前言
前一段时间在实现生产消费队列模型,参考了disruptor的等待策略,对比各种策略的区别,然后发现了BusySpinWaitStrategy忙等策略中注释写的一段话,It is best used when threads can be bound to specific CPU cores.当线程可以被绑定到特定的CPU核心时,用这个策略是最佳的。然后去了解了一下如何将线程绑定到cpu上,大概是如何实现的,这里写篇博客记录一下
注:由于博主经验水平有限,更多的是记录学习笔记并分享,如有纰漏请各位指正,感激不尽
简介
有时候我们在多核机器上,需要将线程(或进程)绑定到给定的某个核心上,让它独享一核心,比如队列的BusySpin忙等策略中、或者netty的eventLoop,将这个忙等的线程绑定到一个cpu核上,可以确保该进程的最大执行速度,实现低延迟,消除操作系统进行调度过程导致线程迁移所造成的抖动影响,还可以避免由于缓存失效而导致的性能开销
这种绑定关系叫做线程(或进程)亲和(affinity),也叫线程(或进程)的亲缘性屏蔽,就是进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性
如果觉得上面说的比较抽象,那么下面我们来实操
实操
官方git:https://github.com/OpenHFT/Java-Thread-Affinity
参考文章:https://blog.csdn.net/shenwansangz/article/details/50297637
首先引入pom
<dependency>
<groupId>net.openhft</groupId>
<artifactId>affinity</artifactId>
<version>3.2.3</version>
</dependency>
1、限制线程在单个cpu核心上运行
try (AffinityLock al = AffinityLock.acquireLock()) {
// do some work while locked to a CPU.
System.out.println(al.cpuId());
while(true) {}
}
用法很简单,在需要亲和的代码上加上acquireLock即可,它会自动分配一个空闲核心
try (AffinityLock al = AffinityLock.acquireLock(5)) {
// do some work while locked to a CPU.
System.out.println(al.cpuId());
while(true) {}
}
如果要指定一个cpu也是可以的,我这里指定cpu5
如果启动了两个java程序,将其分配到同一cpu核心也是可以的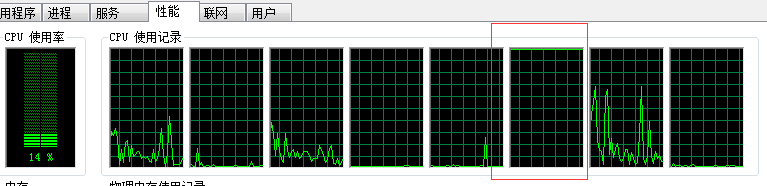
指定了cpu5,可以发现指定的核心被占用了
2、限制线程在多个cpu核心上运行
首先可以通过getAffinity获取进程的关联性掩码,查看当前线程能够在哪几个cpu核心运行
BitSet bitSet = Affinity.getAffinity();
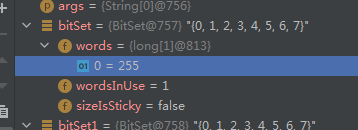
我这里4核8线程的,默认是255,对应二进制mask= 1111 1111,表示该线程可以在所有CPU核心上运行,这个就是默认值
BitSet bitSet1 = new BitSet();
bitSet1.set(4);
bitSet1.set(5);
bitSet1.set(6);
bitSet1.set(7);
Affinity.setAffinity(bitSet1);
可以自己指定mask掩码,比如这里的掩码值为oct(240)=bin(1111 0000),就是把当前线程限制到了cpu4、5、6、7核心上运行,也可以说是运行线程在这四个cpu核心迁移(能够被操作系统调度),关于掩码计算在源码分析会详细说明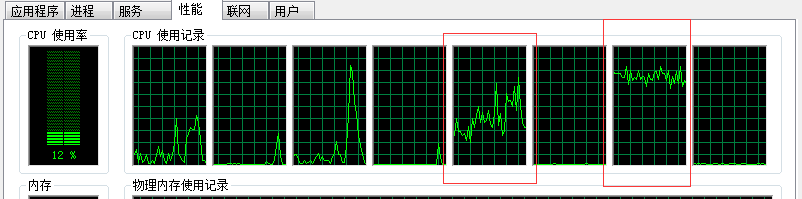
发现这样配置后,负载就被调度器平摊在cpu4、cpu6上面了
最核心的两种用法就是这样子,可以发现用起来相当方便,下面来看看java层面的源码是如何实现的
实现原理
Java-Thread-Affinity基于3.2.3版本
像这种操作比较底层的东西用纯java都是不能完成的,一般是使用JNI调用的C来实现的
查看Java-Thread-Affinity源码,发现它是用JNA Java Native Access (Java 本地访问)实现的
JNA简介:https://wangmaoxiong.blog.csdn.net/article/details/80823622
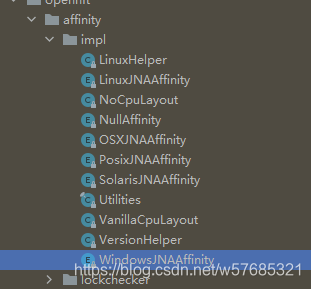
可以看到对于不同操作系统平台都有不同的JNA实现
net.openhft.affinity.Iaffinity是一个通用接口,定义了基本的操作
public interface IAffinity {
/**
* @return returns affinity mask for current thread, or null if unknown
*/
BitSet getAffinity();
/**
* @param affinity sets affinity mask of current thread to specified value
*/
void setAffinity(final BitSet affinity);
/**
* @return the current cpu id, or -1 if unknown.
*/
int getCpu();
/**
* @return the process id of the current process.
*/
int getProcessId();
/**
* @return the thread id of the current thread or -1 is not available.
*/
int getThreadId();
}
net.openhft.affinity.Affinity在类加载的时候就判断当前是什么操作系统,然后获取上面接口的相应的实现类
static {
String osName = System.getProperty("os.name");
if (osName.contains("Win") && isWindowsJNAAffinityUsable()) {
LOGGER.trace("Using Windows JNA-based affinity control implementation");
AFFINITY_IMPL = WindowsJNAAffinity.INSTANCE;
} else if (osName.contains("x")) {
/*if (osName.startsWith("Linux") && NativeAffinity.LOADED) {
LOGGER.trace("Using Linux JNI-based affinity control implementation");
AFFINITY_IMPL = NativeAffinity.INSTANCE;
} else*/
if (osName.startsWith("Linux") && isLinuxJNAAffinityUsable()) {
LOGGER.trace("Using Linux JNA-based affinity control implementation");
AFFINITY_IMPL = LinuxJNAAffinity.INSTANCE;
} else if (isPosixJNAAffinityUsable()) {
LOGGER.trace("Using Posix JNA-based affinity control implementation");
AFFINITY_IMPL = PosixJNAAffinity.INSTANCE;
} else {
LOGGER.info("Using dummy affinity control implementation");
AFFINITY_IMPL = NullAffinity.INSTANCE;
}
} else if (osName.contains("Mac") && isMacJNAAffinityUsable()) {
LOGGER.trace("Using MAC OSX JNA-based thread id implementation");
AFFINITY_IMPL = OSXJNAAffinity.INSTANCE;
} else if (osName.contains("SunOS") && isSolarisJNAAffinityUsable()) {
LOGGER.trace("Using Solaris JNA-based thread id implementation");
AFFINITY_IMPL = SolarisJNAAffinity.INSTANCE;
} else {
LOGGER.info("Using dummy affinity control implementation");
AFFINITY_IMPL = NullAffinity.INSTANCE;
}
}
所以核心的功能实现就在那几个Iaffinity接口的实现类上,下面针对win和linux平台的代码实现做简单分析
windows下分析
在windows下,加载了kernel32.dll,先调用getAffinity方法获取处理器数量,然后调用它的SetThreadAffinityMask函数,通过调用它,就能为各个线程设置亲缘性屏蔽
Java源码实现:
@Override
public void setAffinity(final BitSet affinity) {
final CLibrary lib = CLibrary.INSTANCE;
WinDef.DWORD aff;
long[] longs = affinity.toLongArray();
switch (longs.length) {
case 0:
aff = new WinDef.DWORD(0);
break;
case 1:
aff = new WinDef.DWORD(longs[0]);
break;
default:
throw new IllegalArgumentException("Windows API does not support more than 64 CPUs for thread affinity");
}
int pid = getTid();
try {
lib.SetThreadAffinityMask(pid, aff);
} catch (LastErrorException e) {
throw new IllegalStateException("SetThreadAffinityMask((" + pid + ") , &(" + affinity + ") ) errorNo=" + e.getErrorCode(), e);
}
}
在lib.SetThreadAffinityMask(pid, aff);调用的native SetThreadAffinityMask函数
private interface CLibrary extends Library {
CLibrary INSTANCE = (CLibrary) Native.loadLibrary("kernel32", CLibrary.class);
int GetProcessAffinityMask(final int pid, final PointerType lpProcessAffinityMask, final PointerType lpSystemAffinityMask) throws LastErrorException;
void SetThreadAffinityMask(final int pid, final WinDef.DWORD lpProcessAffinityMask) throws LastErrorException;
int GetCurrentThread() throws LastErrorException;
}
关于它调用的native函数有这些,分别是获取当前进程关联性掩码,设置当前线程关联性掩码,获取当前线程信息
下面来看这个关键的函数:
DWORD_PTR SetThreadAffinityMask(
HANDLE hThread,
DWORD_PTR dwThreadAffinityMask
);
参考文档:https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-setthreadaffinitymask
它的作用是为指定的线程设置处理器亲和性掩码,第一个参数为线程句柄,第二个参数为一个cpu mask
1、线程句柄通过调用GetCurrentThread函数获取
2、mask的规则是,每一bit位表示一个cpu的状态,比如在核心0上(一般不用核心0)mask=0x01;核心1上mask=0x02;核心2上mask=0x04;核心0和核心1上mask=0x03
关于掩码计算
你可能会好奇这个规则通过什么方式计算出来的,其实很简单,先将这个16进制转换为2进制,来详细说明一下mask计算
在64位机器上的 2进制 ====> 16进制
绑定到核心1:(前面省略56个0) 0000 0010 ====> 0x(省略8个0)0000 0002
绑定到核心2:(前面省略56个0) 0000 0100 ====> 0x(省略8个0)0000 0004
绑定到核心1、2:(前面省略56个0) 0000 0110 ====> 0x(省略8个0)0000 0006
绑定到核心6、7:(前面省略56个0) 1100 0000 ====> 0x(省略8个0)0000 00C0
所以规律就是从右往左,一共64个槽位对应64核心,绑定哪个就把哪个的二进制为设置为1。这个思想就是bitMap算法的思想,bitMap在java中的实现是bitSet,所以java源码中用的BitSet定义的affinity变量,然后将其affinity.toLongArray();很方便的转为long类型(DWORD类型),然后传入SetThreadAffinityMask函数中
需要注意的是:Mask为一个DWORD类型,在64位机器上就是64位长度,8字节,相当于java的long类型,所以这里有个缺陷,当cpu核超过64个的时候,也就超过了64bit(8字节)能够表示的长度,就无法使用这个函数进行线程亲和的设置了。可以用另一个SetThreadGroupAffinity函数解决,它使用处理器组解决了这个问题(目前Java-Thread-Affinity框架还不支持64核心以上的,可以自己利用这个方式修改一下)
可以参考文档
https://docs.microsoft.com/en-us/windows/win32/api/processtopologyapi/nf-processtopologyapi-setthreadgroupaffinity
https://docs.microsoft.com/en-us/windows/win32/procthread/processor-groups
Linux下分析
Linux下使用了sched_setaffinity函数来实现的
关于这个函数可以man一下,或者参考https://linux.die.net/man/2/sched_setaffinity
int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
sched_setaffidity ()设置进程的 CPU 关联掩码
参数1:进程的pid,如果 pid 为0,则使用调用此函数的进程
参数2:cpusersize 参数是掩码指向的数据的长度(以字节为单位),通常这个参数被指定为 sizeof (cpu _ set _ t)
参数3:掩码,为cpu_set_t类型,掩码的计算方式与之前的一样,只是这里传递的数据类型不一样
Java源码实现
同样的,linux下调用了下面这几个native函数
interface CLibrary extends Library {
CLibrary INSTANCE = (CLibrary) Native.loadLibrary(LIBRARY_NAME, CLibrary.class);
int sched_setaffinity(final int pid,
final int cpusetsize,
final cpu_set_t cpuset) throws LastErrorException;
int sched_getaffinity(final int pid,
final int cpusetsize,
final cpu_set_t cpuset) throws LastErrorException;
int getpid() throws LastErrorException;
int sched_getcpu() throws LastErrorException;
int uname(final utsname name) throws LastErrorException;
int syscall(int number, Object... args) throws LastErrorException;
}
public static void sched_setaffinity(final int pid, final BitSet affinity) {
final CLibrary lib = CLibrary.INSTANCE;
final cpu_set_t cpuset = new cpu_set_t();
final int size = version.isSameOrNewer(VERSION_2_6) ? cpu_set_t.SIZE_OF_CPU_SET_T : NativeLong.SIZE;
final long[] bits = affinity.toLongArray();
for (int i = 0; i < bits.length; i++) {
if (Platform.is64Bit()) {
cpuset.__bits[i].setValue(bits[i]);
} else {
cpuset.__bits[i * 2].setValue(bits[i] & 0xFFFFFFFFL);
cpuset.__bits[i * 2 + 1].setValue((bits[i] >>> 32) & 0xFFFFFFFFL);
}
}
try {
if (lib.sched_setaffinity(pid, size, cpuset) != 0) {
throw new IllegalStateException("sched_setaffinity(" + pid + ", " + size +
", 0x" + Utilities.toHexString(affinity) + ") failed; errno=" + Native.getLastError());
}
} catch (LastErrorException e) {
throw new IllegalStateException("sched_setaffinity(" + pid + ", " + size +
", 0x" + Utilities.toHexString(affinity) + ") failed; errno=" + e.getErrorCode(), e);
}
}
可以发现最终调用了sched_setaffinity(pid, size, cpuset)
public static class cpu_set_t extends Structure {
static final int __CPU_SETSIZE = 1024;
static final int __NCPUBITS = 8 * NativeLong.SIZE;
static final int SIZE_OF_CPU_SET_T = (__CPU_SETSIZE / __NCPUBITS) * NativeLong.SIZE;
static List<String> FIELD_ORDER = Collections.singletonList("__bits");
public NativeLong[] __bits = new NativeLong[__CPU_SETSIZE / __NCPUBITS];
public cpu_set_t() {
for (int i = 0; i < __bits.length; i++) {
__bits[i] = new NativeLong(0);
}
}
}
这个cpu_set_t的数据结构就是这样子,也看了看对应c结构体是一样的
多提一点,代码里面的NativeLong为当前平台C语言的long类型大小,经过测试,win64是4字节,linux64是8字节
这里可能会感到疑惑,为啥long类型在不同操作系统长度不一样…
多提一点,c语言的数据类型占用字节数跟机器字长(64位、32位、16位)及编译器的数据模型(LP64、ILP64、LLP64、ILP32、LP32等)有关
但有几条铁定的原则(ANSI/ISO制订的):
1 sizeof(short int)<=sizeof(int)
2 sizeof(int)<=sizeof(long int)
3 short int至少应为16位(2字节)
4 long int至少应为32位。
一般情况下windows64位一般使用LLP64模型;64位Unix,Linux使用的是LP64模型,而LLP64的long占32位(4字节),LP64的long占64位(8字节)。如果有不确定的,可以写c代码,sizeof输出看一看
关于这个sched_setaffinity函数的C调用可以参考
https://www.cnblogs.com/zlcxbb/archive/2004/01/13/6801700.html
是线程亲和还是进程亲和?
这里有个疑惑,sched_setaffidity是针对进程(process)设置的,而win的实现是SetThreadAffinityMask基于线程的(它也有基于进程的SetProcessAffinityMask),为什么linux下的实现是针对进程的
猜测可能是与这个有关,Linux下的线程与进程实现基本没有区别(可以认为一个线程本质上就是一个进程),win对于这两个有严格的区别
参考: https://developer.51cto.com/art/202002/610163.htm
通过taskset命令验证
设置完后可以通过taskset –p pid来查看当前的进程运行在哪个cpu上
taskset -p 37337
pid 37337's current affinity mask: 3
结果就是oct(3) = bin(11),我这个linux主机是双核心的,默认的就是运行所有核心处理该进程,所以掩码为11
taskset -pc 1 37337
还可以手工进程绑定在指定cpu1上
进程/线程亲和的思想很常见
这里介绍几个我目前知道的应用场景,简单记录一下,做个知识扩展
1、nginx上可以使用进程亲和
使用worker_cpu_affinity去配置进程与核心的亲和
查看文档:http://nginx.org/en/docs/ngx_core_module.html#worker_cpu_affinity
快速参考:https://blog.csdn.net/u011957758/article/details/50959823
这里涉及到两个配置worker_processes和worker_cpu_affinity
语法:
worker_processes number | auto;
worker_cpu_affinity cpumask …;
worker_cpu_affinity auto [cpumask];
worker_processes默认值为1,定义了工作进程的数量,这里推荐设置为cpu核心数,或者使用auto自动检测。这样开启了多核cpu配置后,理论上来说可以充分利用多核cpu,性能更好。配置过后ps –ef | grep nginx 可以看到开启了多个nginx进程
worker_cpu_affinity,这个就是进程亲和的关键配置,它的作用是将工作进程绑定到cpu,跟之前一样,用cpu的位掩码表示绑定关系,通常为每个工作进程都绑定一个核心,这样能使cpu每个核心负载都比较均衡。这个配置默认情况下不绑定到任何特定的cpu核心上
例子:
1、4核心cpu,将每个工作进程绑定到一个单独的核心
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
2、2核心4线程cpu,将第一个工作进程绑定到cpu0/2,第二个绑定cpu1/3,这个例子适合有超线程技术的cpu
worker_processes 2;
worker_cpu_affinity 0101 1010;
2、Netty的eventLoop也可以使用线程亲和
查看文档https://netty.io/wiki/thread-affinity.html
final int acceptorThreads = 1;
final int workerThreads = 10;
EventLoopGroup acceptorGroup = new NioEventLoopGroup(acceptorThreads);
ThreadFactory threadFactory = new AffinityThreadFactory("atf_wrk", AffinityStrategies.DIFFERENT_CORE);
EventLoopGroup workerGroup = new NioEventLoopGroup(workerThreads, threadFactory);
ServerBootstrap serverBootstrap = new ServerBootstrap().group(acceptorGroup, workerGroup);
大概看下,使用了一个线程亲和的线程工厂,在创建workerEventLoopGroup的时候使用ThreadFactory去自定义创建线程,它会根据我们配置的策略,在newThread的时候进行线程亲和。
@Override
public synchronized Thread newThread(@NotNull final Runnable r) {
String name2 = id <= 1 ? name : (name + '-' + id);
id++;
Thread t = new Thread(new Runnable() {
@Override
public void run() {
try (AffinityLock ignored = acquireLockBasedOnLast()) {
r.run();
}
}
}, name2);
t.setDaemon(daemon);
return t;
}
private synchronized AffinityLock acquireLockBasedOnLast() {
AffinityLock al = lastAffinityLock == null ? AffinityLock.acquireLock() : lastAffinityLock.acquireLock(strategies);
if (al.cpuId() >= 0)
lastAffinityLock = al;
return al;
}
我们知道NioEventLoopGroup是一个线程池实现,EventLoop是一个线程,这个AffinityThreadFactory在run之前调用了AffinityLock.acquireLock(),这样就可以把EventLoop绑定到某一核心上,所以这里的workerThreads根据自己的cpu核心数填写
3、DPDK技术
Intel® DPDK全称Intel Data Plane Development Kit,是intel提供的数据平面开发工具集,为Intel architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,它不同于Linux系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。
DPDK应用程序是运行在用户空间上利用自身提供的数据平面库来收发数据包(DPDK应用程序就是一个普通的用户态进程),绕过了Linux内核协议栈对数据包处理过程。
它可以通过设置CPU亲和性,绑定网卡和线程到固定的core,减少cpu任务切换。特定任务可以被指定只在某个核上工作,避免线程在不同核间频繁切换,保证更多的cache命中。
有兴趣的小伙伴可以参考:https://blog.csdn.net/qq_15437629/article/details/78146823