21年9月28日——吴恩达课程 图像增强
在课程的第一周,我们选择用2000个subset来训练dog ves cat的模型,得出的结果出现了过拟合,即训练的acc很高,但是在验证集上的acc不高,就说明数据量不够,如果数据本身很难很难采集的话,可以使用翻转、改变亮度、添加噪声等操作来扩充数据量。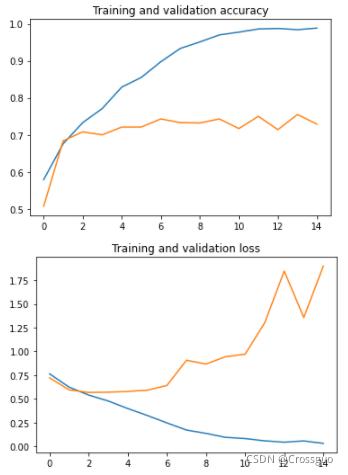
这里补充一下,欠拟合一般是模型太过于简单导致的。
实际上对过拟合简单的解释就是数据量太少,我见过的东西就是训练集里的,遇到其他我没见过的就无法判别,即在验证集中表现不好。
在之前的模型中我们使用了ImageDataGenerator(rescale=1./255)这行代码将图像进行了标准化,标准化意义是使得图片更加可控更容易处理。这里其实我们已经用到了图像增强(image augmentation),接来下我们通过图像增强来扩充数据集。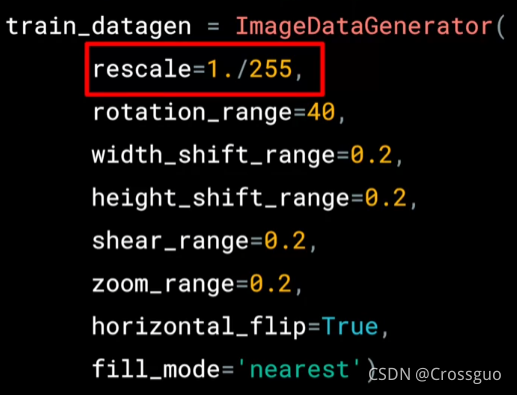
其中,width_shift_range是指左右平移图像,shear_range指的是倾斜变形。

如上图就是倾斜变形。而zoom_range是缩放,不赘述。horizontal_flip指的是水平翻转。
以上我们就做到了图像增强。
具体代码就是:
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
经过各种处理,数据集得到了扩充。之后经过flow方法(为什么呢?)
# Flow training images in batches of 20 using train_datagen generator
train_generator = train_datagen.flow_from_directory(
train_dir, # This is the source directory for training images
target_size=(150, 150), # All images will be resized to 150x150
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
history = model.fit(
train_generator,
steps_per_epoch=100, # 2000 images = batch_size * steps
epochs=100,
validation_data=validation_generator,
validation_steps=50, # 1000 images = batch_size * steps
verbose=2)
最后训练模型。
这种方法可以解决因为数据集过小导致的过拟合。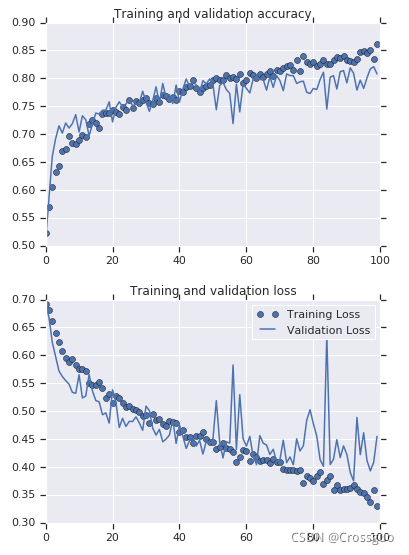
版权声明:本文为qq_44705887原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。