B树(B-tree)
- 概念:
B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个),数据库索引技术里大量使用者B树和B+树的数据结构,让我们来看看他有什么特点;
每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。
- 规则:
(1)排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
(2)子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
(3)关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
(4)所有叶子节点均在同一层、叶子节点包含了关键字和关键字记录的指针
- B树的查询流程:
如上图我要从上图中找到E字母,查找流程如下
(1)获取根节点的关键字进行比较,当前根节点关键字为M,E<M(26个字母顺序),所以往找到指向左边的子节点(二分法规则,左小右大,左边放小于当前节点值的子节点、右边放大于当前节点值的子节点);
(2)拿到关键字D和G,D<E<G 所以直接找到D和G中间的节点;
(3)拿到E和F,因为E=E 所以直接返回关键字和指针信息(如果树结构里面没有包含所要查找的节点则返回null);
特点:
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来)把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度;
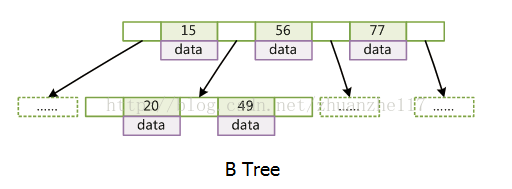
B+树
- 概念
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。为什么说B+树查找的效率要比B树更高、更稳定;我们先看看两者的区别
只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。
- 规则
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
(4)非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现);
- 特点
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;(举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间))
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定(任何关键字的查找必须走一条从根节点到叶子节点的路径,所有关键字的查询路径相同,所以查询效率相当);
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
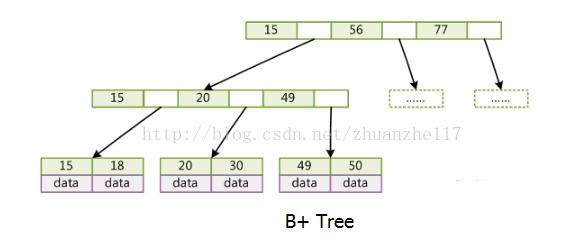
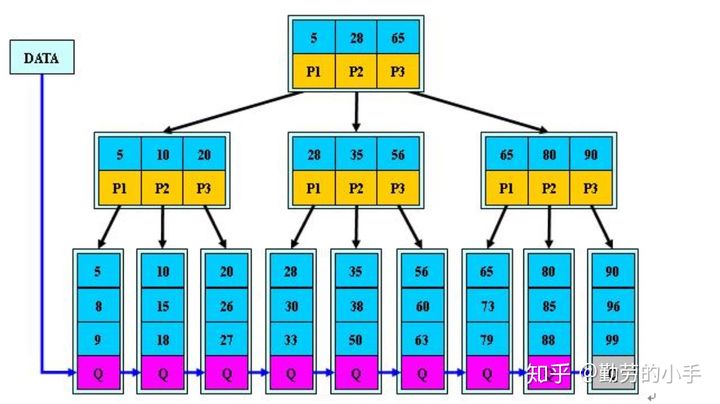
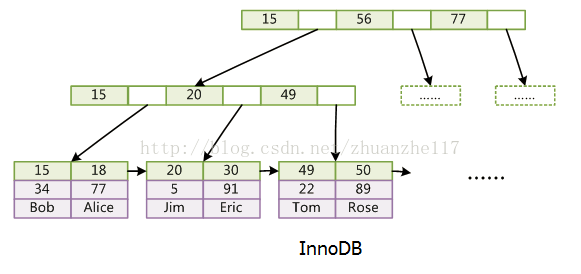
在MySQL中,最常用的两个存储引擎是MyISAM和InnoDB,它们对索引的实现方式是不同的。
MyISAM
data存的是数据地址。索引是索引,数据是数据。索引放在XX.MYI文件中,数据放在XX.MYD文件中,所以也叫非聚集索引。
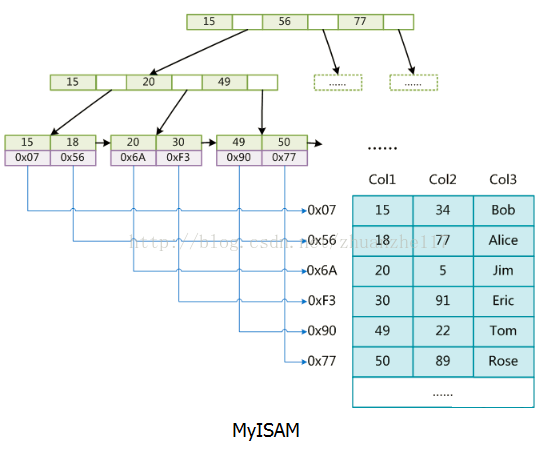
InnoDB
data存的是数据本身。索引也是数据。数据和索引存在一个XX.IDB文件中,所以也叫聚集索引。
文章参考: