Colored Point Cloud Completion for a Head Using Adversarial Rendered Image Loss
使用对抗性渲染损失补全头部彩色点云

Paper:Colored Point Cloud Completion for a Head Using Adversarial Rendered Image Loss (nih.gov)
对于黑色头发等深色头发,单个RGB深度相机容易因为遮挡而导致深度测量失败。本文提出了彩色点云补全方法,基于CD距离和EMD距离提出色差损失,并运用和Lab深度图像间的对抗损失提升视觉质量。
主动三维测量得方法用于黑色头发上时,由于头发呈现黑色,光脉冲将会被悉数吸收;而被动三维测量的方法,从多幅图像中搜索特征点是一件有困难的事。
介绍:
对点云数据的深度学习处理,除了熟知的PointNet和PointNet++以外,动态图卷积神经网络(DGCNN)对特征空间中得K邻域数据进行图卷积,点体素CNN(PVCNN)使用PVConv网络,是点云和基于体素方法得结。PVConv使用3DCNN在不增加体素分辨率得情况下对点云进行内部体素化和卷积,其以低延迟和低图形处理单元内存使用率实现了高精度的零件分割。
相关工作:
FoldNet不使用全连接层,而是通过逐步折叠将二维网格坐标转换为点云曲面。PCN使用PointNet和驻点最大池化,解码使用全连接解码和基于折叠的解码。变形和采样网络MSN使用基于折叠的方法为中间输出生成多个缝补点云,因此能够处理由单个网格折叠难以实现的复杂形状,最终的补全输出由中间输出点云和输入点云结合后进行下采样而均匀分布,并最终使用残差网络进行精细化。SparseNet在其编码和残差网络中使用信道关注edgeConv,基于变形的解码器使用基于样式的点生成,其灵感来自GAN;并用可微分点渲染将输出点云转换为深度图像,并使用基于CNN的鉴别器进行对抗性学习。Cycle4completion从两个方向进行点云补全。Point2color能估计没有颜色的点云信息,网络使用PointNet++进行着色。
数据集:
结合人脸3D数据集(FaceScape)和发型数据集(USC-HairSalon)而得。人脸数据集中含847张脸,每张脸记录20中不同的面部表情。数据集中由五个表达式:中性、张嘴、左下巴、嘴唇和闭眼。USC-HairSalon中共有343种发型,使用HairNet进行数据集扩展。面部和发型使用3DGC软件Blender进行组合。
网络结构:
编码器和残差网络使用PVConv,使用PVConv进行卷积,提取全局特征和差异信息;解码器使用SpareNet中基于样式的折叠层。使用GAN进行训练,并将SpareNet修改用于渲染Lad深度图像。
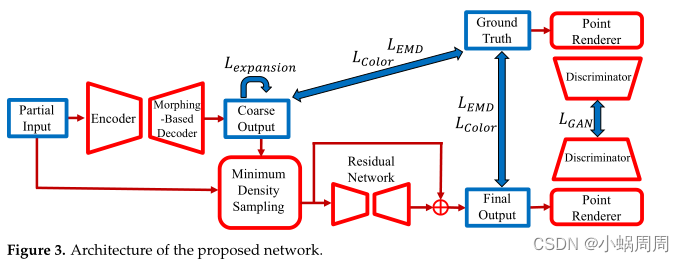
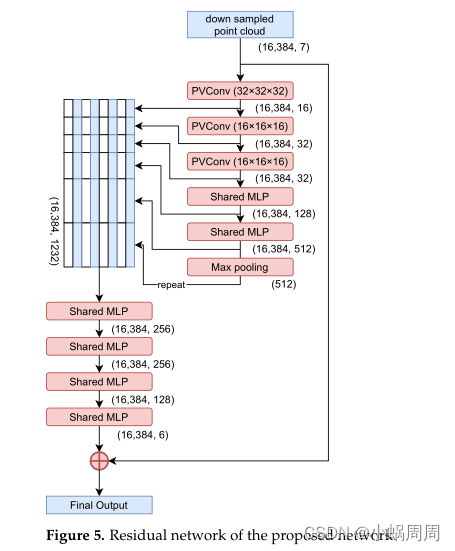
编码得到全局特征之后,基于变形的解码器形变32个[0,1]间的单元为512个点的缝补点云然后输出一个16384的粗粒度点云。中间输出点云和输入点云相加到一起然后经过最小密度采样归一化密度后转换为一个16384的点云。最后残差网络用于细化输出点云。
本文的输入向量为加入了Lab的六维向量,与RGB不同的是它能够使用欧几里得距离近似人类感知的色差。
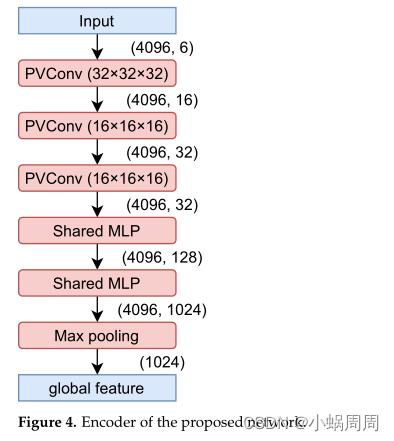
使用Pvconv作为编码器,全局特征和差异信息由体素32*32*32的卷积和16*16*16的卷积得到。
鉴别器由4个CNN网络组成,决定是是真值点云还是补全点云的图像。
实验:
使用MSN进行了四种 类型的训练:使用CD距离或EMD距离,是否使用GAN。并对本文提出的网络进行相同的实验,得到的结果均优于MSN。但在EMD指标上,在无GAN时,使用基于EMD的色差损失,所提出的网络不能优于MSN。这是由于所提出的网络过拟合所致,可以通过扩展数据集以改善过拟合。

由于插值对于复杂的形状效果不佳,因此应考虑使用基于点云的鉴别器进行对抗训练,并使用多步解码器对点云进行上采样。同时,若想将输入中的某些细节保留下来,可以考虑像SpareNet一样使用两次细化,或者使用跳过连接来传递输入细节,此外也可以将输入点云中的单面CD 添加到损失函数以缓解此问题。
运用于实际数据中进行补全发现效果不佳,未来有必要创建一个在各种照明环境中的数据集以提升泛化能力。
展望:
改进网络结构、损失函数、扩展数据集
基于深度学习的彩色点云补全不仅可以扩展到头部,还可以扩展到整个人体。