文章目录
导读
我们都知道,在RR级别下,MySQL的InnoDB引擎通过MVCC(多版本并发控制,Multi-Version Concurrency Control)机制,解决了脏读和不可重复读的问题,同时无锁的设计极大提高了其性能。但是MVCC不能解决幻读的问题。因此,InnoDB引擎使用行锁来解决这个问题。在本文中,首先探讨在MySQL中的幻读(Phantom Rows)究竟是怎样一种现象,然后再对InnoDB中的行级锁的实现进行讨论,并探究各种情况下加锁的具体情况。
准备
在开始之前,首先要说明本文的文档和实验都基于MySQL8.0版本,用到的表和数据如下。
# 建表信息
CREATE TABLE `lock_test` (
`id` int NOT NULL AUTO_INCREMENT,
`num` int DEFAULT NULL,
`no_index` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `num` (`num`)
) ENGINE=InnoDB AUTO_INCREMENT=29 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
# 插入数据
insert into lock_test(id,num,no_index) values(15,20,5),(20,30,15),(25,40,20);
幻读(Phantom Rows)
什么是幻读?
在网络上,关于MySQL的RR级别,能否解决幻读问题其实有一定的争议,有两种常见的说法是RR可以解决幻读问题以及RR可以部分解决幻读问题,但不能完全解决。在讨论能否解决幻读问题(Phantom Rows)之前,首先要清楚什么是幻读问题。在ANSI SQL-92标准和MySQL的官方文档中,对幻读都有着明确的定义。
# ANSI SQL-92 (P1和P2分别是Dirty read和Non-repeatable read)
P3 ("Phantom"): SQL-transaction T1 reads the set of rows N that satisfy some <search condition>. SQL-transaction T2 then executes SQL-statements that generate one or more rows that satisfy the <search condition> used by SQL-transaction T1. If SQL-transaction T1 then repeats the initial read with the same <search condition>, it obtains a different collection of rows.
# MySQL8.0 doc
The so-called phantom problem occurs within a transaction when the same query produces different sets of rows at different times. For example, if a SELECT is executed twice, but returns a row the second time that was not returned the first time, the row is a “phantom” row.
可以看到,phantom rows所指是在返回结果是一个集合(set)的时候,前后两次查询返回结果不一致的问题。MySQL文档中的举例为:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
假设原有id为90和102的记录,事务T1中执行该查询,T2执行插入id为101的记录并提交,T1再次执行该查询,两次结果不一致,即发生了幻读问题。个人认为,幻读类似于范围查询的不可重读问题。
REPEATABLE READ级别下有没有幻读?
在厘清幻读的定义后,再来看MySQL的RR级别是否解决了它。答案是肯定的。由于MySQL是通过MVCC和行级锁的机制实现Repeatable Read,不如对快照读和当前读分别进行讨论。对于快照读(snapshot read)来说,一个事务中读到的都是记录的同一快照版本,显然不会出现幻读;对于当前读(current read),MySQL通过Next-key Locks的机制锁定索引间的区间,也解决了幻读问题。
那么,MySQL的RR级别只能部分解决幻读问题是怎么来的呢?我观察了网络上的此类说法,它们通常承认RR可以解决上述提到的幻读问题,但是将下面一种情况也归结到幻读问题,并认为RR级别下没有解决它。
# transcationA
begin;
select * from lock_test where id = 50; # empty
# transcationB
begin;
insert into lock_test(id,num) values (50,20); #插入成功
commit;
# transcationA
insert into lock_test(id,num) values (50,20); # 插入失败 id为50的记录已存在
在事务A中,select语句观测到表中没有id为50到记录,此后的插入操作却出现失败。对于事务A,这条id为50的记录就如同幻影。但是,显然可以看到,这类问题并不符合幻读问题的定义,并且只有在无锁的RR实现中才会产生。如果RR级别的实现本身就是用S/X锁来完成的,就不会出现这种问题。所以,个人认为这类问题是用乐观锁的方式实现可重复读的必然代价,但不能将之称为幻读问题。
因此,MySQL的REPEATABLE READ级别,完全解决了幻读问题,实际上达到了ANSI标准下的Serializable级别。
InnoDB中行级锁的实现
对于当前读,InnoDB是如何解决幻读问题的呢?这需要从InnoDB中行级锁的实现说起。
Record Locks
顾名思义,Record Lock是加在记录上的锁。例如 select * from lock_test where id =20 for update就会为该记录在主键索引上添加一道Record Lock。值得注意的是,Record Lock是添加在索引上的,如果没有索引,InnoDB会为表创建一个隐藏的聚簇索引,并将锁加在这个索引上(Record locks always lock index records, even if a table is defined with no indexes. For such cases, InnoDB creates a hidden clustered index and uses this index for record locking)。这里说到的索引包括聚簇索引、唯一索引和普通索引,根据查询条件不同Record Lock会添加在不同索引上。
Gap Locks
通过Record Lock,数据库可以避免脏读和不可重复读的发生(根据数据库的隔离等级),但不能阻止幻读的发生。为了防止幻读的发生,需要在索引之间的区间上加Gap Lock。
Gap Lock 是加在索引中一段区间上的锁,它可以加在两个索引记录中间,也可以加在第一个索引记录之前或者最后一个索引记录之后(InnoDB中用supremum pseudo-record来标示比索引中的所有值都大的值,从而给索引上的最后一个区间加锁,但它不是一条真实的记录 )。Gap Lock不会锁定索引本身。关于Gap Lock,有以下值得关注的问题:
- 与Record Lock不同,Gap Lock的存在只是为了防止其他事务在区间内插入记录(即可能产生幻读的操作),它不区分读写锁(存在X GAP LOCK和S GAP LOCK,但是两者没有区别),也不会互相冲突。换言之,在一段区间上可以加多道Gap Lock。
- 当使用唯一索引查询一个唯一值的时候,也不会用到Gap Lock。例如
select * from lock_test where id=20就不会在任何区间加锁,但`select * from lock_test where id<20。依然会对(-∞,20)的区间加Gap Lock。
Next-Key Locks
Next-Key Lock是Record Lock和Gap Lock的组合,它锁定索引上的一条记录和这条记录之前到上一条索引记录的区间。对于本文所用的表,可能的Next Key Lock有:
(-∞,20]
(20,30]
(30,40]
(40,+∞)
根据定义可知,Next-Key Lock 锁定的区间是前开后闭的,但是由于最后一个区间的上界是正无穷所以不能闭合。当进行一次如下的查询:
select * from lock_test where num=30 for update;
会添加哪些锁呢?
InnoDB会在索引上的(20,30]区间内添加一个Next-Key Lock,在(20,30)区间内添加一个Gap Lock,展开来讲就是对(20,30)(30,40)两个区间加了Gap Lock,对num=30的记录添加了Record Lock。
通过实验来验证:
# session1
start transaction;
select * from lock_test where num = 30 for update;
# session2
start transaction;
select * from lock_test where num = 30 for update; # 阻塞 在此有Record Lock
select * from lock_test where num = 25 for update; # 非阻塞 在此无Record Lock
insert into lock_test(num) value (25);# 阻塞
insert into lock_test(num) value (35);# 阻塞 这两处的插入操作被阻塞,说明有Gap Lock
delete from lock_test where num=25;# 非阻塞
update lock_test set num=20 where num=25;# 非阻塞
insert into lock_test(num) value (20);# 阻塞
insert into lock_test(num) value (40);# 非阻塞
前六个SQL语句的结果都很容易理解,但是对于最后两个语句,两边都是开区间,为什么执行结果不一样呢?结合图示来看就很好理解。
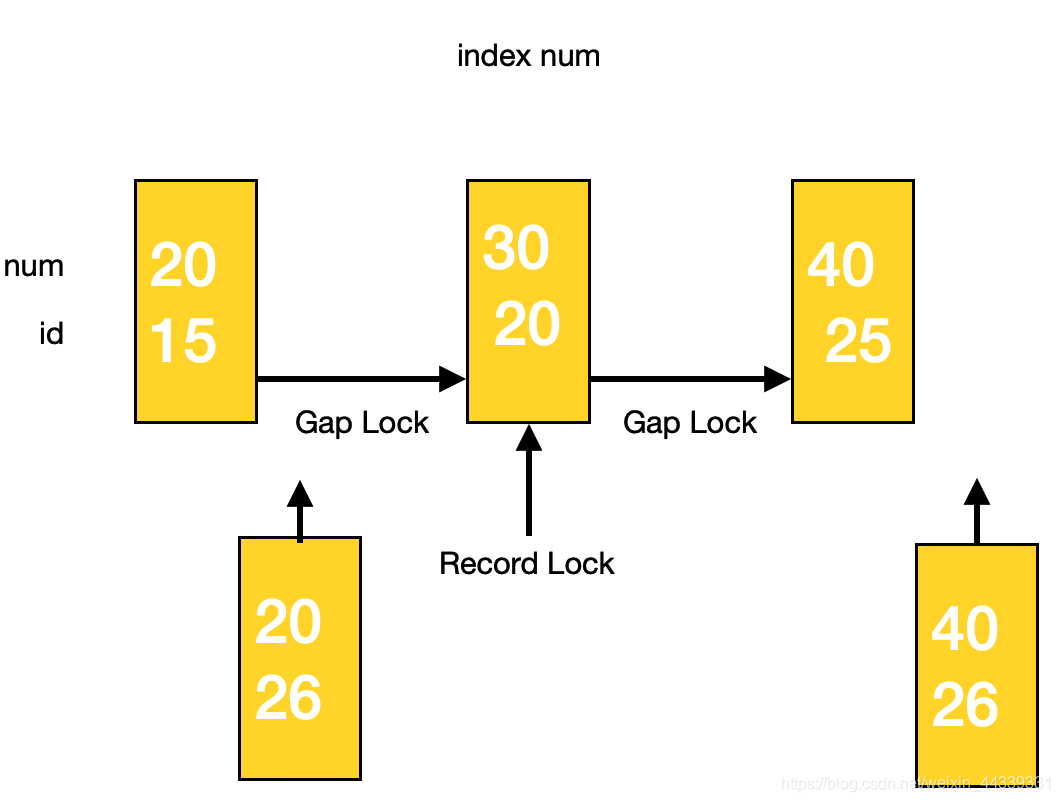
由于自增主键id的存在,插入值为20的新记录会落入Gap Lock的区间,而插入值为40的则不会。我们自行设定主键可以验证这一点。
insert into lock_test(id,num) values (10,20)# 非阻塞
insert into lock_test(id,num) values (18,20)# 阻塞
insert into lock_test(id,num) values (23,40)# 阻塞
insert into lock_test(id,num) values (28,20)# 非阻塞
Insert Intention Locks
Insert Intention Lock(插入意向锁)与IX或IS锁不同,它在进行insert操作的时候在索引上的该区间内加锁。Insert Intention Lock 之间不互斥,但它与Gap Lock 和Next-Key Lock 冲突,这也是Gap Lock使得插入操作无法进行的原因。值得注意的是有Gap Lock时无法添加Insert Intention Lock 但有Insert Intention Lock 不会阻塞插入Gap Lock的操作。
对于一次插入操作,显然索引中没有对应的行可以加record lock;如果对于插入的区间添加Gap Lock,会阻塞该区间其他的插入操作,降低并发性。Insert Intention Lock正是这样一种机制,保证被Gap Lock锁定的区间内无法insert新的记录,同时insert 记录时不会阻塞区间内的其他insert操作。
# session1
start transaction;
select * from lock_test where num =30 for update;
# session2
start transaction;
insert into lock_test(num) values(25); #阻塞
# session1
start transaction;
insert into lock_test(num) values(25);
# session2
start transaction;
select * from lock_test where num =30 for update; # 非阻塞
AUTO-INC Locks和Predicate Locks for Spatial Indexes
AUTO-INC Lock是一种特殊的表级锁,它用来保证自增字段是唯一连续的。例如当多个事务同时向表中添加新记录时,自增主键会按照26、27、28……的顺序,而不会出现多个相同值,也不会出现不连续的情况。Predicate Locks for Spatial Indexes与SPATIAL索引有关,个人没有了解,也与主题无关,不再展开讨论。
加锁情况实验与总结
查询未添加索引的字段会加什么锁?同一条查询语句命中与否是否影响加锁情况?接下来,将从实验中探求对next-key lock机制的诸多疑问的答案。
performance_schema.data_locks
首先,在MySQL8.0中,用performance_schema.data_locks表取代了原有的information_schema.innodb_locks表来记录当前各事务持有锁的信息。原有的innodb_locks表只有在发生锁冲突的时候,才会产生一条记录。例如
begin;
select * from lock_test where num =30 for update;
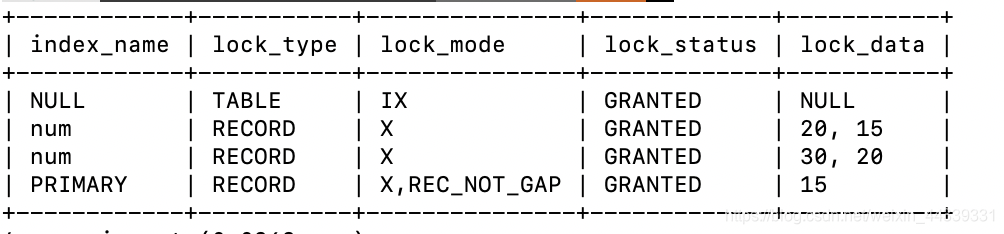
这个事务中实际上持有了锁,但在没有锁冲突的情况下,innodb_locks表依然为空。而在新的performance_schema.data_locks表中记录了所有的锁信息。执行上面的语句后,查询data_locks表可以得到:
select index_name,lock_type,lock_mode,lock_status,lock_data
from performance_schema.data_locks ;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bGCDUYo5-1598167441976)(/Users/sunpengxiang/Desktop/截屏2020-08-23 下午2.25.50.png)]
在data_locks表中我们重点关注下面几个字段:index_name记录锁所在索引的名称;lock_type记录锁的类型是行锁还是表锁;lock_mode记录锁的模式,图中的四个值分别表示IX锁,X Next key Lock,X Record Lock和X Gap Lock;lock_status表示当前锁的状态,granted表示持有锁,waiting表示等待锁;lock_data表示被锁定的数据,20表示锁定主键值为20的记录,30,20表示锁定加锁索引值为30,对应主键值为20的记录。
实验
将select操作大致分为对于单个值的查询和范围查询,然后对主键索引、非唯一辅助索引和无索引的字段,分查询命中和未命中两种情况进行实验。因此一共有2*3*212种情况。实验的步骤类似于:
begin;
select * from lock_test where num = 30 for update;
select index_name,lock_type,lock_mode,lock_status,lock_data
from performance_schema.data_locks ;
commit;
为了简洁起见,下面只展示select 语句和对应结果。
单值查询
主键索引
命中
select * from lock_test where id = 20 for update;
未命中
select * from lock_test where id = 18 for update;

非唯一辅助索引
命中
select * from lock_test where num = 30 for update;

未命中
select * from lock_test where num = 28 for update;

无索引
命中
select * from lock_test where no_index = 20 for update;

未命中
select * from lock_test where no_index = 18 for update;
范围查询
主键索引
命中
select * from lock_test where id < 20 for update;

未命中
select * from lock_test where id < 10 for update;

非唯一辅助索引
命中
select * from lock_test where num < 30 for update;
未命中
select * from lock_test where num < 20 for update;
无索引
与单值查询相同,都是锁定主键上的所有记录。
总结
无论范围查询还是单值查询,无论命中还是未命中,查询无索引的字段都会对表中的所有记录的主键上加Next-key Lock锁。有MySQL对这种情况进行了优化,会在找到目标记录后提前解锁(违法两段锁协议的做法)的说法,但本人未曾考证,不在此展开深入讨论。
其他情况见下表
单值查询 命中 未命中 主键索引 Record Lock Gap Lock 非主键唯一索引 命中记录上的Next-key Lock和下一记录上的Gap Lock;对应主键记录上加Record Lock Gap Lock 范围查询 命中 未命中 主键索引 查询各区间的Gap Lock +命中记录的Record Lock(会组成Next-key Lock) Gap Lock 非主键唯一索引 Next-key Lock;对应主键记录上加Record Lock Next-Key Lock