人民币二分类

机器学习模型训练步骤


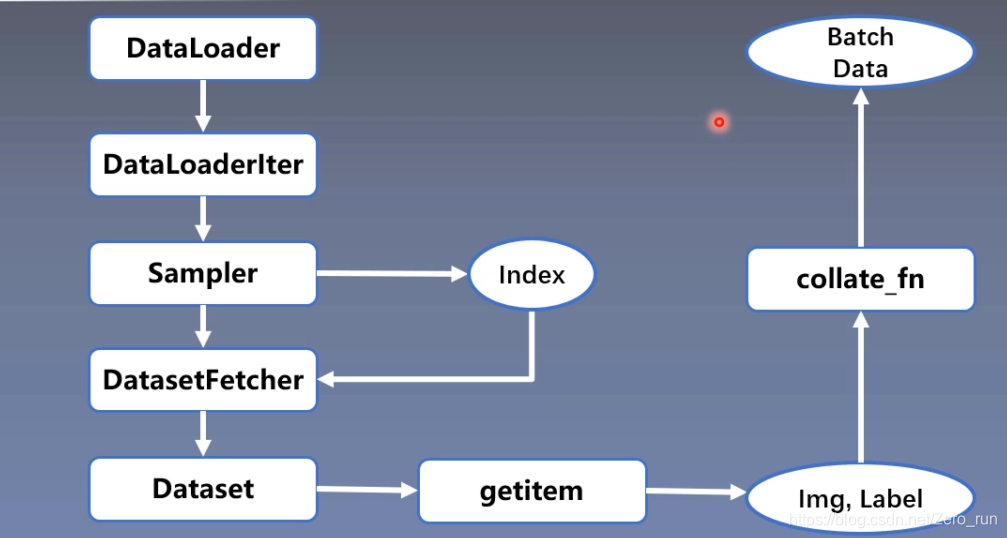
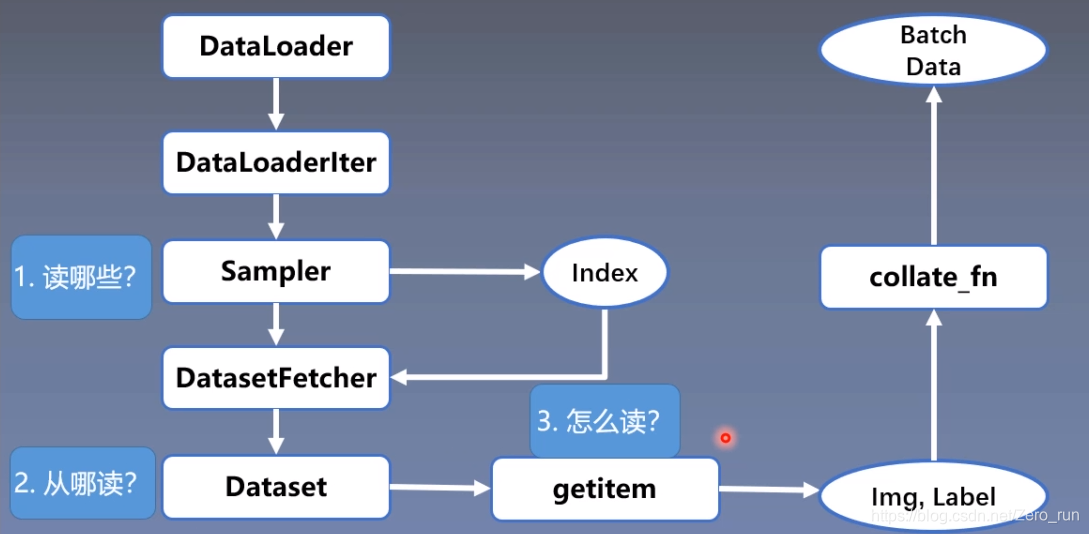
DataLoader 与 Dataset
DataLoader
torch.utils.data.DataLoader
Data(dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_list=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
功能: 构建可迭代的数据装载器
- dataset:Dataset类,决定数据从哪读取以及如何读取
- batchsize:批大小
- num_works: 是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_list:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
Iteration: 一批样本输入到模型中,称之为一个Iteration
Batchsize: 批大小,决定一个Epoch有多少个Iteration

Dataset
torch.utils.data.Dataset
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
功能:Dataset抽象类,所有自定义个Dataset需要继承它,并且复写__getitem__()
getitem: 接收一个索引,返回一个样本


版权声明:本文为Zero_run原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。