文章目录
基本概念
线性可分支持向量机
给定线性可分的训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为
w ∗ ⋅ z + b ∗ = 0 w^*·z+b^*=0w∗⋅z+b∗=0
以及相应的分类决策函数
f ( x ) = w ∗ ⋅ z + b ∗ f(x)=w^*·z+b^*f(x)=w∗⋅z+b∗
称为线性可分支持向量机。
函数间隔和几何间隔
我们可以用∣ ω x + b ∣ |\omega x+b|∣ωx+b∣来表示分类预测的确信程度。
这是点到直线距离计算公式的分子,越大,则距离越远,从而确信程度越高。
我们设类别标记为y ∈ { − 1 , + 1 } y \in \{-1,+1\}y∈{−1,+1},因此,确信程度为y ( ω ⋅ x + b ) y(\omega· x+b)y(ω⋅x+b)
函数间隔
对于给定的训练数据集T和超平面( ω , b ) (\omega,b)(ω,b)
定义超平面关于样本( x i , y i ) (x_i,y_i)(xi,yi)的函数间隔为
γ ^ i = y i ( ω ⋅ x i + b ) \widehat\gamma_i=y_i(\omega· x_i+b)γi=yi(ω⋅xi+b)
我们定义γ ^ = min i = 1 , . . . , N [ y i ( ω ⋅ x i + b ) ] \widehat\gamma=\min_{i=1,...,N}[y_i(\omega· x_i+b)]γ=i=1,...,Nmin[yi(ω⋅xi+b)]
函数间隔不仅表示了确信程度,还表示了正确性,当其为负数时,则为错误分类。
几何间隔
当我们同时等比例扩大ω \omegaω和b bb的时候,超平面不发生变化。
解释:
通常我们会认为:
y = x + 1 y=x+1y=x+1变成了y = 2 x + 2 y=2x+2y=2x+2。这显然不是同一条直线啊!
这样的理解是错误的,超平面应写成x − y + 1 = 0 x-y+1=0x−y+1=0,ω \omegaω也是针对( x , y ) (x,y)(x,y)的系数,因此,是变为2 x − 2 y + 2 = 0 2x-2y+2=02x−2y+2=0。
函数是函数,超平面是超平面!
虽然超平面不发生变化,但是函数间隔变大了。
也就是说,同一个超平面会对应不同的几何间隔,带来的损失也是不同的,我们需要规范化间隔。因此引入几何间隔。
我们对ω \omegaω加以约束,此时
γ i = γ ^ i ∥ ω ∥ \gamma_i=\frac{\widehat\gamma_i}{\|\omega\|}γi=∥ω∥γi
同时,
γ = min i = 1 , 2 , . . . , N γ ^ i ∥ ω ∥ \gamma=\min_{i=1,2,...,N}{\frac{\widehat\gamma_i}{\|\omega\|}}γ=i=1,2,...,Nmin∥ω∥γi
这就是点到直线的距离公式。
间隔最大化
线性可分的数据中,可以找到多个分类超平面进行分类。但SVM要求这个分类超平面满足间隔最大化的条件。
也就是说,离超平面最近的点,要尽可能地大,相当于一个求取最小当中的最大值的问题。
我们的判别函数是分类超平面,目标是让训练集离超平面最近的点的距离尽可能地大。此时,最优化问题可写成:
max w , b γ ^ \max_{w,b}{\widehat\gamma}w,bmaxγ
s . t . y i ( ω ⋅ x i + b ) ≥ γ ^ s.t.\ y_i(\omega ·x_i+b)\ge \widehat\gammas.t. yi(ω⋅xi+b)≥γ
然而该优化问题是没有解的,因为ω \omegaω与b bb可以无限等比例放大,因此该题转化为了:
max w , b γ \max_{w,b}{\gamma}w,bmaxγ
s . t . y i ( ω ⋅ x i + b ) ∥ ω ∥ ≥ γ s.t.\ \frac{y_i(\omega·x_i+b)}{\|\omega\|}\ge \gammas.t. ∥ω∥yi(ω⋅xi+b)≥γ
消除了ω \omegaω与b bb无限等比例放大的问题,仅关注了超平面的方向。
我们再做进一步限制,由于γ ^ \widehat\gammaγ可以等比例缩放,我们不妨让其等于1。
问题转化为了:
min w , b 1 2 ∥ ω ∥ 2 \min_{w,b}{\frac{1}{2}\|\omega\|^2}w,bmin21∥ω∥2
s . t . y i ( ω ⋅ x i + b ) − 1 ≥ 0 s.t.\ y_i(\omega ·x_i+b)-1\ge0s.t. yi(ω⋅xi+b)−1≥0
约束条件中,我们消除了∥ ω ∥ \|\omega\|∥ω∥,这是基于数学层面的消除,几何意义依然可以保留。
写出该形式的原因是:这样很符合一类成熟的优化问题:凸二次规划。
支持向量
在线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的样本点。
支持向量是使约束条件约束条件式等号成立的点。
支持向量机的解是稀疏的,在训练完成后,大部分样本都可以舍弃,最终模型只与支持向量有关。
间隔边界
H 1 : ω x + b = 1 H_1:\omega x+b=1H1:ωx+b=1
H 1 : ω x + b = − 1 H_1:\omega x+b=-1H1:ωx+b=−1
两个超平面相互平行,且没有点落在他们中间,H 1 H_1H1与H 2 H_2H2之间的距离称为间隔,为2 ∥ ω ∥ , \frac{2}{\|\omega\|},∥ω∥2,H 1 H_1H1与H 2 H_2H2称为间隔边界。
算法

Lagrange对偶


说明
Lagrange函数的作用?
将约束问题转化为无约束问题,起到了一个去约束的作用。
原问题也转化为了拉格朗日函数的最大化。
值得关注的是,这样的转化是有固定格式的。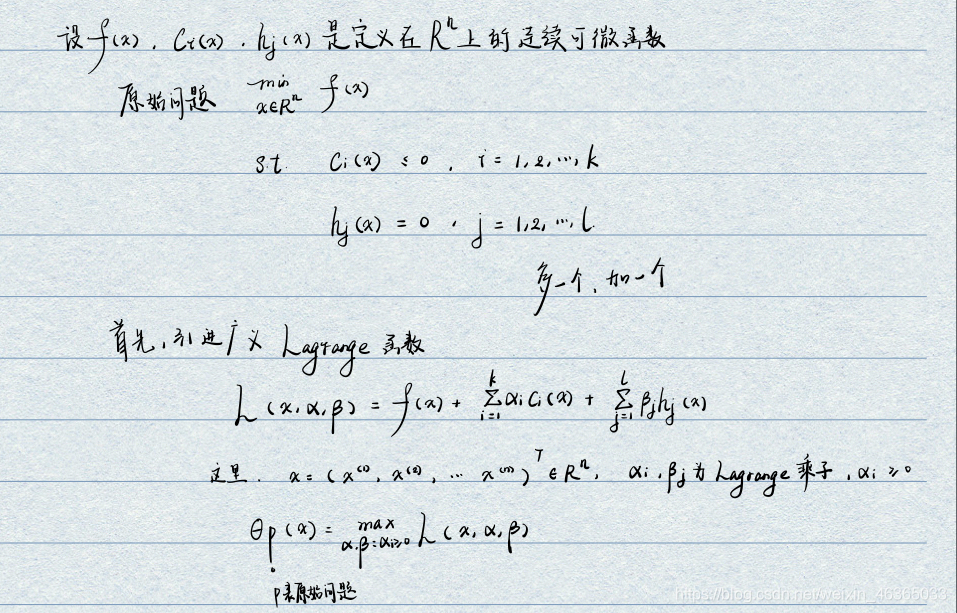
为什么要求取对偶问题?
我们的目的是为了求取ω \omegaω和b bb,然而在原始问题中,因为是minmax的结构,无法直接对其求导,因此要转化结构。
为什么可以交换极大极小?
定理-1:若原始问题和对偶问题都有最优值,则d ∗ = max min L a g r a n g e ≤ min max L a g r a n g e = p ∗ d^*=\max\min Lagrange\le \min\max Lagrange =p^*d∗=maxminLagrange≤minmaxLagrange=p∗
定理-2:1.假设f ( x ) f(x)f(x)和c i ( x ) c_i(x)ci(x)是凸函数,h j ( x ) h_j(x)hj(x)是放射函数;2.假设c i ( x ) c_i(x)ci(x)严格可行,即存在x,对所有的i有c i ( x ) < 0 。 , 则 存 在 c_i(x)\lt0。,则存在ci(x)<0。,则存在x^*, α ∗ ,\alpha^*,α∗,β ∗ \beta^*β∗,使得x ∗ x^*x∗为原始问题的解,α ∗ , β ∗ \alpha^*,\beta^*α∗,β∗是对偶问题的解。
满足定理二,因此两个问题求取的答案是等价的。
求取对偶问题后,如何得到最后的答案?
定理-3:假设f ( x ) f(x)f(x)和c i ( x ) c_i(x)ci(x)是凸函数,h j ( x ) h_j(x)hj(x)是放射函数;2.假设c i ( x ) c_i(x)ci(x)严格可行,即存在x,对所有的i有c i ( x ) < 0 c_i(x)\lt0ci(x)<0。则存在x ∗ x^*x∗,α ∗ \alpha^*α∗,β ∗ \beta^*β∗,使得x ∗ x^*x∗为原始问题的解,α ∗ , β ∗ \alpha^*,\beta^*α∗,β∗是对偶问题的解的充要条件是x ∗ x^*x∗,α ∗ \alpha^*α∗,β ∗ \beta^*β∗满足KKT条件(基于原始问题):
1.▽ x L ( x ∗ , α ∗ , β ∗ ) = 0 \bigtriangledown_xL(x^*,\alpha^*,\beta^*)=0▽xL(x∗,α∗,β∗)=0
2.α i ∗ c i ( x ∗ ) = 0 \alpha_i^*c_i(x^*)=0αi∗ci(x∗)=0
3.c i ( x ∗ ) ≤ 0 c_i(x^*)\le0ci(x∗)≤0
4.α i ∗ ≥ 0 \alpha_i^*\ge0αi∗≥0
5.h j ( x ∗ ) = 0 h_j(x^*)=0hj(x∗)=0
其中ω \omegaω的取值源于minLagrange中,而b bb的取值源于KKT-2。
在α ∗ \alpha^*α∗中至少有一个α j > 0 \alpha_j\gt0αj>0,此时对应的点就是支持向量。
算法更新


软间隔最大化
若线性可分样本中出现了噪声和特异点,使得数据线性不可分该如何处理?
我们引入了软间隔的概念,允许支持向量机在一些样本上不满足函数间隔大于1的约束。
我们对每一个样本点引入了一个松弛变量ξ i ≥ 0 \xi_i\ge 0ξi≥0。此时约束条件变为了:
y i ( ω ⋅ x i + b ) ≥ 1 − ξ i y_i(\omega·x_i+b)\ge1-\xi_iyi(ω⋅xi+b)≥1−ξi
松弛变量的意义指的是样本与“对应”的间隔边界的距离
另外我们再给予该问题一个惩罚,于是,原始问题可以表述为: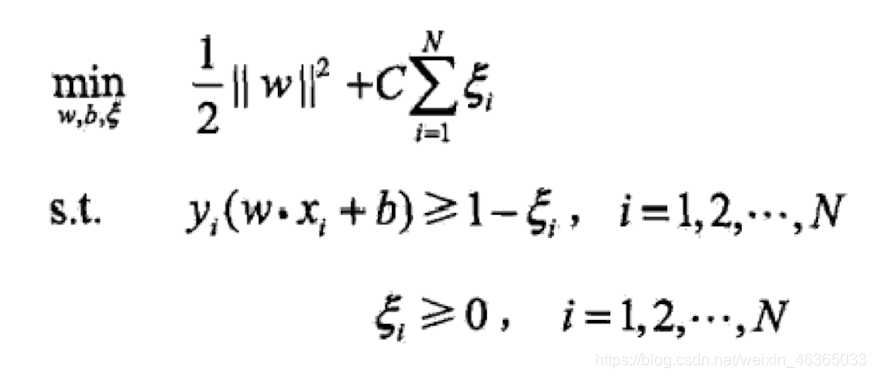
此时,优化目标的含义有两层:
1.间隔尽可能地大;
2.不满足约束样本尽可能少。
其中,C是一个超参数,起到了调和作用。
Lagrange对偶

线性不可分的情况下,b不唯一。
支持向量
由KKT条件-2,我们可以知道,对任一训练样本,总有α i ∗ = 0 \alpha_i^*=0αi∗=0或者y i ( ω ⋅ x + b ) = 1 − ξ i y_i(\omega·x+b)=1-\xi_iyi(ω⋅x+b)=1−ξi。
我们进行如下讨论:
1.α i ∗ = 0 \alpha_i^*=0αi∗=0,该样本对分类面无影响,样本点在间隔边界之外。
2.α i ∗ > 0 \alpha_i^*\gt0αi∗>0,支持向量。
| α i ∗ \alpha_i^*αi∗和ξ i \xi_iξi | 意义 |
|---|---|
| α i ∗ < C \alpha_i^*\lt Cαi∗<C、ξ = 0 \xi = 0ξ=0 | 该样本在间隔边界上 |
| α i ∗ = C \alpha_i^*= Cαi∗=C、0 < ξ < 1 0\lt\xi \lt10<ξ<1 | 该样本在间隔边界与超平面之间 |
| α i ∗ = C \alpha_i^*=Cαi∗=C、ξ = 1 \xi = 1ξ=1 | 该样本在超平面上 |
| α i ∗ = C \alpha_i^*= Cαi∗=C、ξ > 1 \xi \gt1ξ>1 | 该样本错误分类 |
为什么要限制α i \alpha_iαi在[ 0 , C ] [0,C][0,C]之间呢?
算法


合页损失函数
我们在之前的探讨中,我们的目标是让支持向量离超平面的几何距离尽可能地小,约束条件是,这样一个支持向量存在且其函数距离为1.而软间隔问题则更复杂一点。大致目标是保持最大间隔的前提下,让间隔边界之间的样本少一些,远一些,准一些。
我们现在引入一个新的函数来解释支持向量机。
∑ i = 1 N [ 1 − y i ( ω ⋅ x i + b ) ] + + λ ∥ ω ∥ 2 \sum_{i=1}^N[1-y_i(\omega·x_i+b)]_++\lambda\|\omega\|^2i=1∑N[1−yi(ω⋅xi+b)]++λ∥ω∥2
其中: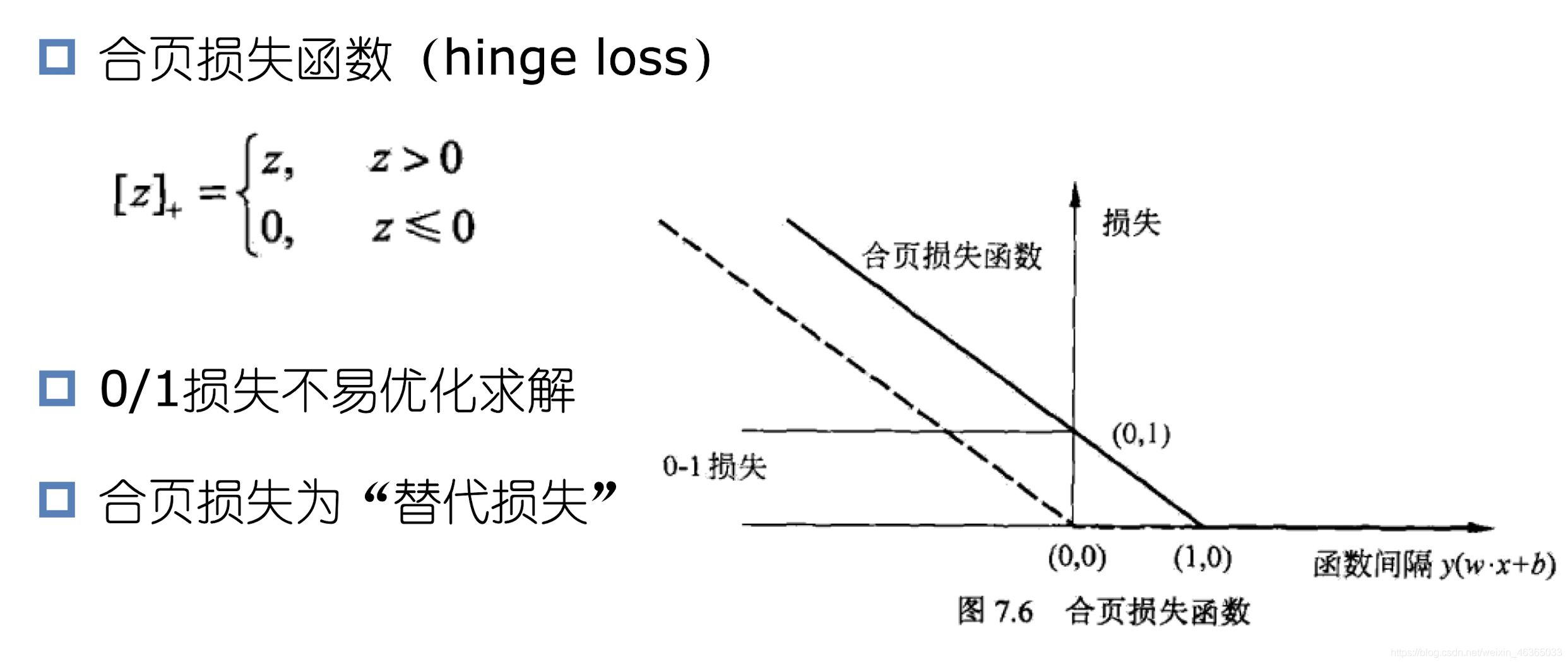
于是有:
也就是说,既要使分类确信度尽可能大,又要使间隔尽可能大。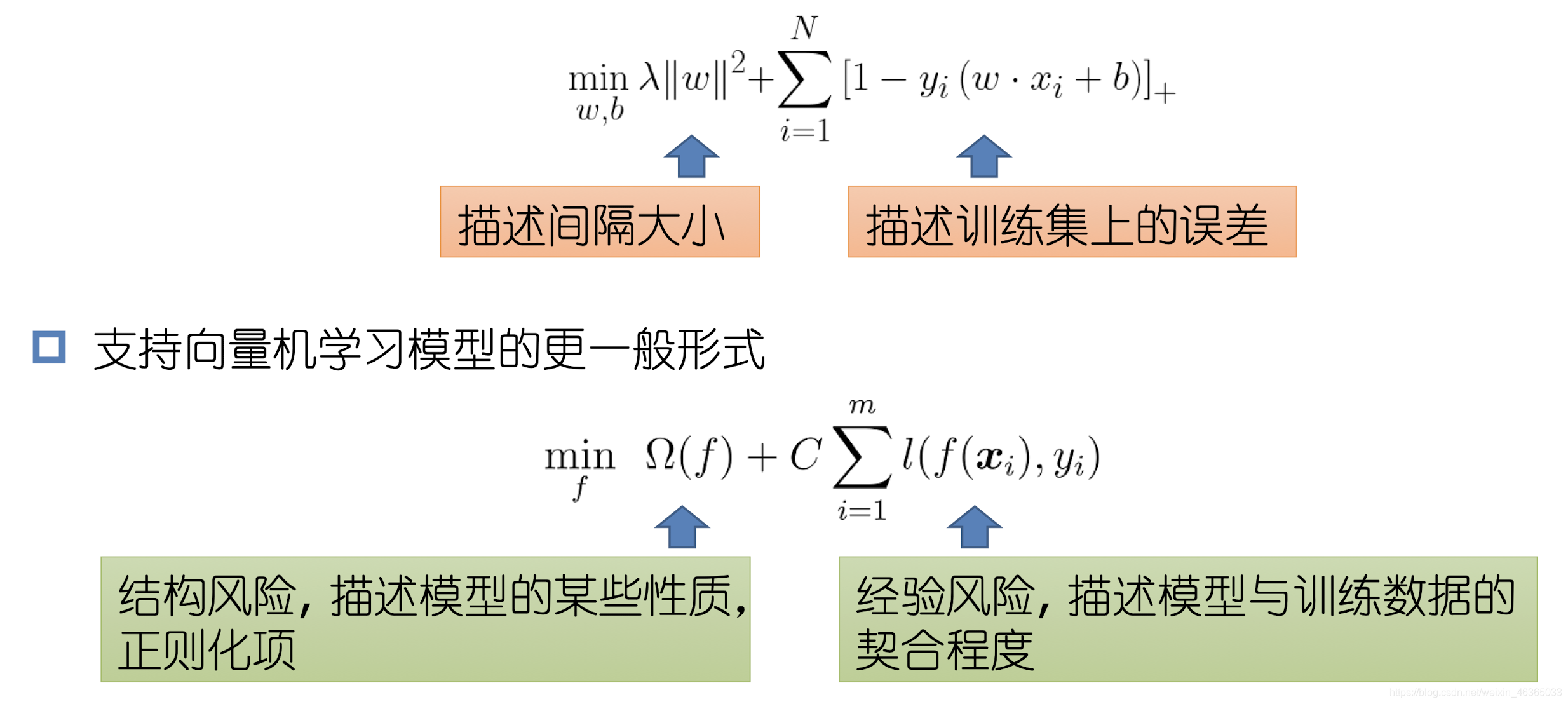
核函数与核方法
核技巧
若我们无法在当前空间找到一个可以正确划分两类样本的线性超平面,我们可以将样本从原始空间映射到一个更高维度的特征空间,使样本在这个空间内线性可分。
也就是说非线性问题通过非线性变换,转化为了线性问题。
我们设样本x xx映射后的向量为ϕ ( x ) \phi(x)ϕ(x),划分的超平面为f ( x ) = ω T ϕ ( x ) + b f(x)=\omega^T\phi(x)+bf(x)=ωTϕ(x)+b。
于是,以非线性支持向量机为例,我们的问题可以转化为:
综上所述,关于核技巧,操作方法两步走:
1.使用变换,将原始空间的数据映射到新空间;
2.在新空间中,使用线性分类的学习方法学习。
核函数
ϕ ( x ) \phi(x)ϕ(x)一般是无限维度的,我们可以不知道ϕ ( x ) \phi(x)ϕ(x)的显示表达,只要知道一个如下所示的核函数,则优化式依然可解。
κ ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) \kappa(x_i,x_j)=\phi(x_i)^T\phi(x_j)κ(xi,xj)=ϕ(xi)Tϕ(xj)
即核函数是两个向量的内积。
定理-4(Mercer)(充分非必要):只要一个对称函数所对应的核矩阵半正定,则它就能作为核函数来使用。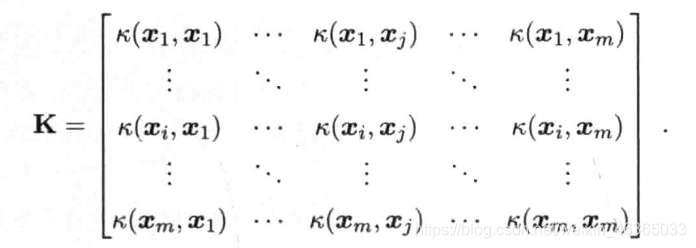
我们常用的核函数有:
注意
1.特征空间的选择对SVM的性能至关重要;
2.由于ϕ ( x ) \phi(x)ϕ(x)未知,难以确定什么样的核函数是合适的;
3.文本数据通常采用线性核,实在不行采用高斯核;
4.γ 1 κ 1 + γ 2 κ 2 \gamma_1\kappa_1+\gamma_2\kappa_2γ1κ1+γ2κ2也是核函数;
5.κ 1 κ 2 \kappa_1\kappa_2κ1κ2也是核函数;
6.g ( x 1 ) κ ( x 1 , x 2 ) g ( x 2 ) g(x_1)\kappa(x_1,x_2)g(x_2)g(x1)κ(x1,x2)g(x2)也是核函数。
支持向量机的表示函数为:
f ( x ) = ω T ⋅ x + b = ∑ α i y i ( x i ⋅ x j ) + b f(x)=\omega^T·x+b=\sum\alpha_iy_i(x_i·x_j)+bf(x)=ωT⋅x+b=∑αiyi(xi⋅xj)+b
于是
f ( x ) = ∑ i = 1 m α i y i κ ( x i , x j ) + b f(x)=\sum_{i=1}^m\alpha_iy_i\kappa(x_i,x_j)+bf(x)=i=1∑mαiyiκ(xi,xj)+b