这两天在网上找了很多博客资料看,有些博文写的很好,但总感觉还是漏了一点东西,让我一直有些地方搞不懂,最终还是看了原论文(偷懒不行啊。。。)。这里就记录一下我的理解,肯定还是有不全的地方,仅供参考。
先附上原论文:https://paperswithcode.com/method/xlnet
pytorch版本代码:https://github.com/huggingface/transformers/blob/master/src/transformers/models/xlnet
前言
XLNet提出的目的就是为了整合传统语言模型和BERT的优点,同时避免掉它们的缺点:
1.BERT是降噪自编码语言模型(denoising auto-encoding,DAE),其优点就是可以兼顾上下文信息,缺点有两点:(a)预训练的时候会随机mask掉15%的tokens,但是在下游任务finetune的时候不会出现[MASK]这个符号,这就导致了pretrain和finetune的不一致;(b)因为随机mask掉15%的tokens,因此在预测其中一个被mask的token的时候,也是看不到其他被mask的tokens,这也就是BERT的一个假设:被mask的tokens之间相互独立。但是这在实际中不可能满足这个假设。
2.传统语言模型是自回归模型(AR),优点就是没有BERT的这些问题,但是其缺点也很明显:无法兼顾上下文信息。
作者提出了XLNet,还是AR模型,但是可以在兼顾上下文信息的同时避免掉BERT的这些缺点。XLNet核心思想主要包括一下几点:
1.排列语言模型(Permutation Language Modeling,PLM),通过对序列中tokens的所有排列组合进行建模来兼顾上下文信息。比如,一个长度为T的序列,共有T!种排列组合。
2.双流自注意力(Two-Stream Self-Attention),排列语言模型想法很好,但是直接使用transformer的self-attention会导致一个问题(不知道要预测的是哪个token,这个后面会详细讲),所以提出了Two-Stream Self-Attention来进行实现。
3.结合了transformer-XL的模型结构,解决长文本问题
4.使用更大和更高质量的数据集来进行预训练,这里借鉴了GPT的思想
排列语言模型
因为AR模型只能获取序列的上文信息,看不到下文的tokens。那有什么办法可以让AR模型同时看到上下文信息呢?作者就想到了既然改不了AR模型的特性,那就更改输入序列,通过对序列中的tokens进行排列组合,就可以让每个token既看到上文tokens,又能看到下文的tokens。
举个例子:一个输入序列为[x1,x2,x3,x4,x5,x6],那么对其所有的token进行排列组合,就有6!种组合,比如 [x3,x5,x1,x6,x4,x2],[x2,x4,x6,x1,x3,x5],[x6,x1,x2,x4,x3,x5],等等。
对于其中一种组合 [x3,x5,x1,x6,x4,x2],对于x4,它既可以看到上文的x1,x3,又可以看到下文的x5,x6,这样不就兼顾上下文信息了吗,很巧妙是不是。
通过让模型对所有的排列组合进行学习,那么就可以兼顾每个token的上下文信息。而且因为是AR模型,所以就没有BERT的缺点。
(这里插一点我个人的思考:既然要兼顾上下文信息,那直接把要预测的那个token放到序列的最后不就可以看到全部的上下文信息了,为什么要学习全部的排列组合呢,而且有些排列组合并不能看到某个token的全部上下文(比如上面的x4就看不到上文的x2)。为什么还要这样操作呢?
我在网上也找了一些回答,主要是两点:
1.如果直接把要预测的那个token放到序列的最后,虽然在第一层看不到目标token,但是后面几层就可以间接学到目标token的信息,造成信息泄露
2.只 mask 一个词的结果是预测这个词时可用的上下文变得多了,使得预测该词这个任务变得简单了,而一个 (相对)trivial 的任务无法让模型学到更有用的信息
如果有其他的想法欢迎在评论区留言~
)
为了实现这一点,作者提出了下面的目标函数:
XLNet maximizes the expected log likelihood of a sequence w.r.t. all possible permutations of the factorization order.
其中ZT表示序列[1,2,…,T]的所有可能的排列组合,z是其中一种排列,zt表示z中的第t个token,z<t表示z中的前t-1个tokens。通过最大化所有排列的期望对数似然概率来优化模型。
另外说明一点,模型并不更改输入序列的token顺序,也就是说输入模型的自始至终都是原来的顺序[x1,x2,x3,x4,x5,x6],这也是为了保证与finetune时一致,因为下游任务finetune的时候输入模型的就是序列本身的顺序。
tokens的排列组合是通过transformer中的attention mask来实现的,通过attention mask可以让token看到相应的上下文tokens。
这点不难理解,因为传统的AR模型就是一个下三角的attention mask来保证每个token看不到下文的tokens。
下文是论文给的一个例子,可以看出输入模型的序列顺序并没有改变,只是通过attention mask实现排列组合。
双流自注意力
排列语言模型的想法可以实现兼顾上下文信息的目的,但是如果直接使用标准的transformer self-attention会有问题。
主要问题就是,如果直接使用标准的transformer self-attention,那么得到的hθ(xz<t )和要预测的目标token位置是无关的,这就导致不论要预测的是哪个位置的token,模型最终输出的分布都是一样的,这就导致模型学不出有用的信息。
对于传统的AR模型,要预测的位置就是下一个token,这很明确。
但是对于XLNet,序列是经过排列组合的,那么多种排列组合谁知道下一个要预测的token是原始输入序列[x1,x2,…,xT]中的哪一个呢?作者在附录里给了例子做解释
比如对于两种排列组合z(1)= [x1,x2,x4,x5,x3,x6]和 z(2)=[x1,x2,x4,x5,x6,x3],要预测第t=5位置上的token,那么z(1)<t=z(2)<t=z<t= [x1,x2,x4,x5],而要预测的z(1)t=i=x3 ≠ j=x6=z(2)t,但是使用标准的transformer self-attention得出的模型预测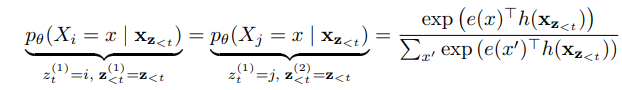
是一样的,这明显是不合理的。
为了解决这个问题,作者对self-attention进行了改进,将目标token的位置引入,使用gθ(xz<t , zt)。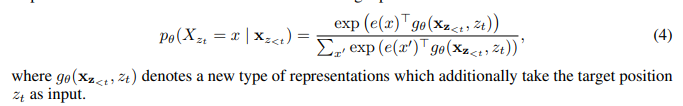
但是如何计算gθ(xz<t , zt)呢?如果直接使用标准的transformer会有两点矛盾:
1.在预测位置zt的token时,需要引入目标token的位置zt,但是目标token的信息content不能引入,否则目标信息泄露,目标函数会变得过于简单,模型学不出东西
2.但是在预测其他位置zj(j>t)的token时,需要引入zt位置token的信息content以提供全部的上下文信息。
为了解决这个矛盾,就考虑将token的位置信息和content信息分开,需要用哪个就用哪个,这就是双流自注意力:
1.content stream:和标准的transformer类似,编码上下文和目标token自身的content信息
2.query stream:只编码上下文xz<t的文本信息和目标token的位置信息,不使用目标token的content信息
实际计算的方式如下: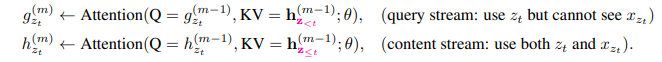

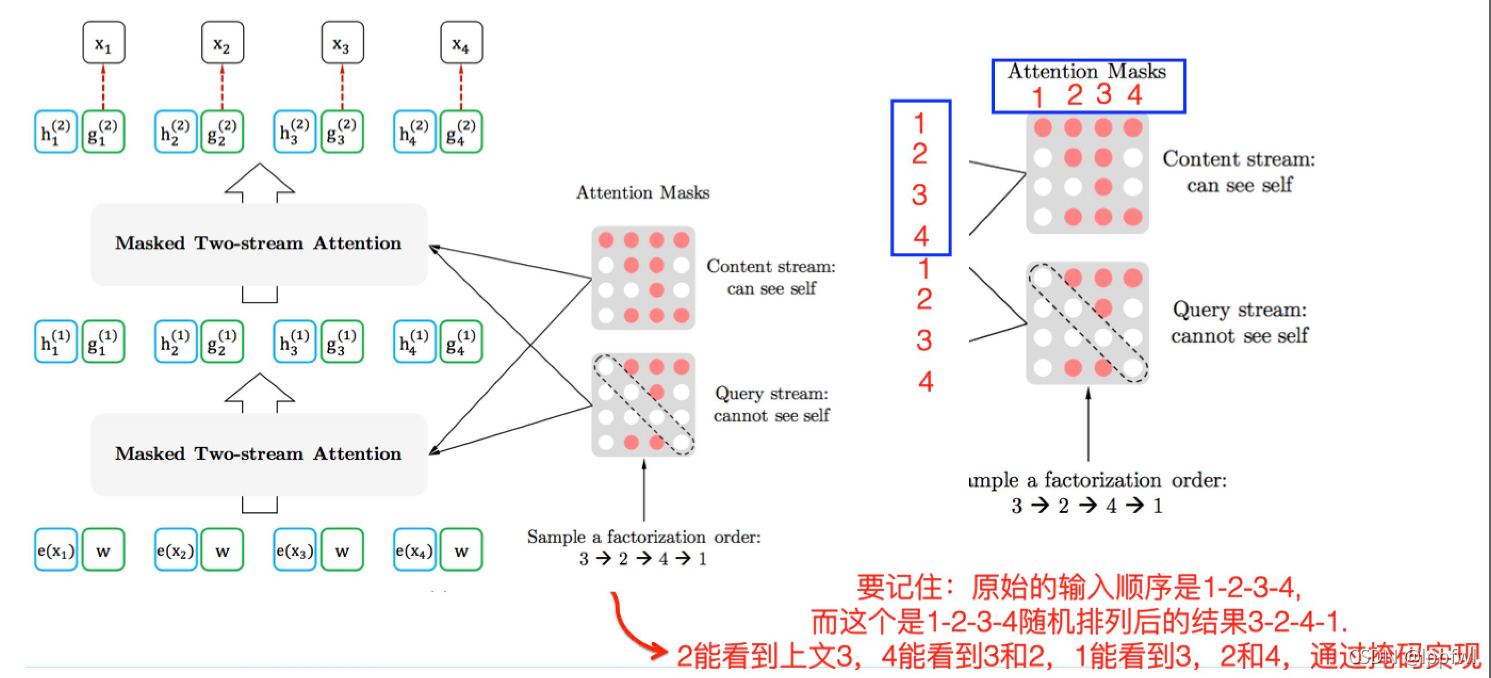
(图片来源:https://zhuanlan.zhihu.com/p/70257427)
在finetune的时候,去掉query stream,只将content stream作为标准的transformer使用即可。
局部预测
排列语言模型虽然has serveral benfits,但是不好训练且收敛速度慢,所以作者为了减小训练难度,对于每一种排列组合,只预测最后几个tokens。作者设置了一个超参数K,将排列组合z划分成两段,预测最后的1/K的tokens。
这种方式感觉和BERT选取15%的tokens进行mask很像,只预测序列的一部分tokens。论文中K取值是6或者7,所以1/K差不多也是15%
Transformer-XL
作者还结合了Transformer-XL的两个重要的思想来解决长序列输入问题:
1.相对位置编码,我暂时还没弄懂XLNet中的位置编码是怎么操作的,后面看了源码和Transformer-XL的论文再过来补充吧。。。
2.片段循环机制,这个的话就是Transformer-XL中利用前面片段的信息来建立长程依赖的方法,在下一个片段输入前面片段的隐层输出。
在XLNet中,片段循环机制的实现,作者进行了介绍,简单来说就是将前一个片段的1~m层的输出对应的拼接到下一片段对应层的输入来实现对前面片段信息的利用。

先写到这,看完源码再回来补充了
原创不易,转载请征得本人同意并注明出处!