展开全部
楼主你好,很高兴能回答你这个很有挑战性的问题,首先我谈谈我对上面9个例e69da5e6ba9062616964757a686964616f31333262373265子的理解,即这个方法应该实现的功能:
这个方法与JDK String原有的方法substring是有区别的,在这个方法里,一个中文汉字相当于占2个英文字符的位置。而且根据方法传入的参数pStart和pEnd在返回相应的子字符串child
如果pstart刚好在某个汉字的前半部分,则child应包含该汉字,在后部分则不含。与之相对应的是pEnd如果在某个汉字的后半部分,则child应含该汉字,否则不包含,如果pStart超出pStr的长度(这里一个汉字长度算2),则返回空,其他性质和JDK的性质形同。
如果觉得我的理解不错,且看下面的代码:
public class Test{
public Test(){
String str="ABCDE";
String str2="ABC你D";
String str3="A你B好C吗勇DE";
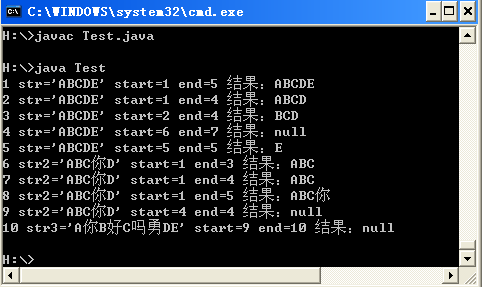
System.out.println("1 str='ABCDE' start=1 end=5 结果:"+getSubString(str,1,5));
System.out.println("2 str='ABCDE' start=1 end=4 结果:"+getSubString(str,1,4));
System.out.println("3 str='ABCDE' start=2 end=4 结果:"+getSubString(str,2,4));
System.out.println("4 str='ABCDE' start=6 end=7 结果:"+getSubString(str,6,7));
System.out.println("5 str='ABCDE' start=5 end=5 结果:"+getSubString(str,5,5));
System.out.println("6 str2='ABC你D' start=1 end=3 结果:"+getSubString(str2,1,3));
System.out.println("7 str2='ABC你D' start=1 end=4 结果:"+getSubString(str2,1,4));
System.out.println("8 str2='ABC你D' start=1 end=5 结果:"+getSubString(str2,1,5));
System.out.println("9 str2='ABC你D' start=4 end=4 结果:"+getSubString(str2,4,4));
System.out.println("10 str3='A你B好C吗勇DE' start=9 end=10 结果:"+getSubString(str3,9,10));
}
public static void main(String args[]){
new Test();
}
public String getSubString(String str,int pstart,int pend){
String resu="";
int beg=0;
int end=0;
int count1=0;
char[] temp=new char[str.length()];
str.getChars(0,str.length(),temp,0);
boolean[] bol=new boolean[str.length()];
for(int i=0;i
bol[i]=false;
if((int)temp[i]>255){//说明是中文
count1++;
bol[i]=true;
}
}
if(pstart>str.length()+count1){
resu=null;
}
if(pstart>pend){
resu=null;
}
if(pstart<1){
beg=0;
}else{
beg=pstart-1;
}
if(pend>str.length()+count1){
end=str.length()+count1;
}else{
end=pend;//在substring的末尾一样
}
//下面开始求应该返回的字符串
if(resu!=null){
if(beg==end){
int count=0;
if(beg==0){
if(bol[0]==true)
resu=null;
else
resu=new String(temp,0,1);
}else{
int len=beg;//zheli
for(int y=0;y
if(bol[y]==true)
count++;
len--;//想明白为什么len--
}
//for循环运行完毕后,len的值就代表在正常字符串中,目标beg的上一字符的索引值
if(count==0){//说明前面没有中文
if((int)temp[beg]>255)//说明自己是中文
resu=null;//返回空
else
resu=new String(temp,beg,1);
}else{//前面有中文,那么一个中文应与2个字符相对
if((int)temp[len+1]>255)//说明自己是中文
resu=null;//返回空
else
resu=new String(temp,len+1,1);
}
}
}else{//下面是正常情况下的比较
int temSt=beg;
int temEd=end-1;//这里减掉一
for(int i=0;i
if(bol[i]==true)
temSt--;
}//循环完毕后temSt表示前字符的正常索引
for(int j=0;j
if(bol[j]==true)
temEd--;
}//循环完毕后temEd-1表示最后字符的正常索引
if(bol[temSt]==true)//说明是字符,说明索引本身是汉字的后半部分,那么应该是不能取的
{
int cont=0;
for(int i=0;i<=temSt;i++){
cont++;
if(bol[i]==true)
cont++;
}
if(pstart==cont)//是偶数不应包含,如果pstart
temSt++;//从下一位开始
}
if(bol[temEd]==true){//因为temEd表示substring 的最面参数,此处是一个汉字,下面要确定是否应该含这个汉字
int cont=0;
for(int i=0;i<=temEd;i++){
cont++;
if(bol[i]==true)
cont++;
}
if(pend
temEd--;//所以只取到前一个
}
if(temSt==temEd){
resu=new String(temp,temSt,1);
}else if(temSt>temEd){
resu=null;
}else{
resu=str.substring(temSt,temEd+1);
}
}
}
return resu;//返回结果
}
}
测试结果如图,并且可以任意修改字符串,保证结果正确。
That's all !