继承与多态
抽象
抽象方法:就是加上abstract关键字,去掉大括号,直接分号结束
抽象类:抽象方法所在的类,必须是抽象类才行。在class之前加上abstract即可
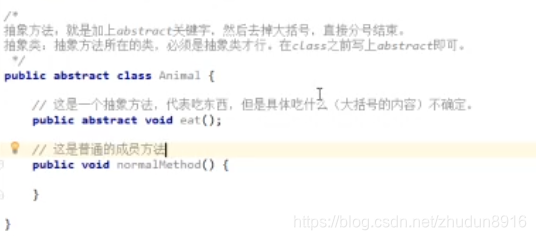
抽象方法使用
1. 不能直接new抽象类对象
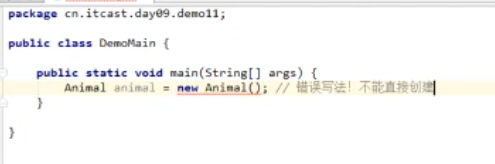
2. 必须用一个子类来继承抽象父类
3. 子类必须覆盖重写父类中的抽象方法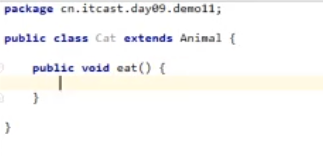
4. 创建子类对象进行使用
抽象类使用注意事项

接口
接口定义:接口就是多个类的公共规范,接口是一种引用类型,最重要的内容就是其中的抽象方法
public interface 接口名称{
//接口内容
}

接口抽象方法的定义
在任何版本中,接口都能定义抽象方法。
public abstract 返回值类型 方法名称 (参数列表);
注意事项:
1. 接口中的抽象方法,修饰符必须是两个固定的关键字:public abstract。
2. 这两个关键字的修饰符,可以选择性的省略

接口的默认方法定义
从java 8开始,接口里允许定义默认方法。
格式:
public default 返回值类型 方法名称 (参数列表){
方法体
}
//接口中的默认方法,可以解决接口升级的问题
1. 接口的默认方法可以通过接口实现类对象调用
2. 接口的默认方法也可以被接口实现类进行覆盖重写
接口的静态方法定义、
从java 8 开始,接口中允许定义静态方法
格式:
public static 返回值类型 方法名称(参数列表){
方法体
}
接口的静态方法调用、
注意事项:不能通过接口实现类调用接口中的静态方法
正确用法:通过接口名称,直接调用其中的静态方法
接口的私有方法定义、
从java 9 开始,接口当中允许定义私有方法
1. 普通私有方法,解决多个默认方法之间的重复代码问题
private 返回值类型 方法名称 (参数列表){
方法体
}
2. 静态私有方法,解决多个静态方法之间的重复代码问题
private static 返回值类型 方法名称 (参数列表){
方法体
}
接口的常量定义及使用、
接口中也可以定义成员变量,但是必须使用 public static final 三个关键字进行修饰。
格式:
public static final 数据类型 常亮名称 = 数据值;
// 使用final关键字进行修饰。说明不可改变
注意:接口当中的常量。必须进行赋值,不能不赋值
规则:接口中常量的名称,使用完全的大写字母,用下划线进行分割
接口小结

继承父类并实现多个接口
1. 接口没有静态代码块或者构造方法
2. 一个类的直接父类是唯一的,但是一个类可以同时实现多个接口
格式:
public class MyInterfaceImpl implements MyInterfacesA,MyInterfacesB{
//覆盖重写所有抽象方法
}
3. 如果实现的多个接口中,存在重复的抽象方法,那么只需覆盖重写一次即可。
4. 如果实现类没有覆盖重写所有的抽象方法,那么实现类必须是一个抽象类
5. 如果实现类实现的多个接口中,存在重复的默认方法,那么实现类一定要对冲突的默认方法就行覆盖重写。
6. 一个类的直接父类与实现接口中的方法重复,优先父类方法执行。
接口之间的多继承
注意:
1. 多个父接口当中的抽象方法重复,没关系
2. 多个父接口中的默认方法如果重复,那么子接口必须进行默认方法的覆盖重写。**【而且要带着default关键字】**
多态
多态的概述
面向对象三大特征:继承性,封装性,多态性
extends继承或者implements实现,是多态性的前提
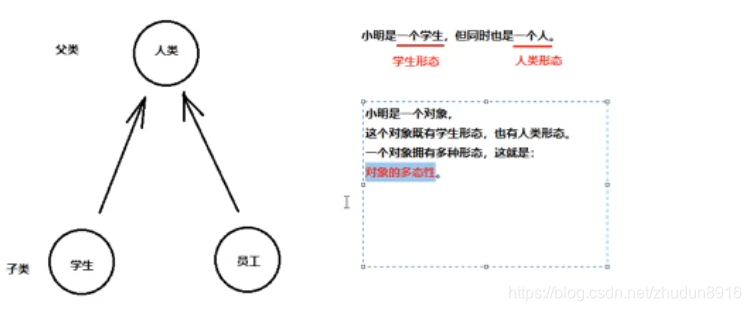
多态的格式与使用
代码当中体现多态性,其实就是一句话,父类引用指向子类对象。
格式:
父类名称 对象名 = new 子类名称();
或者
接口名称 对象名 = new实现类名称();

多态中成员变量的使用特点
访问成员变量的两种方式:
- 直接通过对象名称访问成员变量,看等号左面是谁,优先用谁,没有则向上查找
- 间接通过成员方法访问成员变量,看该方法属于谁,优先用谁,没有则向上找。
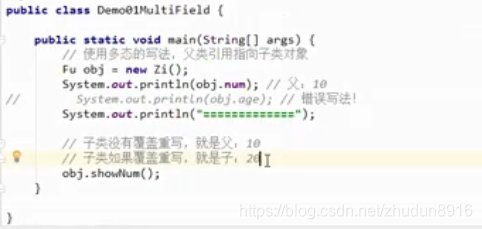
多态中成员方法的使用特点
在多态代码中,成员方法的访问规则是:
看new的是谁,就优先用谁,没有则向上查找。
*注意:编译看左边,运行看右边。*
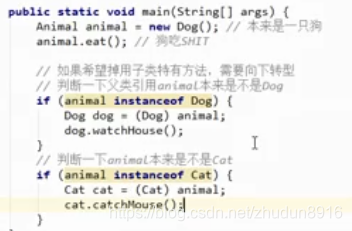
instanceof关键字
格式:
对象 instanceof 类名称
final关键字
final关键字概念与四种用法
final关键字代表最终的,不可改变的。、
常见四种用法:
1. 可以用来修饰一个类
2. 可以用来修饰一个方法
3. 可以用来修饰一个局部变量
4. 可以用来修饰一个成员变量
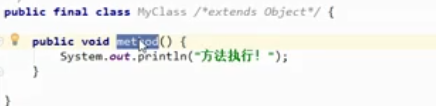
final关键字用于修饰一个类
当final关键字用来修饰一个类的时候:格式
public final class 类名称 {
//.....
}
含义:当前这个类不能有任何子类 (太监类)
注意:一个类如果是final,那么其中所有的成员方法都无法进行覆盖重写
final关键字用于修饰成员方法
当final关键字用来修饰一个方法的时候,这个方法是最终方法,也就是不能覆盖重写

注意事项:
对于类,方法来说 ,abstract关键字和final关键字不能同时使用,因为矛盾。
final关键字作用于局部变量
一旦使用final关键字用来修饰局部变量,那么这个变量就不能进行更改
一次赋值,终生不变
1. 对于基本类型来说,不可变的是变量当中的数据不可变
2. 是对于引用类型来说,不可变的是变量当中的地址值不可改变
final关键字修饰成员变量
对于成员变量来说,如果使用final关键字修饰,那么这个变量照样不变的
1. 由于成员变量有默认值,所以用了final之后必须手动赋值,不在给默认值。。
2. 对于final的成员变量,要么使用直接赋值,要么通过构造方法赋值,二者选其一
权限修饰符
四种权限修饰符
public > protected > (default) > private
同一个类 yes yes yes yes
同一个包 yes yes yes no
不同包子类 yes yes no no
不同包非子类 yes no no NO
内部类
内部类的概念及分类
如果一个事务的内部包含另一个事务,那么这就是一个类内部包含另一个类
分类:
1. 成员内部类
2. 局部内部类(包含匿名内部类)
成员内部类的定义
成员内部类的定义格式:
修饰符 class 外部类名称 {
修饰符 class 内部类名称 {
//........
}
//......
}
注意:内用外,随意访问,外用内,需要内部类对象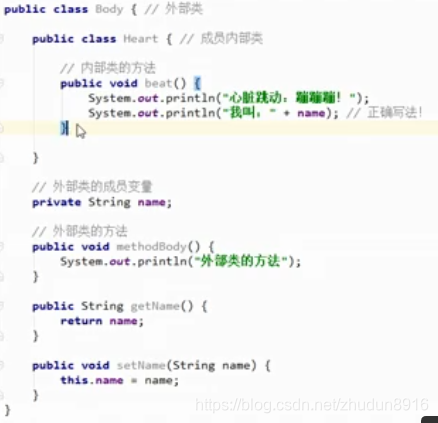
成员内部类的使用
- 间接方式:在外部类的方法当中使用内部类,然后main只调用外部类的方法
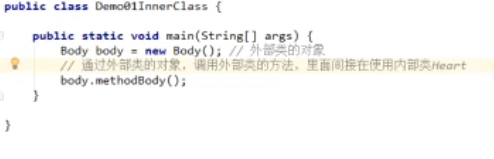
- 直接方式:公式:
外部类名称.内部类名称 对象名 = new 外部类名称().new 内部类名称()

局部内部类的定义
只有当前所属的方法才能使用。
定义格式:
修饰符 class 外部类名称 外部类方法名称(参数列表){
修饰符 返回值类型 外部类方法名称(参数列表){
class 局部内部类名称{
//.....
}
}
}
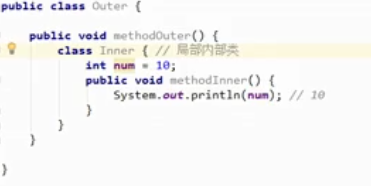
定义一个类的时候,权限修饰符规则
- 外部类: public/(default)
- 成员内部类:public/private/(default)/protectet
- 局部内部类:什么都不能写
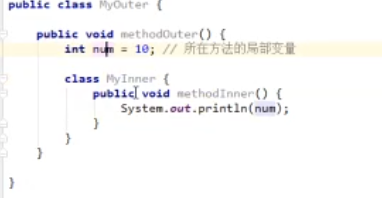
局部内部类的final问题
局部内部类,如果希望访问所在方法的局部变量,那么这个局部变量必须是【有效的final】。
备注:从java 8+开始,只要局部变量事实不变,那么final关键字可以省略。
原因:
- new出来的对象在堆内存当中。
- 局部变量是跟着方法走的,在栈内存当中
- 方法运行结束之后,立刻出栈,局部变量就会立刻消失。
- 但是new出来的对象会在堆当中持续存在,直到垃圾回收消失。
匿名内部类**
如果接口的实现类(或者是父类的子类)只需要使用一次,那么这种情况下就可以省略改类的定义。改为使用匿名内部类。
匿名内部类的定义格式:
接口名称 对象名 = new 接口名称 (){
//覆盖重写所有抽象方法
}

注意:
- 匿名内部类在创建对象的时候只能使用唯一一次
- 匿名对象,在【使用方法】的时候只能使用唯一一次
- 匿名内部类是省略了【实现类/子类名称】但是匿名对象是省略了【对象名称】。
类作为成员变量类型
接口作为成员变量类型
接口作为方法参数或返回值
常用api
object类
java.lang.object类是java语言中的根类,即所有类的父类,它中描述的所有方法子类都可以使用,在对象实例化的时候,最终找的父类就是object
object类的toString方法
看一个类是否重写了toString方法,直接打印这个类对应对象的名字即可,如果没有重写toString方法,那么打印的就是对象的地址值(默认),如果重写了tostring方法,那么就按照重写的方式打印。
object类的equals方法
boolen equals (object obj) 指示其他某个对象是否与此对象相等
object类和objects类

Date类
毫秒值的概念及作用
类 Date 表示特定的瞬间,精确到毫秒,毫秒值可以对时间何日去进行计算。
- 日期转换为毫秒
当前日期:2020-5-11
时间原点:1970-1-1 00:00:00
就是计算当前日期到时间原点一共经历了多少毫秒
System.currentTimeMillis() //当前系统时间的毫秒值
- 把毫秒值转化为日期
注意:中国属于东八区,时间增加8小时
Date类的构造方法和成员方法
- 构造方法
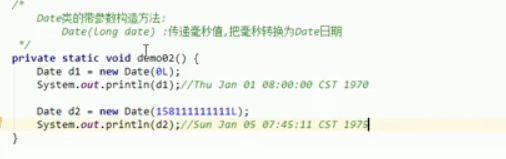
Date date= new Date();
System.out.println(date);
- 成员方法
long getTime() 把日期转化为毫秒值
Date date= new Date();
long time =date.getTime();
System.out.println(time);
DateFormat类和SimpleDateFormat类介绍
DateFormat 是日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并解析日期或时间。
- 格式化(也就是日期 -> 文本)、
- 解析(文本-> 日期)
成员方法:
string format(Date date)按照指定的模式,把Date日期,格式化为符合模式的字符串
Date parse (string Source) 把符合模式的字符串,解析为date日期
DateFormat类是一个抽象类,无法直接使用,要使用DateFormat的子类
SimpleDateFormat
SimpleDateFormat(stringpattern) 用给定的模式和默认语言环境的日期格式符号构造 。
参数:
string pattern: 传递指定的模式
模式:区分大小写的
y 年
M 月
d 日
H 时
m 分
s 秒
写对应的模式,会把模式替换成对应的日期和时间
“yyyy-MM-dd HH:mm:”ss”
“yyyy年 MM月 dd日 HH时 mm分 ss秒”
注意:模式中的字母不能更改,链接模式的符号可以改变。
DateFormat类的format方法和parse方法
format使用步骤
- 创建SimpleDateFormat对象,构造方法中传递指定的模式
- 调用SimpleDateFormat对象中的方法format,按照构造方法中指定的模式,把date日期格式转化为符合模式的字符串
SimpleDateFormat simpleDateFormat= new SimpleDateFormat("yyyy-MM-dd HH-mm-ss");
Date date = new Date();
String date1=simpleDateFormat.format(date);
System.out.println(date);
System.out.println(date1);
parse使用步骤
- 创建SimpleDateFormat对象,构造方法中传递指定的模式
- 调用SimpleDateFormat对象中的方法parse,把符合构造方法中模式的字符串,解析为Date日期
注意: parse方法申明了一个异常叫parseException解析异常,如果字符串和构造方法的模式不一样,那么程序就会抛出此异常
SimpleDateFormat simpleDateFormat= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = simpleDateFormat.parse("2020-05-11 16-47-51");
System.out.println(date);
Calendar类
Calendar类的介绍,获取对象的方式
Calendar是日历类 抽象类 其中提供了很多操作日历的方法,无法直接创建对象使用,里面有一个getInStance()。该方法返回了Calendar类的子类对象
Calander类的常用成员方法
创建日历类对象
Calendar calendar = Calendar.getInstance();


system类
system类的常用方法
public static long currentTimeMillis()
//返回一毫秒为单位的当前时间
//用来测试程序的效率
public static void arraycopy(Object src,
int srcPos,
Object dest,
int destPos,
int length)
//将数组中指定的数据拷贝到另一个数组中
| 参数序号 | 参数名称 | 参数类型 | 参数含义 |
|---|---|---|---|
| 1 | src | Object | 源数组 |
| 2 | srcPos | int | 源数组索引起始位置 |
| 3 | dest | Object | 目标数组 |
| 4 | destPos | int | 目标数组索引起始位置 |
| 5 | length | int | 复制元素个数 |
从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。从 src 引用的源数组到 dest 引用的目标数组,数组组件的一个子序列被复制下来。被复制的组件的编号等于 length 参数。源数组中位置在 srcPos 到 srcPos+length-1 之间的组件被分别复制到目标数组中的 destPos 到 destPos+length-1 位置。
StringBuilder类
StringBuilder原理
字符串缓冲区,可以提高字符串的操作效率
底层也是一个数组,但是没有被final修饰,可以改变长度。
StringBuilder的构造方法和append方法
构造方法:
public StringBuilder():构造一个空的StringBuilder容器。public StringBuilder(String str):构造一个StringBuilder容器,并将字符串添加进去。
public class StringBuilderDemo {
public static void main(String[] args) {
StringBuilder sb1 = new StringBuilder();
System.out.println(sb1); // (空白)
// 使用带参构造
StringBuilder sb2 = new StringBuilder("itcast");
System.out.println(sb2); // itcast
}
}
常用方法:
StringBuilder常用的方法有2个:
public StringBuilder append(...):添加任意类型数据的字符串形式,并返回当前对象自身。public String toString():将当前StringBuilder对象转换为String对象。
append方法具有多种重载形式,可以接收任意类型的参数。任何数据作为参数都会将对应的字符串内容添加到StringBuilder中。例如:
public class Demo02StringBuilder {
public static void main(String[] args) {
//创建对象
StringBuilder builder = new StringBuilder();
//public StringBuilder append(任意类型)
StringBuilder builder2 = builder.append("hello");
//对比一下
System.out.println("builder:"+builder);
System.out.println("builder2:"+builder2);
System.out.println(builder == builder2); //true
// 可以添加 任何类型
builder.append("hello");
builder.append("world");
builder.append(true);
builder.append(100);
// 在我们开发中,会遇到调用一个方法后,返回一个对象的情况。然后使用返回的对象继续调用方法。
// 这种时候,我们就可以把代码现在一起,如append方法一样,代码如下
//链式编程
builder.append("hello").append("world").append(true).append(100);
System.out.println("builder:"+builder);
}
}
备注:StringBuilder已经覆盖重写了Object当中的toString方法。
toString方法
通过toString方法,StringBuilder对象将会转换为不可变的String对象。如:
public class Demo16StringBuilder {
public static void main(String[] args) {
// 链式创建
StringBuilder sb = new StringBuilder("Hello").append("World").append("Java");
// 调用方法
String str = sb.toString();
System.out.println(str); // HelloWorldJava
}
}
基本类型包装类
包装类的概念
Java提供了两个类型系统,基本类型与引用类型,使用基本类型在于效率,然而很多情况,会创建对象使用,因为对象可以做更多的功能,如果想要我们的基本类型像对象一样操作,就可以使用基本类型对应的包装类,如下:
| 基本类型 | 对应的包装类(位于java.lang包中) |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
包装类的装箱与拆箱
基本类型与对应的包装类对象之间,来回转换的过程称为”装箱“与”拆箱“:
装箱:从基本类型转换为对应的包装类对象。
拆箱:从包装类对象转换为对应的基本类型。
用Integer与 int为例:(看懂代码即可)
基本数值---->包装对象
Integer i = new Integer(4);//使用构造函数函数
Integer iii = Integer.valueOf(4);//使用包装类中的valueOf方法
包装对象---->基本数值
int num = i.intValue();
包装类的自动拆箱与装箱
由于我们经常要做基本类型与包装类之间的转换,从Java 5(JDK 1.5)开始,基本类型与包装类的装箱、拆箱动作可以自动完成。例如:
Integer i = 4;//自动装箱。相当于Integer i = Integer.valueOf(4);
i = i + 5;//等号右边:将i对象转成基本数值(自动拆箱) i.intValue() + 5;
//加法运算完成后,再次装箱,把基本数值转成对象。
包装类的基本类型与字符串类型之间的相互转换
基本类型转换String总共有三种方式,查看课后资料可以得知,这里只讲最简单的一种方式:
基本类型直接与””相连接即可;如:34+""
String转换成对应的基本类型
除了Character类之外,其他所有包装类都具有parseXxx静态方法可以将字符串参数转换为对应的基本类型:
public static byte parseByte(String s):将字符串参数转换为对应的byte基本类型。public static short parseShort(String s):将字符串参数转换为对应的short基本类型。public static int parseInt(String s):将字符串参数转换为对应的int基本类型。public static long parseLong(String s):将字符串参数转换为对应的long基本类型。public static float parseFloat(String s):将字符串参数转换为对应的float基本类型。public static double parseDouble(String s):将字符串参数转换为对应的double基本类型。public static boolean parseBoolean(String s):将字符串参数转换为对应的boolean基本类型。
代码使用(仅以Integer类的静态方法parseXxx为例)如:
public class Demo18WrapperParse {
public static void main(String[] args) {
int num = Integer.parseInt("100");
}
}
注意:如果字符串参数的内容无法正确转换为对应的基本类型,则会抛出
java.lang.NumberFormatException异常。
集合
- 集合:集合是java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象。而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
Collection集合
集合框架介绍
JAVASE提供了满足各种需求的API,在使用这些API前,先了解其继承与接口操作架构,才能了解何时采用哪个类,以及类之间如何彼此合作,从而达到灵活应用。
集合按照其存储结构可以分为两大类,分别是单列集合java.util.Collection和双列集合java.util.Map,今天我们主要学习Collection集合,在day04时讲解Map集合。
- Collection:单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是
java.util.List和java.util.Set。其中,List的特点是元素有序、元素可重复。Set的特点是元素无序,而且不可重复。List接口的主要实现类有java.util.ArrayList和java.util.LinkedList,Set接口的主要实现类有java.util.HashSet和java.util.TreeSet。
从上面的描述可以看出JDK中提供了丰富的集合类库,为了便于初学者进行系统地学习,接下来通过一张图来描述整个集合类的继承体系。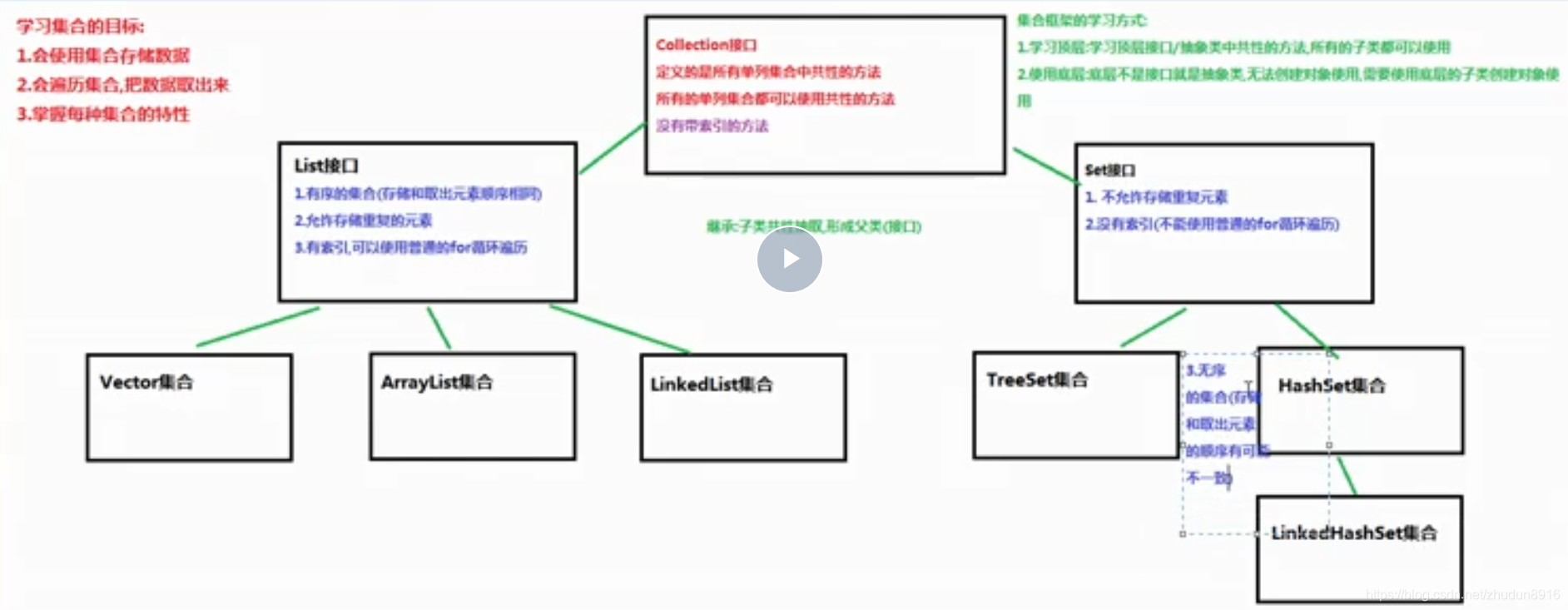
iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
下面介绍一下迭代的概念:
- 迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法如下:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
迭代器的代码实现原理
public class IteratorDemo {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("串串星人");
coll.add("吐槽星人");
coll.add("汪星人");
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
tips::在进行集合元素取出时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会发生java.util.NoSuchElementException没有集合元素的错误。
迭代器的实现原理
当遍历集合时,首先通过调用t集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,
 在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
增强for循环
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
格式:
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}
它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
练习1:遍历数组
public class NBForDemo1 {
public static void main(String[] args) {
int[] arr = {3,5,6,87};
//使用增强for遍历数组
for(int a : arr){//a代表数组中的每个元素
System.out.println(a);
}
}
}
练习2:遍历集合
public class NBFor {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("小河神");
coll.add("老河神");
coll.add("神婆");
//使用增强for遍历
for(String s :coll){//接收变量s代表 代表被遍历到的集合元素
System.out.println(s);
}
}
}
tips: 新for循环必须有被遍历的目标。目标只能是Collection或者是数组。新式for仅仅作为遍历操作出现。
泛型
泛型的概念
Collection虽然可以存储各种对象,但实际上通常Collection只存储同一类型对象。例如都是存储字符串对象。因此在JDK5之后,新增了泛型(Generic)语法,让你在设计API时可以指定类或方法支持泛型,这样我们使用API的时候也变得更为简洁,并得到了编译时期的语法检查。
- 泛型:可以在类或方法中预支地使用未知的类型。
tips:一般在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。
使用泛型的好处
- 将运行时期的ClassCastException,转移到了编译时期变成了编译失败。
- 避免了类型强转的麻烦。
通过我们如下代码体验一下:
public class GenericDemo2 {
public static void main(String[] args) {
Collection<String> list = new ArrayList<String>();
list.add("abc");
list.add("itcast");
// list.add(5);//当集合明确类型后,存放类型不一致就会编译报错
// 集合已经明确具体存放的元素类型,那么在使用迭代器的时候,迭代器也同样会知道具体遍历元素类型
Iterator<String> it = list.iterator();
while(it.hasNext()){
String str = it.next();
//当使用Iterator<String>控制元素类型后,就不需要强转了。获取到的元素直接就是String类型
System.out.println(str.length());
}
}
}
tips:泛型是数据类型的一部分,我们将类名与泛型合并一起看做数据类型。
定义和使用含有泛型的类
泛型,用来灵活地将数据类型应用到不同的类、方法、接口当中。将数据类型作为参数进行传递。
定义格式:
修饰符 class 类名<代表泛型的变量> { }
例如,API中的ArrayList集合:
class ArrayList<E>{
public boolean add(E e){ }
public E get(int index){ }
....
}
使用泛型: 即什么时候确定泛型。
在创建对象的时候确定泛型
例如,ArrayList<String> list = new ArrayList<String>();
此时,变量E的值就是String类型,那么我们的类型就可以理解为:
class ArrayList<String>{
public boolean add(String e){ }
public String get(int index){ }
...
}
再例如,ArrayList<Integer> list = new ArrayList<Integer>();
此时,变量E的值就是Integer类型,那么我们的类型就可以理解为:
class ArrayList<Integer> {
public boolean add(Integer e) { }
public Integer get(int index) { }
...
}
举例自定义泛型类
public class MyGenericClass<MVP> {
//没有MVP类型,在这里代表 未知的一种数据类型 未来传递什么就是什么类型
private MVP mvp;
public void setMVP(MVP mvp) {
this.mvp = mvp;
}
public MVP getMVP() {
return mvp;
}
}
使用:
public class GenericClassDemo {
public static void main(String[] args) {
// 创建一个泛型为String的类
MyGenericClass<String> my = new MyGenericClass<String>();
// 调用setMVP
my.setMVP("大胡子登登");
// 调用getMVP
String mvp = my.getMVP();
System.out.println(mvp);
//创建一个泛型为Integer的类
MyGenericClass<Integer> my2 = new MyGenericClass<Integer>();
my2.setMVP(123);
Integer mvp2 = my2.getMVP();
}
}
定义和使用含有泛型的方法
定义格式:
修饰符 <代表泛型的变量> 返回值类型 方法名(参数){ }
例如,
public class MyGenericMethod {
public <MVP> void show(MVP mvp) {
System.out.println(mvp.getClass());
}
public <MVP> MVP show2(MVP mvp) {
return mvp;
}
}
使用格式:调用方法时,确定泛型的类型
public class GenericMethodDemo {
public static void main(String[] args) {
// 创建对象
MyGenericMethod mm = new MyGenericMethod();
// 演示看方法提示
mm.show("aaa");
mm.show(123);
mm.show(12.45);
}
}
含有泛型的接口
定义格式:
修饰符 interface接口名<代表泛型的变量> { }
例如,
public interface MyGenericInterface<E>{
public abstract void add(E e);
public abstract E getE();
}
使用格式:
1、定义类时确定泛型的类型
例如
public class MyImp1 implements MyGenericInterface<String> {
@Override
public void add(String e) {
// 省略...
}
@Override
public String getE() {
return null;
}
}
此时,泛型E的值就是String类型。
2、始终不确定泛型的类型,直到创建对象时,确定泛型的类型
例如
public class MyImp2<E> implements MyGenericInterface<E> {
@Override
public void add(E e) {
// 省略...
}
@Override
public E getE() {
return null;
}
}
确定泛型:
/*
* 使用
*/
public class GenericInterface {
public static void main(String[] args) {
MyImp2<String> my = new MyImp2<String>();
my.add("aa");
}
}
泛型的统配符
当使用泛型类或者接口时,传递的数据中,泛型类型不确定,可以通过通配符<?>表示。但是一旦使用泛型的通配符后,只能使用Object类中的共性方法,集合中元素自身方法无法使用。
通配符基本使用
泛型的通配符:不知道使用什么类型来接收的时候,此时可以使用?,?表示未知通配符。
此时只能接受数据,不能往该集合中存储数据。
举个例子大家理解使用即可:
public static void main(String[] args) {
Collection<Intger> list1 = new ArrayList<Integer>();
getElement(list1);
Collection<String> list2 = new ArrayList<String>();
getElement(list2);
}
public static void getElement(Collection<?> coll){}
//?代表可以接收任意类型
tips:泛型不存在继承关系 Collection list = new ArrayList();这种是错误的。
通配符高级使用----受限泛型
之前设置泛型的时候,实际上是可以任意设置的,只要是类就可以设置。但是在JAVA的泛型中可以指定一个泛型的上限和下限。
泛型的上限:
- 格式:
类型名称 <? extends 类 > 对象名称 - 意义:
只能接收该类型及其子类
泛型的下限:
- 格式:
类型名称 <? super 类 > 对象名称 - 意义:
只能接收该类型及其父类型
比如:现已知Object类,String 类,Number类,Integer类,其中Number是Integer的父类
public static void main(String[] args) {
Collection<Integer> list1 = new ArrayList<Integer>();
Collection<String> list2 = new ArrayList<String>();
Collection<Number> list3 = new ArrayList<Number>();
Collection<Object> list4 = new ArrayList<Object>();
getElement(list1);
getElement(list2);//报错
getElement(list3);
getElement(list4);//报错
getElement2(list1);//报错
getElement2(list2);//报错
getElement2(list3);
getElement2(list4);
}
// 泛型的上限:此时的泛型?,必须是Number类型或者Number类型的子类
public static void getElement1(Collection<? extends Number> coll){}
// 泛型的下限:此时的泛型?,必须是Number类型或者Number类型的父类
public static void getElement2(Collection<? super Number> coll){}
数据结构
栈
- 栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对元素的存取有如下的特点
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
栈的入口、出口的都是栈的顶端位置。
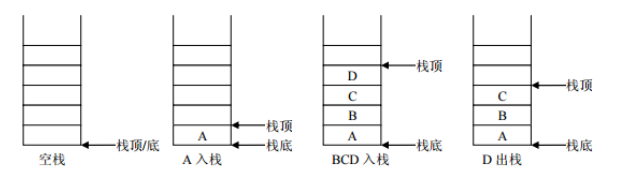
这里两个名词需要注意:
- 入栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
- 出栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
队列
- 队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。
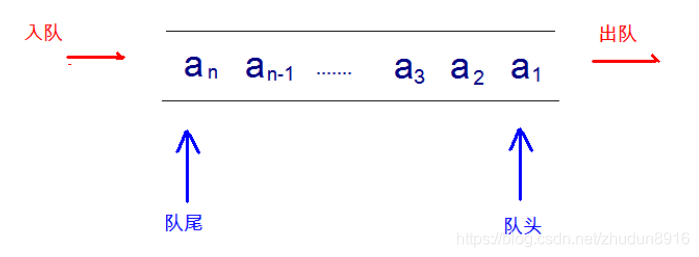
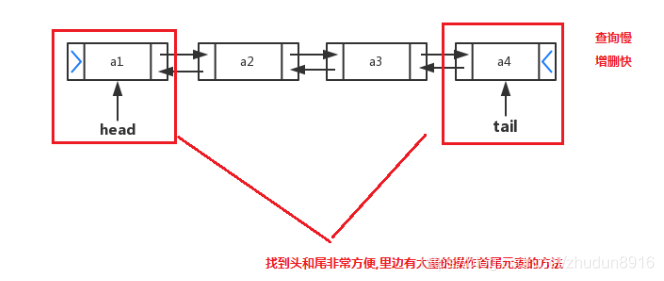
数组
- 数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
查找元素快:通过索引,可以快速访问指定位置的元素
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6pYjdwYe-1589437998090)(img/数组查询快.png)]](https://img-blog.csdnimg.cn/20200514143344865.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3podWR1bjg5MTY=,size_16,color_FFFFFF,t_70)
增删元素慢:数组的长度是固定的。想要增加删除一个元素,必须创建一个新数组,将原数组的数据复制进去
- 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。
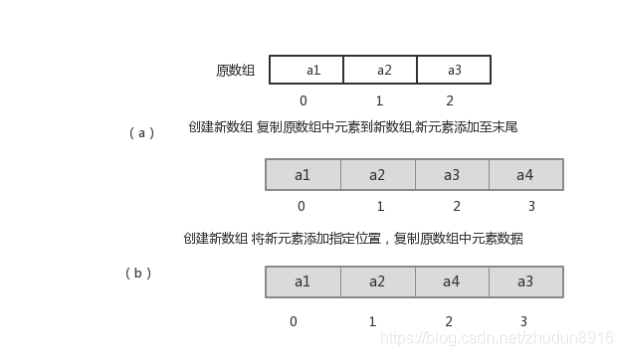
- 指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。

- 指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。
链表
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时i动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
单向链表 链表中只有一条链子,不能保证元素的顺序(存储元素和取出元素的性质有可能不一致)
双向链表 链表中有两条链子,有一条链子专门记录元素的顺序,是一个有序集合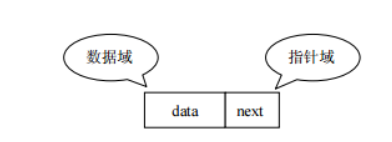
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
特点:
查询慢 :链表中的地址不是连续的,每次查询元素,都必须从头开始查询。
增删块 :链表结构,增加/删除一个元素,对链表的整体结构没有影响,所以增删块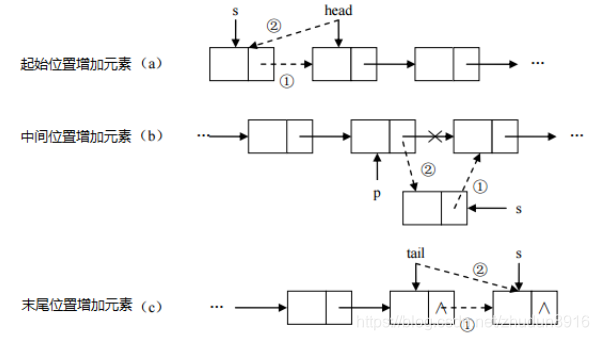
红黑树
- 二叉树:binary tree ,是每个结点不超过2的有序树(tree) 。
简单的理解,就是一种类似于我们生活中树的结构,只不过每个结点上都最多只能有两个子结点。
二叉树是每个节点最多有两个子树的树结构。顶上的叫根结点,两边被称作“左子树”和“右子树”。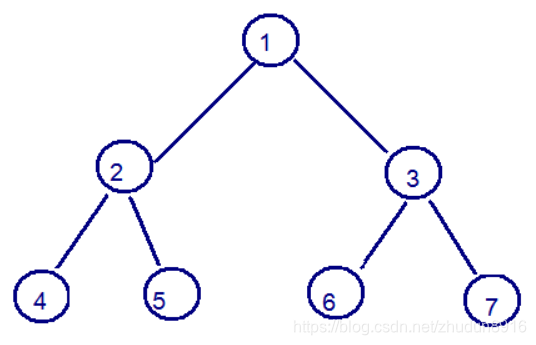
我们要说的是二叉树的一种比较有意思的叫做红黑树,红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树。也就意味着,树的键值仍然是有序的。
红黑树的约束:
- 节点可以是红色的或者黑色的
- 根节点是黑色的
- 叶子节点(特指空节点)是黑色的
- 每个红色节点的子节点都是黑色的
- 任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
红黑树的特点:
速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍
List集合
List接口特点:继承Collection集合
- 它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
List集合常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。public E get(int index):返回集合中指定位置的元素。public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
List集合特有的方法都是跟索引相关,我们在基础班都学习过,那么我们再来复习一遍吧:
public class ListDemo {
public static void main(String[] args) {
// 创建List集合对象
List<String> list = new ArrayList<String>();
// 往 尾部添加 指定元素
list.add("图图");
list.add("小美");
list.add("不高兴");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"没头脑");
System.out.println(list);
// String remove(int index) 删除指定位置元素 返回被删除元素
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 进行 元素替代(改)
// 修改指定位置元素
list.set(0, "三毛");
System.out.println(list);
// String get(int index) 获取指定位置元素
// 跟size() 方法一起用 来 遍历的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//还可以使用增强for
for (String string : list) {
System.out.println(string);
}
}
}
Arraylist集合
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
许多程序员开发时非常随意地使用ArrayList完成任何需求,并不严谨,这种用法是不提倡的。
LinkedList集合
java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
特点:
- 底层是一个链表结构所以查询慢,增删块
- 里面包含大量操作收尾元素的方法
LinkedList是一个双向链表,那么双向链表是什么样子的呢,我们用个图了解下
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法我们作为了解即可:
public void addFirst(E e):将指定元素插入此列表的开头。public void addLast(E e):将指定元素添加到此列表的结尾。public E getFirst():返回此列表的第一个元素。public E getLast():返回此列表的最后一个元素。public E removeFirst():移除并返回此列表的第一个元素。public E removeLast():移除并返回此列表的最后一个元素。public E pop():从此列表所表示的堆栈处弹出一个元素。public void push(E e):将元素推入此列表所表示的堆栈。public boolean isEmpty():如果列表不包含元素,则返回true。
LinkedList是List的子类,List中的方法LinkedList都是可以使用,这里就不做详细介绍,我们只需要了解LinkedList的特有方法即可。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。(了解即可)
方法演示:
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<String> link = new LinkedList<String>();
//添加元素
link.addFirst("abc1");
link.addFirst("abc2");
link.addFirst("abc3");
System.out.println(link);
// 获取元素
System.out.println(link.getFirst());
System.out.println(link.getLast());
// 删除元素
System.out.println(link.removeFirst());
System.out.println(link.removeLast());
while (!link.isEmpty()) { //判断集合是否为空
System.out.println(link.pop()); //弹出集合中的栈顶元素
}
System.out.println(link);
}
}
Vector集合
过时,简要了解
Set集合
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口中元素无序,并且都会以某种规则保证存入的元素不出现重复。
Set接口特点:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
Set集合有多个子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet这两个集合。
HashSet集合
特点:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
- 是一个无序的集合,存储元素和取出元素的顺序可能不一样
- 底层是一个哈希表结构(查询速度非常的快)
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。java.util.HashSet底层的实现其实是一个java.util.HashMap支持,由于我们暂时还未学习,先做了解。
HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。
我们先来使用一下Set集合存储,看下现象,再进行原理的讲解:
public class HashSetDemo {
public static void main(String[] args) {
//创建 Set集合
HashSet<String> set = new HashSet<String>();
//添加元素
set.add(new String("cba"));
set.add("abc");
set.add("bac");
set.add("cba");
//遍历
for (String name : set) {
System.out.println(name);
}
}
}
输出结果如下,说明集合中不能存储重复元素:
cba
abc
bac
tips:根据结果我们发现字符串"cba"只存储了一个,也就是说重复的元素set集合不存储。
哈希值
哈希值:是一个十进制的整数。由系统随机给出 (就是对象的地址,是一个逻辑地址,是模拟出来的得到的地址,不是实际存储的物理地址,在object类有一个方法,可以获得对象的哈希值)
int hashCode()
HashSet集合存储数据的结构
JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。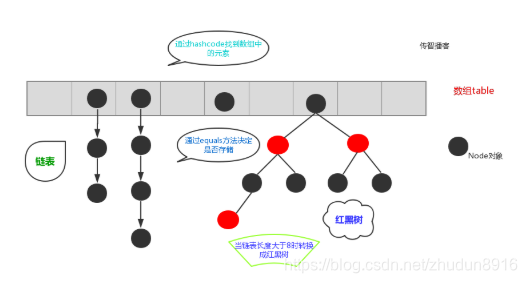
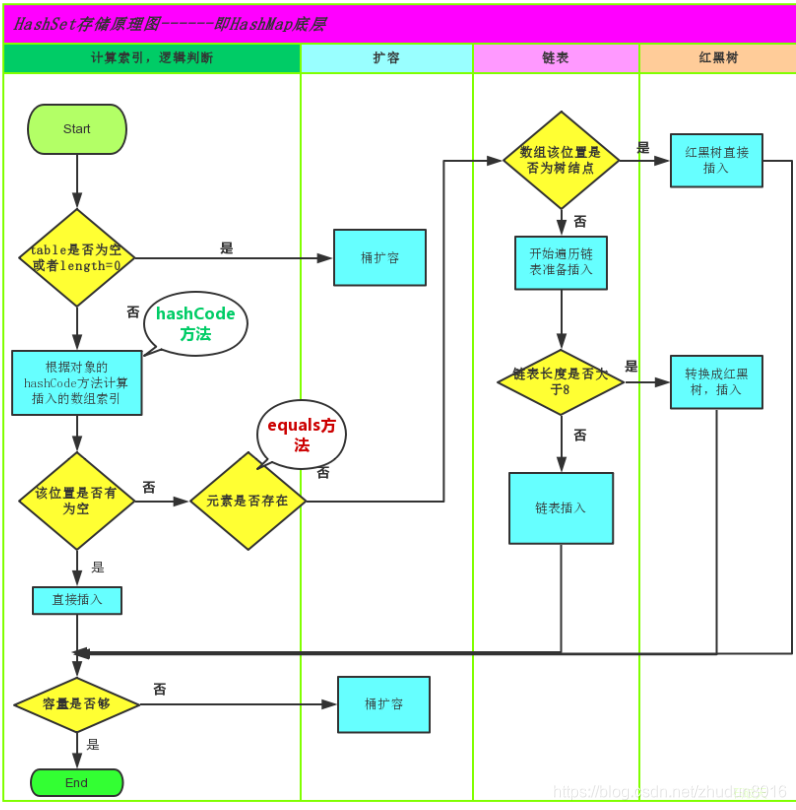
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
HashSet存储自定义元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一
创建自定义Student类
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
public class HashSetDemo2 {
public static void main(String[] args) {
//创建集合对象 该集合中存储 Student类型对象
HashSet<Student> stuSet = new HashSet<Student>();
//存储
Student stu = new Student("于谦", 43);
stuSet.add(stu);
stuSet.add(new Student("郭德纲", 44));
stuSet.add(new Student("于谦", 43));
stuSet.add(new Student("郭麒麟", 23));
stuSet.add(stu);
for (Student stu2 : stuSet) {
System.out.println(stu2);
}
}
}
执行结果:
Student [name=郭德纲, age=44]
Student [name=于谦, age=43]
Student [name=郭麒麟, age=23]
LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。
演示代码如下:
public class LinkedHashSetDemo {
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<String>();
set.add("bbb");
set.add("aaa");
set.add("abc");
set.add("bbc");
Iterator<String> it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
结果:
bbb
aaa
abc
bbc
可变参数
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化成如下格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ }
其实这个书写完全等价与
修饰符 返回值类型 方法名(参数类型[] 形参名){ }
只是后面这种定义,在调用时必须传递数组,而前者可以直接传递数据即可。
JDK1.5以后。出现了简化操作。… 用在参数上,称之为可变参数。
同样是代表数组,但是在调用这个带有可变参数的方法时,不用创建数组(这就是简单之处),直接将数组中的元素作为实际参数进行传递,其实编译成的class文件,将这些元素先封装到一个数组中,在进行传递。这些动作都在编译.class文件时,自动完成了。
代码演示:
public class ChangeArgs {
public static void main(String[] args) {
int[] arr = { 1, 4, 62, 431, 2 };
int sum = getSum(arr);
System.out.println(sum);
// 6 7 2 12 2121
// 求 这几个元素和 6 7 2 12 2121
int sum2 = getSum(6, 7, 2, 12, 2121);
System.out.println(sum2);
}
/*
* 完成数组 所有元素的求和 原始写法
public static int getSum(int[] arr){
int sum = 0;
for(int a : arr){
sum += a;
}
return sum;
}
*/
//可变参数写法
public static int getSum(int... arr) {
int sum = 0;
for (int a : arr) {
sum += a;
}
return sum;
}
}
tips: 上述add方法在同一个类中,只能存在一个。因为会发生调用的不确定性
注意:如果在方法书写时,这个方法拥有多参数,参数中包含可变参数,可变参数一定要写在参数列表的末尾位置。
Collections
Collections集合工具类的方法
java.utils.Collections是集合工具类,用来对集合进行操作。部分方法如下:
public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。public static void shuffle(List<?> list) 打乱顺序:打乱集合顺序。public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。
代码演示:
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
//原来写法
//list.add(12);
//list.add(14);
//list.add(15);
//list.add(1000);
//采用工具类 完成 往集合中添加元素
Collections.addAll(list, 5, 222, 1,2);
System.out.println(list);
//排序方法
Collections.sort(list);
System.out.println(list);
}
}
结果:
[5, 222, 1, 2]
[1, 2, 5, 222]
注意:sort(list List)使用前提
被排序的集合里面存储的元素,必须实现Comparable,重写接口中的方法compareTo定义的排序规则
规则:
自己(this)-参数:升序
参数-this:降序
代码演示之后 ,发现我们的集合按照顺序进行了排列,可是这样的顺序是采用默认的顺序,如果想要指定顺序那该怎么办呢?
我们发现还有个方法没有讲,public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。接下来讲解一下指定规则的排列。
Comparator比较器
public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。
public static <T> void sort(List<T> list,Comparator<? super T> )方法灵活的完成,这个里面就涉及到了Comparator这个接口,位于位于java.util包下,排序是comparator能实现的功能之一,该接口代表一个比较器,比较器具有可比性!顾名思义就是做排序的,通俗地讲需要比较两个对象谁排在前谁排在后,那么比较的方法就是:
public int compare(String o1, String o2):比较其两个参数的顺序。两个对象比较的结果有三种:大于,等于,小于。
如果要按照升序排序,
则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数)
如果要按照降序排序
则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
操作如下:
public class CollectionsDemo3 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
//排序方法 按照第一个单词的降序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.charAt(0) - o1.charAt(0);
}
});
System.out.println(list);
}
}
结果如下:
[sba, nba, cba, aba]
Comparable和Comparator的区别
Comparable:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。只能在类中实现compareTo()一次,不能经常修改类的代码实现自己想要的排序。实现此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进行自动排序,对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
Comparator强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构(如有序set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
如果在使用的时候,想要独立的定义规则去使用 可以采用Collections.sort(List list,Comparetor c)方式,自己定义规则:
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.getAge()-o1.getAge();//以学生的年龄降序
}
});
效果:
Student{name='rose', age=18}
Student{name='ace', age=17}
Student{name='jack', age=16}
Student{name='abc', age=16}
Student{name='mark', age=16}
如果想要规则更多一些,可以参考下面代码:
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
// 年龄降序
int result = o2.getAge()-o1.getAge();//年龄降序
if(result==0){//第一个规则判断完了 下一个规则 姓名的首字母 升序
result = o1.getName().charAt(0)-o2.getName().charAt(0);
}
return result;
}
});
效果如下:
Student{name='rose', age=18}
Student{name='ace', age=17}
Student{name='abc', age=16}
Student{name='jack', age=16}
Student{name='mark', age=16}
Debug追踪

1、Debugger:debug的面板,查看各类东西
2、Console:控制台,查看日志
3、Show Execution Point:单击后跳到此次debug最后执行位置。方便你一顿操作后不知道现在执行到哪个点了。当然,点击Frames最顶那行,也能回到最后位置。
4、Step Over:下一步(遇到调用方法不进入)
5、Step Into:进里面(如果同行有多个可以进入的,会让你移动光标选择进入的方法)
6、Force Step Into:强制进入下一步,不管是什么方法,即使是jdk封装的方法,也会进入
7、Step Out:跳出方法
8、Drop Frame:这是个非常高科技的按钮,是后悔药。详细在后面的调试技巧里讲
9、Run to Cursor:运行直到停在光标处(前提是光标前方无断点),方便的功能,可以不打断点停住
10、Evaluate Expression:计算表达式的值,跟watch不同,这是临时的
11、Trace Current Stream Chain:未知
12、Frames:栈的相关信息,如线程信息,调用链。详情见后 “Frames”
13、线程的信息,打钩是当前线程,下拉可以看到其他线程信息。详情见后 “Frames”
14、调用链的信息,指示是怎么调用到当前断点的,双击可以进入对应的代码。详情见后 “Frames”
15、Return:重新跑一遍debug
16、Resume Program:眼睛一闭运行,直到结束或者遇到下一个断点
17、Pause Program:未知,没用过,不重要
18、Stop:停止debug
19、View Breakpoints:查看所有断点。详细请看后面的 “View Breakpoints”
20、Mute Breakpoints:静音所有断点。可以这么用:不想再在之后的断点中停住,可以点击该按钮运行剩下的代码
21、Get Thread Dump:未知,看名字就是得到线程的Dump文件,可以分析内存情况吧
22、Settings:做一些配置。详细见后续 “Settings”
23、Pin Tab:钉住最前。似乎没什么用,从来不会被遮挡呀。
24、Watch的面板:展示表达式的值的面板,比起Evaluate Expression,可以长久出现,不像Evaluate是临时性查看,下一次debug就没了
25、New Watch:新增watch表达式:可以不在debug过程增加的,也可以右键选择表达式后Add to Watches(这个菜单只有在debug过程才会出现)
26、Remove Watch:删除watch表达式
27、Move Watch Up:上移调序
28、Move Watch Down:下移调序
29、Duplicate Watch:复制一份
30、Show watches in variables tab:在变量的tab页中显示watch表达式。非debug的状态下点击这个图标似乎无反应,只有debug时你会发现变化
31、Layout Settings:设置layout,所谓layout就是那些小面板。可以增加想要的layout,自己搞乱了layout也可以恢复默认。详细见后续 “Layout Settings”
Map集合
map结合概述
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map接口。
我们通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同,如下图。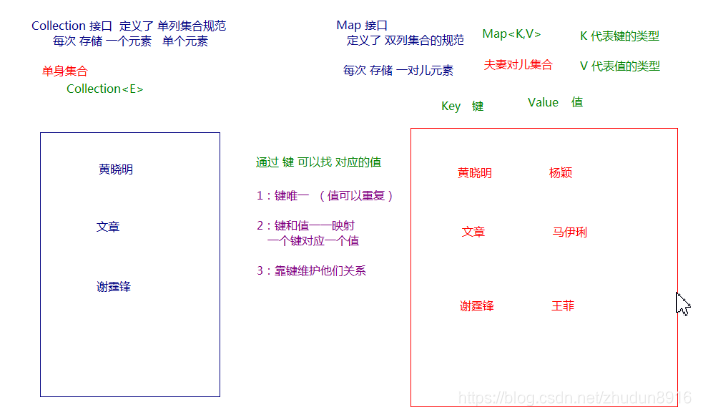
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。Collection中的集合称为单列集合,Map中的集合称为双列集合。- 需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
Map结合的特点:
- Map结合是一个双列集合,一个元素包含两个值(一个key,一个value)
- Map集合中的元素,key和value的数据类型可以相同,也可以不同
- Map集合中的元素,key是不允许重复的,value是可以重复的
- Map集合中的元素,Key和value是一一对应
Map常用子类
通过查看Map接口描述,看到Map有多个子类,这里我们主要讲解常用的HashMap集合、LinkedHashMap集合。
HashMap<K,V>:存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
特点:
底层是哈希表,查询速度快
一个无序的集合LinkedHashMap<K,V>:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
特点:
一个有序的集合
tips:Map接口中的集合都有两个泛型变量<K,V>,在使用时,要为两个泛型变量赋予数据类型。两个泛型变量<K,V>的数据类型可以相同,也可以不同。
Map接口中的常应方法
Map接口中定义了很多方法,常用的如下:
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。
返回值 v :
存储键值对的时候,key值不重复,返回值v是null
存储键值对的时候,key重复会使用新的value替换map中的value,返回被替换的value值public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。public V get(Object key)根据指定的键,在Map集合中获取对应的值。boolean containsKey(Object key)判断集合中是否包含指定的键。public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
Map接口的方法演示
public class MapDemo {
public static void main(String[] args) {
//创建 map对象
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
System.out.println(map);
//String remove(String key)
System.out.println(map.remove("邓超"));
System.out.println(map);
// 想要查看 黄晓明的媳妇 是谁
System.out.println(map.get("黄晓明"));
System.out.println(map.get("邓超"));
}
}
Map集合遍历键找值的方式
键找值方式:即通过元素中的键,获取键所对应的值
分析步骤:
- 获取Map中所有的键,由于键是唯一的,所以返回一个Set集合存储所有的键。方法提示:
keyset() - 遍历键的Set集合,得到每一个键。
- 根据键,获取键所对应的值。方法提示:
get(K key)
代码演示:
public class MapDemo01 {
public static void main(String[] args) {
//创建Map集合对象
HashMap<String, String> map = new HashMap<String,String>();
//添加元素到集合
map.put("胡歌", "霍建华");
map.put("郭德纲", "于谦");
map.put("薛之谦", "大张伟");
//获取所有的键 获取键集
Set<String> keys = map.keySet();
// 遍历键集 得到 每一个键
for (String key : keys) {
//key 就是键
//获取对应值
String value = map.get(key);
System.out.println(key+"的CP是:"+value);
}
}
}
遍历图解: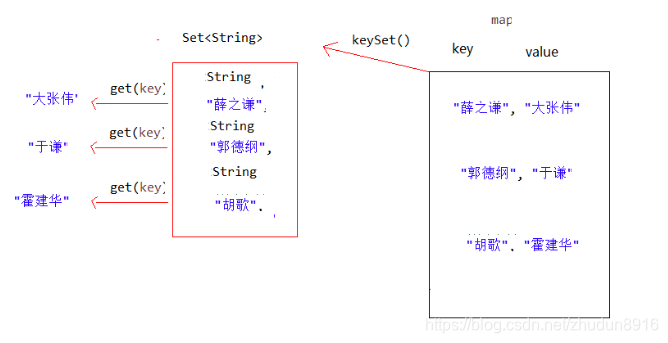
Entry键值对像
我们已经知道,Map中存放的是两种对象,一种称为key(键),一种称为value(值),它们在在Map中是一一对应关系,这一对对象又称做Map中的一个Entry(项)。Entry将键值对的对应关系封装成了对象。即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
既然Entry表示了一对键和值,那么也同样提供了获取对应键和对应值得方法:
public K getKey():获取Entry对象中的键。public V getValue():获取Entry对象中的值。
在Map集合中也提供了获取所有Entry对象的方法:
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
Map集合遍历键值对的方式
键值对方式:即通过集合中每个键值对(Entry)对象,获取键值对(Entry)对象中的键与值。
操作步骤与图解:
获取Map集合中,所有的键值对(Entry)对象,以Set集合形式返回。方法提示:
entrySet()。遍历包含键值对(Entry)对象的Set集合,得到每一个键值对(Entry)对象。
通过键值对(Entry)对象,获取Entry对象中的键与值。 方法提示:
getkey() getValue()
public class MapDemo02 {
public static void main(String[] args) {
// 创建Map集合对象
HashMap<String, String> map = new HashMap<String,String>();
// 添加元素到集合
map.put("胡歌", "霍建华");
map.put("郭德纲", "于谦");
map.put("薛之谦", "大张伟");
// 获取 所有的 entry对象 entrySet
Set<Entry<String,String>> entrySet = map.entrySet();
// 遍历得到每一个entry对象
for (Entry<String, String> entry : entrySet) {
// 解析
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"的CP是:"+value);
}
}
}
遍历图解:
tips:Map集合不能直接使用迭代器或者foreach进行遍历。但是转成Set之后就可以使用了。
HashMap存储自定义类型的键值
练习:每位学生(姓名,年龄)都有自己的家庭住址。那么,既然有对应关系,则将学生对象和家庭住址存储到map集合中。学生作为键, 家庭住址作为值。
注意,学生姓名相同并且年龄相同视为同一名学生。
编写学生类:
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
编写测试类:
public class HashMapTest {
public static void main(String[] args) {
//1,创建Hashmap集合对象。
Map<Student,String>map = new HashMap<Student,String>();
//2,添加元素。
map.put(newStudent("lisi",28), "上海");
map.put(newStudent("wangwu",22), "北京");
map.put(newStudent("zhaoliu",24), "成都");
map.put(newStudent("zhouqi",25), "广州");
map.put(newStudent("wangwu",22), "南京");
//3,取出元素。键找值方式
Set<Student>keySet = map.keySet();
for(Student key: keySet){
Stringvalue = map.get(key);
System.out.println(key.toString()+"....."+value);
}
}
}
- 当给HashMap中存放自定义对象时,如果自定义对象作为key存在,这时要保证对象唯一,必须复写对象的hashCode和equals方法(如果忘记,请回顾HashSet存放自定义对象)。
- 如果要保证map中存放的key和取出的顺序一致,可以使用
java.util.LinkedHashMap集合来存放。
LinkedHashMap集合
我们知道HashMap保证成对元素唯一,并且查询速度很快,可是成对元素存放进去是没有顺序的,那么我们要保证有序,还要速度快怎么办呢?
在HashMap下面有一个子类LinkedHashMap,它是链表和哈希表组合的一个数据存储结构。
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<String, String> map = new LinkedHashMap<String, String>();
map.put("邓超", "孙俪");
map.put("李晨", "范冰冰");
map.put("刘德华", "朱丽倩");
Set<Entry<String, String>> entrySet = map.entrySet();
for (Entry<String, String> entry : entrySet) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
}
结果:
邓超 孙俪
李晨 范冰冰
刘德华 朱丽倩
Hashtable
了解就好
Map集合练习
/*
* 计算一个字符串中每个字符出现次数。
* */
public class test {
public static void main(String[] args) {
HashMap<Character,Integer> map = new HashMap<>();
Scanner scanner = new Scanner(System.in);
String input = scanner.next();
char[] chars = input.toCharArray();
for (int i = 0; i < chars.length; i++) {
if(map.containsKey(chars[i])){
map.put(chars[i],map.get(chars[i])+1);
}else {
map.put(chars[i],1);
}
}
System.out.println(map);
}
}
jdk9对集合添加的优化方法-of方法
通常,我们在代码中创建一个集合(例如,List 或 Set ),并直接用一些元素填充它。 实例化集合,几个 add方法 调用,使得代码重复。
public class Demo01 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("abc");
list.add("def");
list.add("ghi");
System.out.println(list);
}
}
Java 9,添加了几种集合工厂方法,更方便创建少量元素的集合、map实例。新的List、Set、Map的静态工厂方法可以更方便地创建集合的不可变实例。
例子:
public class HelloJDK9 {
public static void main(String[] args) {
Set<String> str1=Set.of("a","b","c");
//str1.add("c");这里编译的时候不会错,但是执行的时候会报错,因为是不可变的集合
System.out.println(str1);
Map<String,Integer> str2=Map.of("a",1,"b",2);
System.out.println(str2);
List<String> str3=List.of("a","b");
System.out.println(str3);
}
}
需要注意以下两点:
1:of()方法只是Map,List,Set这三个接口的静态方法,其父类接口和子类实现并没有这类方法,比如 HashSet,ArrayList等待;
2:返回的集合是不可变的;
线程
创建线程类
线程安全
如果有多个线程在同时运行,而这些线程可能会同时运行这段代码。程序每次运行结果和单线程运行的结果是一样 的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
我们通过一个案例,演示线程的安全问题:
电影院要卖票,我们模拟电影院的卖票过程。假设要播放的电影是 “葫芦娃大战奥特曼”,本次电影的座位共100个 (本场电影只能卖100张票)。 我们来模拟电影院的售票窗口,实现多个窗口同时卖 “葫芦娃大战奥特曼”这场电影票(多个窗口一起卖这100张票) 需要窗口,采用线程对象来模拟;需要票,Runnable接口子类来模拟