PYTHON编程基础回顾
p.s. 本文为笔者为了系统地回顾一遍python的语法和特性知识所记录的笔记,原视频见下链接。
[注]本文不做详细解释,只记录一些关键点,可作为查询手册使用
PYthon基础教程-求知讲堂
简介
- 特性
面向对象|解释型|1991.吉多·范罗苏姆|胶水语言(模块化)
- 发展
- [1991]发布第一个版本
- [2000] Python 2.0发布,增加垃圾回收,支持Unicode
- [2008] Python3.0发布,不完全向前兼容
- [2020]官方不再支持2.0版本
- 优势
简单 | 开源 | 第三方库 | 可移植 | 面向对象&过程
- 短板
运行慢 | 非加密 | 强制缩进 | GIL全局解释器锁
- 【GIL全局解释器锁】Python中的多线程不是真正的多线程,因为GIL(全局解释器锁)会控制对Python虚拟机进行访问时同一时刻只有一个线程在运行
- 【非加密】解释型语言边翻译边运行,因此必须发布源码才得以运行程序;编译型语言只要有中间代码或者是汇编代码照样能够运行
- 命令行执行
- 执行命令:python filename.py
- 路径问题——
①进入到cmd后cd到指定文件路径下再进入python交互环境
②在当前文件的本地目录下执行cmd命令,直接进入到当前路径下的python交互环境- 退出python交互环境:exit() 或者quit()
变量和数据类型
- 变量
用于指代存储在计算机中的数据
- 变量是一段有名字的连续存储的空间,可以通过定义变量来申请并命名这样的存储空间,并通过变量的名字来使用这段存储空间。
- 强类型 | 无需指定数据类型 | 变量类型与赋值数据类型保持一致
- 基本数据类型
【类型分类】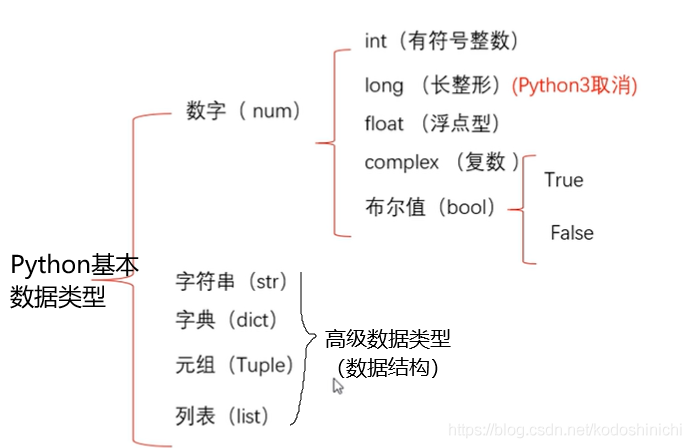
【查看类型】
type(var)
a=20
print(type(a))
#<class 'int'>
3. 变量命名规则
【命名规则】
- 变量名是由数字(0-9)、字母(a-z,A-Z)或下划线构成的符号串
- 变量名必须以字母或下划线开头
- 变量名区分大小写
- python关键字不能用作变量名
【关键字】
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
【命名规范】
当一个变量名是由多个单词组成的复合词语时:
- 小驼峰命名法:第一个单词的首字母小写,其他单词的首字母大写,e.g. userName
- 大驼峰命名法:全部单词的首字母都大写,e.g. UserName
- 下划线命名法:多个单词之间用下划线进行连接,e.g. user_name
运算(符)和表达式
- 算术运算
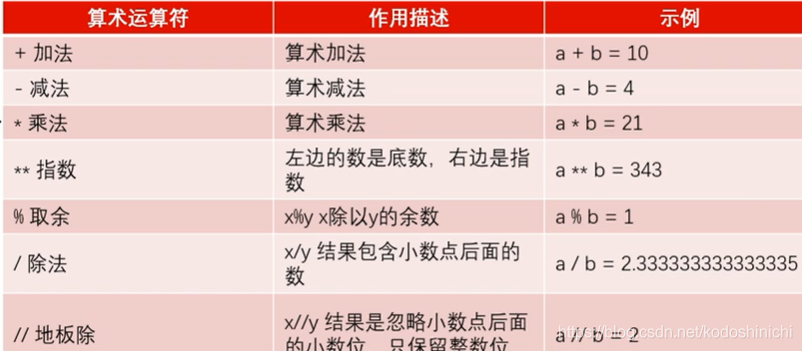
- 比较运算
比较运算的结果都是布尔值
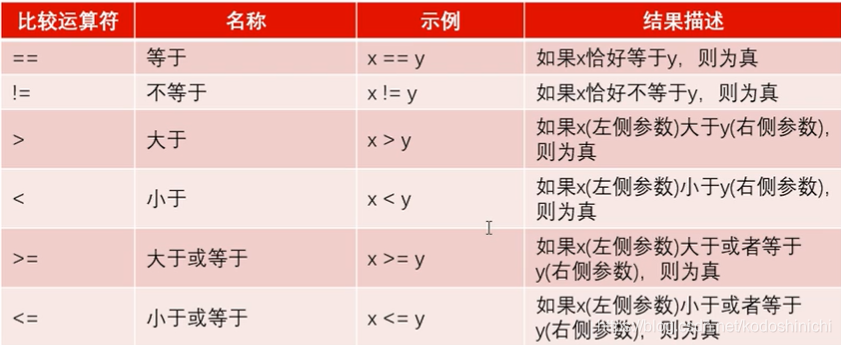
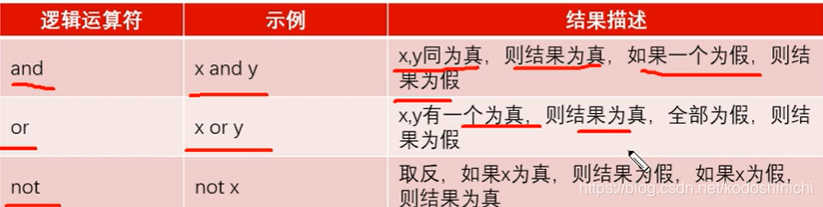
- 逻辑运算
【运算符及运算规则】
【优先级】
() -> not -> and -> or
【短路运算】
逻辑运算符也可以称作是短路运算符
- A and B中,如果A表达式运算的结果为F,则B表达式不再进行运算;
- A or B中,如果A表达式的运算结果为T,则B表达式不再进行运算。
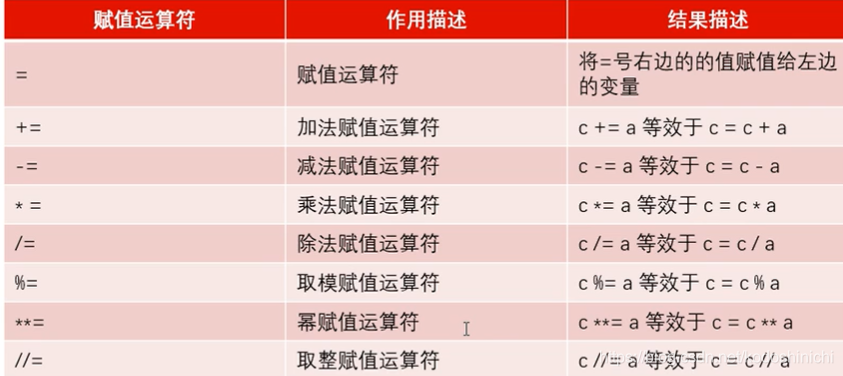
- 赋值运算符
- 输入出
【输出】
- 变量输出:
print(varName)- 格式化输出:
①使用(%)作为占位符,占位符之后跟着的是变量类型
name='CSDN'
subject='Python'
print('我在%s上学习有关%s的课程'%(name,subject))
#我在CSDN上学习有关Python的课程
②使用format方法
addr="广州市白云区"
print('地址:{}'.format(addr))
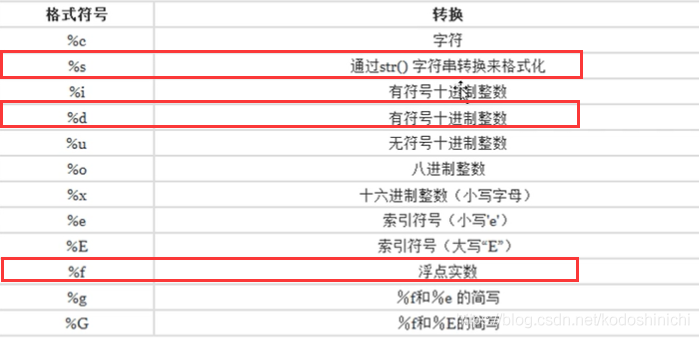
#地址:广州市白云区- 格式化符号:
【输入】
在Python中的输入是通过input函数来实现的
- 使用示例
name = input('请输入您的姓名') print(name)
#小明- input特点:接收到的输入都是str类型
age = input("请输入您的年龄:")
print(age)
print(type(age))
#请输入您的年龄:18
#18
#<class 'str'>
如果涉及到有关数字的运算,还需要进行类型转换,进行整型的强制类型转换int()
流程控制
- 流程:计算机执行代码的顺序;
- 流程控制:对计算机代码执行的顺序进行有效的管理,以实现现实生活中的业务逻辑;
- 流程控制类别:顺序 | 选择(分支) | 循环
- 选择流程
条件语句是通过一条或多条语句的执行结果(布尔值),决定接下来执行的代码块
选择结构也成为分支结构,根据分支的数目,可以分成单分支、双分支和多分支
if conditon1:
do thing1
do thing2
...
elif condition2:#可以有多个elif分支
do thing3
do thing4
...
else:
do thing5
do thing6
...
'''
上述所有的分支结构中,有且只有一个会被执行;且所有的分支应该是两两互斥的
'''
- 循环流程
使用循环流程的目的在于将相似或者相同的代码操作变得更加简洁,使得代码可以重复利用
- while循环
while condition:
do something
【语法特点】
①需要有初始值
②需要有条件表达式
③循环体内的技术变量需要自增或自减,以免造成死循环
【适用场景】
循环次数不确定,依靠循环条件来结束
- for循环
for it in iteration:
do something
do something
'''
其中it是临时变量,iteration是诸如字符串、列表这样的复合、可迭代数据对象
'''
【语法特点】
①遍历操作,依次取集合容器中的每一个值
②在Python中for循环可以遍历任何序列的项目,如一个列表或一个字符串
- break语句/coninue语句
- 使用break语句来结束整个循环——不再执行循环里面的代码
- 使用continue语句跳过本次循环——继续下一次循环
p.s.这两个关键字均只能用在循环中
高级数据类型
【序列】
①定义:在Python中,序列就是一组按照顺序排列的值。
②类型:在Python中,存在三种内置的序列类型——字符串、列表和元组。
③特点:序列对象支持索引和切片操作
【索引】
特征:当第一个正索引为0时,指向的是左端;第一个索引值为负数时,指向的是右端
【切片】
①定义:Python中截取序列对象的其中一段内容
②使用语法:[起始下标:结束下标:步长];
切片截取的内容不包括结束下标对应的数据,步长的含义是确定每隔几个下标获取下一个对象,步长的默认值为1
③特征:下标会越界,但切片不会
字符串及常用方法
- 字符串常用方法

'''
字符串常用方法示例:
功能 方法
①首字母大写 str.capitalize()
②判断字符串是否以某个字符开始或结束 str.startswith()/str.endswith()
③检查某个字符是否在字符串中 str.find()/str.index()
④判断字符串是否是数字或字母组成 str.isalnum()/str.isalpha()/str.isdigit()
⑤字符串中所有字母的大小写转换/大小写判断 str.lower()/str.upper()/str.swapcase()/str.islower()/str.title()
⑥清除字符串中左/右/两边的空白 str.lstrip()/str.rstrip()/str.strip()
'''
#----------------------①----------------------------
str = "peter is learning python."
print("首字母大写后的字符串:%s"%(str.capitalize()))
#---------------------②------------------------------
if str.startswith('p'):
print("字符串%s是以字符p开头的"%str)
else:
print("字符串%s不是以字符p开头的"%str)
#-------------------③--------------------------------
if str.find('l') != -1:#.find()方法返回的是所查找的字符在原字符串中的下标
print("字符串第%s的第%d个下标处含有字符l"%(str,str.find('l')))
else:
print("字符串%s中未含有字符l" % str)
print(str.index('a'))#.index()方法只能用于定位字符串中已有字符在原串中的位置,如果不存在则报错
#---------------------④-------------------------------
str1 = "abc123"
str2 = "abc"
str3 = "123"
if str1.isalnum():
print("字符串%s是由字母和数字组成的"%str1)
if str2.isalpha():
print("字符串%s是由字母组成的"%str2)
if str3.isdigit():
print("字符串%s是由数字组成的"%str3)
#---------------------⑤-----------------------------
ss = "abCdEFGhijk"
sen = "abc Efg aSd"
print("所有字母小写后的字符串为:%s"%ss.lower())
print("所有字母大写后的字符串为:%s"%ss.upper())
print("所有字母大小写互换后的字符串为:%s"%ss.swapcase())
if not ss.islower():
print("%s不是由小写字母组成的。"%ss)
print("将每个单词的首字母变成大写后:%s"%sen.title())
#------------------------⑥---------------------------------
s = " hello "
print("清除左边空白后:%s"%s.lstrip())
print("清除右边空白后:%s"%s.rstrip())
print("清除两边空白后:%s"%s.strip())
'''
输出结果:
首字母大写后的字符串:Peter is learning python.
字符串peter is learning python.是以字符p开头的
字符串第peter is learning python.的第9个下标处含有字符l
11
字符串abc123是由字母和数字组成的
字符串abc是由字母组成的
字符串123是由数字组成的
所有字母小写后的字符串为:abcdefghijk
所有字母大写后的字符串为:ABCDEFGHIJK
所有字母大小写互换后的字符串为:ABcDefgHIJK
abCdEFGhijk不是由小写字母组成的。
将每个单词的首字母变成大写后:Abc Efg Asd
清除左边空白后:hello
清除右边空白后: hello
清除两边空白后:hello
'''
- 字符串的复制
a = "Hello"
b = a #使用赋值语句让b和a具有相同的值
'''
实际上,在Python中=赋值是让两个对象指向内存统同一地址;
因此a和b不仅具有相同的值,实际上其二者是同一个对象
'''
print(id(a)==id(b))
#输出:True
- 字符串的切片
strMsg = "hello world"
#slice[start:end:step],返回的是[start,end)范围内的值,注意前闭后开
print(Msg[2:5])
print(Msg[1:-1:2])
#输出:
#llo
#el ol
列表及常用方法
- 基本介绍
【列表】
列表是一种有序的集合,可以随时删除和添加其中的元素
【特点】
①支持增删改查
②列表中的数据项可以变化,但列表该数据对象本身的地址不会发生变化
③列表中的数据项可以是任何类型的,也不要求相同
【创建】
只需要将逗号分隔的不同数据项用方括号括起来即可
【使用】
- 列表的下标、索引和切片等操作都和字符串一致
- 使用for循环可对列表等序列对象逐一取出值,取完所有值后退出循环
- 使用强制类型转换
list()就可以把序列对象转换成list类型的数据
- 常用方法
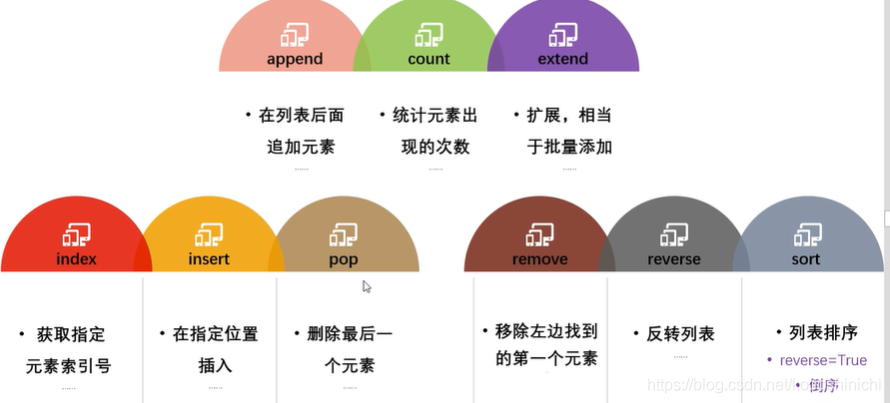
'''
列表常用方法示例:
功能 方法
①增加元素 li.append()/li.extend()/li.insert()
②查找元素和列表获取 切片/索引/li.count()/li.undex()
③修改列表中元素 索引+重新赋值/li.reverse()/li.sort()
④删除列表中的元素 li.pop()/li.remove()/del()函数
'''
#---------------------列表定义----------------------------
li = [1,2,'z',3]
print(type(li))
#---------------------①------------------------------
print(li.append(['hello',1.23]))#append()这类增加型的方法本身是没有返回值的
print(li)#注意显示的结果是列表中含有多级嵌套的
li.insert(1,888)#在li该列表的第1个数据项的位置处插入一个整数888,p.s.下标项从0开始计数
print(li)
li2 = list(range(5))
li.extend(li2)
#注意同样是增加一个列表,append()是内嵌进入原列表,而extend()是直接将原列表的长度进行扩展
#如果只是对原列表进行元素的增加,append一次只能增加一个元素,但是extend可以多个,又称为批量增加
print(li)
#---------------------②------------------------------
#print(li)输出完整列表
print(li[2])#输出第2个元素,下标从0开始计数
print(li[1:3])
print(li*2)#对于序列对象的乘法操作就是将对象的值进行复制
#-------------------③--------------------------------
print("修改之前",li)
li[0]=11.111#使用下标索引+重新赋值
print("修改之后",li)
#---------------------④-------------------------------
#使用del函数
print("删除前: ",li)
del(li[0])#列表后跟索引就是删除下标所指向的值,列表后跟切片就是按照切片规则批量删除
print("删除后: ",li)
#使用remove方法,remove(m)表示移除列表中的数据m
print("移除元素0之前",li2)
li2.remove(0)
print("移除元素0之后",li2)
#使用pop方法,pop(i)表示移除列表中第i项,p.s.下标从0开始计数
print("移除第2项元素之前",li2)
li2.pop(1)
print("移除第2项元素之后",li2)
'''
运行结果:
<class 'list'>
None
[1, 2, 'z', 3, ['hello', 1.23]]
[1, 888, 2, 'z', 3, ['hello', 1.23]]
[1, 888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4]
2
[888, 2]
[1, 888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4, 1, 888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4]
修改之前 [1, 888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4]
修改之后 [11.111, 888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4]
删除前: [11.111, 888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4]
删除后: [888, 2, 'z', 3, ['hello', 1.23], 0, 1, 2, 3, 4]
移除元素0之前 [0, 1, 2, 3, 4]
移除元素0之后 [1, 2, 3, 4]
移除第2项元素之前 [1, 2, 3, 4]
移除第2项元素之后 [1, 3, 4]
'''
元组
- 基本介绍
【元组】
①元组是一种不可变的序列,一经创建不可修改
②使用小括号对用逗号分隔的数据项进行创建
p.s. 当元组中只有一个元素时,也要加上逗号,不然解释器会当做整型来处理
③数据项也可以是任意类型
④同样支持切片、索引操作
- 基本方法
'''
元组常用方法示例:
功能 方法
①元组获取 for循环/切片和索引
②查找元素 tu.count()/tu.undex()
③元组的“修改” 整体重新赋值/对元组中的可修改序列对象进行修改
'''
#---------------------元组创建----------------------------
tu = (1,2,3)
tu1 = ('abcd',123,3.45,[0,1,2,3],'hello')
#数据项即可以是基本数据类型,也可以是复合数据类型
print(type(tu))
print(type(tu1))
#---------------------①------------------------------
# 使用for循环对元组内的元素逐一获取
for item in tu1:
print(item,end=' ')
#使用切片和索引对元组内的元素逐一获取
print()
print(tu1[0])
print(tu1[0:3])#从元组里取出来的切片依然是元组
#---------------------②------------------------------
# 使用count方法统计元素在元组中出现的次数
print("查找元素1在元组(1,2,3)中出现的次数:",tu.count(1))
#-------------------③--------------------------------
tu2 = ()
print("生成了一个新的空元组,其内存地址为: ",id(tu2))
tu2 = (3,)
print("对上述元组重新赋值,其内存地址为: ",id(tu2))
#其二者结果是不一样的,其实是重新生成了一个元组对象,让tu2指向了新的元组对象
#tu1中的倒数第二个对象是列表,可以修改
tu1[-2][0] = -1
print("修改后的元组为: ",tu1)
'''
运行结果:
<class 'tuple'>
<class 'tuple'>
abcd 123 3.45 [0, 1, 2, 3] hello
abcd
('abcd', 123, 3.45)
查找元素1在元组(1,2,3)中出现的次数: 1
生成了一个新的空元组,其内存地址为: 3178464804936
对上述元组重新赋值,其内存地址为: 3178495054568
修改后的元组为: ('abcd', 123, 3.45, [-1, 1, 2, 3], 'hello')
'''
字典及常用方法
- 基本介绍
【字典】
字典是Python中以键值对的形式创建的,诸如{‘key’:‘value’}形式,可以存储任意对象的无序数据类型。
- 字典的键(key)不能重复,值(value)可以重复;
- 如果存在重复的键,后者会对前者进行覆盖;
- 字母的键(key)只能是不可变类型,如数字、字符串、元组等
【操作与特性】
①字典与列表一样,是可修改的数据对象,支持对数据的添加、修改和删除操作;
②在字典中查找某个元素时,是根据键值进行,可以提高查找效率;
③只能通过键来获取字典中的元素,字典不是序列类型,不支持索引、切片等
- 常用方法

'''
字典常用方法举例:
功能 方法
①字典元素获取 用键获取值/dict.keys()/dict.values()
②查找、排序字典中元素 len(dict)/sorted()
③字典的“修改” 键获取+重新赋值/dict.update()
④字典的“删除” dict.pop('key')/del()/clear()
'''
#---------------------字典创建----------------------------
#使用花括号来对字典进行创建,声明时可以直接添加键值对
dict = {'pos':"程序员",'age':'19'}#创建一个字典
print(type(dict))
#通过键值对的方式给字典添加数据 key:value
dict['name'] = '小明'
print(dict)
#---------------------①------------------------------
#通过键获取对应的值
print(dict['name'])
#通过key()获取字典的key对象[,结合for循环得到每一个key值]
print("直接输出所有的键: ",dict.keys())
for item in dict.keys():
print(item,end = ' ')
#通过value()获取字典的value对象[,结合for循环得到每一个value值]
for item in dict.values():
print(item, end=' ')
print()
#通过items()获取字典的键值对对象[,结合for循环进行遍历输出]
for item in dict.items():
print(item, end=' ')
#---------------------②------------------------------
#通过len()函数返回字典中键值对的个数
print()
print("该字典中共有键值对的数目: ",len(dict))
#通过使用函数sorted(),并指定排序的关键字
print('排序前的字典为: ',dict)
dict_sorted = sorted(dict.items(),key=lambda d:d[0])#使用lamda相当于构造了一个匿名函数,按照键的ASCII码进行排序
print('排序后的字典为: ',dict_sorted)#sorted函数不改变原来对象
print('排序的对象类型为: ',type(dict_sorted))#因为进行sorted的是字典的items()方法返回的结果,得到的其实是一个列表
#-------------------③--------------------------------
#通过键获取值,重新赋值进行修改
print("修改前的字典为: ",dict)
dict['name'] = '小军'
print("修改后的字典为: ",dict)
#通过update()方法传入修改后新的键值对,对以前的键值对进行修改
#update方法传入一个之前没有的键,则是添加一个新的键值对
print()
print("更新前的字典为: ",dict)
dict.update({'age':29,'hobby':'唱歌'})
print("更新后的字典为: ",dict)
#-------------------④------------------------------------
#使用dek删除指定元素
del(dict['hobby'])
#使用pop方法删除指定键
dict.pop('pos')
print("删除后的字典为: ",dict)
#使用clear()清空整个字典
dict.clear()
print(dict)#dict对象还在,但是已经是个空字典了
'''
运行结果:
<class 'dict'>
{'pos': '程序员', 'age': '19', 'name': '小明'}
小明
直接输出所有的键: dict_keys(['pos', 'age', 'name'])
pos age name 程序员 19 小明
('pos', '程序员') ('age', '19') ('name', '小明')
该字典中共有键值对的数目: 3
排序前的字典为: {'pos': '程序员', 'age': '19', 'name': '小明'}
排序后的字典为: [('age', '19'), ('name', '小明'), ('pos', '程序员')]
排序的对象类型为: <class 'list'>
修改前的字典为: {'pos': '程序员', 'age': '19', 'name': '小明'}
修改后的字典为: {'pos': '程序员', 'age': '19', 'name': '小军'}
更新前的字典为: {'pos': '程序员', 'age': '19', 'name': '小军'}
更新后的字典为: {'pos': '程序员', 'age': 29, 'name': '小军', 'hobby': '唱歌'}
删除后的字典为: {'age': 29, 'name': '小军'}
{}
'''
共有操作

函数-基础
【函数】
①函数就是一种基本的将代码抽象表达的方式;
②Python中可以灵活地定义函数,且本身内置了很多有用的函数。
基本概念
1 函数定义
在编写程序的过程中,如果某一个功能的代码块出现了多次;
为了提高编写的效率以及对代码进行重用,把具有独立功能的代码块组织成一个小模块——函数
2.函数定义与使用
'''
函数定义
'''
def function_name(参数列表):
'''
函数功能描述
'''
pass
#代码块/函数体——一系列的python语句,表示独立的功能
'''
函数调用
'''
function_name()
参数
【参数】
函数为了实现某项特定的功能,进而为了得到实现功能所需要的数据——称为参数
在定义函数时,只要把参数的名字和位置确定下来,函数的接口定义就完成了。
对于函数调用者而言,只需要知道传递怎样的参数以及函数返回值的类型即可。
- 必选参数
'''
实际参数和形式参数
'''
#函数定义
def sum(a,b):#a,b是形式参数,在定义时不占据内存地址
sum = a+b
print(sum)
#函数调用
sum(1,2)#1,2是实际参数,实际占用内存地址
在上方示例中,如果调用sum()函数,则必须要传入两个参数才能正常调用该函数;
这就是必选参数——在调用时必须给定相对应的实参。
- 默认参数(缺省参数)
如果在调用函数时没有传参数,就使用定义函数时给的缺省值。
'''
默认参数
'''
#函数定义
def sum(a=10,b=20):#在定义函数时已经给参数赋了相应的默认值
sum = a+b
print(sum)
#函数调用
sum()#不给定实参也可以调用,会采用定义时给定的默认值
注意事项:
①缺省参数始终要处于参数列表的末端,不然程序会报错
def sum(a = 10,b = 20,c):
sum = a+b+c
print(sum)
sum(10)
'''
程序报错:
SyntaxError: non-default argument follows default argument
'''
②当有m个缺省参数,对于缺省参数部分只传入了n(m>n)个实参,会按照从左至右的顺序给缺省参数附上实参的值;要想给某一特定的缺省参数传入实参值,需要使用位置参数,形如“形参名=实参值”。
def sum(x,a = 10,b = 20,c = 40):
sum = a+b+c+x
print(sum)
sum(5)#只传入了必选参数的实参值,结果75
sum(5,5)#对于三个缺省参数,只传入了一个实参值,优先赋给a,结果70
sum(5,c = 5)#使用位置参数给特定的缺省参数c传入实参值,结果为40
- 可选参数(不定长参数)
一个函数有时会处理比函数声明时更多的参数,这就是可选参数。
- 当函数的参数个数不确定的时候即使用;
- 定义函数时不需要声明参数名,使用加了一个星号(*)的变量args来存放所有未命名的变量参数,args为元组结构。
def getcomputer(*args):#使用一个星号*加上args来定义可变参数
print(args)
#函数调用
getcomputer(1)
getcomputer(1,2)
'''
运行结果:
(1,)
(1, 2)
由此可知,传入可变参数中的数据,在函数体内是以元组的形式被处理的
'''
- 关键字(可变)参数
关键字可变参数也是用来处理个数不定的参数的情况:
- 使用两个星号**加上kwargs;
- 在函数体内,参数关键字是一个字典类型的数据,且数据的key值一定得是字符串。
def func(**kwargs):
print(kwargs)
#函数调用
# ①直接使用**传入一个字典类型的实参
dict = {'name':'小明','age':19}
func(**dict)#注意这里的实参书写形式
#②将键值对数据以命名参数的形式作为实参传入函数中
func(name = '小红',age=20)
#③因为是可变参数,不传入实参则打印出的参数为空
func()
'''
运行结果:
{'name': '小明', 'age': 19}
{'name': '小红', 'age': 20}
{}
'''
可变参数与关键字可变参数:
- ①其二者可以共同使用,注意区分好形参定义形式和实参数据结构即可;也即可变参数在函数体内以元组形式存在,关键字可变参数在函数体内以字典形式存在。
- ②在形参定义时,可变参数一定要放在关键字可变参数之前
p.s.记忆:一个星号要在两个星号之前
返回值
- 基本概念
【返回值】
- 返回值就是函数执行完之后会返回的一个或多个数据对象
- 在函数体内部通过关键字return 返回一个确定的数据对象,如果不使用该关键字则返回一个空对象
- 返回值的数据对象类型取决于return关键字后接着的数据对象类型
【返回值的数据类型】
- 如果要返回多个结果,将返回的值用逗号隔开,最终会返回一个包含所有返回值的元组;
- 如果要返回列表或字典结构,则在函数体里要事先把返回值的类型声明成列表(用[]创建)或字典(用{}key:value创建)
def calcomputer1(num):#返回整数
result = 0
for i in range(num):
result += i
return result
def calcomputer2(num):#返回列表
li = []
result = 0
for i in range(num):
result += i
li.append(result)
return li
def calcomputer3(num):#返回字典
result = 0
for i in range(num):
result += i
return {'结果':result}
def calcomputer4(num):#返回元组
result = 0
for i in range(num):
result += i
return 0,1,result
res1 = calcomputer1(10)
res2 = calcomputer2(10)
res3 = calcomputer3(10)
res4 = calcomputer4(10)
#当把result作为返回值时,根据result的类型,返回的是整型
print("返回值为: ",res1)
print("当前返回值类型为: ",type(res1))
print()
#当把li作为返回值时,根据li的类型,返回的是列表
print("返回值为: ",res2)
print("当前返回值类型为: ",type(res2))
print()
#当返回值中返回一个字典标准的键值对形式,返回的就是字典
print("返回值为: ",res3)
print("当前返回值类型为: ",type(res3))
print()
#当返回值中返回一个字典标准的键值对形式,返回的就是字典
print("返回值为: ",res4)
print("当前返回值类型为: ",type(res4))
'''
运行结果:
返回值为: 45
当前返回值类型为: <class 'int'>
返回值为: [45]
当前返回值类型为: <class 'list'>
返回值为: {'结果': 45}
当前返回值类型为: <class 'dict'>
返回值为: (0, 1, 45)
当前返回值类型为: <class 'tuple'>
'''
嵌套调用
【函数的嵌套调用】
函数的嵌套调用,即可以在一个函数的内部调用另一个函数
- 内层函数可以访问外层函数中定义的变量,但不能重新赋值(rebind)