从一个经典的例子说起
假设某流行病的感染率为1% ,则未被感染者(健康人)的概率为99% ,记事件A为患病,记事件B为不患病 ,则有:
P(A) = 1% P(B) = 99%
病人去医院检测为阳性的概率为99%,健康人检测为阳性(误诊)的概率为1%,记X为事件检测为阳性,则有:
P(X|A)=99% P(X|B)=1%
现在有位同学去医院检测结果为阳性,那么问这位同学患病的概率是多少?
当我们不知道P(A) P(B)的情况下,直觉上会感觉大概率是患病了;反过来,如果这位同学没有去检测的话,即只知道P(A) P(B),我们会根据经验判断他大概率没有患病。
这里我们称P(A) P(B)为先验概率,P(X|A) P(X|B)为条件概率,X为观测值。则我们要求的结果为P(A|X),即观测为阳性的条件下患病的概率,P(A|X)称为后验概率。贝叶斯定理巧妙的结合了先验知识和观测值,得到最优的结果:
根据全概率公式:
带入则可得:P(A|X)=0.5,即该同学患病的概率实际为50%。
最小错误率贝叶斯决策
根据上述贝叶斯公式,我们可以设计出一个分类器:
其中
再举个例子说明这个贝叶斯公式是如何进行分类的:假如我们的任务是区分学校里的男生和女生,观测值为身高(即通过身高判断性别),那么给出一个样本的观测值
所谓最小错误率就是求解一种决策规则,使得分类的错误率最大,那么在给定观测值
最小风险贝叶斯决策
回到检测流行病的例子,假如我们设计了一个贝叶斯分类器,根据先验和观测值判断是否病,现在我们考虑错判的损失:如果我们将一个健康的人判断为患病,那么这个人会受到精神上不必要的压力,这可以理解为一种损失;但是,如果我们把一个病人错判为健康,继而错失了治疗的好时机,这个损失则更为严重。因此在上述贝叶斯公式计算得到的50%患病概率基础上,考虑使风险最小化,应当分为患病的类别。
引入损失函数
那么:
若
上面已经提到,贝叶斯决策需要用到先验概率和类条件概率密度
对概率密度函数是贝叶斯决策的核心,一般都是通过训练数据去估计。在流行病的例子中,
极大似然估计
- 适用于概率密度函数形式已知,参数未知且是一个固定值的情况,如概率密度函数为正态分布,但是
- 在有一定量的训练样本的前提下,我们可以通过这些样本去估计
对于N个训练样本的观测值
这个式子的含义是:在参数取值为
- 求解方法:带入样本观测值
贝叶斯估计
极大似然估计有什么不足?
上面提到,在训练样本很好的反应了该类的概率分布函数的前提下用最大似然估计去估计参数,但是这个前提一定可以保证么?比如我们抽样了五个女生测量身高,但是这五个女生身高都偏高(假设都是170cm),那么用这一组样本估计的
参数一定是固定形式的未知值吗?
极大似然估计假设待估计参数是一个固定且未知的值,是否可以将这个参数看也成一个遵循某种分布的随机变量?
回到测量身高判断性别的例子,男女生身高的概率密度函数都遵循正态分布,但是这个正态分布的均值参数还要受到地域、年级等因素的影响,考虑将参数看成遵循某种分布(如正态分布)的随机变量,比如对于女生而言,将其身高的正态分布参数
将参数看成随机变量的意义?
将
如果将参数看作随机变量,它的分布如何确定,如何理解?
如果认为待估计参数
引入先验之后怎么做?
参数
看起来根据这个参数先验分布
所以最后的结论是:贝叶斯估计的学习过程是根据训练样本对参数的先验分布的学习过程,使其不断的往真实的分布收敛,当样本量接近无穷时,可以无限逼近真实分布。
极大似然估计的计算复杂度比较低,在样本量充足的时候效果也非常好,但是在样本量不足时,由于贝叶斯估计引入了先验知识,并且采取对参数分布求期望的方式,效果更有保障。
贝叶斯估计的实现步骤
图片截自东南大学张敏灵老师PPT
- 根据训练样本D对参数的先验分布进一步学习,得到参数的后验分布
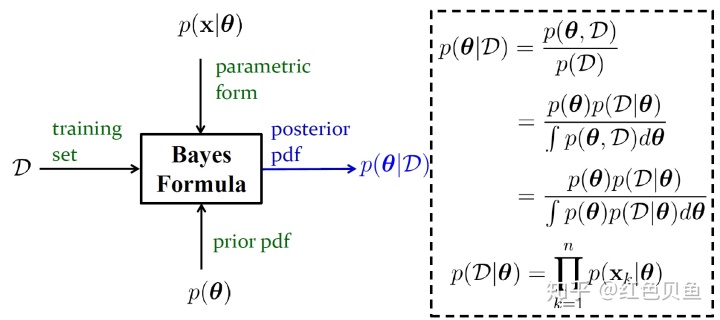
- 对参数的后验概率积分,得到类条件概率密度(此处是的缩写)

- 将类条件概率密度带入贝叶斯公式,得到后验概率,即决策结果