为各维的下标值,若各下标合法,则将e的值赋给A的指定的元素
va_list ap;
Status result;
int off;
va_start(ap,e);
if((result=Locate(*A,ap,&off))==OVERFLOW) //调用Locate()
return result;
*((*A).base+off)=e;
return OK;
}
int main()
{
Array A;
int i,j,k,*p,dim=3,bound1=3,bound2=4,bound3=2; //a[3][4][2]数组
ElemType e,*p1;
InitArray(&A,dim,bound1,bound2,bound3); //构造3*4*2的3维数组A
p=A.bounds;
printf("A.bounds=");
for(i=0; i<dim; i++) //顺序输出A.bounds
printf("%d ",*(p+i));
p=A.constants;
printf("\nA.constants=");
for(i=0; i<dim; i++) //顺序输出A.constants
printf("%d ",*(p+i));
printf("\n%d页%d行%d列矩阵元素如下:\n",bound1,bound2,bound3);
for(i=0; i<bound1; i++)
{
for(j=0; j<bound2; j++)
{
for(k=0; k<bound3; k++)
{
Assign(&A,i*100+j*10+k,i,j,k); // 将i*100+j*10+k赋值给A[i][j][k]
Value(&e,A,i,j,k); //将A[i][j][k]的值赋给e
printf("A[%d][%d][%d]=%2d ",i,j,k,e); //输出A[i][j][k]
}
printf("\n");
}
printf("\n");
}
p1=A.base;
printf("A.base=\n");
for(i=0; i<bound1*bound2*bound3; i++) //顺序输出A.base
{
printf("%4d",*(p1+i));
if(i%(bound2*bound3)==bound2*bound3-1)
printf("\n");
}
DestroyArray(&A);
return 0;
}
3. 矩阵(稀疏矩阵)压缩存储(3种方式)
数据结构中,提供针对某些特殊矩阵的压缩存储结构。
这里所说的特殊矩阵,主要分为以下两类:
- 含有大量相同数据元素的矩阵,比如对称矩阵;
- 含有大量 0 元素的矩阵,比如稀疏矩阵、上(下)三角矩阵;
针对以上两类矩阵,数据结构的压缩存储思想是:矩阵中的相同数据元素(包括元素 0)只存储一个。
对称矩阵

图 1 对称矩阵示意图
图 1 的矩阵中,数据元素沿主对角线对应相等,这类矩阵称为对称矩阵。
矩阵中有两条对角线,其中图 1 中的对角线称为主对角线,另一条从左下角到右上角的对角线为副对角线。对称矩阵指的是各数据元素沿主对角线对称的矩阵。
结合数据结构压缩存储的思想,我们可以使用一维数组存储对称矩阵。由于矩阵中沿对角线两侧的数据相等,因此数组中只需存储对角线一侧(包含对角线)的数据即可。
对称矩阵的实现过程是,若存储下三角中的元素,只需将各元素所在的行标 i 和列标 j 代入下面的公式:

存储上三角的元素要将各元素的行标 i 和列标 j 代入另一个公式:

最终求得的 k 值即为该元素存储到数组中的位置(矩阵中元素的行标和列标都从 1 开始)。
例如,在数组 skr[6] 中存储图 1 中的对称矩阵,则矩阵的压缩存储状态如图 3 所示(存储上三角和下三角的结果相同):

图 3 对称矩阵的压缩存储示意图
注意,以上两个公式既是用来存储矩阵中元素的,也用来从数组中提取矩阵相应位置的元素。例如,如果想从图 3 中的数组提取矩阵中位于 (3,1) 处的元素,由于该元素位于下三角,需用下三角公式获取元素在数组中的位置,即:
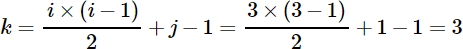
结合图 3,数组下标为 3 的位置存储的是元素 3,与图 1 对应。
上(下)三角矩阵

图 4 上(下)三角矩阵
如图 4 所示,主对角线下的数据元素全部相同的矩阵为上三角矩阵(图 4a)),主对角线上元素全部相同的矩阵为下三角矩阵(图 4b))。
对于这类特殊的矩阵,压缩存储的方式是:上(下)三角矩阵采用对称矩阵的方式存储上(下)三角的数据(元素 0 不用存储)。
例如,压缩存储图 4a) 中的上三角矩阵,矩阵最终的存储状态同图 3 相同。因此可以得出这样一个结论,上(下)三角矩阵存储元素和提取元素的过程和对称矩阵相同。
稀疏矩阵
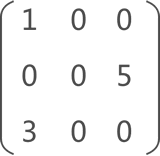
图 5 稀疏矩阵示意图
如图 5 所示,如果矩阵中分布有大量的元素 0,即非 0 元素非常少,这类矩阵称为稀疏矩阵。
压缩存储稀疏矩阵的方法是:只存储矩阵中的非 0 元素,与前面的存储方法不同,稀疏矩阵非 0 元素的存储需同时存储该元素所在矩阵中的行标和列标。
例如,存储图 5 中的稀疏矩阵,需存储以下信息:
- (1,1,1):数据元素为 1,在矩阵中的位置为 (1,1);
- (3,3,1):数据元素为 3,在矩阵中的位置为 (3,1);
- (5,2,3):数据元素为 5,在矩阵中的位置为 (2,3);
- 除此之外,还要存储矩阵的行数 3 和列数 3;
由此,可以成功存储一个稀疏矩阵。
注意,以上 3 种特殊矩阵的压缩存储,除了将数据元素存储起来,还要存储矩阵的行数值和列数值,具体的实现方式后续会介绍 3 种,本节仅需了解矩阵压缩存储的原理。
矩阵压缩存储的 3 种方式
对于以上 3 种特殊的矩阵,对阵矩阵和上下三角矩阵的实现方法是相同的,且实现过程比较容易,仅需套用上面给出的公式即可。
稀疏矩阵的压缩存储,数据结构提供有 3 种具体实现方式:
稀疏矩阵的三种存储结构,会利用后续的 3 篇文章做重点介绍。
4. 三元组顺序表,稀疏矩阵的三元组表示及(C语言)实现
本节介绍稀疏矩阵的三元组顺序表压缩存储方式。
通过《矩阵的压缩存储》一节我们知道,稀疏矩阵的压缩存储,至少需要存储以下信息:
- 矩阵中各非 0 元素的值,以及所在矩阵中的行标和列标;
- 矩阵的总行数和总列数;
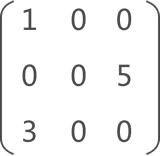
图 1 稀疏矩阵示意图
例如,图 1 是一个稀疏矩阵,若对其进行压缩存储,矩阵中各非 0 元素的存储状态如图 2 所示:

图 2 稀疏矩阵的压缩存储示意图
图 2 的数组中,存储的是三元组(即由 3 部分数据组成的集合),组中数据分别表示(行标,列标,元素值)。
注意,这里矩阵的行标和列标都从 1 开始。
C 语言中,三元组需要用结构体实现,如下所示:
//三元组结构体
typedef struct {
int i,j;//行标i,列标j
int data;//元素值
}triple;由于稀疏矩阵中非 0 元素有多个,因此需要建立 triple 数组存储各个元素的三元组。除此之外,考虑到还要存储矩阵的总行数和总列数,因此可以采用以下结构表示整个稀疏矩阵:
#define number 20
//矩阵的结构表示
typedef struct {
triple data[number];//存储该矩阵中所有非0元素的三元组
int n,m,num;//n和m分别记录矩阵的行数和列数,num记录矩阵中所有的非0元素的个数
}TSMatrix;可以看到,TSMatrix 是一个结构体,其包含一个三元组数组,以及用于存储矩阵总行数、总列数和非 0 元素个数的变量。
假设采用 TSMatrix 结构体存储图 1 中的稀疏矩阵,其 C 语言实现代码应该为:
#include<stdio.h>
#define number 3
typedef struct {
int i,j;
int data;
}triple;
typedef struct {
triple data[number];
int n,m,num;
}TSMatrix;
//输出存储的稀疏矩阵
void display(TSMatrix M);
int main() {
TSMatrix M;
M.m=3;
M.n=3;
M.num=3;
M.data[0].i=1;
M.data[0].j=1;
M.data[0].data=1;
M.data[1].i=2;
M.data[1].j=3;
M.data[1].data=5;
M.data[2].i=3;
M.data[2].j=1;
M.data[2].data=3;
display(M);
return 0;
}
void display(TSMatrix M){
for(int i=1;i<=M.n;i++){
for(int j=1;j<=M.m;j++){
int value =0;
for(int k=0;k<M.num;k++){
if(i == M.data[k].i && j == M.data[k].j){
printf("%d ",M.data[k].data);
value =1;
break;
}
}
if(value == 0)
printf("0 ");
}
printf("\n");
}
}输出结果为:
1 0 0
0 0 5
3 0 0
5. 行逻辑链接的顺序表(压缩存储稀疏矩阵)详解
前面学习了如何使用三元组顺序表存储稀疏矩阵,其实现过程就是将矩阵中各个非 0 元素的行标、列标和元素值以三元组的形式存储到一维数组中。通过研究实现代码你会发现,三元组顺序表每次提取指定元素都需要遍历整个数组,运行效率很低。
本节将学习另一种存储矩阵的方法——行逻辑链接的顺序表。它可以看作是三元组顺序表的升级版,即在三元组顺序表的基础上改善了提取数据的效率。
行逻辑链接的顺序表和三元组顺序表的实现过程类似,它们存储矩阵的过程完全相同,都是将矩阵中非 0 元素的三元组(行标、列标和元素值)存储在一维数组中。但为了提高提取数据的效率,前者在存储矩阵时比后者多使用了一个数组,专门记录矩阵中每行第一个非 0 元素在一维数组中的位置。

图 1 稀疏矩阵示意图
图 1 是一个稀疏矩阵,当使用行逻辑链接的顺序表对其进行压缩存储时,需要做以下两个工作:
- 将矩阵中的非 0 元素采用三元组的形式存储到一维数组 data 中,如图 2 所示(和三元组顺序表一样):

图 2 三元组存储稀疏矩阵
- 使用数组 rpos 记录矩阵中每行第一个非 0 元素在一维数组中的存储位置。如图 3 所示:

图 3 存储各行首个非 0 元素在数组中的位置
通过以上两步操作,即实现了使用行逻辑链接的顺序表存储稀疏矩阵。
此时,如果想从行逻辑链接的顺序表中提取元素,则可以借助 rpos 数组提高遍历数组的效率。
例如,提取图 1 稀疏矩阵中的元素 2 的过程如下:
- 由 rpos 数组可知,第一行首个非 0 元素位于data[1],因此在遍历此行时,可以直接从第 data[1] 的位置开始,一直遍历到下一行首个非 0 元素所在的位置(data[3])之前;
- 同样遍历第二行时,由 rpos 数组可知,此行首个非 0 元素位于 data[3],因此可以直接从第 data[3] 开始,一直遍历到下一行首个非 0 元素所在的位置(data[4])之前;
- 遍历第三行时,由 rpos 数组可知,此行首个非 0 元素位于 data[4],由于这是矩阵的最后一行,因此一直遍历到 rpos 数组结束即可(也就是 data[tu],tu 指的是矩阵非 0 元素的总个数)。
以上操作的完整 C 语言实现代码如下:
#include <stdio.h>
#define MAXSIZE 12500
#define MAXRC 100
#define ElemType int
typedef struct
{
int i,j;//行,列
ElemType e;//元素值
}Triple;
typedef struct
{
Triple data[MAXSIZE+1];
int rpos[MAXRC+1];//每行第一个非零元素在data数组中的位置
int mu,nu,tu;//行数,列数,元素个数
}RLSMatrix;
//矩阵的输出函数
void display(RLSMatrix M){
for(int i=1;i<=M.mu;i++){
for(int j=1;j<=M.nu;j++){
int value=0;
if(i+1 <=M.mu){
for(int k=M.rpos[i];k<M.rpos[i+1];k++){
if(i == M.data[k].i && j == M.data[k].j){
printf("%d ",M.data[k].e);
value=1;
break;
}
}
if(value==0){
printf("0 ");
}
}else{
for(int k=M.rpos[i];k<=M.tu;k++){
if(i == M.data[k].i && j == M.data[k].j){
printf("%d ",M.data[k].e);
value=1;
break;
}
}
if(value==0){
printf("0 ");
}
}
}
printf("\n");
}
}
int main(int argc, char* argv[])
{
RLSMatrix M;
M.tu = 4;
M.mu = 3;
M.nu = 4;
M.rpos[1] = 1;
M.rpos[2] = 3;
M.rpos[3] = 4;
M.data[1].e = 3;
M.data[1].i = 1;
M.data[1].j = 2;
M.data[2].e = 5;
M.data[2].i = 1;
M.data[2].j = 4;
M.data[3].e = 1;
M.data[3].i = 2;
M.data[3].j = 3;
M.data[4].e = 2;
M.data[4].i = 3;
M.data[4].j = 1;
//输出矩阵
display(M);
return 0;
}运行结果:
0 3 0 5
0 0 1 0
2 0 0 0
总结
通过系统地学习使用行逻辑链接的顺序表压缩存储稀疏矩阵,可以发现,它仅比三元组顺序表多使用了一个 rpos 数组,从而提高了提取数据时遍历数组的效率。
6. 十字链表法,十字链表压缩存储稀疏矩阵详解
对于压缩存储稀疏矩阵,无论是使用三元组顺序表,还是使用行逻辑链接的顺序表,归根结底是使用数组存储稀疏矩阵。介于数组 "不利于插入和删除数据" 的特点,以上两种压缩存储方式都不适合解决类似 "向矩阵中添加或删除非 0 元素" 的问题。
例如,A 和 B 分别为两个矩阵,在实现 "将矩阵 B 加到矩阵 A 上" 的操作时,矩阵 A 中的元素会发生很大的变化,之前的非 0 元素可能变为 0,而 0 元素也可能变为非 0 元素。对于此操作的实现,之前所学的压缩存储方法就显得力不从心。
本节将学习用十字链表存储稀疏矩阵,该存储方式采用的是 "链表+数组" 结构,如图 1 所示。
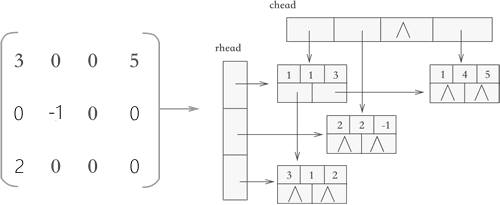
图 1 十字链表示意图
可以看到,使用十字链表压缩存储稀疏矩阵时,矩阵中的各行各列都各用一各链表存储,与此同时,所有行链表的表头存储到一个数组(rhead),所有列链表的表头存储到另一个数组(chead)中。
因此,各个链表中节点的结构应如图 2 所示:

图 2 十字链表的节点结构
两个指针域分别用于链接所在行的下一个元素以及所在列的下一个元素。
链表中节点的 C 语言代码表示应为:
typedef struct OLNode{
int i,j;//元素的行标和列标
int data;//元素的值
struct OLNode * right,*down;//两个指针域
}OLNode; #include<stdio.h>
#include<stdlib.h>
typedef struct OLNode
{
int i, j, e; //矩阵三元组i代表行 j代表列 e代表当前位置的数据
struct OLNode *right, *down; //指针域 右指针 下指针
}OLNode, *OLink;
typedef struct
{
OLink *rhead, *chead; //行和列链表头指针
int mu, nu, tu; //矩阵的行数,列数和非零元的个数
}CrossList;
CrossList CreateMatrix_OL(CrossList M);
void display(CrossList M);
int main()
{
CrossList M;
M.rhead = NULL;
M.chead = NULL;
M = CreateMatrix_OL(M);
printf("输出矩阵M:\n");
display(M);
return 0;
}
CrossList CreateMatrix_OL(CrossList M)
{
int m, n, t;
int i, j, e;
OLNode *p, *q;
printf("输入矩阵的行数、列数和非0元素个数:");
scanf("%d%d%d", &m, &n, &t);
M.mu = m;
M.nu = n;
M.tu = t;
if (!(M.rhead = (OLink*)malloc((m + 1) * sizeof(OLink))) || !(M.chead = (OLink*)malloc((n + 1) * sizeof(OLink))))
{
printf("初始化矩阵失败");
exit(0);
}
for (i = 1; i <= m; i++)
{
M.rhead[i] = NULL;
}
for (j = 1; j <= n; j++)
{
M.chead[j] = NULL;
}
for (scanf("%d%d%d", &i, &j, &e); 0 != i; scanf("%d%d%d", &i, &j, &e)) {
if (!(p = (OLNode*)malloc(sizeof(OLNode))))
{
printf("初始化三元组失败");
exit(0);
}
p->i = i;
p->j = j;
p->e = e;
//链接到行的指定位置
if (NULL == M.rhead[i] || M.rhead[i]->j > j)
{
p->right = M.rhead[i];
M.rhead[i] = p;
}
else
{
for (q = M.rhead[i]; (q->right) && q->right->j < j; q = q->right);
p->right = q->right;
q->right = p;
}
//链接到列的指定位置
if (NULL == M.chead[j] || M.chead[j]->i > i)
{
p->down = M.chead[j];
M.chead[j] = p;
}
else
{
for (q = M.chead[j]; (q->down) && q->down->i < i; q = q->down);
p->down = q->down;
q->down = p;
}
}
return M;
}
void display(CrossList M) {
for (int i = 1; i <= M.nu; i++)
{
if (NULL != M.chead[i])
{
OLink p = M.chead[i];
while (NULL != p)
{
printf("%d\t%d\t%d\n", p->i, p->j, p->e);
p = p->down;
}
}
}
}运行结果:
输入矩阵的行数、列数和非0元素个数:3 3 3
2 2 3
2 3 4
3 2 5
0 0 0
输出矩阵M:
2 2 3
3 2 5
2 3 4
7. 矩阵(稀疏矩阵)的转置算法(C语言)详解
矩阵(包括稀疏矩阵)的转置,即互换矩阵中所有元素的行标和列标,如图 1 所示:

图 1 矩阵转置示意图
但如果想通过程序实现矩阵的转置,互换行标和列标只是第一步。因为实现矩阵转置的前提是将矩阵存储起来,数据结构中提供了 3 种存储矩阵的结构,分别是三元组顺序表、行逻辑链接的顺序表和十字链表。如果采用前两种结构,矩阵的转置过程会涉及三元组表也跟着改变的问题,如图 2 所示:
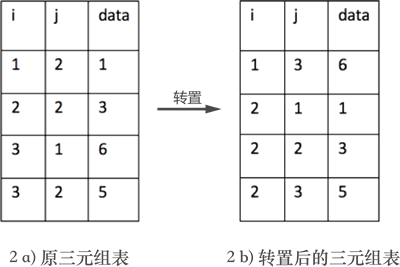
图 2 三元组表的变化
图 2a) 表示的是图 1 中转置之前矩阵的三元组表,2b) 表示的是图 1 中矩阵转置后对应的三元组表。
不仅如此,如果矩阵的行数和列数不等,也需要将它们互换。
因此通过以上分析,矩阵转置的实现过程需完成以下 3 步:
- 将矩阵的行数和列数互换;
- 将三元组表(存储矩阵)中的 i 列和 j 列互换,实现矩阵的转置;
- 以 j 列为序,重新排列三元组表中存储各三元组的先后顺序;
此 3 步中,前两步比较简单,关键在于最后一步的实现。本节先介绍较容易的一种。
矩阵转置的实现思路是:不断遍历存储矩阵的三元组表,每次都取出表中 j 列最小的那一个三元组,互换行标和列标的值,并按次序存储到一个新三元组表中,。
例如,将图 2a) 三元组表存储的矩阵进行转置的过程为:
- 新建一个三元组表(用于存储转置矩阵),并将原矩阵的行数和列数互换赋值给新三元组;
- 遍历三元组表,找到表中 j 列最小值 1 所在的三元组 (3,1,6),然后将其行标和列标互换后添加到一个新的三元组表中,如图 3 所示:
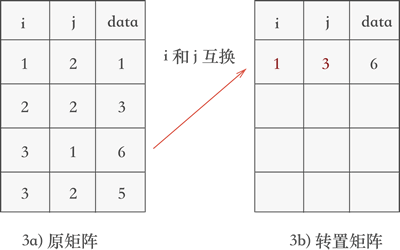
图 3 矩阵转置的第一个过程
- 继续遍历三元组表,找到表中 j 列次小值为 2 的三元组,分别为 (1,2,1)、(2,2,3) 和 (3,2,5),根据找到它们的先后次序将各自的行标和列标互换后添加到新三元组表中,如图 4 所示:
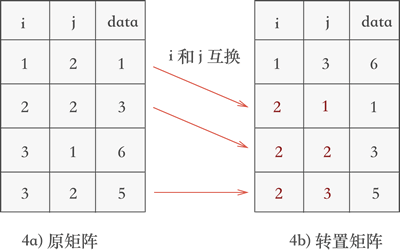
图 4 矩阵转置的第二个过程
对比图 4 和图 2b) 可以看到,矩阵被成功地转置。
因此,矩阵转置的 C 语言实现代码为:
#include<stdio.h>
#define number 10
typedef struct {
int i, j;
int data;
}triple;
typedef struct {
triple data[10];
int n, m, num;
}TSMatrix;
TSMatrix transposeMatrix(TSMatrix M, TSMatrix T) {
T.m = M.n;
T.n = M.m;
T.num = M.num;
if (T.num) {
int q = 0;
for (int col = 1; col <= M.m; col++) {
for (int p = 0; p < M.num; p++) {
if (M.data[p].j == col) {
T.data[q].i = M.data[p].j;
T.data[q].j = M.data[p].i;
T.data[q].data = M.data[p].data;
q++;
}
}
}
}
return T;
}
int main() {
TSMatrix M;
M.m = 2;
M.n = 3;
M.num = 4;
M.data[0].i = 1;
M.data[0].j = 2;
M.data[0].data = 1;
M.data[1].i = 2;
M.data[1].j = 2;
M.data[1].data = 3;
M.data[2].i = 3;
M.data[2].j = 1;
M.data[2].data = 6;
M.data[3].i = 3;
M.data[3].j = 2;
M.data[3].data = 5;
TSMatrix T;
for (int k = 0; k < number; k++) {
T.data[k].i = 0;
T.data[k].j = 0;
T.data[k].data = 0;
}
T = transposeMatrix(M, T);
for (int i = 0; i < T.num; i++) {
printf("(%d,%d,%d)\n", T.data[i].i, T.data[i].j, T.data[i].data);
}
return 0;
}程序运行结果为:
(1,3,6)
(2,1,1)
(2,2,3)
(2,3,5)
由于此算法中嵌套使用了两个 for 循环,时间复杂度为 O(n2)。
8. 稀疏矩阵的快速转置算法(C语言)详解
9. 行逻辑链接的顺序表实现矩阵乘法(附带C语言完整代码)
10. 十字链表实现矩阵加法(附带C语言实现代码)
11. 什么是广义表
前面讲过,数组即可以存储不可再分的数据元素(如数字 5、字符 'a'),也可以继续存储数组(即 n 维数组)。
但需要注意的是,以上两种数据存储形式绝不会出现在同一个数组中。例如,我们可以创建一个整形数组去存储 {1,2,3},我们也可以创建一个二维整形数组去存储 {{1,2,3},{4,5,6}},但数组不适合用来存储类似 {1,{1,2,3}} 这样的数据。
有人可能会说,创建一个二维数组来存储{1,{1,2,3}}。在存储上确实可以实现,但无疑会造成存储空间的浪费。
对于存储 {1,{1,2,3}} 这样的数据,更适合用广义表结构来存储。
广义表,又称列表,也是一种线性存储结构。同数组类似,广义表中既可以存储不可再分的元素,也可以存储广义表,记作:
LS = (a1,a2,…,an)
其中,LS 代表广义表的名称,an 表示广义表存储的数据。广义表中每个 ai 既可以代表单个元素,也可以代表另一个广义表。
广义表的原子和子表
通常,广义表中存储的单个元素称为 "原子",而存储的广义表称为 "子表"。
例如创建一个广义表 LS = {1,{1,2,3}},我们可以这样解释此广义表的构成:广义表 LS 存储了一个原子 1 和子表 {1,2,3}。
以下是广义表存储数据的一些常用形式:
- A = ():A 表示一个广义表,只不过表是空的。
- B = (e):广义表 B 中只有一个原子 e。
- C = (a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 (b,c,d)。
- D = (A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ((),(e),(b,c,d)) 。
- E = (a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于:E = (a,(a,(a,…)))。
注意,A = () 和 A = (()) 是不一样的。前者是空表,而后者是包含一个子表的广义表,只不过这个子表是空表。
广义表的表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
强调一下,除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例如在广义表中 LS={1,{1,2,3},5} 中,表头为原子 1,表尾为子表 {1,2,3} 和原子 5 构成的广义表,即 {{1,2,3},5}。
再比如,在广义表 LS = {1} 中,表头为原子 1 ,但由于广义表中无表尾元素,因此该表的表尾是一个空表,用 {} 表示。
12. 广义表的存储结构详解(包含2种存储方案)
由于广义表中既可存储原子(不可再分的数据元素),也可以存储子表,因此很难使用顺序存储结构表示,通常情况下广义表结构采用链表实现。
使用顺序表实现广义表结构,不仅需要操作 n 维数组(例如 {1,{2,{3,4}}} 就需要使用三维数组存储),还会造成存储空间的浪费。
使用链表存储广义表,首先需要确定链表中节点的结构。由于广义表中可同时存储原子和子表两种形式的数据,因此链表节点的结构也有两种,如图 1 所示:

图 1 广义表节点的两种类型
如图 1 所示,表示原子的节点由两部分构成,分别是 tag 标记位和原子的值,表示子表的节点由三部分构成,分别是 tag 标记位、hp 指针和 tp 指针。
tag 标记位用于区分此节点是原子还是子表,通常原子的 tag 值为 0,子表的 tag 值为 1。子表节点中的 hp 指针用于连接本子表中存储的原子或子表,tp 指针用于连接广义表中下一个原子或子表。
因此,广义表中两种节点的 C 语言表示代码为:
typedef struct GLNode{
int tag;//标志域
union{
char atom;//原子结点的值域
struct{
struct GLNode * hp,*tp;
}ptr;//子表结点的指针域,hp指向表头;tp指向表尾
};
}*Glist;这里用到了 union 共用体,因为同一时间此节点不是原子节点就是子表节点,当表示原子节点时,就使用 atom 变量;反之则使用 ptr 结构体。
例如,广义表 {a,{b,c,d}} 是由一个原子 a 和子表 {b,c,d} 构成,而子表 {b,c,d} 又是由原子 b、c 和 d 构成,用链表存储该广义表如图 2 所示:

图 2 广义表 {a,{b,c,d}} 的结构示意图
图 2 可以看到,存储原子 a、b、c、d 时都是用子表包裹着表示的,因为原子 a 和子表 {b,c,d} 在广义表中同属一级,而原子 b、c、d 也同属一级。
图 2 中链表存储的广义表用 C 语言代码表示为:
Glist creatGlist(Glist C){
//广义表C
C=(Glist)malloc(sizeof(Glist));
C->tag=1;
//表头原子‘a’
C->ptr.hp=(Glist)malloc(sizeof(Glist));
C->ptr.hp->tag=0;
C->ptr.hp->atom='a';
//表尾子表(b,c,d),是一个整体
C->ptr.tp=(Glist)malloc(sizeof(Glist));
C->ptr.tp->tag=1;
C->ptr.tp->ptr.hp=(Glist)malloc(sizeof(Glist));
C->ptr.tp->ptr.tp=NULL;
//开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d)
C->ptr.tp->ptr.hp->tag=1;
C->ptr.tp->ptr.hp->ptr.hp=(Glist)malloc(sizeof(Glist));
C->ptr.tp->ptr.hp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.hp->atom='b';
C->ptr.tp->ptr.hp->ptr.tp=(Glist)malloc(sizeof(Glist));
//存放子表(c,d),表头为c,表尾为d
C->ptr.tp->ptr.hp->ptr.tp->tag=1;
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(Glist));
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->atom='c';
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp=(Glist)malloc(sizeof(Glist));
//存放表尾d
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->tag=1;
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(Glist));
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->atom='d';
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.tp=NULL;
return C;
}广义表的另一种存储结构
如果你觉得图 2 这种存储广义表的方式不合理,可以使用另一套表示广义表中原子和子表结构的节点,如图 3 所示:

图 3 广义表的另一套节点结构
如图 3 所示,表示原子的节点构成由 tag 标记位、原子值和 tp 指针构成,表示子表的节点还是由 tag 标记位、hp 指针和 tp 指针构成。
图 3 的节点结构用 C 语言代码表示为:
typedef struct GLNode{
int tag;//标志域
union{
int atom;//原子结点的值域
struct GLNode *hp;//子表结点的指针域,hp指向表头
};
struct GLNode * tp;//这里的tp相当于链表的next指针,用于指向下一个数据元素
}*Glist;采用图 3 中的节点结构存储广义表 {a,{b,c,d}} 的示意图如图 4 所示:
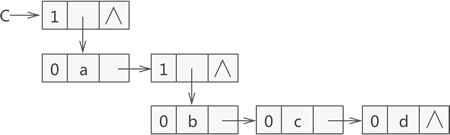
图 4 广义表 {a,{b,c,d}} 的存储结构示意图
图 4 存储广义表对应的 C 语言代码为:
Glist creatGlist(Glist C){
C=(Glist)malloc(sizeof(Glist));
C->tag=1;
C->hp=(Glist)malloc(sizeof(Glist));
C->tp=NULL;
//表头原子a
C->hp->tag=0;
C->atom='a';
C->hp->tp=(Glist)malloc(sizeof(Glist));
C->hp->tp->tag=1;
C->hp->tp->hp=(Glist)malloc(sizeof(Glist));
C->hp->tp->tp=NULL;
//原子b
C->hp->tp->hp->tag=0;
C->hp->tp->hp->atom='b';
C->hp->tp->hp->tp=(Glist)malloc(sizeof(Glist));
//原子c
C->hp->tp->hp->tp->tag=0;
C->hp->tp->hp->tp->atom='c';
C->hp->tp->hp->tp->tp=(Glist)malloc(sizeof(Glist));
//原子d
C->hp->tp->hp->tp->tp->tag=0;
C->hp->tp->hp->tp->tp->atom='d';
C->hp->tp->hp->tp->tp->tp=NULL;
return C;
}需要初学者注意的是,无论采用以上哪一种节点结构存储广义表,都不要破坏广义表中各数据元素之间的并列关系。拿 {a,{b,c,d}} 来说,原子 a 和子表 {b,c,d} 是并列的,而在子表 {b,c,d} 中原子 b、c、d 是并列的。
13. 广义表的深度和长度(C语言)详解
14. 广义表的复制详解(含C语言代码实现)
对于任意一个非空广义表来说,都是由两部分组成:表头和表尾。反之,只要确定的一个广义表的表头和表尾,那么这个广义表就可以唯一确定下来。
复制一个广义表,也是不断的复制表头和表尾的过程。如果表头或者表尾同样是一个广义表,依旧复制其表头和表尾。
所以,复制广义表的过程,其实就是不断的递归,复制广义表中表头和表尾的过程。
递归的出口有两个:
- 如果当前遍历的数据元素为空表,则直接返回空表。
- 如果当前遍历的数据元素为该表的一个原子,那么直接复制,返回即可。
还拿广义表 C 为例:
图1 广义表 C 的结构示意图
代码实现:
#include <stdio.h>
#include <stdlib.h>
typedef struct GLNode{
int tag;//标志域
union{
char atom;//原子结点的值域
struct{
struct GLNode * hp,*tp;
}ptr;//子表结点的指针域,hp指向表头;tp指向表尾
};
}*Glist,GNode;
Glist creatGlist(Glist C){
//广义表C
C=(Glist)malloc(sizeof(GNode));
C->tag=1;
//表头原子‘a’
C->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.hp->tag=0;
C->ptr.hp->atom='a';
//表尾子表(b,c,d),是一个整体
C->ptr.tp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->tag=1;
C->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.tp=NULL;
//开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d)
C->ptr.tp->ptr.hp->tag=1;
C->ptr.tp->ptr.hp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.hp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.hp->atom='b';
C->ptr.tp->ptr.hp->ptr.tp=(Glist)malloc(sizeof(GNode));
//存放子表(c,d),表头为c,表尾为d
C->ptr.tp->ptr.hp->ptr.tp->tag=1;
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->atom='c';
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp=(Glist)malloc(sizeof(GNode));
//存放表尾d
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->tag=1;
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->atom='d';
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.tp=NULL;
return C;
}
void copyGlist(Glist C, Glist *T){
//如果C为空表,那么复制表直接为空表
if (!C) {
*T=NULL;
}
else{
*T=(Glist)malloc(sizeof(GNode));//C不是空表,给T申请内存空间
//申请失败,程序停止
if (!*T) {
exit(0);
}
(*T)->tag=C->tag;//复制表C的tag值
//判断当前表元素是否为原子,如果是,直接复制
if (C->tag==0) {
(*T)->atom=C->atom;
}else{//运行到这,说明复制的是子表
copyGlist(C->ptr.hp, &((*T)->ptr.hp));//复制表头
copyGlist(C->ptr.tp, &((*T)->ptr.tp));//复制表尾
}
}
}
int main(int argc, const char * argv[]) {
Glist C=NULL;
C=creatGlist(C);
Glist T=NULL;
copyGlist(C,&T);
printf("%c",T->ptr.hp->atom);
return 0;
}运行结果:
a
总结
在实现复制广义表的过程中,实现函数为:
void copyGlist(Glist C, Glist *T);
其中,Glist *T,等同于: struct GLNode* *T,此为二级指针,不是一级指针。在主函数中,调用此函数时,传入的是指针 T 的地址,而不是 T 。
这里使用的是地址传递,而不是值传递。如果在这里使用值传递,会导致广义表 T 丢失结点,复制失败。
第六章:串【字符串】
1.定义
串(string) 是由零个或多个字符组成的有限序列,又名叫 字符串
2.串的逻辑结构
串 的逻辑结构和线性表很相似
不同之处在于串针对的是字符集
也就是串中的元素都是字符
因此,对于串的基本操作与线性表是有很大差别的
线性表更关注的是单个元素的操作,比如查找一个元素,插入或删除一个元素
但串中更多的是查找子串位置,得到指定位置子串,替换子串等操作
3.串的存储结构
串 的存储结构与线性表相同,分为两种:
(1)串的顺序存储结构
串的顺序存储结构是用 一组地址连续的存储单元 来存储串中的字符序列。一般是用定长数组来定义
由于是定长数组,因此就会存在一个预定义的最大串长度
一般可以将实际的串长度值保存在数组 0 下标位置,也可以放在数组最后一个下标位置
也有些语言使用在串值后面加一个不计入串长度的结束标记符(比如C语言的\0)来表示串值得终结,这样就无需使用数字进行记录
(2)串的链式存储结构
对于串的链式存储结构,与线性表是相似的
但由于串结构的特殊性(结构中的每个元素数据都是一个字符)
如果也简单地将每个链结点存储一个字符,就会存在很大的空间浪费
因此,一个结点可以考虑存放多个字符
如果最后一个结点未被占满时,可以使用 "#" 或其他非串值字符补全

串的链式存储结构除了在链接串与串操作时有一定的方便之外
总的来说不如顺序存储灵活,性能也不如顺序存储结构好
第七章:树
1.定义
树是 个结点的有限集
当n=0时称为空树
树 其实也是一种递归的实现,即树的定义之中还用到了树的概念
2.特点【根节点-子树-子节点】
在任意一棵非空树中:
(1)且仅有一个特定的结点:根结点(Root)
(2)当 ![]() 时,其余结点可分为
时,其余结点可分为个互不相交的有限集
![]()
其中每一个集合本身又是一棵树,并且称为根的 子树(SubTree)

(3)根结点n大于 0 时根结点是唯一的,不可能同时存在多个根结点
(4)子结点m大于 0时,子树的个数没有限制,但它们一定是互不相交的
下图所示的结构就不符合树的定义,因为它们都有相交的子树:

3.线性结构&树结构的区别用法
对比线性表与树的结构,它们有很大的不同:

单独使用顺序存储结构(即数组)无法很好地实现树的存储概念,不过如果充分利用顺序存储和链式存储结构的特点,则完全可以实现对数的存储结构的表示
4.二叉树
(1)定义
二叉树(Binary Tree):是 个结点的有限集合
该集合或者为空集(称为空二叉树)
或者由一个根结点和两棵互不相交的
分别称为根结点的左子树和右子树的二叉树组成
(2)特点
A:每个结点最多只能有两棵子树
B:左子树和右子树是有顺序的,次序不能任意颠倒
C: 即使树中某结点只有一棵子树,也要区分它是左子树还是右子树
(3)五种基本形态
A:空二叉树
B:只有一个跟结点
C:根结点只有左子树
D:根结点只有右子树
E:根结点既有左子树又有右子树
(4)五种特性【理解】
A:在二叉树的第 i 层上至多有 个结点 (i>=1)
比如第一层是根结点,只有一个;第二层有两个:根结点的左子树和右子树···
B:深度为k的二叉树至多有个结点(k>=1)
比如深度为 1,则至多只有 1 个结点,即根结点;深度为 2,则至多只有 3 个结点:根结点,根结点的左子树,根结点的右子树···
C:对任何一棵二叉树T 如果其叶子结点点数为 ,度(即子结点数)为 2的结点数为
,则
D:具有n个结点的完全二叉树的深度为
[x] 表示不大于 x 的最大整数
(计算机学科中logm表示以2为底,m的对数)
E:如果对一棵树有n 个结点的完全二叉树(其深度为的结点按层序编号(从第 1 层到第
层,每层从左到右),对任一结点 i 有:
a:.如果 i=1,则结点 i 是二叉树的根,无双亲;如果i>1 则其双亲是结点
b:如果2i>n,则结点 i 无左孩子(结点i为叶子结点);否则其左孩子是结点2i
c:如果2i+1>n则结点 i 无右孩子;否则其右孩子是结点2i+1
前面提及到顺序存储对数这种一对多的关系结构实现起来是比较困难的
但是对于二叉树,由于它的特殊性,使得用顺序存储结构也可以实现
(5)二叉树的四种遍历方式【前序遍历-中序遍历-后序遍历-层序遍历】
一:定义:是指从根结点出发,按照某种次序依次访问二叉树中所有结点,使得每个结点被访问一次且仅被访问一次
二:二叉树的遍历方式【左-右】
二叉树的遍历方式有很多,如果我们限制了从左到右的习惯方式,那么主要就分为四种【看结点】
1. 前序遍历
规则是先访问根结点
然后前序遍历左子树
再前序遍历右子树
(总结:根结点 -> 左子树 -> 右子树)
图形化介绍:
如下图所示,遍历的顺序为:ABDGHCEIF

2. 中序遍历
从根结点开始(注意并不是先访问根结点)
中序遍历根结点的左子树
然后再访问根结点
最后中序遍历右子树
(总结:左子树 -> 根结点 -> 右子树)
图形化介绍:
如下图所示,遍历的顺序为:GDHBAEICF

3.后序遍历
从左到右先叶子
后结点的方式遍历访问左右子树
最后访问根结点
(总结:**从左到右访问叶子结点 -> 根结点)
图形化介绍:如下图所示,遍历的顺序为:GHDBIEFCA

4.层序遍历
从树的第一层,即根结点开始访问
从上而下逐层遍历
在同一层中按从左到右的顺序对结点逐个访问
(总结:第一层 -> 第二层(从左到右访问结点)-> ··· -> 最后一层(从左到右访问结点)
图形化介绍:

(6) 赫夫曼编码
树,森林看似复杂
其实它们都可以转化为简单的二叉树来处理
这样就使得面对树和森林的数据结构时,编码实现成为了可能
最基本的压缩编码方法:赫夫曼编码
A:定义
给定n个权值作为n个叶子结点
构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树

a: 路径和路径长度
定义:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径
通路中分支的数目称为路径长度
若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
例子:100和80的路径长度是1,50和30的路径长度是2,20和10的路径长度是3。
b: 结点的权及带权路径长度
定义:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
例子:节点20的路径长度是3,它的带权路径长度= 路径长度 * 权 = 3 * 20 = 60。
c: 树的带权路径长度
定义:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
例子:示例中,树的WPL= 1*100 + 2*50 + 3*20 + 3*10 = 100 + 100 + 60 + 30 = 290。
比较下面两棵树:

上面的两棵树都是以{10, 20, 50, 100}为叶子节点的树。
左边的树WPL=2*10 + 2*20 + 2*50 + 2*100 = 360 右边的树WPL=350
左边的树WPL > 右边的树的WPL。
你也可以计算除上面两种示例之外的情况,但实际上右边的树就是{10,20,50,100}对应的哈夫曼树
补充:数据结构——哈夫曼(Huffman)树+哈夫曼编码
第八章:图(Graph)
1:定义
由顶点的有穷非空集合和顶点之间边的集合组成
通常表示为:G(V,E)
其中,G 表示一个图
V 是图G 中的顶点的集合
E 是图 G中边的集合

A:在线性表中
数据元素之间是被串起来的,仅有线性关系
每个数据元素只有一个直接前驱和一个直接后驱
B:在树形结构中
数据元素之间有着明显的层次关系
并且每一层上的数据元素可能和下一层中多个元素相关
但只能和上一层中一个元素相关
C:图是一种较线性表和树更加复杂的数据结构
在图形结构中,结点之间的关系可以是任意的
图中任意两个数据元素之间都可能相关
2:线性表&树&图的【数据元素名称-有无结点-内部之间的关系】的区别
一:数据元素名称区别
1.线性表中我们把数据元素叫元素
2.树中将数据元素叫结点
3.图中的数据元素,我们称之为顶点(Vertex)
二:可有无结点区别
1.线性表可以没有数据元素,称为空表
2.树中可以没有结点,称为空树
3.图结构中不允许没有顶点,在定义中,若V是顶点的集合,即强调了顶点集合V有穷非空
三:内部之间的关系区别
1.线性表中相邻的数据元素之间具有线性关系
2.树结构中相邻两层的结点具有层次关系
3.图中任意两个顶点之间都可能存在关系,顶点之间的逻辑关系用边进行表示,边集可以是空的
3:图的五种种类【无向图-有向图-简单图-完全无向图-有向完全图】
一:无向图
1.定义
若顶点 到
之间的边没有方向,则称这条边为 无向边(Edge)
用无序偶对 来表示
如果图中任意两个顶点之间的边都是无向边,则称该图为 无向图
无向图顶点的边数叫做 度
2.图形化解释:下图所示即为无向图:

3.结合![]() 表达式介绍
表达式介绍
由于无向图是无方向的,连接顶点
的边
可以表示成无序对
也可以写成
对于上图中的无向图
来说
其中顶点集合
边集合
二:有向图
1.定义
若从顶点
到
的边有方向,则称这条边为 有向边,也称为 弧(Arc)
用有序偶
来表示,
称为弧尾(Tail),
称为弧头(Head)
如果图中任意两个顶点之间的边都是有向边,则称该图为 有向图(Directed graphs)
有向图顶点分为 入度(箭头朝自己) 和 出度(箭头朝外)
2.图形化解释
如下图所示即为一个有向图:

3.结合表达式介绍
连接到顶点A到D的有向边就是弧
A是弧尾
D 是弧头
<A,D>表示弧,注意不能写成<D,A>
对于上图的有向图
![]()
其中顶点集合 ![]()
弧集合 ![]()
有向图和无向图区别:
注:看清楚了,无向边用小括号()表示
而有向边则是使用尖括号<>表示
三:简单图
1.定义
在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图
2.图形化解释
如下所示的两个图就不属于简单图:

四:完全无向图
1.定义
在无向图中,如果任意两个顶点之间都存在边,则称该图为 无向完全图
2.图形化解释
如下图所示即为一个无向完全图:

五: 有向完全图
1.定义
在有向图中,如果任意两个顶点之间都存在 方向互为相反 的两条弧,则称该图为 有向完全图
2.图形化解释
如下图所示即为一个有向完全图:

4:权
(1)定义
有些图的边或弧具有与它相关的数字,这种 与图的边或弧相关的数叫做权(Weight)
这些权可以表示从一个顶点到另一个顶点的距离或耗费
这种带权的图通常称为网(Network)
(2)图形化解释
图就是一张带权的图
即标识中国四大城市的直线距离的网
此图中的权就是两地的距离

图结构中,路径的长度是路径上的边或弧的数据
第一个顶点到最后一个顶点相同的路径称为 回环 或 环(Cycle)
序列中顶点不重复出现的路径称为 简单路径
5.环
(1)定义
除了第一个顶点和最后一个顶点之外
其余顶点不重复出现的回路,称为 简单回路 或 简单环
(2)图形化解释
下图所示两个图粗线都构成环
左侧的环只有第一个顶点和最后一个顶点都是 B
其余顶点没有重复出现,因此其是一个简单环
而右侧的环,由于顶点 C 的重复
因此它就不是简单环了

6.特性
A: 连通
图中顶点间存在 路径,两顶点存在路径则说明是 连通 的
如果路径最终回到起始点则成为 环,当中不重复叫 简单路径
若任意两顶点都是连通的,则图就是 连通图,有向则称为 强连通图
图中有子图,若子图极大连通则就是 连通分量,有向的则称为 强连通分量
E:生成树
无向图中连通且n个顶点n-1条边叫 生成树
有向图中一顶点入度为0
其余顶点入度为1的叫 有向树
一个有向图由若干棵有向树构成生成 森林
由于图的结构比较复杂,任意两个顶点之间都可能存在联系
因此无法以数据元素在内存中的物理位置来表示元素之间的关系
也就是说,图不可能用简单的顺序存储结构(即数组)来表示
而多重链表尽管可以实现图结构(即以一个数据域和多个指针域组成的结点表示图中的一个顶点)
但是却存在内存浪费或操作不便的问题
因此,图存储结构最终还是得通过结合顺序存储和链式存储才能做到比较好地实现
7.图的两种遍历【深度优先遍历-广度优先遍历】的区别用法
图的遍历和树的遍历类似
我们希望 从图中某一顶点触发,遍历图中其余顶点
且使每一个顶点仅被访问一次,这一过程就叫做图的遍历(Traversing Graph)
一:深度优先遍历
1.定义
称为 深度优先搜索,简称 DFS
二叉树的前序、中序、后序遍历,本质上也可以认为是深度优先遍历,深度优先搜索是先序遍历的推广
深度优先遍历(Depth First Search)的主要思想是:
A:首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点
B:当没有未访问过的顶点时则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过
2.图表达流程


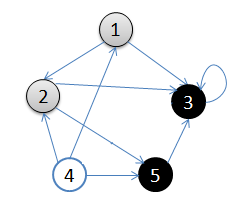
A:1.从v = 顶点1开始出发,先访问顶点1
B:2.按深度优先搜索递归访问v的某个未被访问的邻接点2
C:顶点2结束后,应该访问3或5中的某一个
D:这里为顶点3,此时顶点3不再有出度,因此回溯到顶点2
E:再访问顶点2的另一个邻接点5,由于顶点5的唯一一条边的弧头为3,已经访问了
F:所以此时继续回溯到顶点1,找顶点1的其他邻接点。
举例:
上图可以用邻接矩阵来表示为:
int maze[][] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 0, 1 },
{ 0, 0, 1, 0, 0 },
{ 1, 1, 0, 0, 1 },
{ 0, 0, 1, 0, 0 }
};JAVA代码实现:
import java.util.LinkedList;
import classEnhance.EnhanceModual;
public class DepthFirst extends EnhanceModual {
@Override
public void internalEntrance() {
// TODO Auto-generated method stub
int maze[][] = { { 0, 1, 1, 0, 0 }, { 0, 0, 1, 0, 1 }, { 0, 0, 1, 0, 0 }, { 1, 1, 0, 0, 1 },
{ 0, 0, 1, 0, 0 } };
dfs(maze, 1);
}
public void dfs(int[][] adjacentArr, int start) {
int nodeNum = adjacentArr.length;
if (start <= 0 || start > nodeNum || (nodeNum == 1 && start != 1)) {
System.out.println("Wrong input !");
return;
} else if (nodeNum == 1 && start == 1) {
System.out.println(adjacentArr[0][0]);
return;
}
int[] visited = new int[nodeNum + 1];//0表示结点尚未入栈,也未访问
LinkedList<Integer> stack = new LinkedList<Integer>();
stack.push(start);
visited[start] = 1;//1表示入栈
while (!stack.isEmpty()) {
int nodeIndex = stack.peek();
boolean flag = false;
if(visited[nodeIndex] != 2){
System.out.println(nodeIndex);
visited[nodeIndex] = 2;//2表示结点被访问
}
//沿某一条路径走到无邻接点的顶点
for (int i = 0; i < nodeNum; i++) {
if (adjacentArr[nodeIndex - 1][i] == 1 && visited[i + 1] == 0) {
flag = true;
stack.push(i + 1);
visited[i + 1] = 1;
break;//这里的break不能掉!!!!
}
}
//回溯
if(!flag){
int visitedNodeIndex = stack.pop();
}
}
}
}3.对于连通图
A:它从图中某个顶点
触发,访问此顶点
B:然后从
的未被访问的邻接点出发深度优先遍历图
C:直至图中所有和
有路径相通的顶点都被访问到
4.对于非连通图
只需要对它的连通分量分别进行深度优先遍历
A:即在先前一个顶点进行一次深度优先遍历后
B:若图中尚未有顶点未被访问
则另选图中一个未曾被访问的顶点作为起始点
C:重复上述过程,直至图中所有顶点都被访问到为止
5.深度优先搜索
就是选择一个顶点开始走
期间对于走过的顶点就不在访问,走其他未被访问的
一直走到无路可走
若此时还有顶点未走过,选择一个,重复上述过程
6.对无向图的深度优先遍历图解
以下"无向图"为例:

对上无向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问B(A的邻接点)。 在第1步访问A之后,接下来应该访问的是A的邻接点,即"B,D,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"D和F"的前面,因此,先访问B。
第3步:访问G(B的邻接点)。 和B相连只有"G"(A已经访问过了)
第4步:访问E(G的邻接点)。 在第3步访问了B的邻接点G之后,接下来应该访问G的邻接点,即"E和H"中一个(B已经被访问过,就不算在内)。而由于E在H之前,先访问E。
第5步:访问C(E的邻接点)。 和E相连只有"C"(G已经访问过了)。
第6步:访问D(C的邻接点)。
第7步:访问H。因为D没有未被访问的邻接点;因此,一直回溯到访问G的另一个邻接点H。
第8步:访问(H的邻接点)F。
因此访问顺序是:A -> B -> G -> E -> C -> D -> H -> F
7.对有向图的深度优先遍历
有向图的深优先遍历图解:

对上有向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问(A的出度对应的字母)B。 在第1步访问A之后,接下来应该访问的是A的出度对应字母,即"B,C,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"C和F"的前面,因此,先访问B。
第3步:访问(B的出度对应的字母)F。 B的出度对应字母只有F。
第4步:访问H(F的出度对应的字母)。 F的出度对应字母只有H。
第5步:访问(H的出度对应的字母)G。
第6步:访问(G的出度对应字母)E。 在第5步访问G之后,接下来应该访问的是G的出度对应字母,即"B,C,E"中的一个。但在本文的实现中,顶点B已经访问了,由于C在E前面,所以先访问C。
第7步:访问(C的出度对应的字母)D。
第8步:访问(C的出度对应字母)D。 在第7步访问C之后,接下来应该访问的是C的出度对应字母,即"B,D"中的一个。但在本文的实现中,顶点B已经访问了,所以访问D。
第9步:访问E。D无出度,所以一直回溯到G对应的另一个出度E。
因此访问顺序是:A -> B -> F -> H -> G -> C -> D -> E
二:广度优先遍历
1.定义
又称为 广度优先搜索,简称 BFS
广度优先遍历(Depth First Search)的主要思想是:类似于树的层序遍历
A:广度优先搜索是按层来处理顶点
B:距离开始点最近的那些顶点首先被访问
C:而最远的那些顶点则最后被访问
2.搜索步骤
A :首先选择一个顶点作为起始顶点,并将其染成灰色,其余顶点为白色。
B:将起始顶点放入队列中。
C:从队列首部选出一个顶点并找出所有与之邻接的顶点
将找到的邻接顶点放入队列尾部
将已访问过顶点涂成黑色,没访问过的顶点是白色
如果顶点的颜色是灰色,表示已经发现并且放入了队列
如果顶点的颜色是白色,表示还没有发现
D:按照同样的方法处理队列中的下一个顶点。
基本就是出队的顶点变成黑色,在队列里的是灰色,还没入队的是白色。
3.图表达流程
用一副图来表达这个流程如下:

A:初始状态,从顶点1开始,队列={1}

B:访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}

C:访问2的邻接顶点,2出队,4入队,队列={3,4}

D:访问3的邻接顶点,3出队,队列={4}

E:5.访问4的邻接顶点,4出队,队列={ 空}
从顶点1开始进行广度优先搜索:
初始状态,从顶点1开始,队列={1}访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}访问2的邻接顶点,2出队,4入队,队列={3,4}访问3的邻接顶点,3出队,队列={4}访问4的邻接顶点,4出队,队列={ 空}顶点5对于1来说不可达
举例:
上面图可以用如下邻接矩阵来表示:
int maze[][] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 1, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 0, 0, 0, 0 },
{ 0, 0, 1, 1, 0 }
};JAVA代码实现:
具体的代码如下,这段代码有两个功能,bfs()函数求出从某顶点出发的搜索结果,minPath()函数求从某一顶点出发到另一顶点的最短距离:
import java.util.LinkedList;
import classEnhance.EnhanceModual;
public class BreadthFirst extends EnhanceModual {
@Override
public void internalEntrance() {
// TODO Auto-generated method stub
int maze[][] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 1, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 0, 0, 0, 0 },
{ 0, 0, 1, 1, 0 }
};
bfs(maze, 5);//从顶点5开始搜索图
int start = 5;
int[] result = minPath(maze, start);
for(int i = 1; i < result.length; i++){
if(result[i] !=5 ){
System.out.println("从顶点" + start +"到顶点" + i + "的最短距离为:" + result[i]);
}else{
System.out.println("从顶点" + start +"到顶点" + i + "不可达");
}
}
}
public void bfs(int[][] adjacentArr, int start) {
int nodeNum = adjacentArr.length;
if (start <= 0 || start > nodeNum || (nodeNum == 1 && start != 1)) {
System.out.println("Wrong input !");
return;
} else if (nodeNum == 1 && start == 1) {
System.out.println(adjacentArr[0][0]);
return;
}
int[] visited = new int[nodeNum + 1];//0表示顶点尚未入队,也未访问,注意这里位置0空出来了
LinkedList<Integer> queue = new LinkedList<Integer>();
queue.offer(start);
visited[start] = 1;//1表示入队
while (!queue.isEmpty()) {
int nodeIndex = queue.poll();
System.out.println(nodeIndex);
visited[nodeIndex] = 2;//2表示顶点被访问
for (int i = 0; i < nodeNum; i++) {
if (adjacentArr[nodeIndex - 1][i] == 1 && visited[i + 1] == 0) {
queue.offer(i + 1);
visited[i + 1] = 1;
}
}
}
}
/*
* 从start顶点出发,到图里各个顶点的最短路径
*/
public int[] minPath(int[][] adjacentArr, int start) {
int nodeNum = adjacentArr.length;
LinkedList<Integer> queue = new LinkedList<Integer>();
queue.offer(start);
int path = 0;
int[] nodePath = new int[nodeNum + 1];
for (int i = 0; i < nodePath.length; i++) {
nodePath[i] = nodeNum;
}
nodePath[start] = 0;
int incount = 1;
int outcount = 0;
int tempcount = 0;
while (path < nodeNum) {
path++;
while (incount > outcount) {
int nodeIndex = queue.poll();
outcount++;
for (int i = 0; i < nodeNum; i++) {
if (adjacentArr[nodeIndex - 1][i] == 1 && nodePath[i + 1] == nodeNum) {
queue.offer(i + 1);
tempcount++;
nodePath[i + 1] = path;
}
}
}
incount = tempcount;
tempcount = 0;
outcount = 0;
}
return nodePath;
}
}
/*
//5
//3
//4
//2
//1
//从顶点5到顶点1的最短距离为:2
//从顶点5到顶点2的最短距离为:2
//从顶点5到顶点3的最短距离为:1
//从顶点5到顶点4的最短距离为:1
//从顶点5到顶点5的最短距离为:0
*/
4.对无向图的广度优先遍历图解

A:从A开始,有4个邻接点,“B,C,D,F”,这是第二层;
B:在分别从B,C,D,F开始找他们的邻接点,为第三层。以此类推。

因此访问顺序是:A -> B -> C -> D -> F -> G -> E -> H
5.对有向图的广度优先遍历图解

因此访问顺序是:A -> B -> C -> F -> D -> H -> G -> E
三:异同
1.同:深度优先遍历与广度优先遍历算法在时间复杂度上是一样的
2.异:不同之处仅仅在于对顶点访问的顺序不同
A:深度优先
更适合目标比较明确,以找到目标为主要目的的情况
B:而广度优
先更适合在不断扩大遍历范围时找到相对最优解的情况
例子:游乐场
图的深度优先遍历和广度优先遍历
深度优先遍历简称DFS(Depth First Search),广度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种方式。
我们来到一个游乐场,游乐场里有11个景点。我们从景点0开始,要玩遍游乐场的所有景点,可以有什么样的游玩次序呢?
深度优先遍历
二叉树的前序、中序、后序遍历,本质上也可以认为是深度优先遍历。

第一种是一头扎到底的玩法。我们选择一条支路,尽可能不断地深入,如果遇到死路就往回退,回退过程中如果遇到没探索过的支路,就进入该支路继续深入。
在图中,我们首先选择景点1的这条路,继续深入到景点4、景点5、景点3、景点6,终于发现走不动了(景点旁边的数字代表探索次序):

于是,我们退回到景点1,然后探索景点7,景点8,又走到了死胡同。于是,退回到景点7,探索景点10:

按照这个思路,我们再退回到景点1,探索景点9,最后再退回到景点0,后续依次探索景点2,终于玩遍了整个游乐场:

广度优先遍历
二叉树的层序遍历,本质上也可以认为是深度优先遍历。
在图中,我们首先探索景点0的相邻景点1、2、3、4

接着,我们探索与景点0相隔一层的景点7、9、5、6:

最后,我们探索与景点0相隔两层的景点8、10:

PHP代码实现
<?php
/**
* 图的深度优先遍历、广度优先遍历
* 图的存储结构--邻接矩阵
*/
class Graph {
// 存储节点信息
public $vertices;
// 存储边信息
public $arcs;
// 图的节点数
public $vexnum;
// 记录节点是否已被遍历
public $visited = [];
// 初始化
public function __construct($vertices) {
$this->vertices = $vertices;
$this->vexnum = count($this->vertices);
for ($i = 0; $i < $this->vexnum; $i++) {
for ($j = 0; $j < $this->vexnum; $j++) {
$this->arcs[$i][$j] = 0;
}
}
}
// 两个顶点间添加边(无向图)
public function addEdge($a, $b) {
if ($a == $b) { // 边的头尾不能为同一节点
return;
}
$this->arcs[$a][$b] = 1;
$this->arcs[$b][$a] = 1;
}
// 从第i个节点开始深度优先遍历
public function traverse($i) {
// 标记第i个节点已遍历
$this->visited[$i] = 1;
// 打印当前遍历的节点
echo $this->vertices[$i] . PHP_EOL;
// 遍历邻接矩阵中第i个节点的直接联通关系
for ($j = 0; $j < $this->vexnum ; $j++) {
// 目标节点与当前节点直接联通,并且该节点还没有被访问,递归
if ($this->arcs[$i][$j] == 1 && $this->visited[$j] == 0) {
$this->traverse($j);
}
}
}
//深度优先遍历
public function dfs() {
// 初始化节点遍历标记
$this->init();
// 从没有被遍历的节点开始深度遍历
for ($i = 0; $i < $this->vexnum; $i++) {
if ($this->visited[$i] == 0) {
// 若是连通图,只会执行一次
$this->traverse($i);
}
}
}
// 初始化节点遍历标记
public function init(){
for ($i = 0; $i < $this->vexnum; $i++) {
$this->visited[$i] = 0;
}
}
//广度优先遍历
public function bfs() {
// 初始化节点遍历标记
$this->init();
$queue = [];
for ($i = 0; $i < $this->vexnum; $i++) { // 对每一个顶点做循环
if (!$this->visited[$i]) { // 若是未访问过就处理
$this->visited[$i] = 1; // 设置当前顶点访问过
echo $this->vertices[$i] . PHP_EOL; // 打印顶点
$queue[] = $i; // 将此顶点入队列
while (!empty($queue)) { // 若当前队列不为空
$curr = array_shift($queue); // 将队对元素出队
for ($j = 0; $j < $this->vexnum; $j++) {
if ($this->arcs[$curr][$j] == 1 && $this->visited[$j] == 0) {
$this->visited[$j] = 1; // 将找到的此顶点标记为已访问
echo $this->vertices[$j] . PHP_EOL; // 打印顶点
$queue[] = $j; // 将找到的此顶点入队列
}
}
}
}
}
}
}
/*
0 1 2 3 4 5 6 7 8 9 10
0 0 1 1 1 1 0 0 0 0 0 0
1 1 0 0 0 1 0 0 1 0 1 0
2 1 0 0 0 0 0 0 0 0 0 0
3 1 0 0 0 0 1 1 0 0 0 0
4 1 1 0 0 0 1 0 0 0 0 0
5 0 0 0 1 1 0 0 0 0 0 0
6 0 0 0 1 0 0 0 0 0 0 0
7 0 1 0 0 0 0 0 0 1 0 1
8 0 0 0 0 0 0 0 1 0 0 0
9 0 1 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 1 0 0 0
so
0 1,2,3,4
1 0,4,7,9
2 0
3 0,5,6
4 0,1,5
5 3,4
6 3
7 1,8,10
8 7
9 1
10 7
*/
// 测试
$vertices = ['景点0', '景点1', '景点2', '景点3', '景点4', '景点5', '景点6', '景点7', '景点8', '景点9', '景点10'];
$graph = new Graph($vertices);
$graph->addEdge(0, 1);
$graph->addEdge(0, 2);
$graph->addEdge(0, 3);
$graph->addEdge(0, 4);
$graph->addEdge(1, 4);
$graph->addEdge(1, 7);
$graph->addEdge(1, 9);
$graph->addEdge(3, 5);
$graph->addEdge(3, 6);
$graph->addEdge(4, 5);
$graph->addEdge(7, 8);
$graph->addEdge(7, 10);
// 递归
echo "dfs:";
$graph->dfs();
echo "<br />";
echo "bfs:";
$graph->bfs();
8.最小生成树连通网的两种算法区别和用法【普里姆(Prim)算法-克鲁斯卡尔(Kruskal)算法】
一:最小生成树(Minimum Cost Spanning Tree)
1.定义
把构造连通网的最小代价生成树称为 最小生成树
就是n个顶点
用n-1条边把一个连通图连接起来
并且使权值的和最小
2.图形化分析

如图假设到
表示9个村庄,现在需要在这9个村庄假设通信网络
村庄之间的数字代表村庄之间的直线距离,求用最小成本完成这9个村庄的通信网络建设
3.分析
这幅图只一个带权值的图,即网结构
如果无向连通图是一个网图
那么它的所有生成树中必有一颗是边的权值总和最小的生成树,即最小生成树
找连通网的最小生成树,经典的算法有两种:普里姆(Prim)算法 和 克鲁斯卡尔(Kruskal)算法
二:普里姆算法(Prim算法)
1.定义
A:图论中的一种算法
B:可在加权连通图里搜索最小生成树,意即由此算法搜索到的边子集所构成的树中
C:不但包括了连通图里的全部顶点(英语:Vertex (graph theory))
D:且其全部边的权值之和亦为最小
历史由来:
该算法于1930年由捷克数学家沃伊捷赫·亚尔尼克(英语:Vojtěch Jarník)发现
并在1957年由美国计算机科学家罗伯特·普里姆(英语:Robert C. Prim)独立发现
1959年,艾兹格·迪科斯彻再次发现了该算法
因此,在某些场合,普里姆算法又被称为DJP算法、亚尔尼克算法或普里姆-亚尔尼克算法
2.算法步骤

A:从图中某一个顶点出发(这里选)寻找它相连的所有结点,比较这些结点的权值大小,然后连接权值最小的那个结点。(这里是
)
B:然后将寻找这两个结点相连的所有结点,找到权值最小的连接。(这里是)
C:重复上一步,知道所有结点都连接上

3.算法简单描写叙述
A:输入:一个加权连通图。当中顶点集合为V,边集合为E;
B:初始化:Vnew = {x},当中x为集合V中的任一节点(起始点),Enew = {},为空;
C:反复下列操作,直到Vnew = V:
a.在集合E中选取权值最小的边<u, v>,当中u为集合Vnew中的元素
而v不在Vnew集合当中。而且v∈V
(如果存在有多条满足前述条件即具有同样权值的边,则可随意选取当中之中的一个);
b.将v增加集合Vnew中,将<u, v>边增加集合Enew中。
D:输出:使用集合Vnew和Enew来描写叙述所得到的最小生成树。
4.图例描写叙述
| 图例 | 说明 | 不可选 | 可选 | 已选(Vnew) |
|---|---|---|---|---|
| | 此为原始的加权连通图。每条边一側的数字代表其权值。 | - | - | - |
| 顶点D被随意选为起始点。顶点A、B、E和F通过单条边与D相连。A是距离D近期的顶点。因此将A及对应边AD以高亮表示。 | C, G | A, B, E, F | D | |
| | 下一个顶点为距离D或A近期的顶点。B距D为9,距A为7。E为15。F为6。因此,F距D或A近期,因此将顶点F与对应边DF以高亮表示。
| C, G | B, E, F | A, D |
| 算法继续反复上面的步骤。距离A为7的顶点B被高亮表示。
| C | B, E, G | A, D, F | |
| | 在当前情况下,能够在C、E与G间进行选择。C距B为8,E距B为7,G距F为11。E近期。因此将顶点E与对应边BE高亮表示。
| 无 | C, E, G | A, D, F, B |
| | 这里。可供选择的顶点仅仅有C和G。C距E为5。G距E为9,故选取C,并与边EC一同高亮表示。
| 无 | C, G | A, D, F, B, E |
| 顶点G是唯一剩下的顶点,它距F为11,距E为9,E近期。故高亮表示G及对应边EG。 | 无 | G | A, D, F, B, E, C | |
| 如今,全部顶点均已被选取,图中绿色部分即为连通图的最小生成树。在此例中,最小生成树的权值之和为39。 | 无 | 无 | A, D, F, B, E, C, G |
5.普利姆(Prim)算法适用于求解无向图中的最小生成树
选择一个节点开始,比如V1进入集合U,剩下的集合的V-U包括剩下的节点,然后寻找从集合U到集合V-U最近的路径。
这里有三条路径分别是权重为6到V2,权重为5到V4以及权重为1到V3,显然到通过V3连接而集合U和集合V-U是最近的,
选择V3进入集合U。同样继续选择到V-U的路径,此时有6条可选路径,
分别是权为6到V2【从V1】,权为5到V4【从V1】,权为5到V2【从V3】,权为5到V4【从V3】,权为6到V5【从V3】,权为4到V6【从V3】。
选择出从V3到V6的路径并将V6添加至集合U中。按照这种方法依次将V4,V2和V5添加到集合U直到U和全体节点结合V相等,
或者说V-U集合为空时结束,这时选出的n-1条边即为最小生成树
6.简单证明prim算法
反证法:如果prim生成的不是最小生成树
1).设prim生成的树为G0
2).如果存在Gmin使得cost(Gmin)<cost(G0) 则在Gmin中存在<u,v>不属于G0
3).将<u,v>增加G0中可得一个环。且<u,v>不是该环的最长边(这是由于<u,v>∈Gmin)
4).这与prim每次生成最短边矛盾
5).故如果不成立,命题得证.
7.算法代码实现(未检验)
#define MAX 100000
#define VNUM 10+1 //这里没有ID为0的点,so id号范围1~10
int edge[VNUM][VNUM]={/*输入的邻接矩阵*/};
int lowcost[VNUM]={0}; //记录Vnew中每一个点到V中邻接点的最短边
int addvnew[VNUM]; //标记某点是否增加Vnew
int adjecent[VNUM]={0}; //记录V中与Vnew最邻近的点
void prim(int start)
{
int sumweight=0;
int i,j,k=0;
for(i=1;i<VNUM;i++) //顶点是从1開始
{
lowcost[i]=edge[start][i];
addvnew[i]=-1; //将全部点至于Vnew之外,V之内,这里仅仅要对应的为-1,就表示在Vnew之外
}
addvnew[start]=0; //将起始点start增加Vnew
adjecent[start]=start;
for(i=1;i<VNUM-1;i++)
{
int min=MAX;
int v=-1;
for(j=1;j<VNUM;j++)
{
if(addvnew[j]!=-1&&lowcost[j]<min) //在Vnew之外寻找最短路径
{
min=lowcost[j];
v=j;
}
}
if(v!=-1)
{
printf("%d %d %d\n",adjecent[v],v,lowcost[v]);
addvnew[v]=0; //将v加Vnew中
sumweight+=lowcost[v]; //计算路径长度之和
for(j=1;j<VNUM;j++)
{
if(addvnew[j]==-1&&edge[v][j]<lowcost[j])
{
lowcost[j]=edge[v][j]; //此时v点增加Vnew 须要更新lowcost
adjecent[j]=v;
}
}
}
}
printf("the minmum weight is %d",sumweight);
}8.时间复杂度
这里记顶点数v,边数e
邻接矩阵:O(v2)
邻接表:O(elog2v)
三:克鲁斯卡尔(Kruskal)算法
1.定义
Kruskal算法是一种用来寻找最小生成树的算法,由Joseph Kruskal在1956年发表
用来解决同样问题的还有Prim算法和Boruvka算法等
三种算法都是贪婪算法的应用
和Boruvka算法不同的地方是
Kruskal算法在图中存在同样权值的边时也有效
2.算法步骤
A:从某一顶点为起点
B:逐步找各个顶点最小权值的边来构成最小生成树
那我们也可以直接从边出发,寻找权值最小的边来构建最小生成树
不过在构建的过程中要考虑是否会形成环的情况

3.算法简单描写叙述
A:记Graph中有v个顶点:e个边
B:新建图Graphnew:Graphnew中拥有原图中同样的e个顶点,但没有边
C:将原图Graph中全部e个边按权值从小到大排序
D:循环:
从权值最小的边開始遍历每条边 直至图Graph中全部的节点都在同一个连通分量中
if 这条边连接的两个节点于图Graphnew中不在同一个连通分量中
增加这条边到图Graphnew中
4.图例描写叙述
首先第一步。我们有一张图Graph,有若干点和边
将全部的边的长度排序,用排序的结果作为我们选择边的根据。
这里再次体现了贪心算法的思想。资源排序,对局部最优的资源进行选择,排序完毕后。我们领先选择了边AD。这样我们的图就变成了右图
在剩下的变中寻找。我们找到了CE。
这里边的权重也是5
依次类推我们找到了6,7,7,即DF。AB,BE。
以下继续选择, BC或者EF虽然如今长度为8的边是最小的未选择的边。可是如今他们已经连通了(对于BC能够通过CE,EB来连接,相似的EF能够通过EB,BA,AD,DF来接连)。所以不须要选择他们。
相似的BD也已经连通了(这里上图的连通线用红色表示了)。
最后就剩下EG和FG了。当然我们选择了EG。
最后成功的图
5.Kruskal算法构造最小生成树的过程图解
Kruskal则是采取另一种思路,即从边入手
A:首先n个顶点分别视为n个连通分量
B:然后选择一条权重最小的边
如果边的两端分属于两个连通分量,就把这个边加入集合E
否则舍去这条边而选择下一条代价最小的边
C:依次类推,直到所有节点都在同一个连通分量上
6.简单证明Kruskal算法
对图的顶点数n做归纳,证明Kruskal算法对随意n阶图适用
n=1。显然能够找到最小生成树
如果Kruskal算法对n≤k阶图适用
那么,在k+1阶图G中
我们把最短边的两个端点a和b做一个合并操作,即把u与v合为一个点v'
把原来接在u和v的边都接到v'上去
这样就能够得到一个k阶图G'(u,v的合并是k+1少一条边),G'最小生成树T'能够用Kruskal算法得到
我们证明T'+{<u,v>}是G的最小生成树。
用反证法,如果T'+{<u,v>}不是最小生成树,最小生成树是T。即W(T)<W(T'+{<u,v>})。
显然T应该包括<u,v>,否则,能够用<u,v>增加到T中,形成一个环,删除环上原有的随意一条边,形成一棵更小权值的生成树。而T-{<u,v>}。是G'的生成树。所以W(T-{<u,v>})<=W(T')。也就是W(T)<=W(T')+W(<u,v>)=W(T'+{<u,v>}),产生了矛盾。于是如果不成立。T'+{<u,v>}是G的最小生成树。Kruskal算法对k+1阶图也适用。
由数学归纳法,Kruskal算法得证
7.算法代码实现(未检验)
typedef struct
{
char vertex[VertexNum]; //顶点表
int edges[VertexNum][VertexNum]; //邻接矩阵,可看做边表
int n,e; //图中当前的顶点数和边数
}MGraph;
typedef struct node
{
int u; //边的起始顶点
int v; //边的终止顶点
int w; //边的权值
}Edge;
void kruskal(MGraph G)
{
int i,j,u1,v1,sn1,sn2,k;
int vset[VertexNum]; //辅助数组。判定两个顶点是否连通
int E[EdgeNum]; //存放全部的边
k=0; //E数组的下标从0開始
for (i=0;i<G.n;i++)
{
for (j=0;j<G.n;j++)
{
if (G.edges[i][j]!=0 && G.edges[i][j]!=INF)
{
E[k].u=i;
E[k].v=j;
E[k].w=G.edges[i][j];
k++;
}
}
}
heapsort(E,k,sizeof(E[0])); //堆排序,按权值从小到大排列
for (i=0;i<G.n;i++) //初始化辅助数组
{
vset[i]=i;
}
k=1; //生成的边数,最后要刚好为总边数
j=0; //E中的下标
while (k<G.n)
{
sn1=vset[E[j].u];
sn2=vset[E[j].v]; //得到两顶点属于的集合编号
if (sn1!=sn2) //不在同一集合编号内的话,把边增加最小生成树
{
printf("%d ---> %d, %d",E[j].u,E[j].v,E[j].w);
k++;
for (i=0;i<G.n;i++)
{
if (vset[i]==sn2)
{
vset[i]=sn1;
}
}
}
j++;
}
} 8.时间复杂度
时间复杂度:elog2e
e为图中的边数
四:对比
假设网中有n个节点和e条边
普利姆算法的时间复杂度是O(n^2)
克鲁斯卡尔算法的时间复杂度是O(eloge)
可以看出前者与网中的边数无关
而后者相反
因此
普利姆算法适用于边稠密的网络
克鲁斯卡尔算法适用于求解边稀疏的网
9. AOV 网(Activity On Vertext Network)
在一个表示工程的有向图中
用顶点表示活动
用弧表示活动之间的优先关系
这样的有向图为顶点表示活动的网,我们成为 AOV 网(Activity On Vertext Network)
AOV 网中的弧表示活动之间存在的某种制约关系,同时 AOV 网中不能存在回路
10.拓扑序列
设 G=(V,E)是一个具有 n 个顶点的有向图
V 中的顶点序列
满足若从顶点
到
有一条路径
则在顶点序列中顶点
则我们将这样的顶点序列称为一个 拓扑序列
所谓 拓扑排序,其实就是对一个有向图构造拓扑序列的过程
对 AOV 网进行拓扑排序的基本思路是:
A:从 AOV 网中选择一个入度为 0的顶点输出
B:然后删去此顶点
C:并删除以此顶点为尾的弧
D:继续重复此步骤
E:直到输出全部顶点
或者 AOV 网中不存在入度为 0 的顶点为止
11: AOE 网(Activity On Edge Network)
在一个表示工程的带权有向图中
用顶点表示事件
用有向边表示活动
用边上的权值表示活动的持续时间
这种有向图的边表示活动的网
我们称之为 AOE 网(Activity On Edge Network)
A:始点或源点:我们把 AOE 网中没有入边的顶点称为始点或源点
B:终点或汇点:没有出边的顶点称为终点或汇点;由于一个工程,总有一个开始,一个结束,所以正常情况下,AOE 网只有一个源点一个汇点
C:路径长度:我们把路径上各个活动所持续的时间之和称为 路径长度
D:关键路径:从源点到汇点具有最大长度的路径叫 关键路径
E:关键活动:在关键路径上的活动叫关键活动
第九章:动态内存管理
动态内存管理机制,主要包含两方面内容,用户申请内存空间时,系统如何分配;用户使用内存空间完成后,系统如何及时回收。
另外,内存不断分配与回收的过程,会产生诸多内存碎片,但通过利用数据结构,内存碎片化的问题能够得到有效的解决。
其实,无论是那种操作系统,其内存管理机制都使用了大量数据结构的知识,大大提高内存管理的效率。
本章内容:
- 数据结构之动态内存管理机制
- 边界标识法管理动态内存
- 伙伴系统管理动态内存
- 无用单元收集(垃圾回收机制)
- 内存紧缩(内存碎片化处理)
1. 数据结构之动态内存管理机制
通过前面的学习,介绍很多具体的数据结构的存储以及遍历的方式,过程中只是很表面地介绍了数据的存储,而没有涉及到更底层的有关的存储空间的分配与回收,从本节开始将做更深入地介绍。
在使用早期的计算机上编写程序时,有关数据存储在什么位置等这样的问题都是需要程序员自己来给数据分配内存。而现在的高级语言,大大的减少了程序员的工作,不需要直接和存储空间打交道,程序在编译时由编译程序去合理地分配空间。
本章重点解决的问题是:
- 对于用户向系统提出的申请空间的请求,系统如何分配内存?
- 当用户不在使用之前申请的内存空间后,系统又如何回收?
这里的用户,不是普通意义上的用户,可能是一个普通的变量,一个应用程序,一个命令等等。只要是向系统发出内存申请的,都可以称之为用户。
占用块和空闲块
对于计算机中的内存来说,称已经分配给用户的的内存区统称为“占用块”;还未分配出去的内存区统称为“空闲块”或者“可利用空间块”。
系统的内存管理
对于初始状态下的内存来说,整个空间都是一个空闲块(在编译程序中称为“堆”)。但是随着不同的用户不断地提出存储请求,系统依次分配。
整个内存区就会分割成两个大部分:低地址区域会产生很多占用块;高地址区域还是空闲块。如图 1 所示:

图 1 动态分配过程中的内存状态
但是当某些用户运行结束,所占用的内存区域就变成了空闲块,如图 2 所示:

图 2 动态分配过程中的内存变化
此时,就形成了占用块和空闲块犬牙交错的状态。当后续用户请求分配内存时,系统有两种分配方式:
- 系统继续利用高地址区域的连续空闲块分配给用户,不去理会之前分配给用户的内存区域的状态。直到分配无法进行,也就是高地址的空闲块不能满足用户的需求时,系统才会去回收之前的空闲块,重新组织继续分配;
- 当用户运行一结束,系统马上将其所占空间进行回收。当有新的用户请求分配内存时,系统遍历所有的空闲块,从中找出一个合适的空闲块分配给用户。
合适的空闲块指的是能够满足用户要求的空闲块,具体的查找方式有多种,后续会介绍。
可利用空间表
当采用第 2 种方式时,系统需要建立一张记录所有空闲块信息的表。表的形式有两种:目录表和链表。各自的结构如图 3 所示:
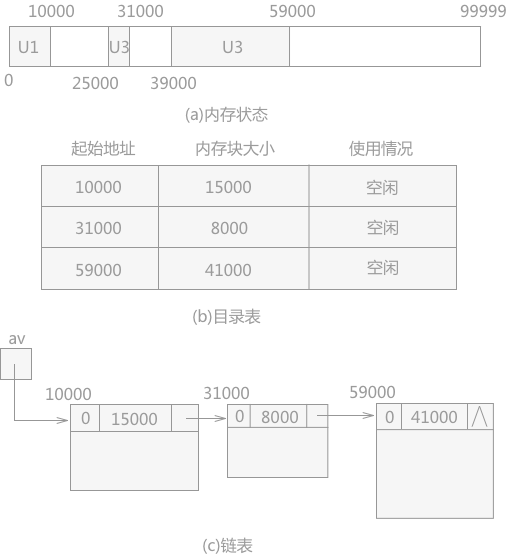
图 3 目录表和链表
目录表:表中每一行代表一个空闲块,由三部分组成:
- 初始地址:记录每个空闲块的起始地址。
- 空闲块大小:记录每个空闲块的内存大小。
- 使用情况:记录每个空闲块是否存储被占用的状态。
链表:表中每个结点代表一个空闲块,每个结点中需要记录空闲块的使用情况、大小和连接下一个空闲块的指针域。
由于链表中有指针的存在,所以结点中不需要记录各内存块的起始地址。
系统在不同的环境中运行,根据用户申请空间的不同,存储空闲块的可利用空间表有以下不同的结构:
- 如果每次用户请求的存储空间大小相同,对于此类系统中的内存来说,在用户运行初期就将整个内存存储块按照所需大小进行分割,然后通过链表链接。当用户申请空间时,从链表中摘除一个结点归其使用;用完后再链接到可利用空间表上。
- 每次如果用户申请的都是若干种大小规格的存储空间,针对这种情况可以建立若干个可利用空间表,每一个链表中的结点大小相同。当用户申请某一规格大小的存储空间时,就从对应的链表中摘除一个结点供其使用;用完后链接到相同规格大小的链表中。
- 用户申请的内存的大小不固定,所以造成系统分配的内存块的大小也不确定,回收时,链接到可利用空间表中每个结点的大小也各不一样。
第 2 种情况下容易面临的问题是:如果同用户申请空间大小相同的链表中没有结点时,就需要找结点更大的链表,从中取出一个结点,一部分给用户使用,剩余部分插入到相应大小的链表中;回收时,将释放的空闲块插入到大小相同的链表中去。如果没有比用户申请的内存空间相等甚至更大的结点时,就需要系统重新组织一些小的连续空间,然后给用户使用。
分配存储空间的方式
通常情况下系统中的可利用空间表是第 3 种情况。如图 3(C) 所示。由于链表中各结点的大小不一,在用户申请内存空间时,就需要从可利用空间表中找出一个合适的结点,有三种查找的方法:
- 首次拟合法:在可利用空间表中从头开始依次遍历,将找到的第一个内存不小于用户申请空间的结点分配给用户,剩余空间仍留在链表中;回收时只要将释放的空闲块插入在链表的表头即可。
- 最佳拟合法:和首次拟合法不同,最佳拟合法是选择一块内存空间不小于用户申请空间,但是却最接近的一个结点分配给用户。为了实现这个方法,首先要将链表中的各个结点按照存储空间的大小进行从小到大排序,由此,在遍历的过程中只需要找到第一块大于用户申请空间的结点即可进行分配;用户运行完成后,需要将空闲块根据其自身的大小插入到链表的相应位置。
- 最差拟合法:和最佳拟合法正好相反,该方法是在不小于用户申请空间的所有结点中,筛选出存储空间最大的结点,从该结点的内存空间中提取出相应的空间给用户使用。为了实现这一方法,可以在开始前先将可利用空间表中的结点按照存储空间大小从大到小进行排序,第一个结点自然就是最大的结点。回收空间时,同样将释放的空闲块插入到相应的位置上。
以上三种方法各有所长:
- 最佳拟合法由于每次分配相差不大的结点给用户使用,所以会生成很多存储空间特别小的结点,以至于根本无法使用,使用过程中,链表中的结点存储大小发生两极分化,大的很大,小的很小。该方法适用于申请内存大小范围较广的系统
- 最差拟合法,由于每次都是从存储空间最大的结点中分配给用户空间,所以链表中的结点大小不会起伏太大。依次适用于申请分配内存空间较窄的系统。
- 首次拟合法每次都是随机分配。在不清楚用户申请空间大小的情况下,使用该方法分配空间。
同时,三种方法中,最佳拟合法相比于其它两种方式,无论是分配过程还是回收过程,都需要遍历链表,所有最费时间。
空间分配与回收过程产生的问题
无论使用以上三种分配方式中的哪一种,最终内存空间都会成为一个一个特别小的内存空间,对于用户申请的空间的需求,单独拿出任何一个结点都不能够满足。
但是并不是说整个内存空间就不够用户使用。在这种情况下,就需要系统在回收的过程考虑将地址相邻的空闲块合并。
2. 边界标识法管理动态内存
本节介绍一种解决系统中内存碎片过多而无法使用的方法——边界标识法。
在使用边界标识法的系统管理内存时,可利用空间表中的结点的构成如图 1:

图 1 结构构成
每个结点中包含 3 个区域,head 域、foot 域 和 space 域:
- space 域表示为该内存块的大小,它的大小通过 head 域中的 size 值表示。
- head 域中包含有 4 部分:llink 和 rlink 分别表示指向当前内存块结点的直接前驱和直接后继。tag 值用于标记当前内存块的状态,是占用块(用 1 表示)还是空闲块(用 0 表示)。size 用于记录该内存块的存储大小。
- foot 域中包含有 2 部分:uplink 是指针域,用于指向内存块本身,通过 uplink 就可以获取该内存块所在内存的首地址。tag 同 head 域中的 tag 相同,都是记录内存块状态的。
注意:head 域和 foot 域在本节中都假设只占用当前存储块的 1 个存储单位的空间,对于该结点整个存储空间来说,可以忽略不计。也就是说,在可利用空间表中,知道下一个结点的首地址,该值减 1 就可以找到当前结点的 foot 域。
使用边界标识法的可利用空间表本身是双向循环链表,每个内存块结点都有指向前驱和后继结点的指针域。
所以,边界标识法管理的内存块结点的代码表示为:
typedef struct WORD{
union{
struct WORD *llink;//指向直接前驱
struct WORD *uplink;//指向结点本身
};
int tag;//标记域,0表示为空闲块;1表示为占用块
int size;//记录内存块的存储大小
struct WORD *rlink;//指向直接后继
OtherType other;//内存块可能包含的其它的部分
}WORD,head,foot,*Space;通过以上介绍的结点结构构建的可利用空间表中,任何一个结点都可以作为该链表的头结点(用 pav 表示头结点),当头结点为 NULL 时,即可利用空间表为空,无法继续分配空间。
分配算法
当用户申请空间时,系统可以采用 3 种分配方法中的任何一种。但在不断地分配的过程中,会产生一些容量极小以至无法利用的空闲块,这些不断生成的小内存块就会减慢遍历分配的速度。
3 种分配方法分别为:首部拟合法、最佳拟合法和最差拟合法。
针对这种情况,解决的措施是:
- 选定一个常量 e,每次分配空间时,判断当前内存块向用户分配空间后,如果剩余部分的容量比 e 小,则将整个内存块全部分配给用户。
- 采用头部拟合法进行分配时,如果每次都从 pav 指向的结点开始遍历,在若干次后,会出现存储量小的结点密集地分布在 pav 结点附近的情况,严重影响遍历的时间。解决办法就是:在每次分配空间后,让 pav 指针指向该分配空间结点的后继结点,然后从新的 pav 指向的结点开始下一次的分配。
分配算法的具体实现代码为(采用首部拟合法)
Space AllocBoundTag(Space *pav,int n){
Space p,f;
int e=10;//设定常亮 e 的值
//如果在遍历过程,当前空闲块的在存储容量比用户申请空间 n 值小,在该空闲块有右孩子的情况下直接跳过
for (p=(*pav); p&&p->size<n&&p->rlink!=(*pav); p=p->rlink);
//跳出循环,首先排除p为空和p指向的空闲块容量小于 n 的情况
if (!p ||p->size<n) {
return NULL;
}else{
//指针f指向p空闲块的foot域
f=FootLoc(p);
//调整pav指针的位置,为下次分配做准备
(*pav)=p->rlink;
//如果该空闲块的存储大小比 n 大,比 n+e 小,负责第一种情况,将 p 指向的空闲块全部分配给用户
if (p->size-n <= e) {
if ((*pav)==p) {
pav=NULL;
}
else{
//全部分配用户,即从可利用空间表中删除 p 空闲块
(*pav)->llink=p->llink;
p->llink->rlink=(*pav);
}
//同时调整head域和foot域中的tag值
p->tag=f->tag=1;
}
//否则,从p空闲块中拿出 大小为 n 的连续空间分配给用户,同时更新p剩余存储块中的信息。
else{
//更改分配块foot域的信息
f->tag=1;
p->size-=n;
//f指针指向剩余空闲块 p 的底部
f=FootLoc(p);
f->tag=0; f->uplink=p;
p=f+1;//p指向的是分配给用户的块的head域,也就是该块的首地址
p->tag=1; p->size=n;
}
return p;
}
}
回收算法
在用户活动完成,系统需要立即回收被用户占用的存储空间,以备新的用户使用。回收算法中需要解决的问题是:在若干次分配操作后,可利用空间块中会产生很多存储空间很小以致无法使用的空闲块。但是经过回收用户释放的空间后,可利用空间表中可能含有地址相邻的空闲块,回收算法需要将这些地址相邻的空闲块合并为大的空闲块供新的用户使用。
合并空闲块有 3 种情况:
- 该空闲块的左边有相邻的空闲块可以进行合并;
- 该空闲块的右边用相邻的空闲块可以进行合并;
- 该空闲块的左右两侧都有相邻的空闲块可以进行合并;
判断当前空闲块左右两侧是否为空闲块的方法是:对于当前空闲块 p ,p-1 就是相邻的低地址处的空闲块的 foot 域,如果 foot 域中的 tag 值为 0 ,表明其为空闲块; p+p->size 表示的是高地址处的块的 head 域,如果 head 域中的 tag 值为 0,表明其为空闲块。
如果当前空闲块的左右两侧都不是空闲块,而是占用块,此种情况下只需要将新的空闲块按照相应的规则(头部拟合法随意插入,其它两种方法在对应位置插入)插入到可利用空间表中即可。实现代码为:
//设定p指针指向的为用户释放的空闲块
p->tag=0;
//f指针指向p空闲块的foot域
Space f=FootLoc(p);
f->uplink=p;
f->tag=0;
//如果pav指针不存在,证明可利用空间表为空,此时设置p为头指针,并重新建立双向循环链表
if (!pav) {
pav=p->llink=p->rlink=p;
}else{
//否则,在p空闲块插入到pav指向的空闲块的左侧
Space q=pav->llink;
p->rlink=pav;
p->llink=q;
q->rlink=pav->llink=p;
pav=p;
}
如果该空闲块的左侧相邻的块为空闲块,右侧为占用块,处理的方法是:只需要更改左侧空闲块中的 size 的大小,并重新设置左侧空闲块的 foot 域即可(如图 2)。

图 2 空闲块合并(当前块,左侧内存块)
实现代码为:
//常量 n 表示当前空闲块的存储大小
int n=p->size;
Space s=(p-1)->uplink;//p-1 为当前块的左侧块的foot域,foot域中的uplink指向的就是左侧块的首地址,s指针代表的是当前块的左侧存储块
s->size+=n;//设置左侧存储块的存储容量
Space f=p+n-1;//f指针指向的是空闲块 p 的foot域
f->uplink=s;//这是foot域的uplink指针重新指向合并后的存储空间的首地址
f->tag=0;//设置foot域的tag标记为空闲块如果用户释放的内存块的相邻左侧为占用块,右侧为空闲块,处理的方法为:将用户释放掉的存储块替换掉右侧的空闲块,同时更改存储块的 size 和右侧空闲块的 uplink 指针的指向(如图 3 所示)。

图 3 空闲块合并(当前块、右侧内存块)
实现代码为:
Space t=p+p->size;//t指针指向右侧空闲块的首地址
p->tag=0;//初始化head域的tag值为0
//找到t右侧空闲块的前驱结点和后继结点,用当前释放的空闲块替换右侧空闲块
Space q=t->llink;
p->llink=q; q->rlink=p;
Space q1=t->rlink;
p->rlink=q1; q1->llink=p;
//更新释放块的size的值
p->size+=t->size;
//更改合并后的foot域的uplink指针的指向
Space f=FootLoc(t);
f->uplink=p;如果当前用户释放掉的空闲块,物理位置上相邻的左右两侧的内存块全部为空闲块,需要将 3 个空闲块合并为一个更大的块,操作的过程为:更新左侧空闲块的 size 的值,同时在可利用空间表中摘除右侧空闲块,最后更新合并后的大的空闲块的 foot 域。
此情况和只有左侧有空闲块的情况雷同,唯一的不同点是多了一步摘除右侧相邻空闲块结点的操作。
实现代码为:
int n=p->size;
Space s=(p-1)->uplink;//找到释放内存块物理位置相邻的低地址的空闲块
Space t=p+p->size;//找到物理位置相邻的高地址处的空闲块
s->size+=n+t->size;//更新左侧空闲块的size的值
//从可利用空间表中摘除右侧空闲块
Space q=t->llink;
Space q1=t->rlink;
q->rlink=q1;
q1->llink=q;
//更新合并后的空闲块的uplink指针的指向
Space f=FootLoc(t);
f->uplink=s;3. 伙伴系统管理动态内存
前面介绍了系统在分配与回收存储空间时采取的边界标识法。本节再介绍一种管理存储空间的方法——伙伴系统。
伙伴系统本身是一种动态管理内存的方法,和边界标识法的区别是:使用伙伴系统管理的存储空间,无论是空闲块还是占用块,大小都是 2 的 n 次幂(n 为正整数)。
例如,系统中整个存储空间为 2m 个字。那么在进行若干次分配与回收后,可利用空间表中只可能包含空间大小为:20、21、22、…、2m 的空闲块。
字是一种计量单位,由若干个字节构成,不同位数的机器,字所包含的字节数不同。例如,8 位机中一个字由 1 个字节组成;16 位机器一个字由 2 个字节组成。
可利用空间表中结点构成
伙伴系统中可利用空间表中的结点构成如图 1 所示:

图 1 结点构成
header 域表示为头部结点,由 4 部分构成:
- llink 和 rlink 为结点类型的指针域,分别用于指向直接前驱和直接后继结点。
- tag 值:用于标记内存块的状态,是占用块(用 1 表示)还是空闲块(用 0 表示)
- kval :记录该存储块的容量。由于系统中各存储块都是 2 的 m 幂次方,所以 kval 记录 m 的值。
代码表示为:
typedef struct WORD_b{
struct WORD_b *llink;//指向直接前驱
int tag;//记录该块是占用块还是空闲块
int kval;//记录该存储块容量大小为2的多少次幂
struct WORD_b *rlink;//指向直接后继
OtherType other;//记录结点的其它信息
}WORD_b,head;在伙伴系统中,由于系统会不断地接受用户的内存申请的请求,所以会产生很多大小不同但是都是容量为 2m 的内存块,所以为了在分配的时候查找方便,系统采用将大小相同的各自建立一个链表。对于初始容量为 2m 的一整块存储空间来说,形成的链表就有可能有 m+1 个,为了更好的对这些链表进行管理,系统将这 m+1 个链表的表头存储在数组中,就类似于邻接表的结构,如图 2。

图 2 伙伴系统的初始状态
可利用空间表的代码表示为:
#define m 16//设定m的初始值
typedef struct HeadNode {
int nodesize;//记录该链表中存储的空闲块的大小
WORD_b * first;//相当于链表中的next指针的作用
}FreeList[m+1];//一维数组分配算法
伙伴系统的分配算法很简单。假设用户向系统申请大小为 n 的存储空间,若 2k-1 < n <= 2k,此时就需要查看可利用空间表中大小为 2k 的链表中有没有可利用的空间结点:
- 如果该链表不为 NULL,可以直接采用头插法从头部取出一个结点,提供给用户使用;
- 如果大小为 2k 的链表为 NULL,就需要依次查看比 2k 大的链表,找到后从链表中删除,截取相应大小的空间给用户使用,剩余的空间,根据大小插入到相应的链表中。
例如,用户向系统申请一块大小为 7 个字的空间,而系统总的内存为 24 个字,则此时按照伙伴系统的分配算法得出:22 < 7 < 23,所以此时应查看可利用空间表中大小为 23 的链表中是否有空闲结点:
- 如果有,则从该链表中摘除一个结点,直接分配给用户使用;
- 如果没有,则需依次查看比 23 大的各个链表中是否有空闲结点。假设,在大小 24 的链表中有空闲块,则摘除该空闲块,分配给用户 23 个字的空间,剩余 23 个字,该剩余的空闲块添加到大小为 23 的链表中。
(A)分配前 (B)分配后
图 3 伙伴系统分配过程
回收算法
无论使用什么内存管理机制,在内存回收的问题上都会面临一个共同的问题:如何把回收的内存进行有效地整合,伙伴系统也不例外。
当用户申请的内存块不再使用时,系统需要将这部分存储块回收,回收时需要判断是否可以和其它的空闲块进行合并。
在寻找合并对象时,伙伴系统和边界标识法不同,在伙伴系统中每一个存储块都有各自的“伙伴”,当用户释放存储块时只需要判断该内存块的伙伴是否为空闲块,如果是则将其合并,然后合并的新的空闲块还需要同其伙伴进行判断整合。反之直接将存储块根据大小插入到可利用空间表中即可。
判断一个存储块的伙伴的位置时,采用的方法为:如果该存储块的起始地址为 p,大小为 2k,则其伙伴所在的起始地址为:

例如,当大小为 28 ,起始地址为 512 的伙伴块的起始地址的计算方式为:
由于 512 MOD 29=0,所以,512+28=768,及如果该存储块回收时,只需要查看起始地址为 768 的存储块的状态,如果是空闲块则两者合并,反之直接将回收的释放块链接到大小为 28 的链表中。
总结
使用伙伴系统进行存储空间的管理过程中,在用户申请空间时,由于大小不同的空闲块处于不同的链表中,所以分配完成的速度会更快,算法相对简单。
回收存储空间时,对于空闲块的合并,不是取决于该空闲块的相邻位置的块的状态;而是完全取决于其伙伴块。所以即使其相邻位置的存储块时空闲块,但是由于两者不是伙伴的关系,所以也不会合并。这也就是该系统的缺点之一:由于在合并时只考虑伙伴,所以容易产生存储的碎片。
4. 无用单元收集(垃圾回收机制)
通过前几节对可利用空间表进行动态存储管理的介绍,运行机制可以概括为:当用户发出申请空间的请求后,系统向用户分配内存;用户运行结束释放存储空间后,系统回收内存。这两部操作都是在用户给出明确的指令后,系统对存储空间进行有效地分配和回收。
但是在实际使用过程中,有时会因为用户申请了空间,但是在使用完成后没有向系统发出释放的指令,导致存储空间既没有被使用也没有被回收,变为了无用单元或者会产生悬挂访问的问题。
什么是无用单元?简单来讲,无用单元是一块用户不再使用,但是系统无法回收的存储空间。例如在C语言中,用户可以通过 malloc 和 free 两个功能函数来动态申请和释放存储空间。当用户使用 malloc 申请的空间使用完成后,没有使用 free 函数进行释放,那么该空间就会成为无用单元。
悬挂访问也很好理解:假设使用 malloc 申请了一块存储空间,有多个指针同时指向这块空间,当其中一个指针完成使命后,私自将该存储空间使用 free 释放掉,导致其他指针处于悬空状态,如果释放掉的空间被再分配后,再通过之前的指针访问,就会造成错误。数据结构中称这种访问为悬挂访问。
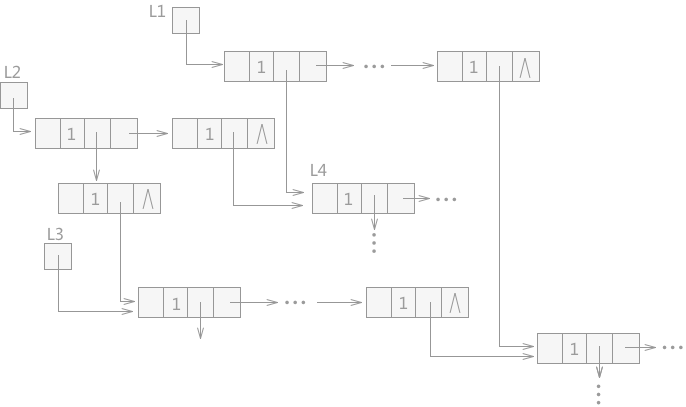
图 1 含有共享子表的广义表
在含有共享子表的广义表中,也可能会产生无用单元。例如图 1 中,L1、L2 和 L3 分别为三个广义表的表头指针,L4 为 L1 和 L2 所共享,L3 是 L2 的子表,L5 为 L1、L2 和 L3 三个广义表所共享。
在图 1 的基础上,假设表 L1 不再使用,而 L2 和 L3 还在使用,若释放表 L1,L1 中的所有结点所占的存储空间都会被释放掉,L2 和 L3 中由于同样包含 L1 中的结点,两个表会被破坏,某些指针会产生悬挂访问的错误;
而如果 L1 表使用完成后不及时释放,L1 中独自占用的结点由于未被释放,系统也不会回收,就会成为无用单元。
解决存储空间可能成为无用单元或者产生悬挂访问的方法有两个:
- 每个申请的存储空间设置一个计数域,这个计数域记录的是指向该存储空间的指针数目,只有当计数域的值为 0 时,该存储空间才会被释放。
- 在程序运行时,所有的存储空间无论是处于使用还是空闲的状态,一律不回收,当系统中的可利用空间表为空时,将程序中断,对当前不在使用状态的存储空间一律回收,全部链接成一个新的可利用空间表后,程序继续执行。
第一种方法非常简单,下面主要介绍第二种方法的具体实现。
第二种方法中,在程序运行过程中很难找出此时哪些存储空间是空闲的。解决这个问题的办法是:找当前正在被占用的存储空间,只需要从当前正在工作的指针变量出发依次遍历,就可以找到当前正在被占用的存储空间,剩余的自然就是此时处于空闲状态的存储空间。
如果想使用第二种方式,可以分为两步进行:
- 对所有当前正在使用的存储空间加上被占用的标记(对于广义表来说,可以在每个结点结构的基础上,添加一个 mark 的标志域。在初始状态下,所有的存储空间全部标志为 0,被占用时标记为 1);
- 依次遍历所有的存储空间,将所有标记为 0 的存储空间链接成一个新的可利用空间表。
对正在被占用的存储空间进行标记的方法有三种:
- 从当前正在工作的指针变量开始,采用递归算法依次将所有表中的存储结点中的标志域全部设置为 1;
- 第一种方法中使用递归算法实现的遍历。而递归底层使用的栈的存储结构,所以也可以直接使用栈的方式进行遍历;
- 以上两种方法都是使用栈结构来记录遍历时指针所走的路径,便于在后期可以沿原路返回。所以第三种方式就是使用其他的方法代替栈的作用。
递归和非递归方式在前面章节做过详细介绍,第三种实现方式中代替栈的方法是:添加三个指针,p 指针指向当前遍历的结点,t 指针永远指向 p 的父结点,q 指向 p 结点的表头或者表尾结点。在遍历过程遵循以下原则:
当 q 指针指向 p 的表头结点时,可能出现 3 种情况:
- p 结点的表头结点只是一个元素结点,没有表头或者表尾,这时只需要对该表头结点打上标记后即 q 指向 p 的表尾;
- p 结点的表头结点是空表或者是已经做过标记的子表,这时直接令 q 指针指向 p 结点的表尾即可;
- p 结点的表头是未添加标记的子表,这时就需要遍历子表,令 p 指向 q,q 指向 q 的表头结点。同时 t 指针相应地往下移动,但是在移动之前需要记录 t 指针的移动轨迹。记录的方法就是令 p 结点的 hp 域指向 t,同时设置 tag 值为 0。
当 q 指针指向 p 的表尾结点时,可能出现 2 种情况:
- p 指针的表尾是未加标记的子表,就需要遍历该子表,和之前的类似,令 p 指针和 t 指针做相应的移动,在移动之前记录 t 指针的移动路径,方法是:用 p 结点的 tp 域指向 t 结点,然后在 t 指向 p,p 指向 q。
- p 指针的表尾如果是空表或者已经做过标记的结点,这时 p 结点和 t 结点都回退到上一个位置。
由于 t 结点的回退路径分别记录在结点的 hp 域或者 tp 域中,在回退时需要根据 tag 的值来判断:如果 tag 值为 0 ,t 结点通过指向自身 hp 域的结点进行回退;反之,t 结点通过指向其 tp 域的结点进行回退。

图 2 待遍历的广义表
例如,图 2 中为一个待遍历的广义表,其中每个结点的结构如图 3 所示:

图 3 广义表中各结点的结构
在遍历如图 2 中的广义表时,从广义表的 a 结点开始,则 p 指针指向结点 a,同时 a 结点中 mark 域设置为 1,表示已经遍历过,t 指针为 nil,q 指针指向 a 结点的表头结点,初始状态如图 4 所示:

图 4 遍历广义表的初始状态
由于 q 指针指向的结点 b 的 tag 值为 1,表示该结点为表结构,所以此时 p 指向 q,q 指向结点 c,同时 t 指针下移,在 t 指针指向结点 a 之前,a 结点中的 hp 域指向 t,同时 a 结点中 tag 值设为 0。效果如图 5 所示:

图 5 遍历广义表(2)
通过 q 指针指向的结点 c 的 tag=1,判断该结点为表结点,同样 p 指针指向 c,q 指针指向 d,同时 t 指针继续下移,在 t 指针指向 结点 b 之前,b 结点的 tag 值更改为 0,同时 hp 域指向结点 a,效果图如图 6 所示:

图 6 遍历广义表(3)
通过 q 指针指向的结点 d 的 tag=0,所以,该结点为原子结点,此时根据遵循的原则,只需要将 q 指针指向的结点 d 的 mark 域标记为 1,然后让 q 指针直接指向 p 指针指向结点的表尾结点,效果图如图 7 所示:
图 7 遍历广义表(4)
当 q 指针指向 p 指针的表尾结点时,同时 q 指针为空,这种情况的下一步操作为 p 指针和 t 指针全部上移动,即 p 指针指向结点 b,同时 t 指针根据 b 结点的 hp 域回退到结点 a。同时由于结点 b 的tag 值为 0,证明之前遍历的是表头,所以还需要遍历 b 结点的表尾结点,同时将结点 b 的 tag 值改为 1。效果图如图 8 所示:

图 8 遍历广义表(5)
由于 q 指针指向的 e 结点为表结点,根据 q 指针指向的 e 结点是 p 指针指向的 b 结点的表尾结点,所以所做的操作为:p 指针和 t 指针在下移之前,令 p 指针指向的结点 b 的 tp 域指向结点 a,然后给 t 赋值 p,p 赋值 q。q 指向 q 的表头结点 f。效果如图 9 所示:

图 9 遍历广义表(6)
由于 q 指针指向的结点 f 为原子结点,所以直接 q 指针的 mark 域设为 1 后,直接令 q 指针指向 p 指针指向的 e 结点的表尾结点。效果如图 10 所示:

图 10 遍历广义表(7)
由于 p 指针指向的 e 结点的表尾结点为空,所以 p 指针和 t 指针都回退。由于 p 指针指向的结点 b 的 tag 值为 1,表明表尾已经遍历完成,所以 t 指针和 p 指针继续上移,最终遍历完成。
总结
无用单元的收集可以采用以上 3 中算法中任何一种。无论使用哪种算法,无用单元收集本身都是很费时间的,所以无用单元的收集不适用于实时处理的情况中使用。
5. 内存紧缩(内存碎片化处理)
前边介绍的有关动态内存管理的方法,无论是边界标识法还是伙伴系统,但是以将空闲的存储空间链接成一个链表,即可利用空间表,对存储空间进行分配和回收。
本节介绍另外一种动态内存管理的方法,使用这种方式在整个内存管理过程中,不管哪个时间段,所有未被占用的空间都是地址连续的存储区。
这些地址连续的未被占用的存储区在编译程序中称为堆。

图 1 存储区状态
假设存储区的初始状态如图 1 所示,若采用本节介绍的方法管理这块存储区,当 B 占用块运行完成同时所占的存储空间释放后,存储区的状态应如图 2 所示:

图 2 更新后的存储区状态
分配内存空间
在分配内存空间时,每次都从可利用空间中选择最低(或者最高)的地址进行分配。具体的实现办法为:设置一个指针(称为堆指针),每次用户申请存储空间时,都是堆的最低(或者最高)地址进行分配。假设当用户申请 N 个单位的存储空间时,堆指针向高地址(或者低地址)移动 N 个存储单位,这 N 个存储单位即为分配给用户使用的空闲块,空闲块的起始地址为堆指针移动之前所在的地址。
例如,某一时间段有四个用户(A、B、C、D)分别申请 12 个单位、6 个单位、10 个单位和 8 个单位的存储空间,假设此时堆指针的初值为 0。则分配后存储空间的效果为:

回收算法
由于系统中的可利用空间始终都是一个连续的存储空间,所以回收时必须将用户释放的存储块合并到这个堆上才能够重新使用。
存储紧缩有两种做法:其一是一旦用户释放所占空间就立即进行回收紧缩;另外一种是在程序执行过程中不立即回收用户释放的存储块,而是等到可利用空间不够分配或者堆指针指向了可利用存储区的最高地址时才进行存储紧缩。
具体的实现过程是:
- 计算占用块的新地址。设立两个指针随巡查向前移动,分别用于指示占用块在紧缩之前和之后的原地址和新地址。因此,在每个占用块的第一个存储单位中,除了存储该占用块的大小和标志域之外,还需要新增一个新地址域,用于存储占用块在紧缩后应有的新地址,即建立一张新、旧地址的对照表。
- 修改用户的出事变量表,保证在进行存储紧缩后,用户还能找到自己的占用块。
- 检查每个占用块中存储的数据。如果有指向其它存储块的指针,则需作相应修改。
- 将所有占用块迁移到新地址去,即进行数据的传递。
最后,还要将堆指针赋以新的值。
总结
存储紧缩较之无用单元收集更为复杂,是一个系统的操作,如果不是非不得已不建议使用。
第十章:查找
1.查找表(Search Table)
由同一类型的数据元素(或记录)构成的集合
2.关键字(Key)

(1)键值:是数据元素中的某个数据项的值,又称为 键值,用它可以标识一个数据元素
(2)关键码:也可以标识一个记录的某个数据项(字段),我们称为 关键码
(3)关键字(Primary Key):若此关键字可以唯一地标识一个记录,则称此关键字为主关键字
(4)次关键字(Secondary Key):而对于那些可以识别多个数据元素(或记录)的关键字,我们称为 次关键字
3.查找
(1)定义
就是根据给定的某个值,在查找表中确定一个其关键字等于给定值得数据元素(或记录)
从逻辑上来说,查找所基于的数据结构是集合
集合中的记录之间没有本质关系
可是要想获得较高的查找性能
我们就不能不改变数据元素之间的关系
在存储时可以将查找集合组织成表,树等结构
比如,对于静态查找表来说,我们不妨应用线性表结构来组织数据
这样可以使用顺序查找算法,如果再对主关键字排序,则可以应用折半查找等技术进行高效的查找
(2)静态查找表&动态查找表的区别用法【顺序查找-线性查找-折半查找-二分查找-有序表查找-插值查找-斐波那契查找-索引顺序表查找-分块查找】
一:静态查找表(Static Search Table)
只作查找操作的查找表
主要操作:
(1)查询某个 ”特定的“ 数据元素是否在查找表中
(2)检索某个 ”特定的“ 数据元素和各种属性
1.顺序查找表【线性查找】:从线性表一端开始扫描,将扫到的关键字与给定值比较,相同则查找成功
2.有序表查找【折半查找】【二分查找】:若线性表有序,则可以折半查找
折半查找升级版为插值查找,及不取1/2处。斐波那契查找,也是折半查找的变种
3.索引顺序表查找【分块查找】:效率介于1)2)之间
又称分块查找。块与块之间有序,块内无序。实际进行两次查找,第一次折半查找,第二次顺序查找
二: 动态查找表(Dynamic Search Table)
在查找过程中同时插入查找表中不存在的数据元素
或者从查找表中删除已经存在的某个数据元素
主要操作:
(1)查找时插入数据元素
(2)查找时删除数据元素
动态查找表可以对查找表结构进行修改,相比于静态查找表,查找过程中会修改元素
三:顺序查找(Sequential Search)【线性查找】
1.查找过程
是最基本的查找技术,它的查找过程是:
A:从表中第一个(或最后一个)记录开始
B:逐个进行记录的关键字和给定值比较
C:若某个记录的关键字等于给定值,则查找成功
D:如果直到最后一个(或第一个)记录,仍然找不到关键字与给定值相等的记录,则查找失败
2.时间复杂度:顺序查找的时间复杂度为O(n)
四:折半查找(Binary Search)【二分查找】【有序表查找】
它的前提是线性表中的记录必须是关键码有序(通常从小到达有序),线性表必须采用顺序存储
1.查找过程
二分查找的基本思想是:
在有序表中
A:取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功
B:若给定值小于中间记录的关键字,则在中间记录的左半区继续查找
C:若给定值大于中间记录的关键字,则在中间记录的右半区继续查找
D:不断重复上述过程,直到查找成功
或所有查找区域无记录,查找失败为止
2.时间复杂度:二分查找的时间复杂度为O(logn)
3.二分查找在静态查找表&动态查找表
由于 二分查找 的前提条件是要求集合有序
A:静态查找表:因此,对于静态查找表,一次排序后不再变化,这样的算法已经比较好了
B:动态查找表:但对于需要频繁执行插入或删除操作的数据集(动态查找表)来说;维护有序的排序会带来不小的工作量,那就不建议使用
五:插值查找(Interpolation Search)
1.查找过程
根据要查找的关键字 key
与查找表中的最大最小记录的关键字比较后的查找方法
其核心在于插值计算公式
2.插值查找&二分查找的异同
A:同:插值查找 与 二分查找 的时间复杂度都是O(logn)
B:异:
但对于表长较大,而关键字分布又比较均匀的查找表来说
插值查找算法的平均性能比二分查找要好的多
(因为,二分查找是折半查找
而插值查找会根据要查找的 key 计算得出其在整个查找表中的权重得到的位置会更接近 key 的位置)
反之,数组中如果分布类似
![]() 这种极端不均匀的数据
这种极端不均匀的数据
用插值查找未必是很合适的选择
六:斐波那契查找(Fibonacci Search)
1.查找过程
斐波那契查找与二分查找和插值查找都是有序查找算法
不过其是利用了黄金分割原理来实现的
其核心算法为:
A:当 ![]() 时,查找成功
时,查找成功
B:当![]() 时,新范围是第 low 个到第 mid-1 个,此时范围个数为
时,新范围是第 low 个到第 mid-1 个,此时范围个数为![]() 个
个
C:当![]() 时,新范围是第 m+1 个到第 high 个,此时范围个数为
时,新范围是第 m+1 个到第 high 个,此时范围个数为![]() 个
个
管斐波那契查找的时间复杂度也为 O(logn)
3.二分查找&插值查找&斐波那契查找的异同
A:同
二分查找,插值查找 和 斐波那契查找 都是有序查找算法
它们的本质其实是相同的,都是选择序列中间的某个位置与给定值进行比较
依据序列的有序性,每次查找都可以去除两端一部分序列,从而提升查找性能
B:异
三者的区别仅在与中间位置的选择策略不同:
二分查找直接取序列中点作为 mid
插值查找按给定值在序列的权重(比例)作为 mid
斐波那契查找是用序列的黄金分割点(即:0.618:1)作为 mid
但就平均性能来说,斐波那契查找要优于二分查找
还有一点比较关键的地方
二分查找是进行加减法与除法运算:mid=low+(high-low)/2
插值查找进行复杂的四则运算:mid=low+(high-low)*(key-a[low])/(a[high]-a[low])
斐波那契查找只是最简单的加减法运算:mid=low+F[k-1]-1
在海量数据的查找过程中,这种细微的差别可能会影响最终的查找效率
七:索引顺序表查找【分块查找】
是顺序查找的一种改进
1.性能:其性能介于顺序查找和折半查找之间
2.查找过程
A:分块查找把线性表分成若干块
每一块中的元素存储顺序是任意的
但是块与块之间必须是按关键字大小排序
(即前一块中的最大关键字大于(或小于)后一块中的最小(或最大)关键字值)。
B:另外,需要建立一个索引表
索引表中的一项对应线性表中的一项
索引表按关键字值递增(或递减)顺序排列
索引项由关键字域和链域组成
关键字域存放相应块的最大关键字
链域存放指向本块第一个结点的指针
索引表查找算法:实际上进行了两次查找(折半查找+顺序查找)
因此整个算法的平均查找长度是两次查找的平均查找长度之和
4.索引
假设查找的数据集是普通的顺序存储
那么插入操作(插入到末尾)和删除操作(删除记录后记录向前移相对耗时
但如果只把删除的元素与最后一个元素互换
然后表记录数减一,则很高效)的效率是可以接受的
但是顺序存储表由于无序会造成查找效率很低
如果查找的数据集是有序线性表,并且是顺序存储的
那么其查找(二分法,插值法,斐波那契···)效率很高
但是由于有序,在插入和删除操作上,就需要耗费大量的时间
(1)定义
就是把一个关键字与它对应的记录相关联的过程(关键字=记录)
数据结构的最终目的就是提高数据的处理速度
索引是为了加快查找速度而设计的一种数据结构
一个索引由若干个索引项构成
每个索引项至少应包含关键字和其对应的记录在存储器中的位置等信息
索引技术是组织大型数据库以及磁盘文件的一种重要技术
(2)按照结构分类
索引按照结构可以分为:线性索引,树形索引和多级索引
(3)三种线性索引&两种表【稠密索引-分块索引-倒排索引-多重表-倒排表】
一:线性索引【索引表】:就是将索引项集合组织为线性结构,也称为 索引表
二:稠密索引
1.定义:指在线性索引中,将数据集中的每个记录对应一个索引项
2.图形化解释

稠密索引要应对的可能是成千上万的数据
因此,对于稠密索引这个索引表来说,索引项一定是按照关键码有序的排列
三:分块索引
1.定义
对数据集进行有序分块,并将每块对应一个索引项
其中,分块有序 指的是把数据集的记录分成若干块
并且这些块需要满足 块内无序 和 块间有序 这两个条件
注意理解:稠密索引是因为索引项和数据集的记录个数相同,所以空间代价很大
我们可以对数据集进行分块,使其分块有序,然后再对每一块建立一个索引项(类似于图书馆的分块)
2.图形化解释

3.查找步骤
在分块索引表中查找,就是分两步进行:
A:在分块索引表中查找要查关键字所在的块
由于分块索引表示块间有序的
因此很容易利用二分插值等算法得到结果
B:找到关键字所在的块后
根据块首指针找到对应的块
并在块中顺序查找关键码
因为块中可以是无序的,因此只能顺序查找
4.分块有序:是把数据集的记录分成了若干块,并且这些块需要满足两个条件
(1)块内无序:每一块内的记录不要求有序
(2)块间有序:比如要求第二块记录的关键字均要大于第一块中所有记录的关键字,第三块要大于第二块。 只有块间有序才有可能在查找时带来效率
5.分块索引:对于分块有序的数据集,将每块对应一个索引项,这种索引方法叫做分块索引
分块索引结构数据项
分块索引的索引项结构分为三个数据项:
A:最大关键码--存储每一块中的最大关键字
B:块长--存储每一块中记录的个数以便于循环时使用
C:块首地址--用于指向块首数据元素的指针
便于开始对这一块中记录进行遍历
四:倒排索引
指的是索引项具备 次关键码 和 记录号表 两个字段
且记录号表存储具有相同次关键字的所有记录的记录号(可以是指向记录的指针或者是该记录的主关键字)
则称这样的索引方法为 倒排索引(inverted index)
之所以成为倒排索引,是因为其是有属性值来确定记录位置
而不是由记录来确定属性值(即通过内容关键字来查找文章,而不是由文章来查找其内容关键字)
五:多重表
若不仅要按主关键码进行查找
还要按次关键码按给定码值或给定取值范围进行查找
则需在建立主索引的同时,也建立次关键码索引

六:倒排表
索引项包括次关键码的值和具有该值的各记录的地址
或包括次关键码的一个取值范围和取值在该范围内的所有记录的地址
优缺点
优点:
(1)既适合主关键码查找,也适合次关键码的查找
(2)查找速度较快
(3)没有要求对主文件中次关键码相同的记录建立链接
因而不需要对主文件进行修改
故其使用和维护简单方便
缺点:
(1)由于记录号表是不定长的,故处理起来不太方便
(2)由于倒排表的记录号表中记录号要求有序
这对在主文件中进行插入和删除记录操作带来相应处理上的工作量
5.二叉排序树【 二叉查找树】
而使用 二叉排序树 这种存储结构时,就可以实现对动态查找表的高效插入,删除和查找操作
(1)定义
二叉排序树(Binary Sort Tree):又称为 二叉查找树
它或者是一棵空树
或者是具有下列性质的二叉树:
A:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
B:若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值
C:它的左、右子树也分别为二叉排序树
(2)目的
构造一棵 二叉排序树 的目的,其实并不是为了排序
而是为了提高查找和插入删除关键字的速度
不管怎么说,在一个有序数据集上的查找,速度总是要快于无序的数据集的
而二叉排序树这种非线性的结构
也有利于插入和删除的实现
(3)存储方式
A:定义:二叉排序树 是以链接的方式存储
B:执行插入或删除操作时:保持了链接存储结构在执行插入或删除操作时不用移动元素的有点(只需修改链接指针),插入和删除的时间性能比较好
C:查找操作时:而对于二叉排序树的查找,走的就是从根结点到要查找的结点的路径,其比较次数等于给定值得结点在二叉排序树的层数
D:查找次数最少:极端情况下,查找次数最少为 1 次,即根结点就是要找的结点
E:查找次数最多:最多也不会超过树的深度。也就是说,二叉排序树的查找性能取决于二叉排序树的形状
F:二叉排序树的形状:很可惜的是,二叉排序树的形状是不确定的(想象下极端的右斜树或左斜树)
G:解决二叉排序树的形状问题:对于这个问题,解决方案就是让二叉排序树左右子树是比较平衡的
H:深度:即其深度与完全二叉树相同,均为![]()
I:时间复杂度:那么查找的时间复杂度就为![]()
J:平衡二叉树(AVL 树):近似二分查找,这种结构就称为 平衡二叉树
(4)平衡二叉树:(Self-Balancing Binary Search Tree 或 Height-Balanced Binary Search Tree)是一种二叉排序树,其中每一个结点的左子树和右子树的高度差至多等于1
(5)平衡因子 BF(Balance Factor):将二叉树上结点的左子树深度减去右子树深度的值称为 平衡因子 BF
(6)平衡二叉树:上所有结点的平衡因子只可能是 -1、0 和 1,只要二叉树上有一个结点的平衡因子的绝对值大于 1,则该二叉树就是不平衡的
(7)最小不平衡子树:距离插入结点最近的,且平衡因子的绝对值大于 1的结点为根的子树,我们称为 最小不平衡子树

如上图所示,当新插入结点 37 时
距离它最近的平衡因子绝对值超过 1 的结点是 58
(58 的左子树高度为 2,右子树高度为 0)
所以从 58 开始以下的子树为最小不平衡子树
(8)平衡二叉树实现原理
平衡二叉树构建的基本思想就是在构建二叉树排序树的过程中
每当插入一个结点时
先检查是否因插入而破坏了树的平衡性
若是,则找出最小不平衡子树
在保持二叉排序树特性的前提下
调整最小不平衡子树中各结点之间的链接关系
进行相应的旋转,使之成为新的平衡子树
6.多路查找树(muitl-way search tree)
(1)分析
对于 树 来说,一个结点只能存储一个元素
那么在元素非常多的时候,就会使得要么树的度非常大(结点拥有子树的个数的最大值)
要么树的高度非常大,甚至两者都必须足够大才行
这就使得内存存取外存次数非常多
这显然成了时间效率上的瓶颈
这迫使我们要打破每一个结点只存储一个元素的限制,为此引入了多路查找树的概念
(2)定义
其每一个结点的孩子树可以多于两个
且每一个结点处可以存储多个元素
由于它是查找树,因此所有元素之间存在某种特定的排序关系(即其是有序的)
(3)四中常见的多路查找树【2-3 树$2-3-4 树$B 树$B+ 树】的区别用法
一:2-3 树
1.定义
每个结点都具有两个孩子(我们称它为 2 结点)或三个孩子(我们称它为 3 结点)的树
一个 2 结点包含一个元素和两个孩子(或没有孩子)
且左子树数据元素小于该元素
右子树数据元素大于该元素
一个 3 结点 包含一小一大两个元素和三个孩子(或没有孩子)
如果有 3 个孩子的话
左子树包含小于较小元素的元素
右子树包含大于较大元素的元素
中间子树包含介于两元素之间的元素
2.图形化解释

二: 2-3-4 树
定义
其为 2-3 树 的扩展
在其基础上增加一个 4 结点 的使用
一个 4 结点包含小中大三个元素和四个孩子(或没有孩子)
如果某个 4 结点有孩子的话
左子树包含小于最小元素的元素
第二子树包含大于最小元素,小于第二元素的元素
第三子树包含大于第二元素,小于最大元素的元素
右子树包含大于最大元素的元素
三:B 树(B-tree)
定义
其是一种平衡的多路查找树
2-3 树 和 2-3-4 树 都是 B 树 的特例
结点最大的孩子数目称为 B 树 的阶(order)
因此
2-3 树 为3 阶 B 树
2-3-4 树 为4 阶 B 树
四: B+ 树
定义
其是应文件系统所需而出的一种 B 树 的变形树
在 B 树 中
每一个元素在该树中只出现一次
有可能在叶子结点上
也有可能在分支结点上
而在 B+ 树 中
出现在分支结点中的元素会被当作它们在该分支结点位置的中序后继者(叶子结点)中再次列出
另外,每一个叶子结点都会保存一个指向后一叶子结点的指针
五: B 树 减少这种内外存交互
1.传统的硬盘处理
对于海量数据,数据一般都保存到外存(eg:硬盘)中
每次需要数据时,再读取到内存中
因此,如果内存与外存交换数据次数频繁,就会造成时间效率上的瓶颈
2. B 树处理
而使用 B 树 可以减少这种内外存交互:
我们的外存,比如硬盘,是将所有的信息分割成相等大小的页面,每次硬盘读写的都是一个或多个完整的页面
对于一个硬盘来说,一页的长度可能是 211 到 214 个字节
3.思路方法
在一个典型的 B 树 应用中,要处理的硬盘数据量很大,因此无法一次全部装入内存
因此我们会对 B 树 进行调整
使得 B 树 的阶数(或结点的元素)与硬盘存储的页面大小相匹配
比如说一棵 B 树 的阶为 1001(即 1 个结点包含 1000 个关键字),高度为 2,它可以储存超过 10 亿个关键字
我们只要让根结点持久地保留在内存中
那么在这棵树上,寻找某一个关键字至多需要两次硬盘的读取即可
通过这种方式
在有限内存的情况下,每一次磁盘的访问我们都可以获得最大数量的数据
可以说,B 树的数据结构就是为内外存的数据交互准备的
7.散列技术
(1)定义
是在记录的存储位置和它的关键字之间建立一个确定的对应关系![]()
使得每个关键字 key 对应一个存储位置![]()
查找时,根据这个确定的对应关系找到给定值 key 的映射![]()
若查找集合中存在这个记录,则必定在 ![]() 的位置上
的位置上
这里我们把这种对应关系![]() 称为 散列函数,又称为 哈希(Hash)函数
称为 散列函数,又称为 哈希(Hash)函数
散列技术 既是一种存储方法,也是一种查找方法
通过 散列函数 计算关键字散列地址
并按此散列地址存储对应记录查找时
通过同样的 散列函数 计算关键字散列地址,按此地址访问对应记录
(2)散列表【哈希表(Hash table)】
采用散列技术将记录存储在一块连续的存储空间中
则这块连续存储空间称为 散列表 或 哈希表
(3)散列地址
那么关键字对应的记录存储位置我们称为 散列地址
(4)散列函数设计原则
A:计算简单:
散列函数的计算时间不应该超过其他查找技术与关键字比较的时间
防止散列冲突最好的办法就是尽量让散列地址均匀地分布在存储空间中
这样可以保证存储空间的有效利用,并减少为处理冲突而耗费的时间
(5)构造散列函数的六种方法【直接定址法-数字分析法-平方取中法-折叠法-除留余数法-随机数法】
这些方法原理都是将原来数字按某种规律变成另一个数字
一:直接定址法
取关键字的某个线性函数值作为散列地址:![]()
直接定址法获取得到的散列函数有点就是简单,均匀也不会产生冲突
但问题是这需要事先知道关键字的分布情况
适合查找表较小且连续的情况
由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用
二:数字分析法
如果关键字是位数较多的数字(比如手机号),且这些数字部分存在相同规律
则可以采用抽取剩余不同规律部分作为散列地址
比如手机号前三位是接入号,中间四位是 HLR 识别号,只有后四位才是真正的用户号
也就是说,如果手机号作为关键字,那么极有可能前 7 位是相同的
此时我们选择后四位作为散列地址就是不错的选择
同时,对于抽取出来的数字,还可以再进行反转
右环位移,左环位移等操作
目的就是为了提供一个能够尽量合理地将关键字分配到散列表的各个位置的散列函数
数字分析法通常适合处理关键字位数比较大的情况
如果事先知道关键字的分布且关键字的若干位分布较均匀,就可以考虑用这个方法
三:平方取中法
即取关键字平方的中间位数作为散列地址
比如假设关键字是 4321,那么它的平方就是 18671041,抽取中间的 3 位就可以是 671,也可以是 710,用做散列地址
平方取中法比较适合于不知道关键字的分布,而位数又不是很大的情况
四:折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短些)
然后将这几部分叠加求和
并按散列表表长,取后几位作为散列地址
比如假设关键字是 9876543210,散列表表长为三位
则我们可以将它分为四组 987|654|321|0
然后将它们叠加求和 987+654+321+0=1962
再取后 3 位得到散列地址即为 962
有时可能这还不能够保证分布均匀
那么也可以尝试从一端到另一端来回折叠后对齐相加
比如讲 987 和 321 反转
再与 654 和 0 相加,变成 789+654+123+0=1566
此时散列地址为 566
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况
五:除留余数法
此方法为最常用的构造散列函数方法
对于散列表长为![]() 的散列函数公式为:
的散列函数公式为:![]()
很显然,本方法的关键就在于选择合适的 ![]()
根据前辈们的经验
若散列表表长为![]()
通常 ![]() 为小于或等于表长(最好接近
为小于或等于表长(最好接近![]() )的最小质数或不包含小于 20 质因子的合数
)的最小质数或不包含小于 20 质因子的合数
六:随机数法
选择一个随机数
取关键字的随机函数值为它的散列地址:![]()
当关键字的长度不等时采用这个方法构造散列函数是比较合适的
(6)处理散列冲突的四种方法【开放定址法-再散列函数法-链地址法-公共溢出区法】
一:开放定址法
1.定义:所谓的 开放定址法 就是一旦发生了冲突,就去寻找下一个空的散列地址
2.要求:只要散列表足够大,空的散列地址总能找到,并将记录存入
3. 线性探测法
![]()
使用该公式用于解决冲突的开放定址法称为 线性探测法
对于 线性探测法,在出现冲突时,它只能晚后一步一步检测看是否有空位置
假设此时该冲突位置后续没有可用位置,但前面有一个空位置
尽管可以不断地求余数后得到结果,但效率很差
4.二次探测法
因此可以改进该算法,增加双向寻找可能的空位置,这种新算法称为 二次探测法:
![]()
5. 随机探测法
此外还有一种方法是,在冲突时,对于位移量
采用随机函数计算得到,我们称为 随机探测法:
注:这里的随机其实是伪随机数
即设置相同的随机种子,则不断调用随机函数的过程中就可以生成不会重复的数列
同时,在查找时,用同样的随机种子,它每次得到的数列也是相同的
因此相同的
就可以得到相同的散列地址
二:再散列函数法
1.散列函数:即提供多个散列函数:![]()
2.解释
这里的 ![]() 就是不同的散列函数
就是不同的散列函数
然后每当发生散列地址冲突时
就换一个散列函数计算
相信总会有一个可以把冲突解决掉(todo:: how to search??)
3.优点弊端
A:优点:这种方法能够使得关键字不产生聚集
B:弊端:当然,相应地也增加了计算的时间
三:链地址法
1.定义
将所有关键字为同义词(即哈希地址相同)的记录存储在一个单链表中
我们称这种表为同义词子表
在散列表中只存储所有同义词子表的头指针
2.优点弊端
A:优点:链地址法对于可能会造成很多冲突的散列函数来说提供了绝不会出现找不到地址的保障
B:弊端:当然,这也就带来了查找时需要遍历单链表的性能损耗
四: 公共溢出区法
即为所有冲突的关键字建立一个公共的溢出区来存放
在查找时,对给定值通过散列函数计算出散列地址后
先与基本表的相应位置进行比对
如果相等,则查找成功
如果不相等,则到溢出表去进行顺序查找
如果对于基本表而言,有冲突的数据很少的情况下
公共溢出区的结构对查找性能来说还是非常高的
(7)散列表性能分析
A:散列函数是否均匀:
散列函数的好坏直接影响着出现冲突的频繁程度
由于不同的散列函数对同一组随机的关键字,产生冲突的可能性是相同的
因此可以不考虑它对平均查找长度的影响
B:处理冲突的方法:
相同的关键字,相同的散列函数,但处理冲突的方法不同,会使得平均查找长度不同
比如线性探测处理冲突可能会产生堆积
显然就没有二次探测法好
而链地址法处理冲突不会产生任何堆积
因而具有更佳的平均查找性能
C:散列表的装填因子:
所谓的装填因子
标志着散列表的装满的程度
当填入表中的记录越多
就越大,产生冲突的可能性就越大
比如假设散列表长度是 12,而填入表中的记录个数为 11,那么此时的装填因子
因此再填入最后一个关键字产生冲突的可能性就非常之大
也就是说,散列表的平均查找长度取决于装填因子
而不是取决于查找集合中的记录个数
不管记录个数
有多大
我们总可以选择一个合适的装填因子以便将平均查找长度限定在一个范围之内
此时我们散列查找的时间复杂度就真的是
通常我们都是将散列表的空间设置得比查找集合大
此时虽然是浪费了一定的空间,但换来的是查找效率的大大提升
总的来说,还是非常值得的
第十一章:内部排序
1.定义
排序 的依据是关键字之间的大小关
即对同一个记录集合(数据集合)
针对不同的关键字进行排序
可以得到不同的序列
(注:此处的关键字可以是记录的主关键字,也可以是此关键字,甚至是若干数据项的组合)
2.多个关键的排序最终都可以转化为单个关键字的排序
比如,现在要对学生的成绩进行排序
排序规则为按总分降序排序,若总分分数相同,按主科(语数英)总分数进行降序排序
直接的思路肯定是先进行总分排序,然后遇到总分相同的,就进行主科总分排序
但是还可以使用一个技巧来实现一次排序即可完成上述组合排序问题:
例如,把总分与主科总分当成字符串首尾拼接到一起
(注意如果主科成绩不够三位,则需在前面补零)
(比如:甲,乙两人的总分都为 753,其中,
甲的理科总分为 229,
而乙的理科总分为 236,
则甲的拼接为:"753229",
乙的拼接为:"753236",
比较这两个拼接字符串即可直接(一次性)
直到乙排在甲前面(乙 > 甲)
3.排序的稳定性
假设
且在排序前的序列中
领先于
如果排序后
则称所用的排序方法是 稳定的
反之,若可能使得排序后的序列中
则称所用的排序方法是 不稳定的
如下图所示:
4.内排序&外排序
据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序 和 外排序
(1)内排序
是在排序整个过程中,待排序的所有记录全部被放置在内存中
内排序分为:插入排序,交换排序,选择排序 和 归并排序
(2)外排序
是由于排序的记录个数太多,不能同时放置在内存
整个排序过程需要在内外存之间多次交互数据才能进行
5.影响内排序的三个方面
(1)时间性能
在内排序中,主要进行两种操作:比较 和 移动
是指关键字之间的比较,这是做排序最基本的操作
是指记录从一个位置移动到另一个位置
事实上,移动可以通过改变记录的存储方式来予以避免
高效率的内排序算法应该是具有尽可能少的关键字比较次数和尽可能少的记录移动次数
(2)辅助空间
辅助内存空间是除了存放待排序所占用的存储空间之外
执行算法所需要的其他存储空间
(3)算法的复杂性
此处指的是算法本身的复杂度
而不是指算法的时间复杂度
6.C 语言中的十四种内部排序算法

==================================================================================
一:插入排序
A:直接插入排序
1.定义:
插入排序(英语:Insertion Sort)是一种简单直观的排序算法
它的工作原理是通过构建有序序列
对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入
插入排序在实现上,通常采用in-place排序(即只需用到 {\displaystyle O(1)} {\displaystyle O(1)}的额外空间的排序)
因而在从后向前扫描过程中,需要反复把已排序元素逐步向后
挪位,为最新元素提供插入空间
2.算法演示
实例1:
void insertion_sort(int arr[], int len){
int i,j,temp;
for (i=1;i<len;i++){
temp = arr[i];
for (j=i;j>0 && arr[j-1]>temp;j--)
arr[j] = arr[j-1];
arr[j] = temp;
}
}3.基本思想
将一个记录插入到已安排好序的序列中,从而得到一个新的有序序列
将序列的第一个数据看成是一个有序的子序列
然后从第二个记录逐个向该有序的子序列进行有序的插入,直至整个序列有序
4.排序流程图

JAVA实例1:
import java.util.Arrays;
public class Sort {
public static void main(String[] args) {
int arr[] = {2,1,5,3,6,4,9,8,7};
int temp;
for (int i=1;i<arr.length;i++){
//待排元素小于有序序列的最后一个元素时,向前插入
if (arr[i]<arr[i-1]){
temp = arr[i];
for (int j=i;j>=0;j--){
if (j>0 && arr[j-1]>temp) {
arr[j]=arr[j-1];
}else {
arr[j]=temp;
break;
}
}
}
}
System.out.println(Arrays.toString(arr));B:希尔排序
1.定义:
希尔排序,也称递减增量排序算法
是插入排序的一种更高效的改进版本
希尔排序是非稳定排序算法
2.算法演示
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
实例2:
void shell_sort(int arr[], int len) {
int gap, i, j;
int temp;
for (gap = len >> 1; gap > 0; gap = gap >> 1)
for (i = gap; i < len; i++) {
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap)
arr[j + gap] = arr[j];
arr[j + gap] = temp;
}
}C:其他插入排序
直接插入排序算法简便,且容易实现
当待排序记录的数量n很小时,宜采用直接插人排序
当待排序记录的数量n很大时,不宜采用直接插人排序
由此需要讨论改进的办法
在直接插人排序的基础上,从减少“比较"和“移动”
这两种操作的次数着眼,可得下列各种插入排序的方法
a:折半插入排序【二分查找】
1.原理
折半插入算法是对直接插入排序算法的改进,排序原理同直接插入算法
先折半查找元素的应该插入的位置,
后统一移动应该移动的元素
再将这个元素插入到正确的位置
2.区别
在插入到已排序的数据时采用来折半查找(二分查找)
取已经排好序的数组的中间元素,与插入的数据进行比较
如果比插入的数据大,那么插入的数据肯定属于前半部分
否则属于后半部分
依次不断缩小范围,确定要插入的位置
实例3:
int[] arr={5,2,6,0,9}
经行折半插入排序
public class BinaryInsertSort {
public static void main(String[] args){
int arr[] = { 5 , 2 , 6 , 0 , 9 };
//打印排序前的数据
System.out.println("排序前的数据:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
//直接插入排序
binaryInsertSort(arr);
//打印排序后的数据
System.out.println();
System.out.println("排序后的数据:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
private static void binaryInsertSort(int arr[]){
int low,high,m,temp,i,j;
for(i = 1;i<arr.length;i++){
//折半查找应该插入的位置
low = 0;
high = i-1;
while(low <= high){
m = (low+high)/2;
if(arr[m] > arr[i])
high = m - 1;
else
low = m + 1;
}
//统一移动元素,然后将这个元素插入到正确的位置
temp = arr[i];
for(j=i;j>high+1;j--){
arr[j] = arr[j-1];
}
arr[high+1] = temp;
}
}
}
3.图解
4.过程
初始状态:设5为有序,其中i为1,即:5 2 0 6 9
第一趟排序:low为0,high为0,则中间值下标为0((low+high)/2,下文都是如此计算),即5大于2,则插入到5前面,然后i自增。即:2 5 6 0 9
第二趟排序:low为0,high为1,则中间值下标为0,即2小于6,然后low等于中间值得下标加1,继续找中间值为5小于6,则插入到5后面,然后i自增。即:2 5 6 0 9
第三趟排序:low为0,high为2,则中间值下标为1,即5大于0,然后high等于中间值得下标减1,继续找中间值为2大于0,则插入到2前面,然后i自增。即:0 2 5 6 9
第四趟排序:low为0,high为3,则中间值下标为1,即2小于9,然后low等于中间值得下标加上1,继续找中间值为5小于9,然后low等于中间值得下标加上1,继续找中间值为6小于9,则插入到6后面,然后i自增,即:0 2 5 6 9
最终的答案为:0 2 5 6 9
5.时间复杂度
可以看出,折半插入排序减少了比较元素的次数,约为O(nlogn)
比较的次数取决于表的元素个数n
因此,折半插入排序的时间复杂度仍然为O(n²),
但它的效果还是比直接插入排序要好
6.空间复杂度
排序只需要一个位置来暂存元素,因此空间复杂度为O(1)
b:路插入排序
1.定义
是在折半插入排序的基础上对其进行改进
减少其在排序过程中移动记录的次数从而提高效率
2.实现思路
设置一个同存储记录的数组大小相同的数组 d
将无序表中第一个记录添加进 d[0] 的位置上
然后从无序表中第二个记录开始
同 d[0] 作比较:如果该值比 d[0] 大,则添加到其右侧;反之添加到其左侧
在这里的数组 d 可以理解成一个环状数组
3.算法演示

使用 2-路插入排序算法对无序表
{3,1,7,5,2,4,9,6}排序的过程如下:1.将记录 3 添加到数组 d 中:
2.然后将 1 插入到数组 d 中,如下图所示:
3.将记录 7 插入到数组 d 中,如下图所示:
4.将记录 5 插入到数组 d 中,由于其比 7小,但是比 3 大,所以需要移动 7 的位置
然后将 5 插入,如下图所示:
5.将记录 2 插入到数组 d 中,由于比 1大,比 3 小,所以需要移动 3、7、5 的位置
然后将 2 插入,如下图所示:
6.将记录 4 插入到数组 d 中,需要移动 5 和 7 的位置,如下图所示:
7.将记录 9 插入到数组 d 中,如下图所示:
8.将记录 6 插入到数组 d 中,如下图所示:
最终存储在原数组时,从 d[7] 开始依次存储
4.时间复杂度
2-路插入排序相比于折半插入排序
只是减少了移动记录的次数,没有根本上避免
所以其时间复杂度仍为
O()
实例4:2-路插入排序算法的具体实现代码为:
#include <stdio.h>
#include <stdlib.h>
void insert(int arr[], int temp[], int n)
{
int i,first,final,k;
first = final = 0;//分别记录temp数组中最大值和最小值的位置
temp[0] = arr[0];
for (i = 1; i < n; i ++){
// 待插入元素比最小的元素小
if (arr[i] < temp[first]){
first = (first - 1 + n) % n;
temp[first] = arr[i];
}
// 待插入元素比最大元素大
else if (arr[i] > temp[final]){
final = (final + 1 + n) % n;
temp[final] = arr[i];
}
// 插入元素比最小大,比最大小
else {
k = (final + 1 + n) % n;
//当插入值比当前值小时,需要移动当前值的位置
while (temp[((k - 1) + n) % n] > arr[i]) {
temp[(k + n) % n] =temp[(k - 1 + n) % n];
k = (k - 1 + n) % n;
}
//插入该值
temp[(k + n) % n] = arr[i];
//因为最大值的位置改变,所以需要实时更新final的位置
final = (final + 1 + n) % n;
}
}
// 将排序记录复制到原来的顺序表里
for (k = 0; k < n; k ++) {
arr[k] = temp[(first + k) % n];
}
}
int main()
{
int a[8] = {3,1,7,5,2,4,9,6};
int temp[8];
insert(a,temp,8);
for (int i = 0; i < 8; i ++){
printf("%d ", a[i]);
}
return 0;
}
/*结果:
1 2 3 4 5 6 7 9
*/c:表插入排序
1.引入
前面章节中所介绍到的三种插入排序算法,其基本结构都采用数组的形式进行存储
因而无法避免排序过程中产生的数据移动的问题
如果想要从根本上解决只能改变数据的存储结构,改用链表存储
2.定义
即使用链表的存储结构对数据进行插入排序
在对记录按照其关键字进行排序的过程中
不需要移动记录的存储位置
只需要更改结点间指针的指向
3.算法演示

将无序表{49,38,76,13,27}用表插入排序的方式进行排序,其过程为:
1.首先使存储 49 的结点与表头结点构成一个初始的循环链表,完成对链表的初始化,如下表所示:
2.然后将以 38 为关键字的记录插入到循环链表中(只需要更改其链表的 next 指针即可),插入后的链表为:
3.再将以 76 为关键字的结点插入到循环链表中,插入后的链表为:
4.再将以 13 为关键字的结点插入到循环链表中,插入后的链表为:
5.最后将以 27 为关键字的结点插入到循环链表中,插入后的链表为:
6.最终形成的循环链表为:
4.时间复杂度
从表插入排序的实现过程上分析,与直接插入排序相比只是避免了移动记录的过程(修改各记录结点中的指针域即可),而插入过程中同其它关键字的比较次数并没有改变,所以表插入排序算法的时间复杂度仍是O(n2)
5.空间复杂度:表插入排序的空间复杂度是插入排序的两倍
实例5:链表的存储结构用代码表示为:
#define SIZE 100
typedef struct {
int rc;//记录项
int next;//指针项,由于在数组中,所以只需要记录下一个结点所在数组位置的下标即可。
}SLNode;
typedef struct {
SLNode r[SIZE];//存储记录的链表
int length;//记录当前链表长度
}SLinkListType;
在使用数组结构表示的链表中
设定数组下标为 0 的结点作为链表的表头结点
并令其关键字取最大整数
则表插入排序的具体实现过程是:
首先将链表中数组下标为 1 的结点和表头结点构成一个循环链表
然后将后序的所有结点按照其存储的关键字的大小
依次插入到循环链表中
==================================================================================
二:选择排序
A:简单选择排序
1.定义:
选择排序(Selection sort)是一种简单直观的排序算法
它的工作原理首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
然后,再从剩余未排序元素中继续寻找最小(大)元素
然后放到已排序序列的末尾
以此类推,直到所有元素均排序完毕
选择排序是一种不稳定的排序方式
2.算法演示
2.算法演示
实例6:
void swap(int *a,int *b) //交換兩個變數
{
int temp = *a;
*a = *b;
*b = temp;
}
void selection_sort(int arr[], int len)
{
int i,j;
for (i = 0 ; i < len - 1 ; i++)
{
int min = i;
for (j = i + 1; j < len; j++) //走訪未排序的元素
if (arr[j] < arr[min]) //找到目前最小值
min = j; //紀錄最小值
swap(&arr[min], &arr[i]); //做交換
}
}3.算法的实现思想
对于具有 n 个记录的无序表遍历 n-1 次
第 i 次从无序表中第 i 个记录开始
找出后序关键字中最小的记录
然后放置在第 i 的位置上
例如对无序表{56,12,80,91,20}采用简单选择排序算法进行排序,具体过程为:
1 第一次遍历时,从下标为 1 的位置即 56 开始,找出关键字值最小的记录 12,同下标为 0 的关键字 56 交换位置:
2 第二次遍历时,从下标为 2 的位置即 56 开始,找出最小值 20,同下标为 2 的关键字 56 互换位置:
3 第三次遍历时,从下标为 3 的位置即 80 开始,找出最小值 56,同下标为 3 的关键字 80 互换位置:
4 第四次遍历时,从下标为 4 的位置即 91 开始,找出最小是 80,同下标为 4 的关键字 91 互换位置:
到此简单选择排序算法完成,无序表变为有序表
实例7:简单选择排序的实现代码为:
#include <stdio.h>
#include <stdlib.h>
#define MAX 9
//单个记录的结构体
typedef struct {
int key;
}SqNote;
//记录表的结构体
typedef struct {
SqNote r[MAX];
int length;
}SqList;
//交换两个记录的位置
void swap(SqNote *a,SqNote *b){
int key=a->key;
a->key=b->key;
b->key=key;
}
//查找表中关键字的最小值
int SelectMinKey(SqList *L,int i){
int min=i;
//从下标为 i+1 开始,一直遍历至最后一个关键字,找到最小值所在的位置
while (i+1<L->length) {
if (L->r[min].key>L->r[i+1].key) {
min=i+1;
}
i++;
}
return min;
}
//简单选择排序算法实现函数
void SelectSort(SqList * L){
for (int i=0; i<L->length; i++) {
//查找第 i 的位置所要放置的最小值的位置
int j=SelectMinKey(L,i);
//如果 j 和 i 不相等,说明最小值不在下标为 i 的位置,需要交换
if (i!=j) {
swap(&(L->r[i]),&(L->r[j]));
}
}
}
int main() {
SqList * L=(SqList*)malloc(sizeof(SqList));
L->length=8;
L->r[0].key=49;
L->r[1].key=38;
L->r[2].key=65;
L->r[3].key=97;
L->r[4].key=76;
L->r[5].key=13;
L->r[6].key=27;
L->r[7].key=49;
SelectSort(L);
for (int i=0; i<L->length; i++) {
printf("%d ",L->r[i].key);
}
return 0;
}
/*
13 27 38 49 49 65 76 97
*/B:直接选择排序
1.定义
直接选择排序(Straight Select Sorting) 也是一种简单的排序方法
它的基本思想是:第一次从R[0]~R[n-1]中选取最小值
与R[0]交换,第二次从R[1]~R[n-1]中选取最小值,与R[1]交换,....
第i次从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换,.....,第n-1次从R[n-2]~R[n-1]中选取最小值
与R[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列
2.算法演示
例如:给定n=8,数组R中的8个元素的排序码为(8,3,2,1,7,4,6,5),则直接选择排序的过程如下所示
由于百科不方便画出关联箭头 所以用 n -- n 表示 :
初始状态 [ 8 3 2 1 7 4 6 5 ] 8 -- 1
第一次 [ 1 3 2 8 7 4 6 5 ] 3 -- 2
第二次 [ 1 2 3 8 7 4 6 5 ] 3 -- 3
第三次 [ 1 2 3 8 7 4 6 5 ] 8 -- 4
第四次 [ 1 2 3 4 7 8 6 5 ] 7 -- 5
第五次 [ 1 2 3 4 5 8 6 7 ] 8 -- 6
第六次 [ 1 2 3 4 5 6 8 7 ] 8 -- 7
第七次 [ 1 2 3 4 5 6 7 8 ] 排序完成3.排序算法
// elemtype 为所需排序的类型
void SelectSort(elemtype R[], int n) {
int i, j, m;
elemtype t;
for (i = 0; i < n - 1; i++) {
m = i;
for (j = i + 1; j < n; j++)
if (R[j] < R[m]) m = j;
if (m != i) {
t = R[i];
R[i] = R[m];
R[m] = t;
}
}
}4.时间复杂度
在直接选择排序中,共需要进行n-1次选择和交换
每次选择需要进行 n-i 次比较 (1<=i<=n-1)
而每次交换最多需要3次移动,因此,总的比较次数C=(n*n - n)/2
总的移动次数 3(n-1).由此可知
直接选择排序的时间复杂度为 O(n2)
所以当记录占用字节数较多时
通常比直接插入排序的执行速度快些
由于在直接选择排序中存在着不相邻元素之间的互换
因此,直接选择排序是一种不稳定的排序方法
C:树形选择排序【锦标赛排序】
1.定义
树形选择排序又称锦标赛排序(Tournament Sort)
是一种按照锦标赛的思想进行选择排序的方法
首先对n个记录的关键字进行两两比较
然后在n/2个较小者之间再进行两两比较
如此重复,直至选出最小的记录为止
此方法在计算机运算中,是以程序命令体现完成,最后来达到理想的排序目的
2.算法演示
1 首先对n个记录的关键字进行两两比较
然后在其中[n/2](向上取整)个较小者之间再进行两两比较
如此重复,直至选出最小关键字的记录为止
8个叶子结点中依次存放排序之前的8个关键字
每个非终端结点中的关键字均等于其左、右孩子结点中
较小的那个关键字,则根结点中的关键字为叶子结点中的最小关键字
在输出最小关键字之后
根据关系的可传递性
欲选出次小关键字,仅需将叶子结点中的最小关键字
2 改为“最大值”
然后从该叶子结点开始
和其左右兄弟的关键字进行比较
修改从叶子结点到根结点的路径上各结点的关键字
则根结点的关键字即为次小值
同理,可依次选出从小到大的所有关键字
3.时间复杂度
由于含有n个叶子结点的完全二叉树的深度为[log2n]+1
则在树形选择排序中,除了最小关键字以外
每选择一个次小关键字仅需进行[log2n]次比较
因此,它的时间复杂度为O(nlogn)
但是,这种排序方法也有一些缺点,比如辅助存储空间较多,并且需要和“最大值”进行多余的比较。
为了弥补,另一种选择排序被提出——堆排序
实例8:
#region "树形选择排序"
/// <summary>
/// 树形选择排序,Powered By 思念天灵
/// </summary>
/// <param name="mData">待排序的数组</param>
/// <returns>已排好序的数组</returns>
public int[] TreeSelectionSort(int[] mData)
{
int TreeLong = mData.Length * 4;
int MinValue = -10000;
int[] tree = new int[TreeLong]; // 树的大小
int baseSize;
int i;
int n = mData.Length;
int max;
int maxIndex;
int treeSize;
baseSize = 1;
while (baseSize < n)
{
baseSize *= 2;
}
treeSize = baseSize * 2 - 1;
for (i = 0; i < n; i++)
{
tree[treeSize - i] = mData[i];
}
for (; i < baseSize; i++)
{
tree[treeSize - i] = MinValue;
}
// 构造一棵树
for (i = treeSize; i > 1; i -= 2)
{
tree[i / 2] = (tree[i] > tree[i - 1] ? tree[i] : tree[i - 1]);
}
n -= 1;
while (n != -1)
{
max = tree[1];
mData[n--] = max;
maxIndex = treeSize;
while (tree[maxIndex] != max)
{
maxIndex--;
}
tree[maxIndex] = MinValue;
while (maxIndex > 1)
{
if (maxIndex % 2 == 0)
{
tree[maxIndex / 2] = (tree[maxIndex] > tree[maxIndex + 1] ? tree[maxIndex] : tree[maxIndex + 1]);
}
else
{
tree[maxIndex / 2] = (tree[maxIndex] > tree[maxIndex - 1] ? tree[maxIndex] : tree[maxIndex - 1]);
}
maxIndex /= 2;
}
}
return mData;
}
#endregion
D:堆排序
堆 是具有下列性质的完全二叉树:
堆排序(Heapsort)是指利用堆这种数据结构(后面的【图解数据结构】内容会讲解分析)所设计的一种排序算法
堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:
即子结点的键值或索引总是小于(或者大于)它的父节点
堆排序可以说是一种利用堆的概念来排序的选择排序
1.定义
2.每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆
如下图所示:
3.每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
如下图所示:
4.时间复杂度:堆排序的平均时间复杂度为 Ο(nlogn)
5.算法步骤
创建一个堆 H[0……n-1]
把堆首(最大值)和堆尾互换
把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置
重复步骤 2,直到堆的尺寸为 1
6.算法演示
7.排序动画过程解释
1.首先,将所有的数字存储在堆中
2.按大顶堆构建堆,其中大顶堆的一个特性是数据将被从大到小取出,将取出的数字按照相反的顺序进行排列,数字就完成了排序
3.在这里数字 5 先入堆
4.数字 2 入堆
5.数字 7 入堆, 7 此时是最后一个节点,与最后一个非叶子节点(也就是数字 5 )进行比较,由于 7 大于 5 ,所以 7 和 5 交互
6.按照上述的操作将所有数字入堆,然后从左到右,从上到下进行调整,构造出大顶堆
7.入堆完成之后,将堆顶元素取出,将末尾元素置于堆顶,重新调整结构,使其满足堆定义
8.堆顶元素数字 7 取出,末尾元素数字 4 置于堆顶,为了维护好大顶堆的定义,最后一个非叶子节点数字 5 与 4 比较,而后交换两个数字的位置
9.反复执行调整+交换步骤,直到整个序列有序
==================================================================================
三:交换排序
A:冒泡排序
1.定义:
冒泡排序(英语:Bubble Sort)是一种简单的排序算法
它重复地走访过要排序的数列,一次比较两个元素
如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来
冒泡排序是一种稳定的排序方式
2.算法演示
实例9:
#include <stdio.h>
void bubble_sort(int arr[], int len) {
int i, j, temp;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
int main() {
int arr[] = { 22, 34, 3, 32, 82, 55, 89, 50, 37, 5, 64, 35, 9, 70 };
int len = (int) sizeof(arr) / sizeof(*arr);
bubble_sort(arr, len);
int i;
for (i = 0; i < len; i++)
printf("%d ", arr[i]);
return 0;
}B:快速排序
1.定义:
在区间中随机挑选一个元素作基准
将小于基准的元素放在基准之前
大于基准的元素放在基准之后
再分别对小数区与大数区进行排序
2.算法演示
实例10:迭代法
typedef struct _Range {
int start, end;
} Range;
Range new_Range(int s, int e) {
Range r;
r.start = s;
r.end = e;
return r;
}
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort(int arr[], const int len) {
if (len <= 0)
return; // 避免len等於負值時引發段錯誤(Segment Fault)
// r[]模擬列表,p為數量,r[p++]為push,r[--p]為pop且取得元素
Range r[len];
int p = 0;
r[p++] = new_Range(0, len - 1);
while (p) {
Range range = r[--p];
if (range.start >= range.end)
continue;
int mid = arr[(range.start + range.end) / 2]; // 選取中間點為基準點
int left = range.start, right = range.end;
do
{
while (arr[left] < mid) ++left; // 檢測基準點左側是否符合要求
while (arr[right] > mid) --right; //檢測基準點右側是否符合要求
if (left <= right)
{
swap(&arr[left],&arr[right]);
left++;right--; // 移動指針以繼續
}
} while (left <= right);
if (range.start < right) r[p++] = new_Range(range.start, right);
if (range.end > left) r[p++] = new_Range(left, range.end);
}
}实例11:递归法
void swap(int *x, int *y) {
int t = *x;
*x = *y;
*y = t;
}
void quick_sort_recursive(int arr[], int start, int end) {
if (start >= end)
return;
int mid = arr[end];
int left = start, right = end - 1;
while (left < right) {
while (arr[left] < mid && left < right)
left++;
while (arr[right] >= mid && left < right)
right--;
swap(&arr[left], &arr[right]);
}
if (arr[left] >= arr[end])
swap(&arr[left], &arr[end]);
else
left++;
if (left)
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
void quick_sort(int arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}==================================================================================
四:归并排序
1.定义:
把数据分为两段
从两段中逐个选最小的元素移入新数据段的末尾
可从上到下或从下到上进行
2. 算法演示
实例12:迭代法
int min(int x, int y) {
return x < y ? x : y;
}
void merge_sort(int arr[], int len) {
int* a = arr;
int* b = (int*) malloc(len * sizeof(int));
int seg, start;
for (seg = 1; seg < len; seg += seg) {
for (start = 0; start < len; start += seg + seg) {
int low = start, mid = min(start + seg, len), high = min(start + seg + seg, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
int* temp = a;
a = b;
b = temp;
}
if (a != arr) {
int i;
for (i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
free(b);
}实例13:递归法
void merge_sort_recursive(int arr[], int reg[], int start, int end) {
if (start >= end)
return;
int len = end - start, mid = (len >> 1) + start;
int start1 = start, end1 = mid;
int start2 = mid + 1, end2 = end;
merge_sort_recursive(arr, reg, start1, end1);
merge_sort_recursive(arr, reg, start2, end2);
int k = start;
while (start1 <= end1 && start2 <= end2)
reg[k++] = arr[start1] < arr[start2] ? arr[start1++] : arr[start2++];
while (start1 <= end1)
reg[k++] = arr[start1++];
while (start2 <= end2)
reg[k++] = arr[start2++];
for (k = start; k <= end; k++)
arr[k] = reg[k];
}
void merge_sort(int arr[], const int len) {
int reg[len];
merge_sort_recursive(arr, reg, 0, len - 1);
}==================================================================================
五:基数排序
基数排序是一种非比较型整数排序算法
其原理是将整数按位数切割成不同的数字
然后按每个位数分别比较
由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数
所以基数排序也不是只能使用于整数
基数排序有两种方法:多关键字的排序;链式基数排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值
两种方式:
1、最高位优先:先按照最高位排成若干子序列,再对子序列按照次高位排序
2、最低位优先:不必分子序列,每次排序全体元素都参与,不比较,而是通过分配+收集的方式
A:多关键字的排序
1.定义
很多时候,一个对象可以用多个特征值来刻画它,可以把每个特征值看做一个关键字
比如扑克牌有花色和点数这两个特征
如果所要求的顺序由多个关键字联合决定
我们就可以利用这种特征来使用多关键字排序方法
多关键字地位不是平等的,有优先级大小
如扑克牌排序我们就可以规定花色比点数优先
也就是说无论点数多少
只要花色大的就认为它是大牌,
比如规定黑桃大于红心,红心大于梅花,梅花大于方块
2.排序思路
多关键字排序有两种思路:
MSD(先用高优先级的关键字进行分组)
LSD(先用低优先级的关键字进行分组
3.高优先级排序MSD
下边我们先看高优先级排序方式MSD,
比如有如下扑克牌,我们规定花色优先,花色从小到大关系如下图:方块,梅花,红心,黑桃
第一步:我们先用高优先级的关键字(花色)进行分组,如下图
我们可以想象成四个盒子,把扑克牌按照花色扔进4个盒子中。
全部分进四个盒子之后,在每个组内进行排序(每个盒子内的排序算法随意),每个盒子里边元素排好序之后入下图:
这里每个组内(盒子)的排序也可以继续采用分组的方式,在每个盒子按低优先级分组收集
保证每个组内元素排好序,再把这些排好序的各组的元素收集起来就可以了。如下图
收集好之后,如下图,就是已经排好序的游戏序列。
4.低优先级排序LSD
我们分析一下低优先级,还以扑克牌为例
第一步:我们先用最低优先级的关键字进行分组
第二步:分组分好之后进行收集
第三步:收集好的数据再按花色进行重新分组
第四步:把分组后数据再重新收集,就可以得到一个有序数组。
B:链式基数排序
1.定义
采用多关键字排序中的LSD方法
先对低优先级关键字排序
再按照高点的优先级关键字排序
不过基数排序在排序过程中不需要经过关键字的比较
而是借助“分配”和“收集”两种操作
对单逻辑关键字进行排序的一种内部排序方法
2.排序思路
比如,若关键字是十进制表示的数字,且范围在[0,999]内
则可以把每一个十进制数字看成由三个关键字组成(K0, K1, K2)
其中K0是百位数,K1是十位数,K2是个位数
基RADIX的取值为10; 按LSD进行排序,从最低位关键字起
按关键字的不同值将序列中记录“分配”到RADIX个队列中后再“收集”之
如此重复d次。按这种方法实现的排序称之为基数排序
以链表作存储结构的基数排序叫链式基数排序
3.示意图
比如,若关键字是十进制表示的数字,且范围在[0,999]内
则可以把每一个十进制数字看成由三个关键字组成(K0, K1, K2)
其中K0是百位数,K1是十位数,K2是个位数
基RADIX的取值为10; 按LSD进行排序,从最低位关键字起
按关键字的不同值将序列中记录“分配”到RADIX个队列中后再“收集”之
如此重复d次。按这种方法实现的排序称之为基数排序
以链表作存储结构的基数排序叫链式基数排序
4.算法分析
对n个记录(假设每个记录含d个关键字,每个关键字的取值范围为rd个值)进行链式基数排序的时间复杂度为d*(n+rd),其中每一躺分配的时间复杂度为n,每一躺收集的时间复杂度为rd,整个排序需进行d躺分配和收集。
所需辅助空间为2*rd个队列指针,由于采用链表作存储结构,相对于其他采用顺序存储结构的排序方法而言,还增加了n个指针域的空间。
链式基数排序是稳定的排序。
实例14:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <string.h>
4
5 #define DEBUG
6
7 #define EQ(a, b) ((a) == (b))
8 #define LT(a, b) ((a) < (b))
9 #define LQ(a, b) ((a) <= (b))
10
11 //关键字项数的最大个数
12 #define MAX_NUM_OF_KEY 8
13 //关键字基数,此时是十进制整数的基数就是10
14 #define RADIX 10
15 //静态链表的最大长度
16 #define MAX_SPACE 10000
17
18 //定义结点中的关键字类型为int
19 typedef int KeyType;
20 //定义结点中除关键字外的附件信息为char
21 typedef char InfoType;
22
23 //静态链表的结点类型
24 typedef struct{
25 //关键字
26 KeyType keys[MAX_NUM_OF_KEY];
27 //除关键字外的其他数据项
28 InfoType otheritems;
29 int next;
30 }SLCell;
31
32 //静态链表类型
33 typedef struct{
34 //静态链表的可利用空间,r[0]为头结点
35 SLCell r[MAX_SPACE];
36 //每个记录的关键字个数
37 int keynum;
38 //静态链表的当前长度
39 int recnum;
40 }SLList;
41
42 //指针数组类型
43 typedef int ArrType[RADIX];
44
45 void PrintSList(SLList L)
46 {
47 int i = 0;
48 printf("下标值 ");
49 for(i=0; i<=L.recnum; i++){
50 printf(" %-6d", i);
51 }
52 printf("\n关键字 ");
53 for(i=0; i<=L.recnum; i++){
54 printf(" %-1d%-1d%-1d,%-2c", L.r[i].keys[2], L.r[i].keys[1], L.r[i].keys[0], L.r[i].otheritems);
55 }
56 // printf("\n其他值 ");
57 // for(i=0; i<=L.recnum; i++){
58 // printf(" %-5c", L.r[i].otheritems);
59 // }
60 printf("\n下一项 ");
61 for(i=0; i<=L.recnum; i++){
62 printf(" %-6d", L.r[i].next);
63 }
64 printf("\n");
65 return;
66 }
67
68 void PrintArr(ArrType arr, int size)
69 {
70 int i = 0;
71 for(i=0; i<size; i++){
72 printf("[%d]%-2d ", i, arr[i]);
73 }
74 printf("\n");
75 }
76
77 /*
78 *静态链表L的r域中记录已按(key[0],...,key[i-1])有序
79 *本算法按第i个关键字keys[i]建立RADIX个子表,使同一子表中记录的keys[i]相同。
80 *f[0,...,RADIX-1]和e[0,...,RADIX-1]分别指向各子表中的第一个记录和最后一个记录。
81 */
82 void Distribute(SLCell *r, int i, ArrType f, ArrType e)
83 {
84 int j = 0;
85 //各子表初始化为空
86 for(j=0; j<RADIX; j++)
87 f[j] = e[j] = 0;
88
89 int p = 0;
90 for(p=r[0].next; p; p=r[p].next){
91 j = r[p].keys[i];
92 if(!f[j])
93 f[j] = p;
94 else
95 r[e[j]].next = p;
96 //将p所指的结点插入第j个字表中
97 e[j] = p;
98 }
99 }
100
101 /*
102 * 本算法按keys[i]自小到大地将f[0,...,RADIX-1]所指各子表依次链接成一个链表
103 * e[0,...,RADIX-1]为各子表的尾指针
104 */
105 void Collect(SLCell *r, int i, ArrType f, ArrType e){
106 int j = 0, t = 0;
107 //找到第一个非空子表,
108 for(j=0; !f[j]; j++);
109 //r[0].next指向第一个非空子表的第一个结点
110 r[0].next = f[j];
111 //t指向第一个非空子表的最后结点
112 t = e[j];
113 while(j<RADIX){
114 //找下一个非空子表
115 for(j+=1; !f[j]; j++);
116 //链接两个非空子表
117 if(j<RADIX && f[j]){
118 r[t].next = f[j];
119 t = e[j];
120 }
121 }
122 //t指向最后一个非空子表中的最后一个结点
123 r[t].next = 0;
124 }
125
126 /*
127 * L是采用静态链表表示的顺序表。
128 * 对L作基数排序,使得L成为按关键字自小到大的有效静态链表,L->r[0]为头结点
129 */
130 void RadixSort(SLList *L)
131 {
132 int i = 0;
133 //将L改造成静态链表
134 for(i=0; i<L->recnum; i++)
135 L->r[i].next = i+1;
136 L->r[L->recnum].next = 0;
137 #ifdef DEBUG
138 printf("将L改造成静态链表\n");
139 PrintSList(*L);
140 #endif
141
142 ArrType f, e;
143 //按最低位优先依次对各关键字进行分配和收集
144 for(i=0; i<L->keynum; i++){
145 //第i趟分配
146 Distribute(L->r, i, f, e);
147 #ifdef DEBUG
148 printf("第%d趟分配---------------------------------------\n");
149 PrintSList(*L);
150 printf("头指针队列:");
151 PrintArr(f, RADIX);
152 printf("尾指针队列:");
153 PrintArr(e, RADIX);
154 #endif
155 //第i躺收集
156 Collect(L->r, i, f, e);
157 #ifdef DEBUG
158 printf("第%d趟收集----\n");
159 PrintSList(*L);
160 printf("按next打印:");
161 int p = 0;
162 for(p=L->r[0].next; p; p=L->r[p].next){
163 printf("%d%d%d ", L->r[p].keys[2], L->r[p].keys[1], L->r[p].keys[0]);
164 }
165 printf("\n");
166 #endif
167 }
168 }
169
170 int getRedFromStr(char str[], int i, SLCell *result)
171 {
172 int key = atoi(str);
173 if(key<0 || key >999){
174 printf("Error:too big!\n");
175 return -1;
176 }
177 int units = 0, tens = 0, huns = 0;
178 //百位
179 huns = key/100;
180 //十位
181 tens = (key-100*huns)/10;
182 //个位
183 units = (key-100*huns-10*tens)/1;
184 result->keys[0] = units;
185 result->keys[1] = tens;
186 result->keys[2] = huns;
187 result->otheritems = 'a'+i-1;
188 return 0;
189 }
190
191
192 int main(int argc, char *argv[])
193 {
194 SLList L;
195 int i = 0;
196 for(i=1; i<argc; i++){
197 if(i>MAX_SPACE)
198 break;
199 if(getRedFromStr(argv[i], i, &L.r[i]) < 0){
200 printf("Error:only 0-999!\n");
201 return -1;
202 }
203 }
204 L.keynum = 3;
205 L.recnum = i-1;
206 L.r[0].next = 0;
207 L.r[0].otheritems = '0';
208 RadixSort(&L);
209 return 0;
210 }运行结果:
==================================================================================
六:补充两种排序
A:计数排序
1.定义
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中
作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数
2.特征
当输入的元素是 n 个 0 到 k 之间的整数时它的运行时间是 Θ(n + k)
计数排序不是比较排序,排序的速度快于任何比较排序算法
由于用来计数的数组C的长度取决于待排序数组中数据的范围
(等于待排序数组的最大值与最小值的差加上1)
这使得计数排序对于数据范围很大的数组,需要大量时间和内存
例如:计数排序是用来排序0到100之间的数字的最好的算法
但是它不适合按字母顺序排序人名
但是,计数排序可以用在基数排序中的算法来排序数据范围很大的数组
通俗地理解,例如有 10 个年龄不同的人,统计出有 8 个人的年龄比 A 小
那 A 的年龄就排在第 9 位,用这个方法可以得到其他每个人的位置,也就排好了序
当然,年龄有重复时需要特殊处理(保证稳定性)
这就是为什么最后要反向填充目标数组,以及将每个数字的统计减去 1 的原因
3.算法的步骤
- (1)找出待排序的数组中最大和最小的元素
- (2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- (3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- (4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
4. 动图演示
实例15:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void print_arr(int *arr, int n) {
int i;
printf("%d", arr[0]);
for (i = 1; i < n; i++)
printf(" %d", arr[i]);
printf("\n");
}
void counting_sort(int *ini_arr, int *sorted_arr, int n) {
int *count_arr = (int *) malloc(sizeof(int) * 100);
int i, j, k;
for (k = 0; k < 100; k++)
count_arr[k] = 0;
for (i = 0; i < n; i++)
count_arr[ini_arr[i]]++;
for (k = 1; k < 100; k++)
count_arr[k] += count_arr[k - 1];
for (j = n; j > 0; j--)
sorted_arr[--count_arr[ini_arr[j - 1]]] = ini_arr[j - 1];
free(count_arr);
}
int main(int argc, char **argv) {
int n = 10;
int i;
int *arr = (int *) malloc(sizeof(int) * n);
int *sorted_arr = (int *) malloc(sizeof(int) * n);
srand(time(0));
for (i = 0; i < n; i++)
arr[i] = rand() % 100;
printf("ini_array: ");
print_arr(arr, n);
counting_sort(arr, sorted_arr, n);
printf("sorted_array: ");
print_arr(sorted_arr, n);
free(arr);
free(sorted_arr);
return 0;
}B:桶排序
1.定义
桶排序是计数排序的升级版
它利用了函数的映射关系
高效与否的关键就在于这个映射函数的确定
为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要
2.什么时候最快:当输入的数据可以均匀的分配到每一个桶中
3.什么时候最慢:当输入的数据被分配到了同一个桶中
4.示意图
元素分布在桶中:
然后,元素在每个桶中排序:
实例16:
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}==================================================================================
七:总结
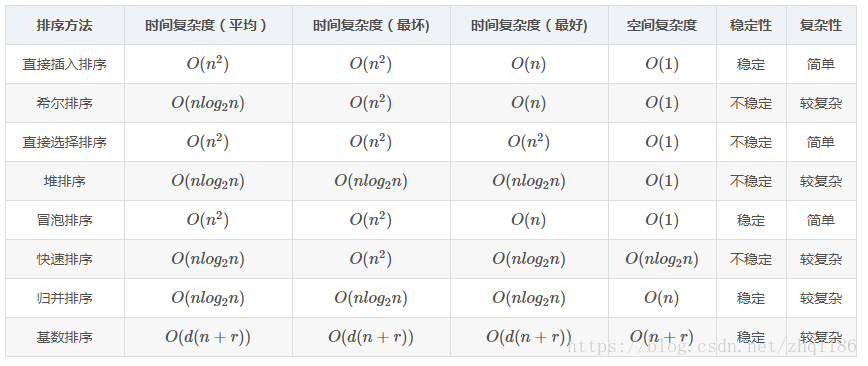
从算法的简单性来看,可以将 7 种算法分为两类:
简单算法:冒泡,简单选择,直接插入
改进算法:希尔,堆,归并,快速
显然后面 3 种改进算法要胜过希尔排序,并远远胜过前 3 种简单算法
反而冒泡和直接插入排序更好
也就是说,如果你的待排序序列总是 基本有序
反而不应该考虑 4 种复杂的改进算法
堆排序和归并排序又强过快速排序以及其他简单排序
归并排序强调要马跑得快,就得给马吃饱
快速排序也有相应的空间要求
反而堆排序等却都是少量索取,大量付出,对空间要求是
如果执行算法的软件非常在乎 内存使用量 时,选择归并排序和快速排序就不是一个较好的决策了
综合各项指标,经过优化的快速排序是性能最好的排序算法
但是不同的场合我们也应该考虑使用不同的算法来应对
(1)平方阶(O(n2))排序
一般称为简单排序,例如直接插入、直接选择和冒泡排序;
(2)线性对数阶(O(nlgn))排序
如快速、堆和归并排序;
(3)O(n1+£)阶排序
£是介于0和1之间的常数,即0<£<1,如希尔排序;
(4)线性阶(O(n))排序
如桶、箱和基数排序。
简单排序中直接插入最好,快速排序最快,当文件为正序时,直接插入和冒泡均最佳。
因为不同的排序方法适应不同的应用环境和要求,所以选择合适的排序方法应综合考虑下列因素:
①待排序的记录数目n;
②记录的大小(规模);
③关键字的结构及其初始状态;
④对稳定性的要求;
⑤语言工具的条件;
⑥存储结构;
⑦时间和辅助空间复杂度等。
(1)若n较小(如n≤50),可采用直接插入或直接选择排序。
当记录规模较小时,直接插入排序较好;否则因为直接选择移动的记录数少于直接插人,应选直接选择排序为宜。
(2)若文件初始状态基本有序(指正序),则应选用直接插人、冒泡或随机的快速排序为宜;
(3)若n较大,则应采用时间复杂度为O(nlgn)的排序方法:快速排序、堆排序或归并排序。
快速排序是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况。这两种排序都是不稳定的。若要求排序稳定,则可选用归并排序。但本章介绍的从单个记录起进行两两归并的 排序算法并不值得提倡,通常可以将它和直接插入排序结合在一起使用。先利用直接插入排序求得较长的有序子文件,然后再两两归并之。因为直接插入排序是稳定的,所以改进后的归并排序仍是稳定的。
(4)在基于比较的排序方法中,每次比较两个关键字的大小之后,仅仅出现两种可能的转移,因此可以用一棵二叉树来描述比较判定过程。
当文件的n个关键字随机分布时,任何借助于"比较"的排序算法,至少需要O(nlgn)的时间。
箱排序和基数排序只需一步就会引起m种可能的转移,即把一个记录装入m个箱子之一,因此在一般情况下,箱排序和基数排序可能在O(n)时间内完成对n个记录的排序。但是,箱排序和基数排序只适用于像字符串和整数这类有明显结构特征的关键字,而当关键字的取值范围属于某个无穷集合(例如实数型关键字)时,无法使用箱排序和基数排序,这时只有借助于"比较"的方法来排序。
若n很大,记录的关键字位数较少且可以分解时,采用基数排序较好。虽然桶排序对关键字的结构无要求,但它也只有在关键字是随机分布时才能使平均时间达到线性阶,否则为平方阶。同时要注意,箱、桶、基数这三种分配排序均假定了关键字若为数字时,则其值均是非负的,否则将其映射到箱(桶)号时,又要增加相应的时间。
(5)有的语言(如Fortran,Cobol或Basic等)没有提供指针及递归,导致实现归并、快速(它们用递归实现较简单)和基数(使用了指针)等排序算法变得复杂。此时可考虑用其它排序。
(6)本章给出的排序算法,输人数据均是存储在一个向量中。当记录的规模较大时,为避免耗费大量的时间去移动记录,可以用链表作为存储结构。譬如插入排序、归并排序、基数排序都易于在链表上实现,使之减少记录的移动次数。但有的排序方法,如快速排序和堆排序,在链表上却难于实现,在这种情况下,可以提取关键字建立索引表,然后对索引表进行排序。然而更为简单的方法是:引人一个整型向量t作为辅助表,排序前令t[i]=i(0≤i<n),若排序算法中要求交换R[i]和R[j],则只需交换t[i]和t[j]即可;排序结束后,向量t就指示了记录之间的顺序关系:
R[t[0]].key≤R[t[1]].key≤…≤R[t[n-1]].key
若要求最终结果是:
R[0].key≤R[1].key≤…≤R[n-1].key
则可以在排序结束后,再按辅助表所规定的次序重排各记录,完成这种重排的时间是O(n)。
第十二章:外部排序
1.外部排序定义
外部排序指的是大文件的排序
即待排序的记录存储在外存储器上
待排序的文件无法一次装入内存,需要在内存和外部存储器之间进行多次数据交换,以达到排序整个文件的目的
外部排序最常用的算法是多路归并排序
即将原文件分解成多个能够一次性装入内存的部分
分别把每一部分调入内存完成排序
然后,对已经排序的子文件进行多路归并排序
2.外部排序的基本思路
1)按可用内存的大小
把外存上含有n个记录的文件分成若干个长度为L的子文件
把这些子文件依次读入内存,并利用有效的内部排序方法对它们进行排序
再将排序后得到的有序子文件重新写入外存
2)对这些有序子文件逐趟归并
使其逐渐由小到大,直至得到整个有序文件为止
举例:
假设有一个72KB的文件,其中存储了18K个整数,磁盘中物理块的大小为4KB,将文件分成18组,每组刚好4KB
首先通过18次内部排序,把18组数据排好序,得到初始的18个归并段R1~R18,每个归并段有1024个整数。
然后对这18个归并段使用4路平衡归并排序:
第1次归并:产生5个归并段
R11 R12 R13 R14 R15
其中
R11是由{R1,R2,R3,R4}中的数据合并而来
R12是由{R5,R6,R7,R8}中的数据合并而来
R13是由{R9,R10,R11,R12}中的数据合并而来
R14是由{R13,R14,R15,R16}中的数据合并而来
R15是由{R17,R18}中的数据合并而来
把这5个归并段的数据写入5个文件:
foo_1.dat foo_2.dat foo_3.dat foo_4.dat foo_5.dat
第2次归并:从第1次归并产生的5个文件中读取数据,合并,产生2个归并段
R21 R22
其中R21是由{R11,R12,R13,R14}中的数据合并而来
其中R22是由{R15}中的数据合并而来
把这2个归并段写入2个文件
bar_1.dat bar_2.dat
第3次归并:从第2次归并产生的2个文件中读取数据,合并,产生1个归并段
R31
R31是由{R21,R22}中的数据合并而来
把这个文件写入1个文件
foo_1.dat
此即为最终排序好的文件。
3.外部排序算法
(1)定义
外部排序算法,即要借助外部存储器对数据进行排序的算法,包括置换平衡归并排序算法、置换选择排序算法等
外部排序算法的实现,其实就是将体积大的数据分割为内存容得下的多份数据
然后分别使用内部排序算法进行排序,最后进行整合
和内部排序算法不同,外部排序算法的主要影响因素在于读写内存的次数
而当待排序的文件比内存的可使用容量还大时
文件无法一次性放到内存中进行排序
需要借助于外部存储器(例如硬盘、U盘、光盘)
(2)外部排序算法由两个阶段构成
1)按照内存大小,将大文件分成若干长度为 l 的子文件(l 应小于内存的可使用容量)
然后将各个子文件依次读入内存,使用适当的内部排序算法对其进行排序
(排好序的子文件统称为“归并段”或者“顺段”)
将排好序的归并段重新写入外存,为下一个子文件排序腾出内存空间;
(2)对得到的顺段进行合并,直至得到整个有序的文件为止。
(3)2-路平衡归并
举例:
有一个含有 10000 个记录的文件,但是内存的可使用容量仅为 1000 个记录,毫无疑问需要使用外部排序算法,具体分为两步:
- 将整个文件其等分为 10 个临时文件(每个文件中含有 1000 个记录),然后将这 10 个文件依次进入内存,采取适当的内存排序算法对其中的记录进行排序,将得到的有序文件(初始归并段)移至外存。
- 对得到的 10 个初始归并段进行如图 1 的两两归并,直至得到一个完整的有序文件
如图 1所示有 10 个初始归并段到一个有序文件- 共进行了 4 次归并,每次都由 m 个归并段得到 ⌈m/2⌉ 个归并段
- 这种归并方式被称为 2-路平衡归并
注意:此例中采用了将文件进行等分的操作,还有不等分的算法
注意:在实际归并的过程中,由于内存容量的限制不能满足同时将 2 个归并段全部完整的读入内存进行归并
只能不断地取 2 个归并段中的每一小部分进行归并
通过不断地读数据和向外存写数据,直至 2 个归并段完成归并变为 1 个大的有序文件。
对于外部排序算法来说
影响整体排序效率的因素主要取决于读写外存的次数
即访问外存的次数越多,算法花费的时间就越多,效率就越低
计算机中处理数据的为中央处理器(CPU)
如若需要访问外存中的数据
只能通过将数据从外存导入内存,然后从内存中获取
同时由于内存读写速度快,外存读写速度慢的差异,更加影响了外部排序的效率
(4)5-路归并
对于同一个文件来说,对其进行外部排序时访问外存的次数同归并的次数成正比
即归并操作的次数越多,访问外存的次数就越多
图 1 中使用的是 2-路平衡归并的方式,举一反三
还可以使用 3-路归并、4-路归并甚至是 10-路归并的方式,图 2 为 5-路归并的方式:
对比 图 1 和图 2可以看出
对于 k-路平衡归并中 k 值得选择,增加 k 可以减少归并的次数
从而减少外存读写的次数,最终达到提高算法效率的目的
除此之外,一般情况下对于具有 m 个初始归并段进行 k-路平衡归并时
归并的次数为:s=⌊logkm ⌋(其中 s 表示归并次数)
从公式上可以判断出,想要达到减少归并次数从而提高算法效率的目的,可以从两个角度实现:
- 增加 k-路平衡归并中的k 值;
- 尽量减少初始归并段的数量 m,即增加每个归并段的容量;
其增加 k 值的想法引申出了一种外部排序算法:多路平衡归并算法
增加数量 m 的想法引申出了另一种外部排序算法:置换-选择排序算法
4.多路平衡归并排序(胜者树、败者树)算法
(1)引入
但是经过计算得知,如果毫无限度地增加 k 值
虽然会减少读写外存数据的次数
但会增加内部归并的时间,得不偿失
为了避免在增加 k 值的过程中影响内部归并的效率
在进行 k-路归并时可以使用“败者树”来实现
该方法在增加 k 值时不会影响其内部归并的效率
(2)败者树实现内部归并
败者树是树形选择排序的一种变形,本身是一棵完全二叉树
(3)胜者树
在树形选择排序一节中
对于无序表
{49,38,65,97,76,13,27,49}创建的完全二叉树如图 1 所示构建此树的目的是选出无序表中的最小值
这棵树与败者树正好相反,是一棵“胜者树”

因为树中每个非终端结点(除叶子结点之外的其它结点)中的值都
表示的是左右孩子相比较后的较小值(谁最小即为胜者)
例如叶子结点 49 和 38 相对比,由于 38 更小
所以其双亲结点中的值保留的是胜者 38
然后用 38 去继续同上层去比较,一直比较到树的根结点
(4)败者树
而败者树恰好相反,其双亲结点存储的是左右孩子比较之后的失败者,而胜利者则继续同其它的胜者去比较
胜者树和败者树的区别就是:
胜者树中的非终端结点中存储的是胜利的一方
败者树中的非终端结点存储的是失败的一方
而在比较过程中,都是拿胜者去比较

如图 2 所示为一棵 5-路归并的败者树
其中 b0—b4 为树的叶子结点
分别为 5 个归并段中存储的记录的关键字
ls 为一维数组,表示的是非终端结点,其中存储的数值表示第几归并段(例如 b0 为第 0 个归并段)
ls[0] 中存储的为最终的胜者,表示当前第 3 归并段中的关键字最小
当最终胜者判断完成后
只需要更新叶子结点 b3 的值,即导入关键字 15
然后让该结点不断同其双亲结点所表示的关键字进行比较
败者留在双亲结点中,胜者继续向上比较
注意:为了防止在归并过程中某个归并段变为空
处理的办法为:
可以在每个归并段最后附加一个关键字为最大值的记录
这样当某一时刻选出的冠军为最大值时
表明 5 个归并段已全部归并完成
(因为只要还有记录,最终的胜者就不可能是附加的最大值)
(5)败者树内部归并的具体实现
#include <stdio.h>
#define k 5
#define MAXKEY 10000
#define MINKEY -1
typedef int LoserTree[k];//表示非终端结点,由于是完全二叉树,所以可以使用一维数组来表示
typedef struct {
int key;
}ExNode,External[k+1];
External b;//表示败者树的叶子结点
//a0-a4为5个初始归并段
int a0[]={10,15,16};
int a1[]={9,18,20};
int a2[]={20,22,40};
int a3[]={6,15,25};
int a4[]={12,37,48};
//t0-t4用于模拟从初始归并段中读入记录时使用
int t0=0,t1=0,t2=0,t3=0,t4=0;
//沿从叶子结点b[s]到根结点ls[0]的路径调整败者树
void Adjust(LoserTree ls,int s){
int t=(s+k)/2;
while (t>0) {
//判断每一个叶子结点同其双亲结点中记录的败者的值相比较,调整败者的值,其中 s 一直表示的都是胜者
if (b[s].key>b[ls[t]].key) {
int swap=s;
s=ls[t];
ls[t]=swap;
}
t=t/2;
}
//最终将胜者的值赋给 ls[0]
ls[0]=s;
}
//创建败者树
void CreateLoserTree(LoserTree ls){
b[k].key=MINKEY;
//设置ls数组中败者的初始值
for (int i=0; i<k; i++) {
ls[i]=k;
}
//对于每一个叶子结点,调整败者树中非终端结点中记录败者的值
for (int i=k-1; i>=0; i--) {
Adjust(ls, i);
}
}
//模拟从外存向内存读入初始归并段中的每一小部分
void input(int i){
switch (i) {
case 0:
if (t0<3) {
b[i].key=a0[t0];
t0++;
}else{
b[i].key=MAXKEY;
}
break;
case 1:
if (t1<3) {
b[i].key=a1[t1];
t1++;
}else{
b[i].key=MAXKEY;
}
break;
case 2:
if (t2<3) {
b[i].key=a2[t2];
t2++;
}else{
b[i].key=MAXKEY;
}
break;
case 3:
if (t3<3) {
b[i].key=a3[t3];
t3++;
}else{
b[i].key=MAXKEY;
}
break;
case 4:
if (t4<3) {
b[i].key=a4[t4];
t4++;
}else{
b[i].key=MAXKEY;
}
break;
default:
break;
}
}
//败者树的建立及内部归并
void K_Merge(LoserTree ls){
//模拟从外存中的5个初始归并段中向内存调取数据
for (int i=0; i<=k; i++) {
input(i);
}
//创建败者树
CreateLoserTree(ls);
//最终的胜者存储在 is[0]中,当其值为 MAXKEY时,证明5个临时文件归并结束
while (b[ls[0]].key!=MAXKEY) {
//输出过程模拟向外存写的操作
printf("%d ",b[ls[0]].key);
//继续读入后续的记录
input(ls[0]);
//根据新读入的记录的关键字的值,重新调整败者树,找出最终的胜者
Adjust(ls,ls[0]);
}
}
int main(int argc, const char * argv[]) {
LoserTree ls;
K_Merge(ls);
return 0;
}
/*
6 9 10 12 15 15 16 18 20 20 22 25 37 40 48
*/5.置换-选择排序算法
(1)引入
上一节介绍了增加 k-路归并排序中的 k 值来提高外部排序效率的方法
而除此之外,还有另外一条路可走
即减少初始归并段的个数,也就是本章第一节中提到的减小 m 的值
m 的求值方法为:m=⌈n/l⌉(n 表示为外部文件中的记录数,l 表示初始归并段中包含的记录数)如果要想减小 m 的值,在外部文件总的记录数 n 值一定的情况下,只能增加每个归并段中所包含的记录数 l
而对于初始归并段的形成,就不能再采用上一章所介绍的内部排序的算法
因为所有的内部排序算法正常运行的前提是所有的记录都存在于内存中
而内存的可使用空间是一定的,如果增加 l 的值,内存是盛不下的
(2)图解
例如已知初始文件中总共有 24 个记录,假设内存工作区最多可容纳 6 个记录
按照之前的选择排序算法最少也只能分为4 个初始归并段
而如果使用置换—选择排序
可以实现将 24 个记录分为 3 个初始归并段,如图 1 所示:

(3)操作过程
置换—选择排序算法的具体操作过程为:
- 首先从初始文件中输入 6 个记录到内存工作区中;
- 从内存工作区中选出关键字最小的记录,将其记为 MINIMAX 记录;
- 然后将 MINIMAX 记录输出到归并段文件中;
- 此时内存工作区中还剩余 5 个记录,若初始文件不为空,则从初始文件中输入下一个记录到内存工作区中;
- 从内存工作区中的所有比 MINIMAX 值大的记录中选出值最小的关键字的记录,作为新的 MINIMAX 记录;
- 重复过程 3—5,直至在内存工作区中选不出新的 MINIMAX 记录为止,由此就得到了一个初始归并段;
- 重复 2—6,直至内存工作为空,由此就可以得到全部的初始归并段。
拿图 1 中的初始文件为例,首先输入前 6 个记录到内存工作区,其中关键字最小的为 29,所以选其为 MINIMAX 记录,同时将其输出到归并段文件中,如下图所示:
此时初始文件不为空,所以从中输入下一个记录 14 到内存工作区中,然后从内存工作区中的比 29 大的记录中,选择一个最小值作为新的 MINIMAX 值输出到 归并段文件中,如下图所示:
初始文件还不为空,所以继续输入 61 到内存工作区中,从内存工作区中的所有关键字比 38 大的记录中,选择一个最小值作为新的 MINIMAX 值输出到归并段文件中,如下图所示:
如此重复性进行,直至选不出 MINIMAX 值为止,如下图所示:
当选不出 MINIMAX 值时,表示一个归并段已经生成
则开始下一个归并段的创建,创建过程同第一个归并段一样
在上述创建初始段文件的过程中,需要不断地在内存工作区中选择新的 MINIMAX 记录
即选择不小于旧的 MINIMAX 记录的最小值
此过程需要利用“败者树”来实现
同上一节所用到的败者树不同的是,在不断选择新的 MINIMAX 记录时为了防止新加入的关键字值小的的影响
每个叶子结点附加一个序号位
当进行关键字的比较时,先比较序号,序号小的为胜者
序号相同的关键字值小的为胜者
(4)置换选择排序算法的具体实现
#include <stdio.h>
#define MAXKEY 10000
#define RUNEND_SYMBOL 10000 // 归并段结束标志
#define w 6 // 内存工作区可容纳的记录个数
#define N 24 // 设文件中含有的记录的数量
typedef int KeyType; // 定义关键字类型为整型
// 记录类型
typedef struct{
KeyType key; // 关键字项
}RedType;
typedef int LoserTree[w];// 败者树是完全二叉树且不含叶子,可采用顺序存储结构
typedef struct
{
RedType rec; /* 记录 */
KeyType key; /* 从记录中抽取的关键字 */
int rnum; /* 所属归并段的段号 */
}RedNode, WorkArea[w];
// 从wa[q]起到败者树的根比较选择MINIMAX记录,并由q指示它所在的归并段
void Select_MiniMax(LoserTree ls,WorkArea wa,int q){
int p, s, t;
// ls[t]为q的双亲节点,p作为中介
for(t = (w+q)/2,p = ls[t]; t > 0;t = t/2,p = ls[t]){
// 段号小者 或者 段号相等且关键字更小的为胜者
if(wa[p].rnum < wa[q].rnum || (wa[p].rnum == wa[q].rnum && wa[p].key < wa[q].key)){
s=q;
q=ls[t]; //q指示新的胜利者
ls[t]=s;
}
}
ls[0] = q; // 最后的冠军
}
//输入w个记录到内存工作区wa,建得败者树ls,选出关键字最小的记录,并由s指示其在wa中的位置。
void Construct_Loser(LoserTree ls, WorkArea wa, FILE *fi){
int i;
for(i = 0; i < w; ++i){
wa[i].rnum = wa[i].key = ls[i] = 0;
}
for(i = w - 1; i >= 0; --i){
fread(&wa[i].rec, sizeof(RedType), 1, fi);// 输入一个记录
wa[i].key = wa[i].rec.key; // 提取关键字
wa[i].rnum = 1; // 其段号为"1"
Select_MiniMax(ls,wa,i); // 调整败者树
}
}
// 求得一个初始归并段,fi为输入文件指针,fo为输出文件指针。
void get_run(LoserTree ls,WorkArea wa,int rc,int *rmax,FILE *fi,FILE *fo){
int q;
KeyType minimax;
// 选得的MINIMAX记录属当前段时
while(wa[ls[0]].rnum == rc){
q = ls[0];// q指示MINIMAX记录在wa中的位置
minimax = wa[q].key;
// 将刚选得的MINIMAX记录写入输出文件
fwrite(&wa[q].rec, sizeof(RedType), 1, fo);
// 如果输入文件结束,则虚设一条记录(属"rmax+1"段)
if(feof(fi)){
wa[q].rnum = *rmax+1;
wa[q].key = MAXKEY;
}else{ // 输入文件非空时
// 从输入文件读入下一记录
fread(&wa[q].rec,sizeof(RedType),1,fi);
wa[q].key = wa[q].rec.key;// 提取关键字
if(wa[q].key < minimax){
// 新读入的记录比上一轮的最小关键字还小,则它属下一段
*rmax = rc+1;
wa[q].rnum = *rmax;
}else{
// 新读入的记录大则属当前段
wa[q].rnum = rc;
}
}
// 选择新的MINIMAX记录
Select_MiniMax(ls, wa, q);
}
}
//在败者树ls和内存工作区wa上用置换-选择排序求初始归并段
void Replace_Selection(LoserTree ls, WorkArea wa, FILE *fi, FILE *fo){
int rc, rmax;
RedType j;
j.key = RUNEND_SYMBOL;
// 初建败者树
Construct_Loser(ls, wa, fi);
rc = rmax =1;//rc指示当前生成的初始归并段的段号,rmax指示wa中关键字所属初始归并段的最大段号
while(rc <= rmax){// "rc=rmax+1"标志输入文件的置换-选择排序已完成
// 求得一个初始归并段
get_run(ls, wa, rc, &rmax, fi, fo);
fwrite(&j,sizeof(RedType),1,fo);//将段结束标志写入输出文件
rc = wa[ls[0]].rnum;//设置下一段的段号
}
}
void print(RedType t){
printf("%d ",t.key);
}
int main(){
RedType a[N]={51,49,39,46,38,29,14,61,15,30,1,48,52,3,63,27,4,13,89,24,46,58,33,76};
RedType b;
FILE *fi,*fo; //输入输出文件
LoserTree ls; // 败者树
WorkArea wa; // 内存工作区
int i, k;
fo = fopen("ori","wb"); //准备对 ori 文本文件进行写操作
//将数组 a 写入大文件ori
fwrite(a, sizeof(RedType), N, fo);
fclose(fo); //关闭指针 fo 表示的文件
fi = fopen("ori","rb");//准备对 ori 文本文件进行读操作
printf("文件中的待排序记录为:\n");
for(i = 1; i <= N; i++){
// 依次将文件ori的数据读入并赋值给b
fread(&b,sizeof(RedType),1,fi);
print(b);
}
printf("\n");
rewind(fi);// 使fi的指针重新返回大文件ori的起始位置,以便重新读入内存,产生有序的子文件。
fo = fopen("out","wb");
// 用置换-选择排序求初始归并段
Replace_Selection(ls, wa, fi, fo);
fclose(fo);
fclose(fi);
fi = fopen("out","rb");
printf("初始归并段各为:\n");
do{
k = fread(&b, sizeof(RedType), 1, fi); //读 fi 指针指向的文件,并将读的记录赋值给 b,整个操作成功与否的结果赋值给 k
if(k == 1){
if(b.key ==MAXKEY){//当其值等于最大值时,表明当前初始归并段已经完成
printf("\n\n");
continue;
}
print(b);
}
}while(k == 1);
return 0;
}
/*
文件中的待排序记录为:
51 49 39 46 38 29 14 61 15 30 1 48 52 3 63 27 4 13 89 24 46 58 33 76
初始归并段各为:
29 38 39 46 49 51 61
1 3 14 15 27 30 48 52 63 89
4 13 13 24 33 46 58 76
*/6.最佳归并树
(1)思考
本节带领大家思考一个问题:
无论是通过等分还是置换-选择排序得到的归并段
如何设置它们的归并顺序
可以使得对外存的访问次数降到最低?
(2)举例参考
例如,现有通过置换选择排序算法所得到的 9 个初始归并段
其长度分别为:
9,30,12,18,3,17,2,6,24在对其采用 3-路平衡归并的方式时可能出现如图 1 所示的情况:

提示:图 1 中的叶子结点表示初始归并段,各自包含记录的长度用结点的权重来表示;非终端结点表示归并后的临时文件
假设在进行平衡归并时,操作每个记录都需要单独进行一次对外存的读写
那么图 1 中的归并过程需要对外存进行读或者写的次数为:
(9+30+12+18+3+17+2+6+24)*2*2=484(图 1 中涉及到了两次归并,对外存的读和写各进行 2 次)从计算结果上看,对于图 1 中的 3 叉树来讲,其操作外存的次数恰好是树的带权路径长度的 2 倍
对于如何减少访问外存的次数的问题,就等同于考虑如何使 k-路归并所构成的 k 叉树的带权路径长度最短
若想使树的带权路径长度最短,就是构造赫夫曼树【只要其带权路径长度最短,亦可以称为赫夫曼树】
若对上述 9 个初始归并段构造一棵赫夫曼树作为归并树,如图 2 所示:
依照图 2 所示,其对外存的读写次数为:
(2*3+3*3+6*3+9*2+12*2+17*2+18*2+24*2+30)*2=446通过以构建赫夫曼树的方式构建归并树,使其对读写外存的次数降至最低
(k-路平衡归并,需要选取合适的 k 值,构建赫夫曼树作为归并树)
所以称此归并树为最佳归并树

7.“虚段”的归并树
(1)引入
上述图 2 中所构建的为一颗真正的 3叉树(树中各结点的度不是 3 就是 0)
而若 9 个初始归并段改为 8 个,在做 3-路平衡归并的时候就需要有一个结点的度为 2
对于具体设置哪个结点的度为 2,为了使总的带权路径长度最短,正确的选择方法是:附加一个权值为 0 的结点(称为“虚段”)
例如图 2 中若去掉权值为 30 的结点,其附加虚段的最佳归并树如图 3 所示:
注意:虚段的设置只是为了方便构建赫夫曼树,在构建完成后虚段自动去掉即可

(2)如何判断是否需要增加虚段,以及增加多少虚段
在一般情况下,对于 k–路平衡归并来说
若 (m-1)MOD(k-1)=0,则不需要增加虚段
否则需附加 k-(m-1)MOD(k-1)-1 个虚段
为了提高整个外部排序的效率,本章分别从以上两个方面对外部排序进行了优化:
- 在实现将初始文件分为 m 个初始归并段时,为了尽量减小 m 的值,采用置换-选择排序算法,可实现将整个初始文件分为数量较少的长度不等的初始归并段
- 同时在将初始归并段归并为有序完整文件的过程中,为了尽量减少读写外存的次数,采用构建最佳归并树的方式,对初始归并段进行归并,而归并的具体实现方法是采用败者树的方式
十三:文件
一:什么是文件?
1.表
集合为表,文件在外存集合为表
2.文件
称存储在二级存储器(外存储器)中的记录集合为文件
二:文件及类别
1.操作系统的文件&数据库文件【记录的类型不同】
(1)操作系统的文件
操作系统中的文件仅是一维的连续的字符序列,无结构、无解释
它也是记录的集合,这个记录仅是一个字符组
用户为了存取、加工方便,把文件中的信息划分成若干组
每一组信息称为一个逻辑记录,且可按顺序编号
(2)数据库文件
数据库中的文件是带有结构的记录的集合
这类记录是由一个或多个数据项组成的集合,它也是文件中可存取的数据的基本单位
数据项是最基本的不可分的数据单位,也是文件中可使用的数据的最小单位
例如,图12. 1所示为一一个数据库文件,每个学生的情况是一一个记录,它由10个数据项组成。

2.定长记录文件&不定长记录文件【含有信息长度】
(1)定长记录文件
若文件中每个记录含有的信息长度相同,则称这类记录为定长记录,由这类记录组成的文件称做定长记录
(2)不定长记录文件
若文件中含有信息长度不等的不定长记录,则称不定长记录文件
3.单关键字文件&多关键字文件【记录中关键字的多少】
(1)单关键字文件
若文件中的记录只有一个惟一标识记录的主关键字,则称单关键字文件
(2)多关键字文件
若文件中的记录除了含有一个主关键字外,还含有若干个次关键字,则称为多关键字文件
记录中所有非关键字的数据项称为记录的属性
三:逻辑结构&物理结构
1.逻辑结构
记录的逻辑结构是指记录在用户或应用程序员面前呈现的方式
是用户对数据的表示和存取方式
通常,记录的逻辑结构着眼在用户使用方便
2.物理结构
记录的物理结构是数据在物理存储器上存储的方式
是数据的物理表示和组织
而记录的物理结构则应考虑提高存储空间的利用率和减少存取记录的时间
它根据不同的需要及设备本身的特性可以有多种方式
从11.1节的讨论中已得知:
一个物理记录指的是计算机用一条I/O命令进行读写的基本数据单位
对于固定的设备和操作系统,它的大小基本上是固定不变的
而逻辑记录的大小是由使用要求定的
3.文件的组织方式
文件在存储介质(磁盘或磁带)上的组织方式称为文件的物理结构
文件可以有各种各样的组织方式,其基本方式有3种:
顺序组织、随机组织和链组织
一个特定的文件应采用何种物理结构应综合考虑各种因素
如:存储介质的类型、记录的类型、大小和关键字的数目以及对文件作何种操作等
4.物理记录&逻辑记录之间的3种关系:
(1) 一个物理记录存放一个逻辑记录
(2)一个物理记录包含多个逻辑记录
(3)多个物理记录表示一个逻辑记录
用户读/写一个记录是指逻辑记录
查找对应的物理记录则是操作系统的职责
图12.2简单表示了这种关系
图中的逻辑记录和物理记录满足上述第- -种关系,物理记录之间用指针相链接

四:文件的操作【运算】
文件的操作有两类:检索和修改
1.文件的检索
文件的检索有下列3种方式:
存取下一个逻辑记录
(2)直接存取
存取第i个逻辑记录
以上两种存取方式都是根据记录序号(即记录存人文件时的顺序编号)或记录的相对位置进行存取的
给定一个值,查询一个或-批关键字与给定值相关的记录
对数据库文件可以有如下4种查询方式:
查询关键字等于给定值的记录
例如,在图12.1的文件中,给定--个准考证号码或学生姓名,查询相关记录
查询关键字属某个区域内的记录
例如,在图12.1的文件中查询某某中学的学生成绩,则给定准考证号的某个数值范围。
给定关键字的某个函数
例如查询总分在全体学生的平均分以上的记录或处于中值的记录。.
以上3种询问用布尔运算组合起来的询问
例如,查询总分在600分以上且数学在100分以上,或者总分在平均分以下的外语在98分以,上的全部记录。
2.文件的修改
文件的修改包括插入一个记录、删除-一个记录和更新-个记录 3种操作
文件的操作可以有实时和批量两种不同方式
通常实时处理对应答时间要求严格,应在接收询问之后几秒钟内完成检索和修改,而批量处理则不然
不同的文件系统其使用有不同的要求
例如,一个民航自动服务系统,其检索和修改都应实时处理;而银行的用有不同的要求
例如,一个民航自动服务系统,其检索和修改都应实时处理;而银行的件上,在一天的营业之后再进行批量处理
五:顺序文件
1.定义
顺序文件(SequentialFile)是记录按其在文件中的逻辑顺序依次进入存储介质而建立的
即顺序文件中物理记录的顺序和逻辑记录的顺序是一致的
2.连续文件&串联文件
若次序相继的两个物理记录在存储介质上的存储位置是相邻的,则又称连续文件
若物理记录之间的次序由指针相链表示,则称串联文件
3.特点
顺序文件是根据记录的序号或记录的相对位置来进行存取的文件组织方式
它的特点是:
(1)存取第i个记录,必须先搜索在它之前的i-1个记录
(2)插人新的记录时只能加在文件的末尾
(3)若要更新文件中的某个记录,则必须将整个文件进行复制
由于顺序文件的优点是连续存取的速度快
因此主要用于只进行顺序存取、批量修改的情况
若对应答时间要求不严时亦可进行直接存取
4.举例
磁带是一种典型的顺序存取设备
因此存储在磁带上的文件只能是顺序文件
磁带文件适合于文件的数据量甚大、平时记录变化少、只作批量修改的情况
在对磁带文件作修改时,--般需用另一条复制带将原带上不变的记录复制-遍
同时在复制的过程中插人新的记录和用更改后的新记录代替原记录写人
为了修改方便起见,要求待复制的顺序文件按关键字有序(若非数据库文件,则可将逻辑记录号作为关键字)
磁带文件的批处理过程可如下进行:
待修改的原始文件称做主文件存放在一条磁带上
所有的修改请求集中构成一个文件,称做事务文件,存放在另一台磁带上
尚需第三台磁带作为新的主文件的存储介质
=====================================================================================
主文件按关键字自小至大(或自大至小)顺序有序
事务文件必须和主文件有相同的有序关系
因此,首先对事务文件进行排序,然后将主文件和事务文件归并成-一个新的主文件
图12.3为这个过程的示意图
在归并的过程中,顺序读出主文件与事务文件中的记录比较它们的关键字并分别进行处理
对于关键字不匹配的主文件中的记录,则直接将其写人新主文件中
“更改”和“删去”记录时,要求其关键字相匹配
“删去”不用写人
而“更改”则要将更改后的新记录写入新主文件
“插人”时不要求关键字相匹配,可直接将事务文件.上要插入的记录写到新主文件的适当位置
=====================================================================================
例如有一个银行的账目文件:
其主文件保存着各储户的存款余额;
每个储户作为一个记录,储户账号为关键字;记录按关键字从小到大顺序排列
一天的存人和支出集中在一个事务文件中,事务文件也按账号排序
成批地更改主文件并得到一个新的主文件
其过程如图12.4所示


六:索引文件
1.定义
除了文件本身(称做数据区)之外
另建立--张指示逻辑记录和物理记录之间一一对应关系的表一索引表
这类包括文件数据区和索引表两大部分的文件称做索引文件
2.图解
图12. 5所示为两个索引表的例子
索引表中的每一项称做索引项
论主文件是否按关键字有序,索引表中的索引项总是按关键字(或逻辑记录号)顺序排列

3.索引顺序文件&索引非顺序文件
若数据区中的记录也按关键字顺序排列,则称索引顺序文件
反之,若数据区中记录不按关键字顺序排列,则称索引非顺序文件
4.特点
索引表是由系统程序自动生成的
在记录输人建立数据区的同时建立一个索引表
表中的索引项按记录输人的先后次序排列
待全部记录输入完毕后再对索引表进行排序
例如,对应于图12.6(a)的数据文件
其索引表如图12.6(b)所示
而图12.6(c)为文件记录输人过程中建立的索引表

5.检索
(1)检索方式
索引文件的检索方式为直接存取或按关键字(进行简单询问)存取
检索过程和第9章讨论的分块查找相类似
应分两步进行:
首先,查找索引表,若索引表上存在该记录,则根据索引项的指示读取外存上该记录
否则说明外存上不存在该记录,也就不需要访问外存
由于索引项的长度比记录小得多,则通常可将索引表-次读入 内存
由此在索引文件中进行检索只访问外存两次
即一次读索引,一-次读记录
并且由于索引表是有序的;则查找索引表时可用折半查找法
(2)索引文件的修改更新
索引文件的修改也容易进行
删除-个记录时,仅需删去相应的索引项
插人-一个记录时,应将记录置于数据区的末尾
同时在索引表中插人索引项
更新记录时,应将更新后的记录置于数据区的末尾,同时修改索引表中相应的索引项
当记录数目很大时,索引表也很大,以致-一个物理块容纳不下
在这种情况下查阅索索引表需占用3个物理块的外存,每一个物理块容纳3个索引
则建立的查找表如图12.7所索引表需占用3个物理块的外存
检索记录时,先查找查找表,再查索引表,然后读取记录
3次访向外存即可。若查找表中项目还多,则可建立更高一级的索引
通常最高可有四级索引:数据文件→索引表→查找表- +第二查找表- +第三查找表
而检索过程从最高一级索引即第三查找表开始,需要5次访问

上述的多级索引是一种静态索引,各级索引均为顺序表结构
其结构简单,但修改很不方便,每次修改都要重组索引。因此,当数据文件在使用过程中记录变动较多时,应采用动态索引
如二叉排序树(或二叉平衡树)、B树以及键树,这些都是树表结构,插人、删除都很方便
又由于它本身是层次结构,则无需建立多级索引,而且建立索引表的过程即二叉排序树(或平衡树)作索引,其查找性能已在第9章中进行了详细讨论
反之,当文件二叉排序树(或平衡树)作索引,其查找性能已在第9章中进行了详细讨论
反之,当文件很大时,索引表(树表)本身也在外存,则查找索引时尚需多次访问外存,并且,访问外存的次数恰为查找路径.上的结点数。显然,为减少访问外存的次数,就应尽量縮减索引表的深度
因此,此时宜采用m叉的B-树作索引表。m的选择取决于索引项的多少和缓冲区的大小。又,从“9. 2. 3/键树”的讨论可见,键树适用于作某些特殊类型的关键字的索引表
和上述对排序树的讨论类似,当索引表不大时,可采用双链表作存储结构(此时索引表在内存);反之,则采用Trie树。总之,由于访问外存的时间比内存查找的时间大得多,所以.对外存中索引表的查找效能主要取决于访问外存的次数,即索引表的深度
(3) 稠密索引&非稠密索引
显然,索引文件只能是磁盘文件
综上所述,由于数据文件中记录不按关键字顺序排列
则必须对每个记录建立一个索引项
如此建立的索引表称之为稠密索引,它的特点是可以在索引表中进行“预查找”,即从索引表便可确定待查记录是否存在或作某些逻辑运算
如果数据文件中的记录按关键字顺序有序,则可对一组记录建立-一个索引项,这种索引表称之为非稠密索引
它不能进行“预查找”,但索引表占用的存储空间少,管理要求低
七:ISAM文件和VSAM文件
1.ISAM文件
(1)定义
索引顺序存取方法ISAM为Indexed Sequential Access Methed的缩写,它是一种专为磁盘存取设计的文件组织方式
由于磁盘是以:盘组、柱面和磁道三级地址存取的设备
则可对磁盘上的数据文件建立盘组、柱面和磁道中三级索引
(2)文件结构示列
文件的记录在同一盘组上存放时,应先集中放在一个柱面上
然后再顺序存放在相邻的柱面上,对同一柱面,则应按盘面的次序顺序存放
shi
例如图12.8为存放在一个磁盘组上的ISAM文件
(3)磁道索引项结构
每个柱面建立一个磁道索引
每个磁道索引项由两部分组成:基本索引项和溢出索引项
如图12.9所示,每一部分都包括关键字和指针两项
前者表示该磁道中最末一个记录的关键字(在此为最大关键字)
后者指示该磁道中第-一个记录的位置

(4)柱面索引
柱面索引存放在某个柱面上,若柱面索引较大,占多个磁道,则可建立柱面索引的索引一主索引
在ISAM文件上检索记录时,先从主索引出发找到相应的柱面索引
再从柱面索引找到记录所在柱面的磁道索引
最后从磁道索引找到记录所在磁道的第-一个记录的位置
由此出发在该磁道上进行顺序查找直至找到为止
反之,若找遍该磁道而不存在此记录,则表明该文件中无此记录
例如,查找关键字为21的记录时的查找路径如图12. 8中的粗实线所示
从图12.8中读者可看到,每个柱面上还开辟有-个滥出区
并且,磁道索引项中有溢出索引项,这是为插人记录所设置的
由于ISAM文件中记录是按关键字顺序存放的,则在插人记录时需移动记录
并将同一磁道上最末一个记录移至溢出区,同时修改磁道索引项
(5)溢出区3种设置方法
通常溢出区可有3种设置方法:
(1)集中存放一整个文件 设-一个大的单- - 的溢出区;
(2)分散存放一每个柱 面设一个溢出区;
(3)集中与分散相结合一溢 出时记录先移至每个柱面各自的溢出区,待满之后再使用公共溢出区
图12.8是第二种设置法
(6)文件的插入和溢出处理
每个柱面的基本区是顺序存储结构
而溢出区是链表结构
同一磁道溢出的记录由指针相链
该磁道索引的溢出索引项中的关键字指示该磁道溢出的记录的最大关键字
而指针则指示在溢出区中的第一个记录
图12.10所示为插人记录和溢出处理的具体例子
其中(a)为插人前的某一柱面上的状态
(b)为插入R.s时,将第二道中关键字大于65的记录顺次后移,且使Roo溢出至溢出区的情况
(c)为插人Res之后的状态,此时2道的基本索引项的关键字改为80,且溢出索引项的关键字改为90
其指针指向第4道第一个记录即Rgo;
(d)是相继插人Ras和Ra后的状态,Ro。
s插人在第3道的第一个记录的位置而使Rrs溢出。
而由于80<83<90,则R被直接插人到溢出区,作为第2道在溢出区的第一个记录,
并将它的指针指向Reo的位置,同时修改第2道索引的溢出索引项的指针指向Res。




(7)柱面索的位置
通常,磁道索引放在每个柱面的第一道上,那么,柱面索引是否也放在文件的第一个柱面上呢?由于每一次检索都需先查找柱面索引,则磁头需在各柱面间来回移动,我们希望磁头移动距离的平均值最小。假设文件占有n个柱面,柱面索引在第x柱面上。则磁头移动距离的平均值为:
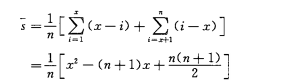
柱面索引应放在数据文件的中间位置的柱面上
2.VSAM文件
虚拟存储存取方法VSAM是Virtual Storage Access Method的缩写
这种存取方法利用了操作系统的虚拟存储器的功能,给用户提供方便
对用户来说,文件只有控制区间和控制区城等逻辑存储单位
与外存储器中柱面、磁道等具体存储单位没有必然的联系
用户在存取文件中的记录时,不需要考虑这个记录的当前位置是否在内存
也不需要考虑何时执行对外存进行“读/写”的指令
VSAM文件的结构如图12. 11所示。
它由3部分组成:索引集、顺序集和数据集
文件的记录均存放在数据集中
数据集中的一个结点称为控制区间(Control Interval)它是一个I/O操作的基本单位,它由一组连续的存储单元组成
控制区间的大小可随文件不同而不同
但同一文件.上控制区间的大小相同
每个控制区间含有一个或多个按关键字递增有序排列的记录
顺序集和索引集一起构成- -棵B+树,为文件的索引部分
顺序集中存放每个控制区间的索引项

每个控制区间的索引项由两部分信息组成:
即该控制的一个结点,结点之间用指针相链结,而每个结点又在其上- -层的结点中建有索引,且逐的一个结点,结点之间用指针相链结,而每个结点又在其上- -层的结点中建有索引,且逐层向上建立索引
所有的索引项都由最大关键字和指针两部分信息组成,这些高层的索引项形成B+树的非终端结点。因此,VSAM文件既可在顺序集中进行顺序存取,又可从最高层的索引(B+树的根结点)出发进行按关键字存取。顺序集中一个结点连同其对应的所有控制区间形成-个整体,称做控制区域(ControlRange)。每个控制区间可视为--个逻辑磁道,而每个控制区域可视为-一个逻辑柱面
在VSAM文件中,记录可以是不定长的,则在控制区间中除了存放记录本身以外
还有每个记录的控制信息(如记录的长度等)
和整个区间的控制信息(如区间中存有的记录数等)
控制区间的结构如图12. 12所示。
在控制区间上存取-一个记录时需从控制区间的.两端出发同时向中间扫描

VSAM文件中没有溢出区,解决插人的办法是在初建文件时留有空间
-.是每个控制区间内不填满记录,在最末-个记录和控制信息之间留有空隙;
二是在每个控制区域中有一些完全空的控制区间,并在顺序集的索引中指明这些空区间
当插人新记录时,大多数的新记录能插人到相应的控制区间内
但要注意为了保持区间内记录的关键字自小至大有序
则需将区间内关键字大于插入记录关键字的记录向控制信息的方向移动
若在若干记录插人之后控制区间已满,则在下一个记录插人时要进行控制区间的分裂
即将近乎一半的记录移到同一控制区域中全空的控制区间中,并修改顺序集中相应索引
倘若控制区域中已经没有全空的控制区间,则要进行控制区域的分裂
此时顺序集中的结点亦在VSAM文件中删除记录时,需将同一控制区间中较删除记录关键字大的记录向前情况
在VSAM文件中删除记录时,需将同一控制区间中较删除记录关键字大的记录向前移动
把空间留给以后插人的新记录。若整个控制区间变空,则需修改顺序集中相应的索引项
由此可见,VSAM文件占有较多的存储空间,一般只能保持约75%的存储空间利用率
但它的优点是:动态地分配和释放存储空间,不需要对文件进行重组,并能较快地对插人的记录进行查找
查找一一个后插人记录的时间与查找一一个原有记录的时间是相同的
为了作性能上的优化,VSAM用了一些其他的技术,如指针和关键字的压缩、索引的存放处理等
八:直接存取文件【散列文件】
1.定义
直接存取文件指的是利用杂凑(Hash)法进行组织的文件
它类似于哈希表,即根据:
文件中关键字的特点设计一种哈希函数和处理冲突的方法将记录散列到存储设备上,故又称散列文件
2.桶
与哈希表不同的是,对于文件来说,磁盘上的文件记录通常是成组存放的
若干个记录组成一个存储单位,在散列文件中,这个存储单位叫做桶(Bucket)
假若-一个桶能存放m个记录
这就是说,m个同义词的记录可以存放在同一地址的桶中
而当第m+1个同义词出现时才发生“溢出”
处理溢出也可采用哈希表中处理冲突的各种方法,但对散列文件,主要采用链地址法。
3.处理溢出 【溢出桶-基桶】
当发生“溢出”时,需要将第m+1个同义词存放到另一个桶中
通常称此桶为“溢出桶”;相对地,称前m个同义词存放的桶为“基桶”
溢出桶和基桶大小相同,相互之间用指针相链接
当在基桶中没有找到待查记录时,就顺指针所指到溢出桶中进行查找
因此,希望同--散列地址的溢出桶和基桶在磁盘上的物理位置不要相距太远最好在同一柱面上
4.直接存取文件示例
例如,某一文件有18 个记录
其关键字分别为278, 109 , 063, 930,589 ,184, 505 ,269 , 008 ,083,164, 215,330,810,620,110,384,355
桶的容量m=3,桶数b=7。用除留余数法作哈希函数H(key)=key MOD 7
由此得到的直接存取文件如图12. 13所示

5.桶的容量和查找次数的关系
在直接文件中进行查找时,首先根据给定值求得哈希地址(即基桶号)
将基桶的记录出桶的记录读人内存继续进行顺序查找,直至检索成功或不成功
因此,总的查找时出桶的记录读人内存继续进行顺序查找,直至检索成功或不成功
因此,总的查找时出桶的记录读人内存继续进行顺序查找,直至检索成功或不成功。
因此,总的查找时间为:
a为存取桶数的期望值(相当于哈希表中的平均查找长度),
对链地址处理溢出来说,a=1+g;
te为存取-个桶所需的时间;ti为在内存中顺序查找一个记录所需时间。
a为装载因子,在散列文件中.
n为文件的记录数,
b为桶数,m为桶的容量。
显然,增加m可减少a,也就使a减小,此时虽则使ti增大,但由于te>>ti,则总的时间T仍可减少
图12.14 展示了a和a的关系。
在直接存取文件中删除记录时,和哈希表一样,仅需对被删记录作--标记即可
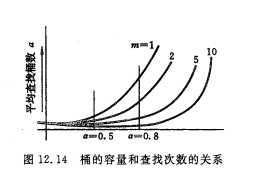
6.优缺点
总之,直接存取文件的优点是:
文件随机存放,记录不需进行排序
插人、删除方便
存取速度快
不需要索引区,节省存储空间
其缺点是:
不能进行顺序存取,只能按关键字随构不合理
即溢出桶满而基桶内多数为被删除的记录此时亦需重组文件
结构不合理,即溢出桶满而基桶内多数为被删除的记录
此时亦需重组文件
九:多关键字文件
多关键字文件的特点是
在对文件进行检索操作时,不仅对主关键字进行简单询问
还经常需要对次关键字进行其他类型的询问检索
1.多重表文件
多重表文件(MultilistFile)的特点是:
记录按主关键字的顺序构成-一个串联文件
并建立主关键字的索引(称为主索引)
对每一个次关键字项建立次关键字索引(称为次索引)
所有具有同一次关键字的记录构成一个链表
主索引为非稠密索引,次索引为稠密索引


多重链表文件易于构造,也易于修改
如果不要求保持链表的某种次序,则插人一个新记录是容易的
此时可将记录插在链表的头指针之后
但是,要删去一个记录却很繁琐,需在每个次关键字的链表中删去该记录
2:倒排序文件
倒排文件和多重表文件的区别在于次关键字索引的结构不同
通常,称倒排文件中的次关键字索引为倒排表
具有相同次关键字的记录之间不设指针相链
而在倒排表中该次关键字的一项中存放这些记录的物理记录号
解答,如询问“软件”专业的学生中有否选课程“乙”的
则只要将“软件”索引中的记录号和“乙”索引中的记录号作求“交”的集合运算即可

在插人和删除记录时,倒排表也要作相应的修改
值得注意的是倒排表中具有同--次关键字的记录号是有序排列的,则修改时要作相应移动
若数据文件非串链文件,而是索引顺序文件(如ISAM文件),
则倒排表中应存放记录的主关键字而不是物理记录号
倒排文件的缺点是维护困难
在同一索引表中,不同的关键字其记录数不同
各倒排表的长度不等,同--倒排表中各项长度也不等