一、分类的主要思想
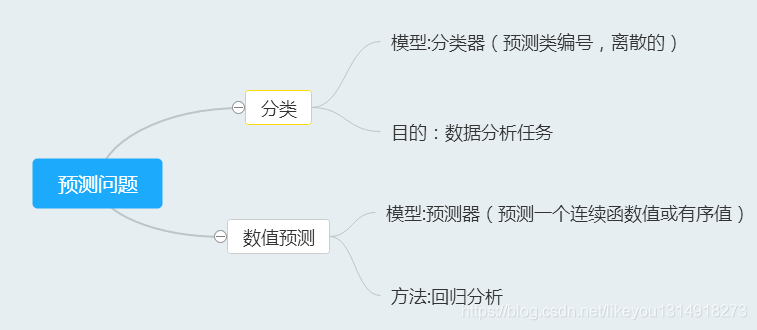
分类是一种重要的数据分析形势,它提取刻画重要数据类的模型。这种模型称为分类器,预测分类(离散的、无序的)类标号。
例如:可以建立一个分类模型,把银行贷款申请划分成“安全”或"危险";销售数据的“是”或“否”;等等。这些类别可以用离散值表示,其中值之间的次序没有意义。
数据分析任务都是分类,都需要构造一个模型或分类器来预测类标号。
销售经理希望预测给定的顾客将花多少钱。该数据分析任务就是数值预测,其中构造的模型预测一个连续值函数或有
序值,而不是类标号。这种模型是预测器。回归分析是数值预测最常用的统计学方法。(当然还存在其他数值预测方法)。
分类和数值预测是预测问题的两种重要类型。本文主要讲述分类。

二、分类的步骤
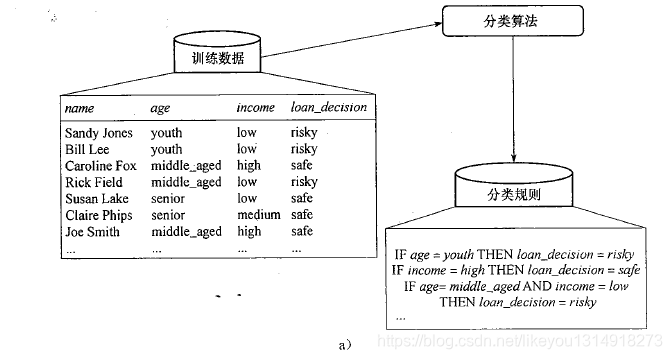
数据分类是一个两阶段过程,包括学习阶段(构建分类模型)和分类阶段(使用模型预测给定数据的类标号)
在第一阶段,建立描述预先定义的数据类或概念集的分类器。这是学习阶段(或训练阶段),其中分类算法通过分析或从训练集“学习”来构造分类器。训练集中提供了每个训练元组的类标号,这一阶段也称为监督学习(即分类器的学习在被告知每个训练元组属于哪个类的“监督”下进行的)。它不同于无监督学习(或聚类),每个训练组的类标号是未知的,并且要学习的类的个数或集合也可能事先不知道。
在第二阶段,使用模型进行分类。首先评估分类器的预测准确率。如果使用训练集来度量分类器的准确率,则评估可能是乐观的,因为分类器趋向于过分拟合该数据(即在学习期间,它可能包含了训练数据中的某些特定的异常,这些异常不在一般数据集中出现)。

三、分类的基本技术(部分)
3.1 如何建立决策树分类器
决策树归纳是从有类标号的训练元组中学习决策树。决策树是一种类似于流程图的树结构。一个典型的决策树如下图所示
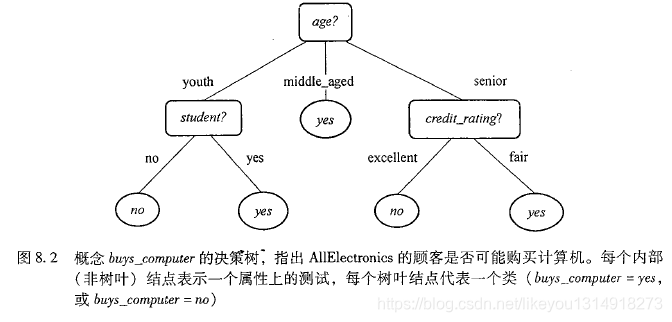
属性选择度量是一种选择分裂准则。如1.信息增益;2.基尼指数
在决策树创建时由于数据中的噪声和离群点,往往需要通过剪枝方法处理这种过分拟合数据问题。
3.2 贝叶斯分类器
贝叶斯分类方法是统计学分类方法。它们可以预测类隶属关系的概率。
贝叶斯分类基于贝叶斯定理。分类算法的比较研究发现,一种称为朴素贝叶斯分类法的简单贝叶斯分类法可以与决策树和经过挑选的神经网络分类器相媲美。
(1)贝叶斯定理: P(H|X)是后验概率;P(H)是先验概率
(2) 朴素贝叶斯分类
或简答贝叶斯分类方法
计算方法可参考教材《数据挖掘概念与技术第三版》。
例子:使用朴素贝叶斯分类预测类标号
3.3 基于规则的分类器
IF-THEN规则分类;决策树提取规则;使用顺序覆盖算法的规则归纳。
四、评估和比较分类方法
精度、召回率
----------后续用到在补充--------------