本文是《数据库系统概论》的第五章(数据库完整性)的部分课后习题和存储过程习题,题目来源:【2019-2020春学期】数据库作业14:第五章: 数据库完整性 习题 + 存储过程
数据库完整性习题6
假设有下面两个关系模式:
职工(职工号,姓名,年龄,职务,工资,部门号),其中职工号为主码:
部门(部门号,名称,经理名,电话),其中部门号为主码。
用SQL语言定义这两个关系模式,要求在模式中完成以下完整性约束条件的定义:
①定义每个模式的主码;②定义参照完整性;③定义职工年龄不得超过60岁。
(ps:因为之前我就建立过COMPANY数据库,里面含有这两张表,不过关系模式不一样,所以我先将原有的两张表删除)
-- 切换至COMPANY数据库,并删除原来的两张表
USE COMPANY;
DROP TABLE Staff; /*这里需要注意要先删除Staff表,因为它引用了Dept表的主码作为外码约束,必须先把它删了才删得了Dept表*/
DROP TABLE Dept;
-- 按该题要求新建Dept和Staff表,分别对应部门和职工两个关系模式
CREATE TABLE Dept (
DNO VARCHAR(10) PRIMARY KEY,
DNAME VARCHAR(10) UNIQUE, /*给部门名设置UNIQUE,隐含着NOT NULL*/
MNAME VARCHAR(10) NOT NULL, /*经理名*/
PHONE INT NOT NULL
)
CREATE TABLE Staff (
SNO VARCHAR(10) PRIMARY KEY,
SNAME VARCHAR(10) NOT NULL,
AGE INT CHECK(AGE <= 60 AND AGE > 0) NOT NULL,
DUTY VARCHAR(8) NOT NULL, /*职务*/
SALARY INT NOT NULL,
DNO VARCHAR(10) REFERENCES Dept(DNO)
)
因为职工表Staff 里的部门号DNO引用的是部门表Dept的主码DNO,所以得先建立Dept表再建立Staff表~
如下图,新建成功!
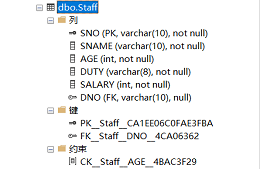
?值得注意的是:给部门名DNAME设置的UNIQUE键其实某种意义上隐含着不能为空,因为如果出现多个空值的话,他们就是相同的,即违反了UNIQUE键,如下图: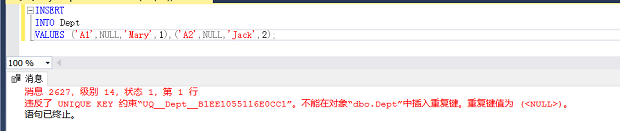
存储过程习题2
对学生-课程数据库编写存储过程,完成下述功能:
1)统计离散数学的成绩分布情况,即按照各分数段统计人数:
(ps:学生-课程数据库涉及Student、Course、SC三张表,之前在写操作基础篇的时候用到很多次啦,因为目前课程表Course中没有离散数学这个科目,所以我先添加课程:离散数学且同时给SC表添加相应数据)
-- 添加课程:离散数学
INSERT
INTO Course
VALUES ('8', '离散数学', NULL, 4);
SELECT * FROM Course;
(ps:Cpno是先修课的课程号,即学了先修课才能学该课程,我这里就不设置先修课啦,Ccredit是该课程的学分)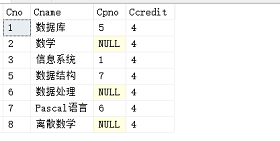
-- 给SC表添加数据
INSERT
INTO SC
VALUES ('201215121', '8', 80), ('201215122', '8', 85), ('201215124', '8', 96),
('201215129', '8', 72), ('201215130', '8', 60), ('201215131', '8', 59);
SELECT * FROM SC;
为了方便查看,我把之前SC表里的数据清空了~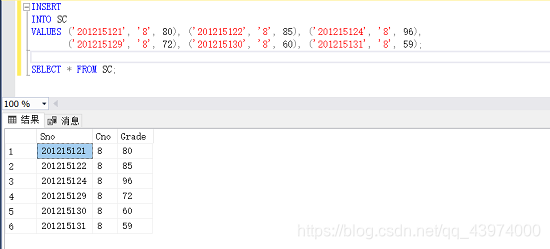
— — — — — — — — — — — — — — — — — — — — — —
?好了,现在开始按要求完成该题
① 先建立一张表Amount来记录各个分数段及其人数:
-- 新建表Amount
CREATE TABLE Amount (
ScoreLevel CHAR(15),
Number INT
)
-- 插入数据
INSERT
INTO Amount
VALUES ('小于60', 0), ('[60,70)', 0), ('[70,80)', 0),
('[80,90)', 0), ('大于等于90', 0);
SELECT * FROM Amount;
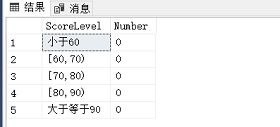
② 创建存储过程:
IF(exists(select * from sys.objects where name='Proc_SCORELEVEL'))
DROP PROCEDURE Proc_SCORELEVEL;
GO
-- 创建存储过程Proc_SCORELEVEL
CREATE PROCEDURE Proc_SCORELEVEL
AS
BEGIN
--定义变量
DECLARE @Cno CHAR(4), --需要将Course表中的Cno赋值过来查询的时候用
@under60 INT, --低于60分
@f60t70 INT, --大于等于60小于70
@f70t80 INT,
@f80t90 INT,
@beyond90 INT; --90及其以上
-- 给@Cno赋值
SELECT @Cno = Cno FROM Course WHERE Cname = '离散数学';
-- 分数小于60的
SELECT @under60 = COUNT (*) FROM SC WHERE Grade < 60 AND Cno = @Cno;
UPDATE Amount SET Number = @under60 WHERE ScoreLevel ='小于60';
-- 大于等于60小于70
SELECT @f60t70 = COUNT (*) FROM SC WHERE Grade >= 60 AND Grade < 70 AND Cno = @Cno;
UPDATE Amount SET Number = @f60t70 WHERE ScoreLevel = '[60,70)';
-- 大于等于70小于80
SELECT @f70t80 = COUNT (*) FROM SC WHERE Grade >= 70 AND Grade < 80 AND Cno = @Cno;
UPDATE Amount SET Number = @f70t80 WHERE ScoreLevel = '[70,80)';
/*大于等于80小于90*/
SELECT @f80t90 = COUNT (*) FROM SC WHERE Grade >= 80 AND Grade < 90 AND Cno = @Cno;
UPDATE Amount SET Number = @f80t90 WHERE ScoreLevel = '[80,90)';
/*大于等90*/
SELECT @beyond90 = COUNT (*) FROM SC WHERE Grade >= 90 AND Cno = @Cno;
UPDATE Amount SET Number = @beyond90 WHERE ScoreLevel = '大于等于90';
END;
EXEC Proc_SCORELEVEL; -- 执行刚创建好的存储过程
SELECT * FROM Amount;
?来看结果如何:
执行存储过程前:
执行后: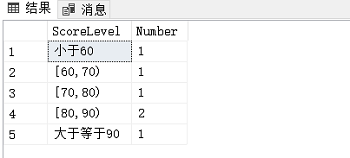
对比刚刚的Amount表和数据可以看到,该存储过程创建和执行都稳了!
2)统计任意一门课的平均成绩:
① 先建立一张表AvgSC来记录任意一门课的平均成绩:
-- 新建表
CREATE TABLE AvgSC (
Cname CHAR(10), -- 课程名
AvgScore FLOAT --平均分
)
-- 插入数据
INSERT
INTO AvgSC
VALUES ('数据库', 0), ('数据结构', 0), ('离散数学', 0);
SELECT * FROM AvgSC;
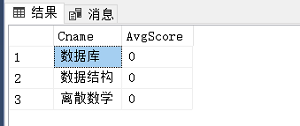
② 创建存储过程:
IF(exists(select * from sys.objects where name='Proc_AVGSC'))
DROP PROCEDURE Proc_AVGSC;
GO
-- 创建存储过程
CREATE PROCEDURE Proc_AVGSC
AS
BEGIN
-- 定义变量
DECLARE @Avg1 FLOAT,
@Avg2 FLOAT,
@Avg3 FLOAT;
SELECT @Avg1 = AVG(Grade) FROM SC WHERE Cno = '1'; -- SC表中数据库的课程号是1
UPDATE AvgSC SET AvgScore = @Avg1 WHERE Cname = '数据库';
SELECT @Avg2 = AVG(Grade) FROM SC WHERE Cno = '5'; -- SC表中数据结构的课程号是5
UPDATE AvgSC SET AvgScore = @Avg2 WHERE Cname = '数据结构';
SELECT @Avg3 = AVG(Grade) FROM SC WHERE Cno = '8'; -- SC表中离散数学的课程号是8
UPDATE AvgSC SET AvgScore = @Avg3 WHERE Cname = '离散数学';
END;
EXEC Proc_AVGSC;
SELECT * FROM AvgSC;
首先,咱们看看SC长啥样(为了做实验,我1号课和5号课各加上了两条数据):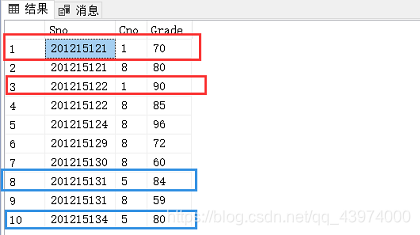
执行存储过程前后对比: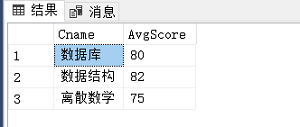
存储过程创建和执行成功!✌
3)将学生选课成绩从百分制改为等级制(即A、B、C、D、E):
-- 给SC表为增加一个属性列ScoreLevel*/
ALTER TABLE SC ADD ScoreLevel CHAR(4);
IF(exists(select * from sys.objects where name='Proc_CHANGE'))
DROP PROCEDURE Proc_CHANGE;
GO
-- 新建存储过程
CREATE PROCEDURE Proc_CHANGE
AS
BEGIN
UPDATE SC SET ScoreLevel = 'E' WHERE Grade < 60;
UPDATE SC SET ScoreLevel = 'D' WHERE Grade >= 60 AND Grade < 70;
UPDATE SC SET ScoreLevel = 'C' WHERE Grade >= 70 AND Grade < 80;
UPDATE SC SET ScoreLevel = 'B' WHERE Grade >= 80 AND Grade < 90;
UPDATE SC SET ScoreLevel = 'A' WHERE Grade >= 90;
END;
EXEC Proc_CHANGE;
SELECT * FROM SC;
bingo~?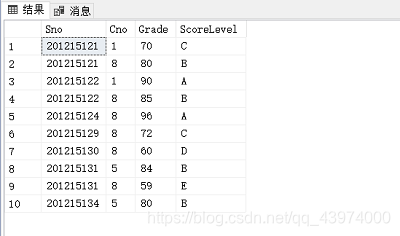
这里需要注意当按照分数段划分等级时用 比较运算符> < = 来划分范围,如果用BETWEEN和AND的话因为BETWEEN和AND是包括边界的,所以会造成结果错误!
— — — — — — — — — — — — — — — —
?小总结:
① BEGIN 和 END 要配对使用!相当于C语言中的函数的大括号一样的,在里面定义变量,赋值,和写要执行的功能等等……
② 变量是在批处理或过程的主体中(这里即在BEGIN和END中)用 DECLARE 语句声明的,并用 SET 或 SELECT 语句赋值,变量名必须以 at 符 (@) 开头!
③ 创建好存储过程后一定要记得执行存储过程EXEC 定义的存储过程名
终于完成啦~ 因为存储过程标准SQL和T-SQL有很多不一样的地方,经过这样的习题训练之后更加了解和掌握T-SQL创建存储过程了,还是挺有收获的?
· 与本篇习题有关的总结篇在这里:【吐血整理】数据库的完整性