本文授权转载自原作者黄瑞敏, 未经许可请勿转载
编译,其实就是把源代码变成机器能理解的目标代码(如汇编语言)的过程。
编译的主要步骤主要如下:
- 词法分析:把输入的字符串流变成
token。 - 语法分析:把
token变成抽象语法树AST。 - 语义分析:遍历
AST树,根据已有的语义规则做语义理解和语义检查。 - 生成目标语言(如汇编语言)。
本篇文章分析以 javascript 为程序语言的基本编译过程及相关原理。
词法分析
简单理解,就是将程序(字符串形式)进行解析:
例如对于
10 + 2 * 30
我们已经定义好这些词法:
- TokenNumber: 1 2 3 4 5 6 7 8 9 0 的组合
- Operator: + 、-、 *、 / 之一
- Whitespace:
- LineTerminator:
空白和换行没有意义,因此不加入后续语义分析。
怎么将程序字符解析出我们需要的一个一个的 token ,有两种方法,一种是状态机,一种正则;
这里用状态机demo作为例子解析 10 + 2 * 30:
let token = [];
let result = [];
const inSingleChar = char => { // 分析单个字符
if(['1', '2', '3', '4', '5', '6', '7', '8', '9', '0'].indexOf(char) > -1) {
token.push(char);
return inNumber;
}
if(['+', '-', '*', '/'].indexOf(char) > -1) {
emmitToken(char, char);
return inSingleChar
}
if(char === ' ') {
return inSingleChar;
}
if(char === '\r'
|| char === '\n'
) {
return inSingleChar;
}
}
const inNumber = char => {
if(['1', '2', '3', '4', '5', '6', '7', '8', '9', '0'].indexOf(char) > -1) {
token.push(char);
return inNumber;
} else {
emmitToken("Number", token.join(""));
token = [];
return inSingleChar(char);
}
}
function emmitToken(type, value) {
console.log(value);
result.push({
type,
value: value
});
}
接下来运行上述代码:
let input = "24 + 2 * 100";
let state = inSingleChar;
for(var c of input.split(''))
state = state(c);
state(Symbol('EOF')); // EOF为文件结束符
result.push({
type: 'EOF'
})
运行之后,结果如下:
24
+
2
*
100
得到的result,即解析得到的 token如下:
[{
type: 'Number',
value: '24'
},
{
type: '+',
value: '+'
},
{
type: 'Number',
value: '2'
},
{
type: '*',
value: '*'
},
{
type: 'Number',
value: '100'
},
{
type: 'EOF'
}]
这样我们就对这段表达式程序进行了正确的词法“分割”,这个函数虽然实现得简陋,但是实际上就是一个有限状态机[1],如图:
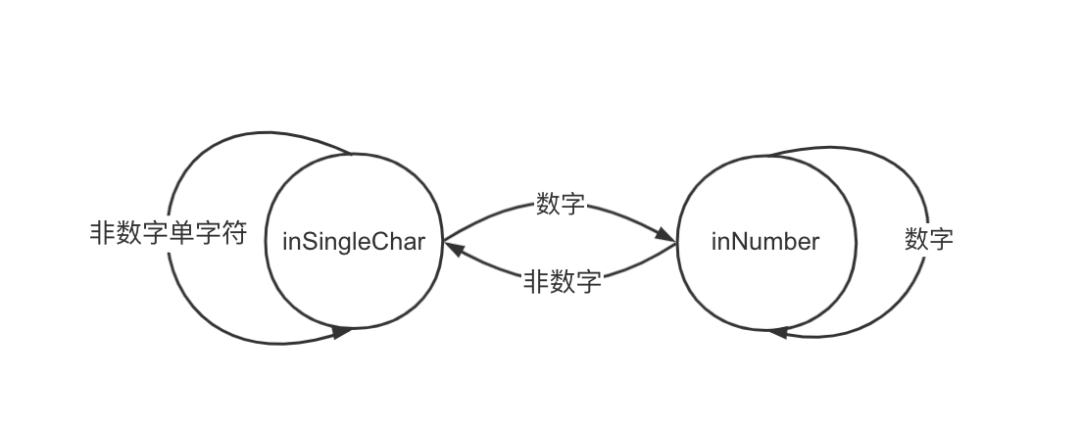
当然,真正的分析词法的状态机要复杂很多,因为不只是有数字和上述几个特定的字符。
语法分析
词法分析得到 token 之后就是语法分析; 将其转换成 AST语法树 ,那么什么是 AST语法树 ?
“Abstract Syntax Tree, 是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于 if-condition-then 这样的条件跳转语句,可以使用带有三个分支的节点来表示。
是不是很抽象,咋一看确实有点难以理解,这里介绍一个工具,“AST螺丝刀” recast[2]。
recast 能将程序转化成AST语法树;
首先安装 npm i recast。
接着,可以在vs code中调试这段代码:
const recast = require("recast");
const code = `10 + 2 * 30`;
const ast = recast.parse(code);
const add = ast.program.body[0];
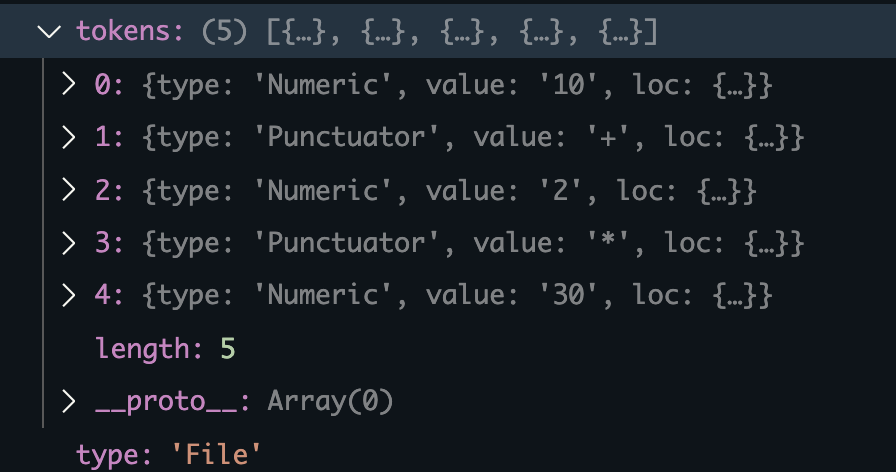
可以看见ast对象中有token这个数组记录了组成该表达式的字符:
再看 ast.program.body[0] 这个对象:
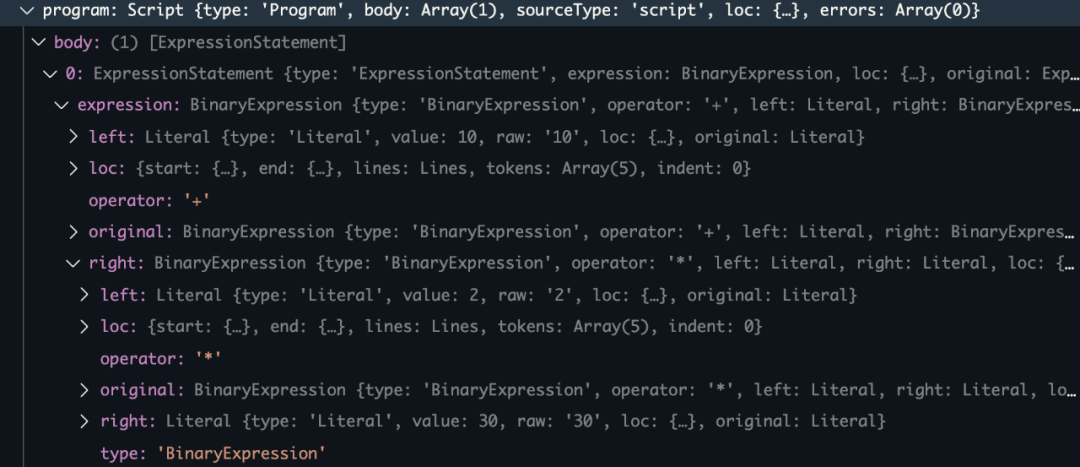
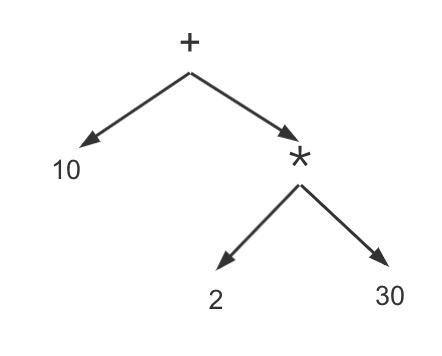
其实就是AST语法树:
这里只是一个简单的表达式,如果是一个完整的函数会是怎么样的呢?
可以再看这个例子:
const recast = require("recast");
const code =
`
function add(a, b) {
var sum = 10 + 2 * 30;
return sum;
}
`;
const ast = recast.parse(code);
const add = ast.program.body[0];
调试出来的 ast.program.body[0] 如图:

也就是包含这些属性:
FunctionDeclaration{
type: 'FunctionDeclaration',
params:
[ Identifier { type: 'Identifier', name: 'a', loc: [Object] },
Identifier { type: 'Identifier', name: 'b', loc: [Object] } ],
body: {
body: [VariableDeclaration, ReturnStatement],
type: 'BlockStatement'
}
}
可视化为树形结构即为:
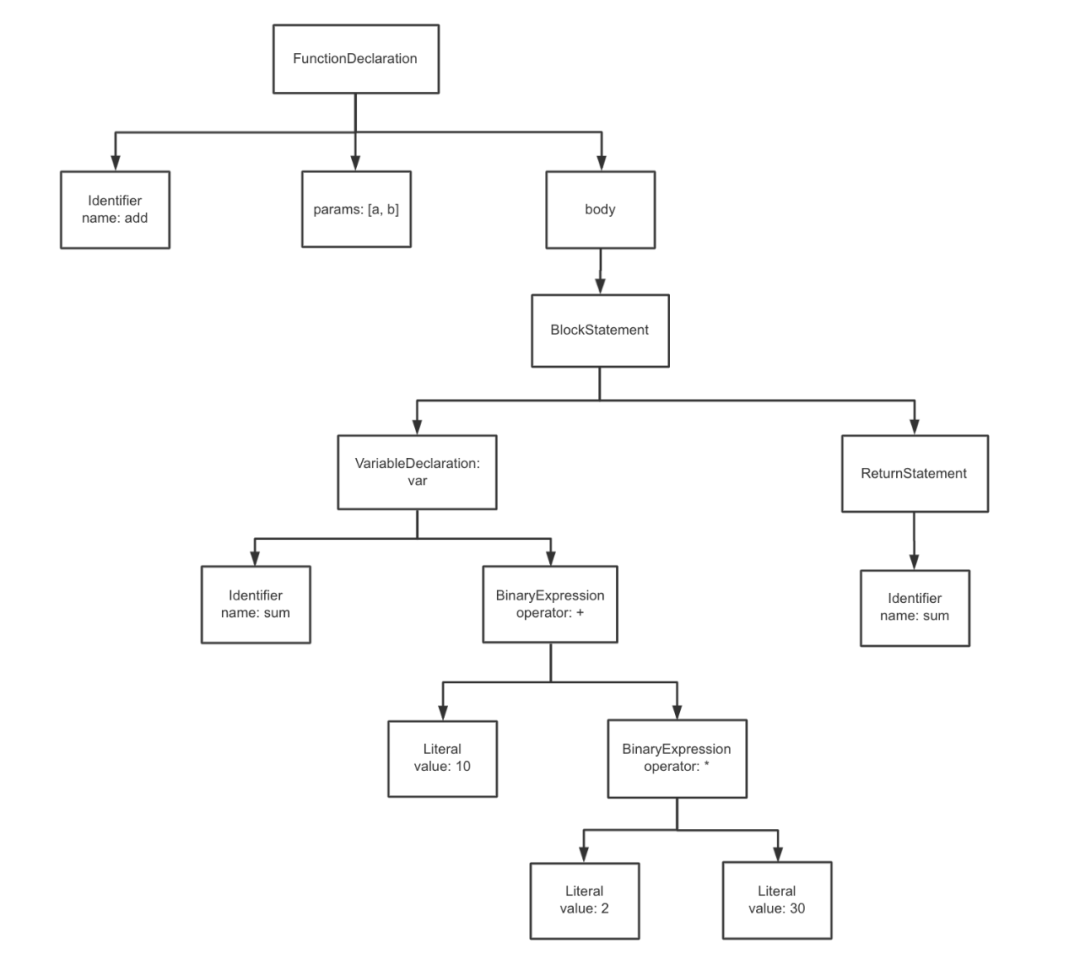
注意:组成这棵 AST语法树 的节点“部件”可以在:AST对象文档[3]中找到。
那么实际中怎么将一个一个 Token 转换成上述 AST语法树 呢?这里涉及到的算法一般有两种,推荐自行查阅 LL算法[4]或LR算法[5]。
语义分析
生成 AST语法树 后,程序的语法结构就很清晰了,但是机器如何理解这棵“树”的呢?实际上,语言的设计者在定义类似“a+3”中加号这个操作符的时候,是给它规定了一些语义的,就是要把加号两边的数字相加。例如在 ECMAScript(也就是 JavaScript)标准 2020 版 加法操作的语义规则[6] 中,对于如何计算左节点、右节点的值,如何进行类型转换等有这样的规定:

同时语义言分析也会进行标注,做上下文相关的分析。并对不符合规范的地方进行报错。
生成目标代码
之后,编译器这时可以说可以直接生成目标代码了,因为编译器已经完全理解了程序的含义,并把它表示成了带有语义信息的 AST、符号表等数据结构。其实实际编译过程还会再生成中间代码(处于源代码和目标代码之间的一种表示形式)及进行优化。
例如:跳过方法如 person.getName() 的调用,直接根据对象的地址计算出 name 属性的地址,然后直接从内存取值。(该优化法称为内联)
中间代码可以使得优化更加简易,而优化可以使目标代码运行效率更高。
总结
理解了代码运行前都做了什么,能更宏观地了解一门语言,例如,在列javascript知识框架时,可以这么列出它的框架:
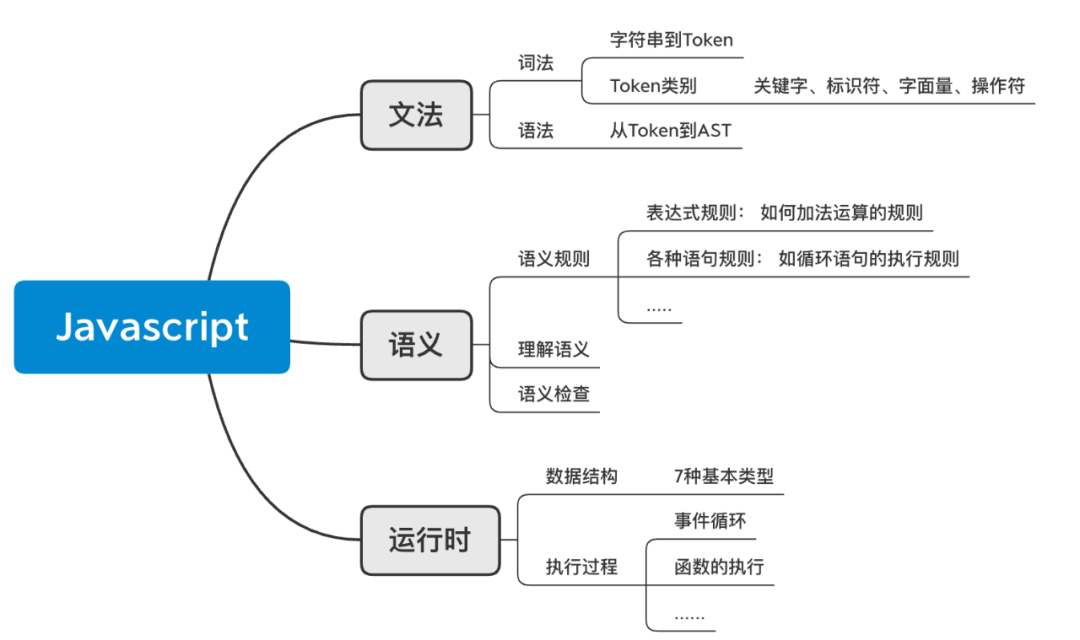
然而本文只是简单介绍了以javascript为例子的简单的代码编译机制,当然其中涉及到的每一个知识点都并不简单,因此需要由浅入深,逐步探索。
参考资料
[1]有限状态机: https://zh.wikipedia.org/wiki/%E6%9C%89%E9%99%90%E7%8A%B6%E6%80%81%E6%9C%BA
[2]recast: https://github.com/benjamn/recast
[3]AST对象文档: https://developer.mozilla.org/en-US/docs/Mozilla/Projects/SpiderMonkey/Parser_API#Node_objects
[4]LL算法: https://zh.wikipedia.org/wiki/LL%E5%89%96%E6%9E%90%E5%99%A8
[5]LR算法: https://zh.wikipedia.org/wiki/LR%E5%89%96%E6%9E%90%E5%99%A8
[6]加法操作的语义规则: https://tc39.es/ecma262/2020/#sec-additive-operators