高级语法
1.封装性进阶
原先学习过对属性私有化,在类属性名前加双下划线(即__),只允许本类访问
class Computer(object):
"""
给类添加object
私有化属性 前边加__
setter和getter
"""
def __init__(self):
#私有化属性前边加__
self.__brand="DEll"
#setter方法
def set_brand(self,brand):
self.__brand=brand
#getter方法
def get_brand(self):
return self.__brand
#创建对象
computer=Computer()
computer.set_brand("huawei")
print(computer.get_brand())
(1)形式为“xxxx”或“xxxx()”为公有的,如:公有变量、公有方法,在外部可直接访问;
class Computer(object):
def __init__(self):
# 公有属性
self.brand = "小米"
self.size = 8
def show_info(self):
print("品牌名称:", self.brand)
print("内存大小:", self.size)
# 创建对象
computer = Computer()
# 访问属性 对象名.属性
print(computer.brand)
# 访问方法 对象名.方法()
computer.show_info()

(2)形式为“_xx”或“_xx()”–私有化[ 使用不多]。即前置单下划线,为私有化属性或方法,类对象和子类可以访问,且需要注意的是*若采用“from 模块名 import ”的形式导入不了该类私有化属性或方法
# coding:utf-8
class Computer(object):
def __init__(self):
# 私有属性
self.__price=2
def show_info(self):
print("私有属性:",self.__price)
def __fun(self):
print("--私有方法--")
# 创建对象
computer = Computer()
# 访问私有化属性 对象名._类名__属性名
print("名字重整的方式访问私有属性:",computer._Computer__price)
#访问私有方法
fun=computer._Computer__fun
fun()

(4)形式为“xx”或“xx()”即前后双下划线,通常为 Python 系统提供的属性、模块或魔法方法,如:main、init()等,建议开发者不要以这种形式命名
(5)形式为“xx_”或“xx_()”即后置单下划线,通常是开发者用于避免与 Python 关键字冲突而命名的。
# coding:utf-8
"""
标识符的命名规则:
1.由字母、数字、下划线组成;
2.不能使用关键字作为命名;
3.开头不能是数字;
4.区分大小写、对大小写敏感;
5.对长度没有限制。
"""
a = 100
print(a)
_else = 100
print(_else)
return_ = 90
print(return_)
2**.属性property**
开头说的setter和getter方法处理时不太方便.原因:获取属性值之前,需要先设置属性值。步骤:①设置属性值,setter;②获取属性值,getter。
首先,从一个自定义类 Student 说起,给该类的年龄属性进行封装,即写 getter 与 setter 方法,此时需要对年龄属性进行私有化。
class Student(object):
def __init__(self):
self.__age = 0
def set_age(self, age):
# if 0 <= age and age <= 140:
if 0 <= age <= 140:
self.__age = age
else:
self.__age = 0
# self.__age = age
def get_age(self):
return self.__age
# 使用 :创建对象
student = Student()
#设置属性
student.set_age(-18)
print("年龄值:",student.get_age())
可以使用一个较为简便的方式来升级上述案例并完成相同的功能,即使用 property(),语法格式如下:
公有属性名 = property(getter 方法名, setter 方法名)
class Student(object):
def __init__(self):
self.__age = 0
def set_age(self, age):
# if 0 <= age and age <= 140:
if 0 <= age <= 140:
self.__age = age
else:
self.__age = 0
# self.__age = age
def get_age(self):
return self.__age
#把setter getter方法的值放入一个公有属性中,property()
age=property(get_age,set_age)
# 使用 :创建对象
student = Student()
#设置属性 替换原来的student.set_age(-18)
student.age=-18
#获取时不用写student.get_age()
print("年龄值:",student.age)
property() 小知识
使用 property()升级 setter 与 getter 方法,其实内部真实的处理方式是:①当“student.age = 29”执行时(即形式为:对象名.公有属性名=值),内部会自动调用 setter 方法;②当“print(“property()升级后年龄值为:%d”%student.age)”执行时(即形式为:对象名.公有属性名),内部会自动调用 getter 方法。
@property
装饰器
@...
def 方法名():
代码
使用**@property可让setter与getter方法称为属性函数**,且可以对属性赋值时做必要的检查,并保证代码的简洁、清晰,它有两个主要作用(1)将 setter 与 getter 方法转换为只读方法;(2)重新实现一个属性的 setter 设置和 getter 读取方法,同时也可做为一个方法是否结束的判定,语法:
@property
def 方法名(self):
return ...
@方法名.setter
def 方法名(self,value):
...
注意,上述的语法格式中,方法名全部相同,在调用时,会把方法名当成一个共有属性名来调用
对象名.属性名 = 值 #注:属性名即为上述的方法名
# coding:utf-8
class Student(object):
def __init__(self):
self.__age = 0
@property
def age(self): #稍后调用age age是共有属性名
return self.__age
@age.setter
def age(self, value):
# if 0 <= age and age <= 140:
if 0 <= value <= 140:
self.__age = value
else:
self.__age = 0
# 使用 :创建对象
student = Student()
#设置属性
student.age=-18
print("年龄值:",student.age)
通过使用property后,可以命名相同的方法名,且调用时,会把该方法名当成是一个公有的属性名来使用。
动态语言
–静态语言(编译,再运行。C 语言、Java)、动态语言(在运行过程中,可以动态的添加属性、方法 --PHP、js、Python)
1.基本定义
动态语言的全称为"动态编程语言",这是高级程序设计语言的一个类别,已广泛应用于计算机科学领域。它是一类在程序执行时能够改变其结构的语言,如新的函数、属性,甚至能够引进新代码,同时已有的函数也能够被删除或有其他结构上的变化等。现如今,动态语言活跃于各类网站、博客、商业领域等,非常具有活力。例如,脚本语言 JavaScript(简称 JS)便是非常常见的一个动态语言–添加 table 表格 tr/tb,此外Python、PHP、Ruby等都属于动态语言,而开发者所熟知的 Java、C、C++等则不属于动态语言且是属于静态语言。
开始:java 源代码(.java 文件),使用 javac 命令进行编译(编译源文件),形成一个.class 文件,使用 java 命令运行(已编译成功的文件)。
通俗地说,动态语言其实可以理解为不需编译即可运行,且在运行过程中能动态的添加属性、方法等,而像Java、C、C++等语言,都需要先进行编译,只有编译成功后,才能运行,而运行过程中是不允许动态的对已编译好的属性、方法等进行随意修改或添加新属性、新方法。
2.添加属性
1.给对象添加属性
# coding:utf-8
class User(object):
#初始化属性
def __init__(self,name,age):
self.name=name
self.age=age
user=User("小明",18)
print(user.name)
#给对象添加属性
user.sex="男"
print("性别:",user.sex)

可以发现,User类中没有sex属性,但却可以在运行过程中动态的添加sex属性且能访问到,这既可以说是动态语言的一个魅力,也可以说是一个坑吧。这其实就是在动态地给实例添加属性内容。
2.给类添加属性
user2=User("王刚",16)
print(user2.sex)

从上边报错可以看出,User类中没有sex这个属性,user对象添加了sex属性,现在调用的是user2,user对象的sex属性对user2不起作用。
若要给User实例对象都加上sex属性,语法格式:
类名.新属性名 = 属性值
class User(object):
#初始化属性
def __init__(self,name,age):
self.name=name
self.age=age
#给类添加属性
User.sex="男"
#创建对象1
user1=User("小亮",22)
print(user1.sex)
user2=User("小刚",22)
print(user1.sex)

需要注意的是,若在调用新属性且没设置新的属性值时,则使用默认值;若在调用新属性且已设置新的属性值时,则使用已设置的值
3.添加方法
1.普通方法
# coding:utf-8
def show(self):
print("----普通方法----")
class User(object):
def start(self):
print("User类中的普通方法")
user=User()
user.start()
#添加
user.run=show
user.run()

run()方法不属于类或user对象,因此报错,若要解决,需要将run()方法添加到类User或user对象中。
# coding:utf-8
import types
def show(self):
print("----普通方法----")
class User(object):
def start(self):
print("User类中的普通方法")
user=User()
user.start()
#添加方法 添加到user对象中的方法名为run
user.run=types.MethodType(show,user)
#调用
user.run()

2.静态方法和类方法
对于 Python 中的静态方法(@staticmethod)与类方法(声明 @classmethod),则可以直接采用如下语法格式:
类名.方法名 = 静态方法名或类方法名
此外,还需注意的是,要定义静态方法时,需要使用@staticmethod 声明;要定义类方法时,需要使用@classmethod 声明。
# coding:utf-8
@staticmethod
def run():
print("静态方法 run()")
class User(object):
def start(self):
print("User类中的普通方法")
user=User()
user.start()
#添加方法 类名.方法名
User.run=run
#调用
User.run()
#对象名调用
user.run()

类方法:注意第一个参数是cls
# coding:utf-8
@classmethod
def run(cls):
print("类方法 run()")
class User(object):
def start(self):
print("User类中的普通方法")
user2=User()
user2.start()
#添加方法 类名.方法名
User.run=run
#调用
User.run()
#调用
user2.run()

相比于类似于 Python 的这类动态语言,静态语言更加严谨,下面来通俗的了解一下动态语言与静态语言的特性,如下:
1.动态语言:可以在程序运行过程中,动态的修改代码;
2.静态语言:首先要进行编译,在进行运行,当编译完成后就已确定好代码,在运行过程中不能随意修改代码。
若想要限制 Python 类能添加的属性,即限定外部只能动态的添加某些属性,此时就可以使用一个特殊的变量,那就是__slots__,该变量是一个元组(tuple)类型。
语法格式如下:–>在类中的第一个代码中,添加__slots__变量
__slots__ = ("属性名 1","属性名 2","属性名 3",...)
# coding:utf-8
class User(object):
#限定User只能添加name,age
__slots__ = ("name","age")
user=User()
user.name="小明"
user.age=18
user.sex="male"

3.删除属性
对于python动态语言的特性,也是可以删除属性的
del 对象名.属性名 #方式 1
delattr(对象名,"属性名") #方式 2 attribute
# coding:utf-8
class User(object):
def __init__(self):
self.name="小明"
self.age=18
user=User()
print(user.name)
print(user.age)
print("--------------")
#删除属性
# del user.name
delattr(user,"name")
print(user.age)
print(user.name)

生成器
在之前的学习过程中,我们了解到,通过列表生成式**(list)可以直接创建一个列表变量**(列表元素 1000 万)。但是,受到不同电脑硬件的限制(如:内存容量不足),列表容量通常是有限个的。而实际应用中,当创建了一个包含100 万个元素的列表时,不仅占用很大的存储空间,若仅仅只需要访问前几个元素,则后面绝大多数元素内容所占用的空间都极大的浪费了内存资源。
因此,若列表元素可以按照某种算法进行推算出来,那是否可以在循环过程中不断推算出后续的元素内容呢?此时,则不必要创建出完整的 list,从而大大节省内存空间。在 Python 中,这种一边循环一边计算的算法机制,就称为生成器(generator)。
1.创建生成器
# coding:utf-8
#列表推导式
lists=[x for x in range(5)]
print(lists)
#生成器
b=(x for x in range(5))
print(b)
 2.使用函数实现
2.使用函数实现
生成器(generator)功能非常强大,若推算的算法较为复杂,且使用 for 循环(斐波那契数列–递归)无法实现时,
还可使用函数来进行实现。比如,数学中特别著名的斐波那契数列(Fibonacci),除第一个数和第二个数外,任意数都由前两个数相加求和所得到的,数列如下:
0,1, 1, 2, 3, 5, 8, 13, 21, 34, …
# coding:utf-8
def feibo(a):
if a<=1:
return a
else:
#递归算法
return feibo(a-1)+feibo(a-2)
c=input("输入要输出几个斐波那契数列:")
lisa=[]
for i in range(int(c)):
lisa.append(feibo(i))
print(lisa)
#斐波那契数列求和
print(sum(lisa))

还可以写成:
# coding:utf-8
def feibo(n):
a = 0
b = 1
i = 0
alist=[]
while i < n:
print(b)
alist.append(b)
#斐波那契数列规则 1+1 2 1+2 3 2+3 5
a,b=b,a+b
i+=1
print(alist)
#生成器
feibo(6)
函数实际上定义了斐波那契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种四维其实非常类似于生成器(generator),而要把feibo函数编程生成器,只需要把上述程序稍加修改,将print(b)改为yield b即可
def feibo(n):
a = 0
b = 1
# 循环
i = 0
while i < n:
yield b
# 斐波那契数列规则 1+1 2 1+2 3 2+3 5
a, b = b, a + b
i += 1
# 生成器
print(feibo(6))
结果
3.访问生成器元素
data=[x for x in range(5)]
print(data)
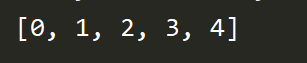
data=(x for x in range(5))
print(data)

区别在于最外层的[] () 中括号出来的是列表list,小括号是一个生成器(generator),直接打印生成器对象data,会发现打印出来的是generator类型与内存地址值,若需要打印元素值,可以使用next()函数
next(x) ---------获得 x 中的元素值,从初始元素开始依次获得,参数 x 表示生成器对象。
next(x) ---------获得 x 中的元素值,从初始元素开始依次获得,参数 x 表示生成器对象。
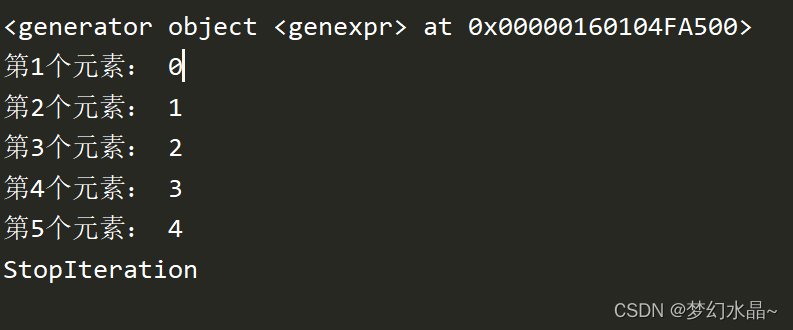
data=(x for x in range(5))
print(data)
try:
print("第1个元素:",next(data))
#print("第 1 个元素:", data.__next__())
print("第2个元素:",next(data))
#print("第 2 个元素:", data.__next__())
print("第3个元素:",next(data))
print("第4个元素:",next(data))
print("第5个元素:",next(data)) #取值完毕 下标越界 迭代(循环 遍历)
print("第6个元素:",next(data))
print("第7个元素:",next(data))
except Exception as error:
print("StopIteration")
上述案例的斐波那契数列:
# coding:utf-8
def feibo(n):
a = 0
b = 1
# 循环
i = 0
while i < n:
yield b
# 斐波那契数列规则 1+1 2 1+2 3 2+3 5
a, b = b, a + b
i += 1
# 生成器
print(feibo(6))
#生成器可以遍历输出值
for temp in feibo(6):
print(temp)

4.send()函数
# coding:utf-8
#使用while循环获得0-10之间的自然数
def loop(number):
i=0
while i < number:
print(i)
i+=1
print(loop(10))

send(s)-----用于设置 yield 后的返回值内容。–返回值内容就是 s
一般地,next(x)等同于 send(None);对于上述案例,temp 用于接收下次 data.send(“hello”)发送过来的值
# coding:utf-8
#使用while循环获得0-10之间的自然数
def loop(number):
i=0
while i < number:
# print(i) #存储到一个算法中
temp=yield i #把这个内容保存在一个变量中,输出变量
print("临时变量:",temp)
i+=1
# print(loop(10))
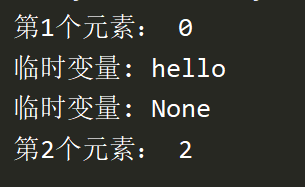
#变量
datas=loop(10)
#获取元素用next()
print("第1个元素:",next(datas))
#默认调用send(None)
datas.send("hello")
print("第2个元素:",next(datas))
对于生成器,在这里,还需要注意:
(1)生成器是一个能记住上一次返回时在函数体中具体位置的函数;–算法
(2)使用生成器可节约内存资源,不至于大大浪费内存空间;–所有数据存在了一套算法中,若要获取数据元素,则可以通过算法快速获得 next()、next()
(3)对生成器遍历到下一次的调用(如:next())时,所使用的参数都是第 1 次调用时所留下的,即是在整个所有函数调用的参数都是第 1 次所调用时留下的,而不是重新创建的。