最近我打算做一个仿b站页面的项目,打算直接从b站api取数据,然后用ajax请求了一下url发现这个api果然是不支持跨域的,所以我打算通过node.js抓取b站数据搭建服务器来完成这个项目并顺便写了这篇博客。
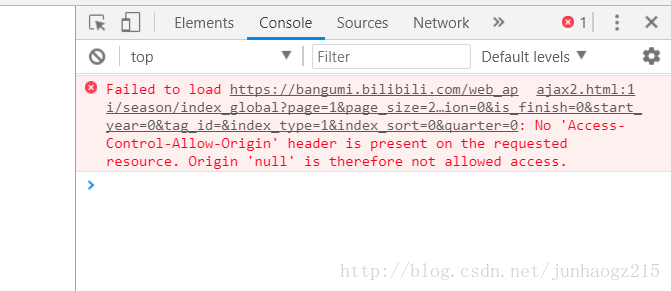
下面我将会把自己爬取api的步骤分享给大家,刚开始写博客,思路略有些混乱请大家见谅,博客中若有错误还请严厉指出。
今天我爬取的页面是b站番剧类目中番剧索引页面中的数据(我是b站粉ヽ(ー_ー)ノ)。

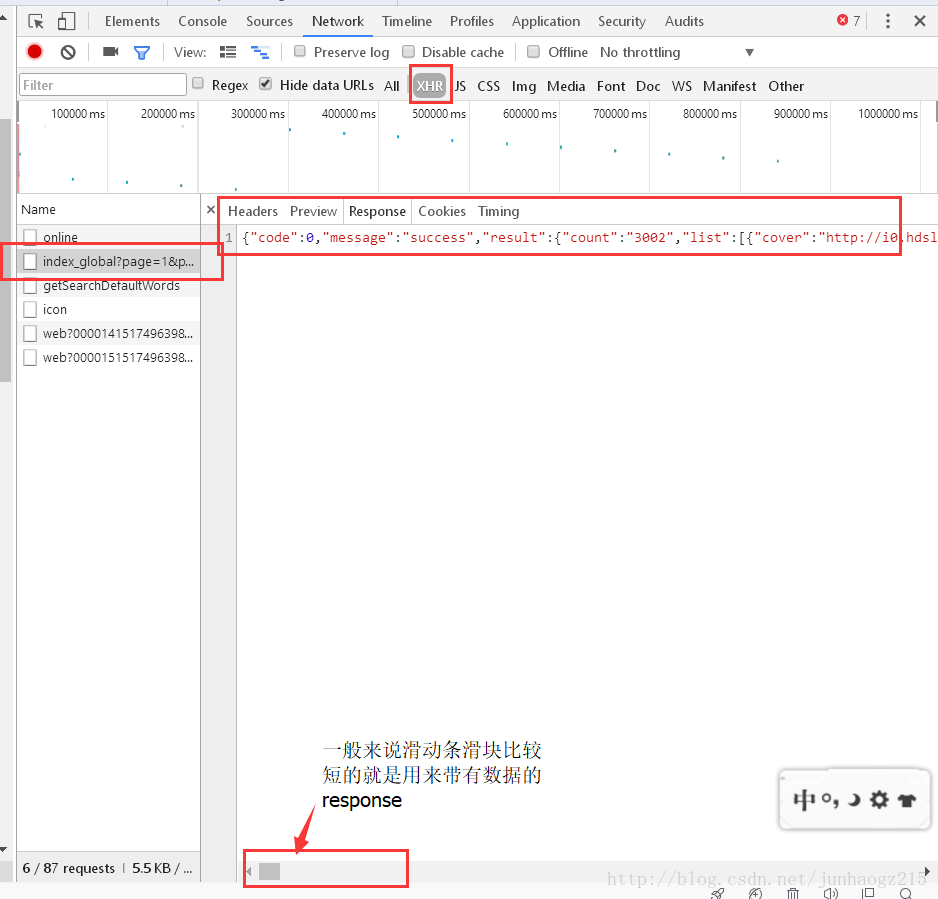
1、打开番剧索引页面并按F12打开控制台,刷新一下页面,然后到控制台的network中页面将filter设置为XHR,然后依次查看各个请求的Response中有没有所需数据,有数据的请求就是我们今天要找的。
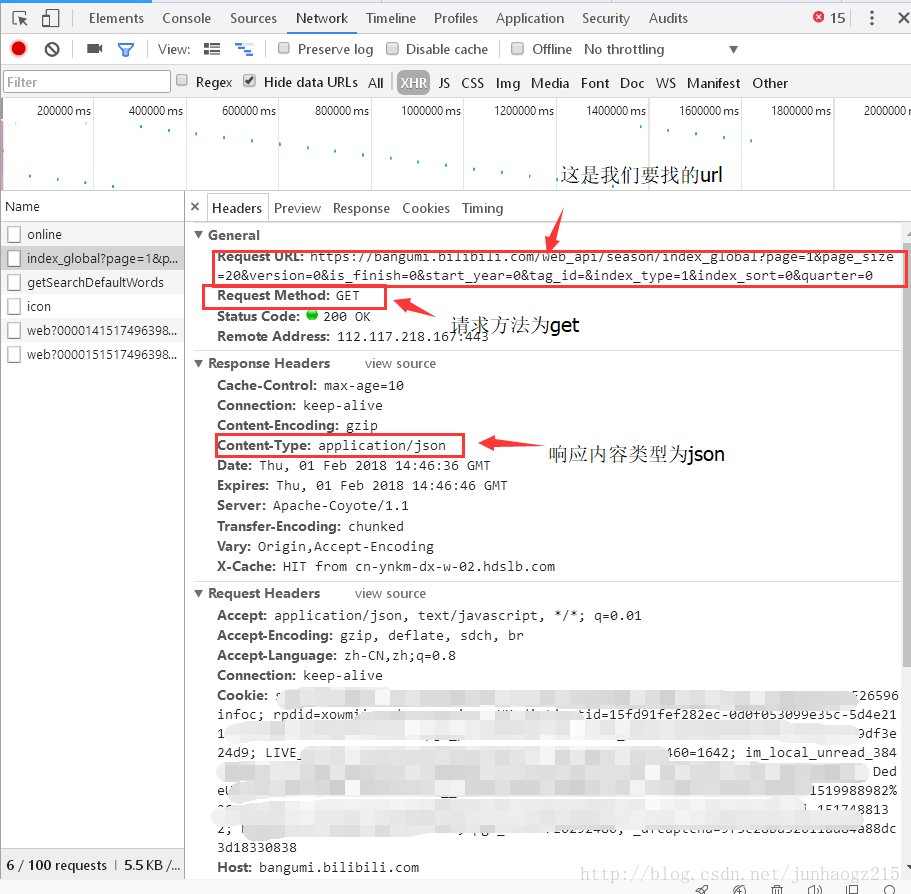
2、下面切换到Headers页面,Request URL 中的地址就是我们要的url,请求类型为get,通过page可以选择查询的页码,page_size可以选择每页的数据条数,后面的每个查询字符串都有自己的意义大家可以自己摸索。
3、下一步就是通过node.js中的https模仿浏览器向b站服务器发送请求来获取数据,请求地址就是我们上面找到的URL,请求类型为get,具体代码如下:
'use strict'
const http = require('https');
const url = require('url');
var biliUrl = `https://bangumi.bilibili.com/web_api/season/
index_global?page=1&page_size=20&version=0
&is_finish=0&start_year=0&tag_id=&index_type=1
&index_sort=0&quarter=`;
http.get(biliUrl, (res) => {
var data = ''; //接口数据
res.on('data', (chunk) => {
data += chunk; //拼接数据块
});
res.on('end', function() {
let json = JSON.parse(data); //解析json
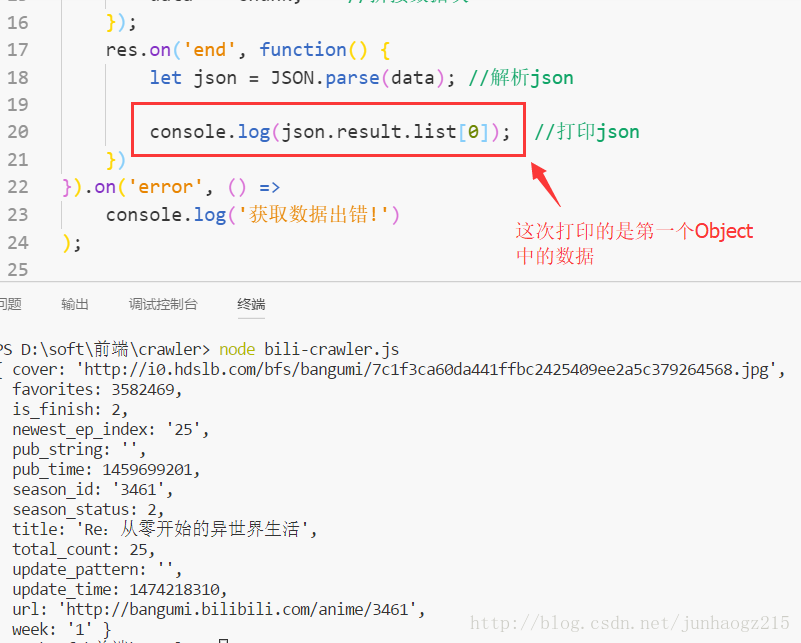
console.log(json); //打印json
})
}).on('error', () =>
console.log('获取数据出错!')
);
运行后控制台效果如下(其中每一个Object对象中都存在一部番剧的信息):
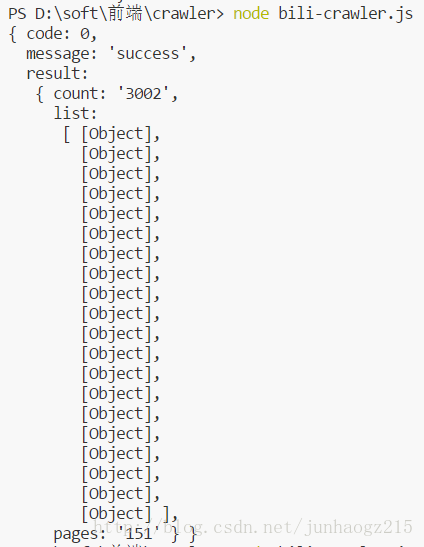
下面是第一个obj对象里包含的内容,其中有番剧名(title),番剧图片连接(cover),番剧url(url),番剧更新时间(week)等信息.
版权声明:本文为junhaogz215原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。