我们的任务是对未来某一天的话务量进行预测(可能是普通工作日,或者节假日)。
其实在项目中最初的任务就是对当年的清明节的话务量进行预测,对于这种一年才会发生一次的时间,我们肯定是需要从往年的该时间段发现有效的Pattern。
其实这种方法也适用于平时话务量的预测,因为每天都有自己的Pattern——星期几,或者这个月的几号。所以我们下面阐述的方法也适用于平时话务量的预测。
还要交代一下的就是,时间序列的预测往往还强调“在线”性,比如股票价格预测,我们说预测明天股价最有用的信息很可能就是今天的股价,所以今天的股价对模型进行Modify很重要。但是我们的话务预测往往不是这样,因为一天之内,我们往往很难对提供话务服务的基站进行有效的调控部署,所以在话务预测方面,预测未来较长时间某天的话务量往往是实际的需求(这也是ARIMA和HMM没有被采用的原因)。
一般做法
那么假设现在是2月1日,而我要预测4月5号(清明节)以及放假这三天全市所有小区的话务量。而我有的数据呢,是一年的话务量(即从去年2月份到今年二月份的话务量)。
其实一个通用的做法就是计算通过Ratio——待预测那一天的话务量和目前话务量的比例值来进行预测。
打个比方,我要预测4月5号的话务量,如果我可以计算出当天24个小时的话务量和去年清明节24个小时话务量的比例值,那么我就可以给出今年4月5号的话务量了。实践证明用比值的方法还是相当有效的。之前有人利用往年的Ratio值来作为今年的Ratio值,还是获得了不错的效果。
这里先给出我们话务预测的框架:
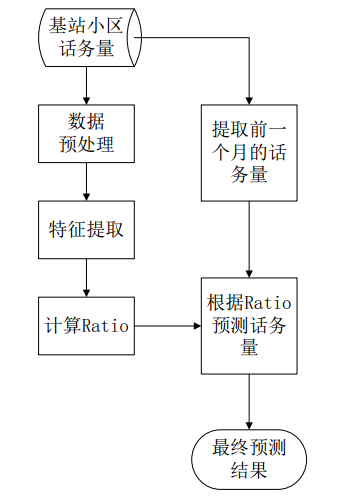
我的做法
但是,我并没有历年清明节的数据(因为话务量的数据量较大,所以网优部门只暂存一年的数据)。那么,我们的大体思路还是拿去年清明节的话务量*Ratio来预测今年清明节的话务量,但是Ratio的计算我们得想想办法了。
这里我们引入一个概念——“基础话务量”,这个量表示的是地区话务的基础水平。
打个比方,某小区有个广场,所以每到晚上,大妈们过来跳舞了,手机都带着,导致这个小区的话务量攀升了,或者过春节了,小区的人都回老家过年了,那么话务量会锐减。但是,我们说,随着时间的推移,该小区开通手机上网业务的人越来越多,不考虑哪些日常的波动,小区真正使用手机在上网的“基础”话务量是上升了的。
同样的道理,撇去各种变化因素,城市整体的话务量肯定有一个变化趋势,那么我们的Ratio肯定要把这个因素考虑进去。
第二,假设我要预测的是小区A的话务量,我仅仅用A小区的历史记录计算出来的Ratio作为A的Ratio吗,我们在实际中发现,这样做其实还是存在很大误差的,为了减少这种偶然性的偏差,我们采用这样的策略:找到和A比较相似的N个小区,然后用这N个小区Ratio的均值,作为A的Ratio值。
那怎么找最相似的N个小区呢,我们首先当然要提取特征了,然后再特征空间中使用KNN找出N个和他最近的小区,或者我们进行聚类,用该聚类的Ratio均值,作为A的Ratio。
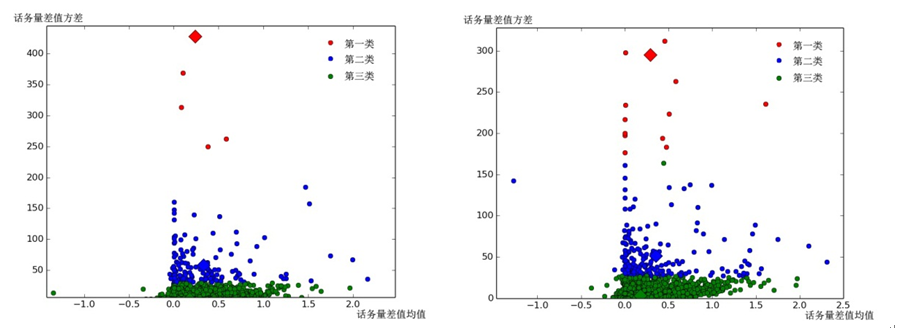
上图是我们利用话务量的均值和方差,作为两个特征,对不同的两个月的话务数据进行聚类的结果的观察(这边我们聚成3类),可以发现在不同时间,话务量在特征空间中的聚类特性变化不大,这也是为什么我们能够用KNN和K-means进行这样的分析(如果随着时间的推移,样本在特征空间中的分布变化很大,那么就拿聚类来说,这些样本到了下一期可能就不在一个聚类中了,那还谈何用该聚类的Ratio均值作为聚类中每个样本的Ratio呢)。
这了我们忽略了一个重要的细节——特征,下一节我们来看看,我们所使用的特征。