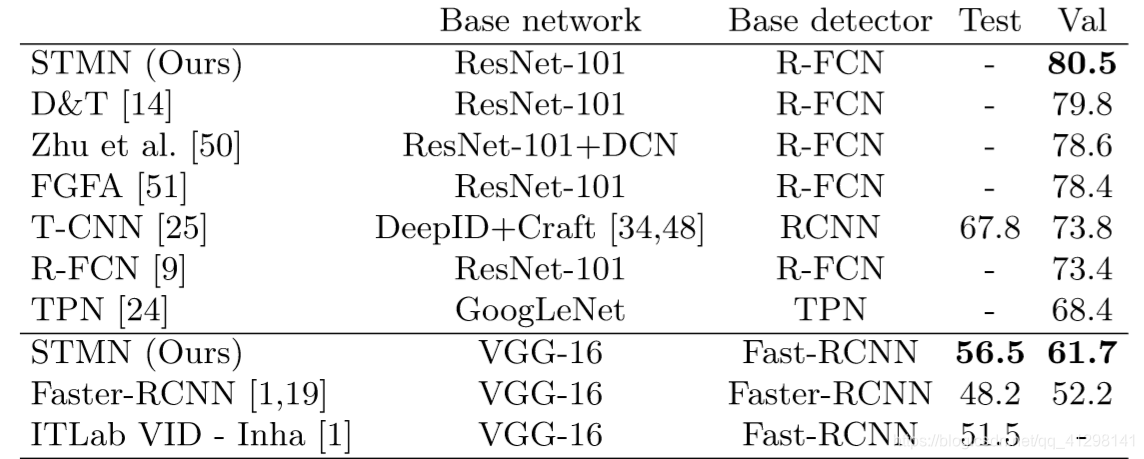
主要贡献:提出了一个新的时空记忆网络(STMN)用于视频目标检测。将预先训练好的图像分类权重集成到memory和网络内对齐模块中,该模块在时间上对memory进行空间对齐
Towards high performance for video object detection和fgfa只能在固定数量的小帧上进行聚合信息,本文的方法可以在长的可变的帧上面进行信息聚合。只需要计算一个帧级的空间memory,计算是独立于proposals的数量的。
ConvGRU首先被提出用于动作识别,然后又被用于视频目标分割的任务,本文的工作与之有三个不同点:(1)是分类边界框而不是帧或者像素(2)提出的STMN充分利用在大型图片数据集上预先训练的静态图片检测器权重(3)本文提出的时空记忆是通过MatchTrans模块进行逐帧对齐的。结果表明这个方法比ConvGRU在视频目标检测上性能更好。
方法: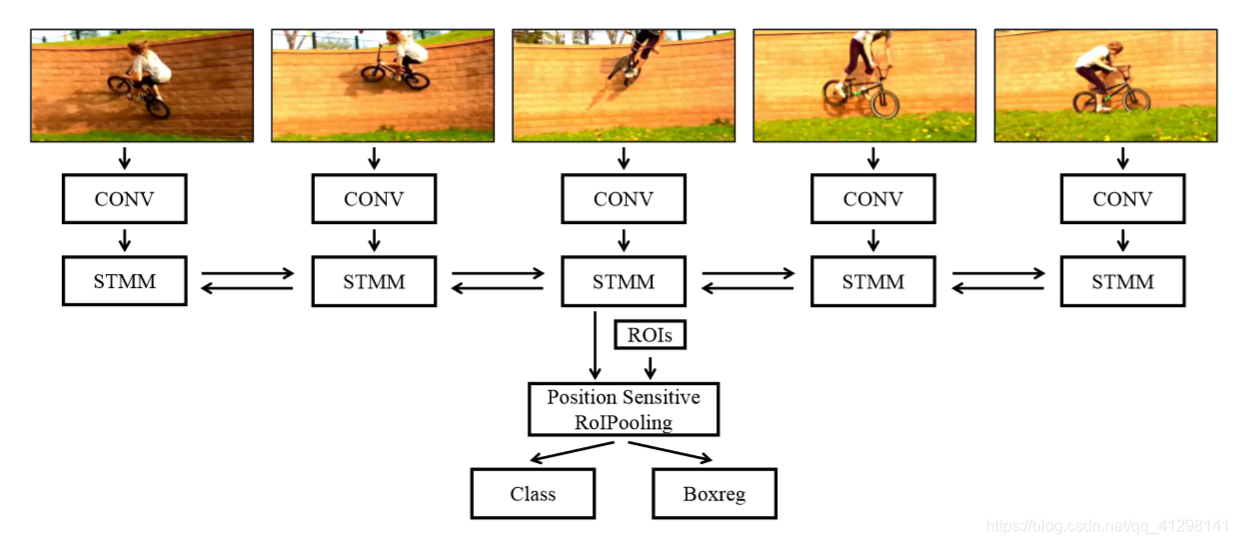
概述:如上图所示,对于一个长度为L的视频序列,首先对每一帧通过卷积网络得到卷积特征映射F1,F2,F3,…FT作为外观特征,然后将每一帧的外观特征送入到时空记忆模块(STMM)中。每个时间t的STMM接收外观特征Ft和时空记忆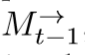 ,其包含了之前t-1帧的所有信息。STMM根据这两个更新当前时刻的
,其包含了之前t-1帧的所有信息。STMM根据这两个更新当前时刻的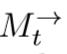 ,为了抓住前后帧的信息,使用两个STMM,一个方向一个,即
,为了抓住前后帧的信息,使用两个STMM,一个方向一个,即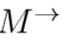 和
和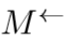 ,两者集合起来得到暂时调整的内存M。M中保存了空间信息,然后将其送入到随后的卷积/玩全连接层用于类别分类和边界框回归。
,两者集合起来得到暂时调整的内存M。M中保存了空间信息,然后将其送入到随后的卷积/玩全连接层用于类别分类和边界框回归。
STMM
计算公式如下: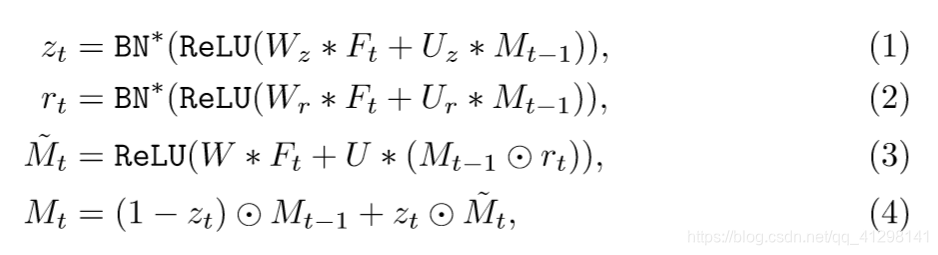
表示卷积,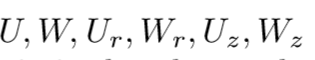 是权重,端到端的优化。rt门表示之前的状态Mt-1有多少需要忘记以此生成候选记忆
是权重,端到端的优化。rt门表示之前的状态Mt-1有多少需要忘记以此生成候选记忆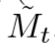 ,Zt门表示需要结合多少先前的Mt-1和
,Zt门表示需要结合多少先前的Mt-1和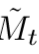 来生成Mt。为了生成rt和zt,需要先对Mt-1和Ft进行放射变换,然后对输出应用ReLu。BN是对标准的BatchNorm进行两次变换,使得输入在【0,1】之间,而不是0均值,和单位标准差
来生成Mt。为了生成rt和zt,需要先对Mt-1和Ft进行放射变换,然后对输出应用ReLu。BN是对标准的BatchNorm进行两次变换,使得输入在【0,1】之间,而不是0均值,和单位标准差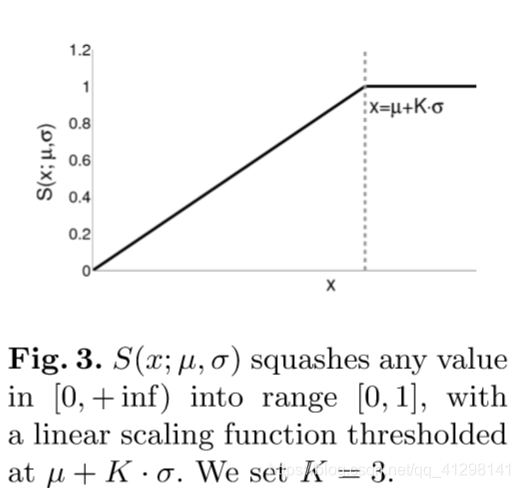
与ConvGRU的不同之处:由于是使用RFCN基于图片的检测器的权重来初始化STMN,因此需要做出两个改变(1)将COnvGRU中的sigmoid和tanh都变为ReLU,因为ConvGRU的输出在【-1,1】(due to tanh)和预训练卷积层的输入范围不匹配。(2)用交换的卷积层的权重来初始化公式1-3中的权重,而不是随意初始化。
时空记忆对齐:
由于目标在视频中处于移动状态,因此它们的空间特征在帧之间是不对其的,因此需要跨帧对齐memory。如果不对齐就会出现下图第四行的现象。为了解决这个问题提出了MatchTrans模块。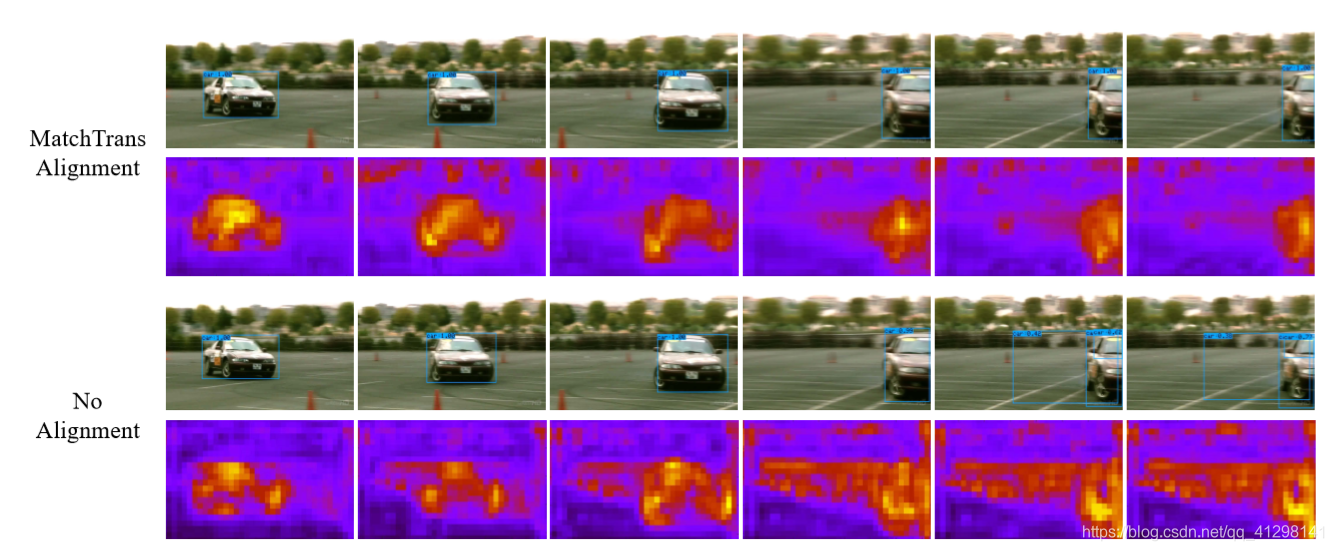
对于Ft中的(x,y)位置的特征元Ft(x,y),MatchTrans计算Ft(x,y)和Ft-1 (x,y)位置周围小范围的特征元之间的关系。转换系数计算如下: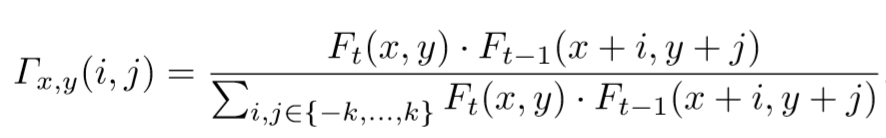
将不对齐的Mt-1转换成对齐的Mt-1‘的公式如下: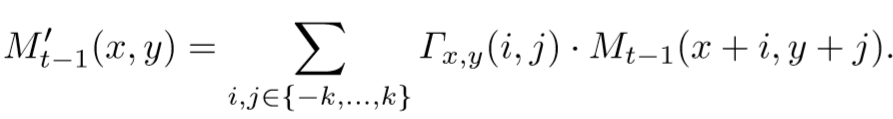
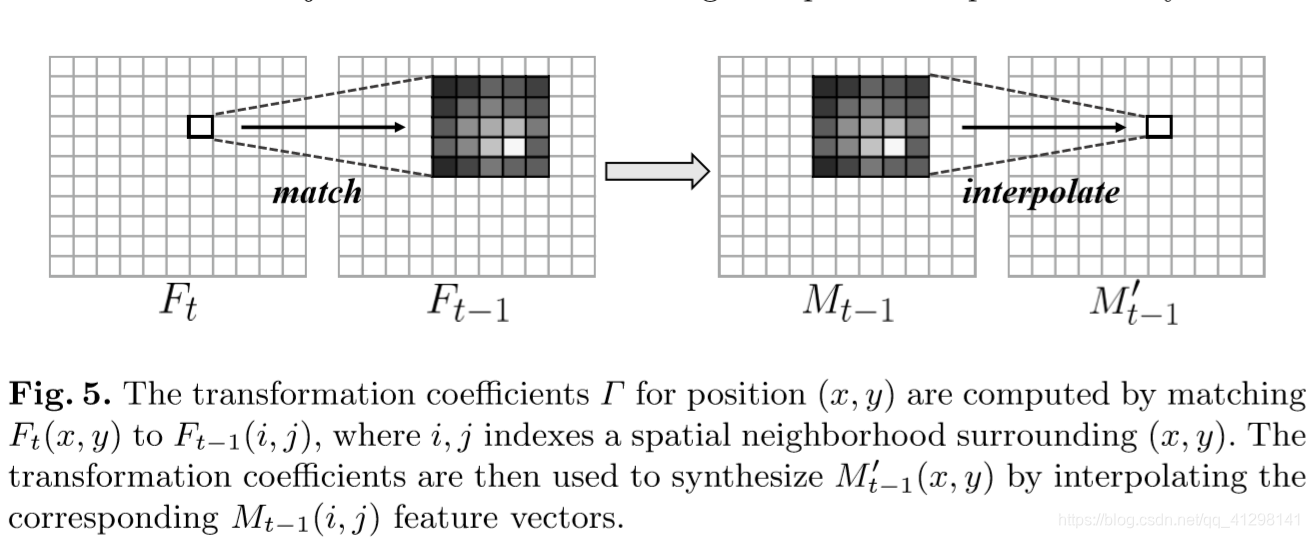
这个方法和光流相比更加有效,劫争了储存光流的计算时间和空间。
实现细节:
使用以resnet-101为backbone的r-FCN网络,首先在ImageNet DET上进行训练,然后迁移权重初始化STMN检测器,继续在ImageNet VID上进行微调。训练时的序列长度设为7
结果
超过基于R-FCN的静态图片检测器7.1%,超过了所有以ResNet-101为基础网络的视频目标检测器,为了与以Faster R-CNN为基础网络的检测器相比,作者同样将STMN以Faster R-CNN或者VGG16为基础网络进行训练,结果同样超过它们。(61.7%vs 52.2%)