1、概述
本章将介绍模型剩余的部分与数据加载与训练
2、GeneratorFullModel完整的生成器
2.1 金字塔网络(ImagePyramide)
该网络用于获取不同缩放比的照片
class ImagePyramide(torch.nn.Module):
"""
Create image pyramide for computing pyramide perceptual loss. See Sec 3.3
"""
def __init__(self, scales, num_channels):
super(ImagePyramide, self).__init__()
downs = {}
for scale in scales:
downs[str(scale).replace('.', '-')] = AntiAliasInterpolation2d(num_channels, scale)
self.downs = nn.ModuleDict(downs)
def forward(self, x):
out_dict = {}
for scale, down_module in self.downs.items():
out_dict['prediction_' + str(scale).replace('-', '.')] = down_module(x)
return out_dict测试代码
scales= [1, 0.5, 0.25, 0.125]
pyramide=ImagePyramide(scales,3)
pyramide_source=pyramide(source)
pyramide_source_list=[w2 for (w1,w2) in pyramide_source.items()]
figure,ax=plt.subplots(2,2,figsize=(8,4))
for i in range(2):
for j in range(2):
show_item=pyramide_source_list[(2*i)+j]
ax[i,j].imshow(show_item[0].permute(1,2,0).data)效果如下

2.2 Vgg19网络与感知损失(perceptual loss)
Vgg19是一个预训练好的网络,是风格转化中用到的一个经典网络,vgg不同卷积层的网络输出的多个特征映射。使用L1损失函数或平均绝对误差比较这些特征图。这些特征图包含图像的内容,但不包含外观。然后,感知损失计算出两个图像的内容有多相似。当然,我们希望生成的图像包含驱动图像的运动
下面代码主要实现一下功能
- 将输入进行按照指定的均值与方差进行normalize操作
- 取出vgg网络的第2,7,12,30层的特征输出并返回
class Vgg19(torch.nn.Module):
"""
Vgg19 network for perceptual loss. See Sec 3.3.
"""
def __init__(self, requires_grad=False):
super(Vgg19, self).__init__()
vgg_pretrained_features = models.vgg19(pretrained=True).features
self.slice1 = torch.nn.Sequential()
self.slice2 = torch.nn.Sequential()
self.slice3 = torch.nn.Sequential()
self.slice4 = torch.nn.Sequential()
self.slice5 = torch.nn.Sequential()
for x in range(2):
self.slice1.add_module(str(x), vgg_pretrained_features[x])
for x in range(2, 7):
self.slice2.add_module(str(x), vgg_pretrained_features[x])
for x in range(7, 12):
self.slice3.add_module(str(x), vgg_pretrained_features[x])
for x in range(12, 21):
self.slice4.add_module(str(x), vgg_pretrained_features[x])
for x in range(21, 30):
self.slice5.add_module(str(x), vgg_pretrained_features[x])
self.mean = torch.nn.Parameter(data=torch.Tensor(np.array([0.485, 0.456, 0.406]).reshape((1, 3, 1, 1))),
requires_grad=False)
self.std = torch.nn.Parameter(data=torch.Tensor(np.array([0.229, 0.224, 0.225]).reshape((1, 3, 1, 1))),
requires_grad=False)
if not requires_grad:
for param in self.parameters():
param.requires_grad = False
def forward(self, X):
#对输入进行归一化
X = (X - self.mean) / self.std
h_relu1 = self.slice1(X)
h_relu2 = self.slice2(h_relu1)
h_relu3 = self.slice3(h_relu2)
h_relu4 = self.slice4(h_relu3)
h_relu5 = self.slice5(h_relu4)
out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
return out测试代码
vgg = Vgg19()
x_vgg=vgg(source)
感知损失的关键代码如下
检测配置文件中是否有感知损失的权重设定
if sum(self.loss_weights['perceptual']) != 0:
value_total = 0
#循环金字塔网络输出的各种大小的图片
for scale in self.scales:
#生成图片的特征图
x_vgg = self.vgg(pyramide_generated['prediction_' + str(scale)])
#真实图片的特征图
y_vgg = self.vgg(pyramide_real['prediction_' + str(scale)])
#根据权重进行加权
for i, weight in enumerate(self.loss_weights['perceptual']):
value = torch.abs(x_vgg[i] - y_vgg[i].detach()).mean()
value_total += self.loss_weights['perceptual'][i] * value
loss_values['perceptual'] = value_total2.3 判别器(discriminator)¶
这里的判别器是一种不太规范的叫法,这里的判别器只是将图像与关键帧信息用来生成高斯的置信图,并加以返回
class DownBlock2d_disc(nn.Module):
"""
Simple block for processing video (encoder).
"""
def __init__(self, in_features, out_features, norm=False, kernel_size=4, pool=False, sn=False):
super(DownBlock2d_disc, self).__init__()
self.conv = nn.Conv2d(in_channels=in_features, out_channels=out_features, kernel_size=kernel_size)
if sn:
self.conv = nn.utils.spectral_norm(self.conv)
if norm:
self.norm = nn.InstanceNorm2d(out_features, affine=True)
else:
self.norm = None
self.pool = pool
def forward(self, x):
out = x
out = self.conv(out)
if self.norm:
out = self.norm(out)
out = F.leaky_relu(out, 0.2)
if self.pool:
out = F.avg_pool2d(out, (2, 2))
return out
class Discriminator(nn.Module):
"""
Discriminator similar to Pix2Pix
"""
def __init__(self, num_channels=3, block_expansion=64, num_blocks=4, max_features=512,
sn=False, use_kp=False, num_kp=10, kp_variance=0.01, **kwargs):
super(Discriminator, self).__init__()
down_blocks = []
for i in range(num_blocks):
down_blocks.append(
DownBlock2d_disc(num_channels + num_kp * use_kp if i == 0 else min(max_features, block_expansion * (2 ** i)),
min(max_features, block_expansion * (2 ** (i + 1))),
norm=(i != 0), kernel_size=4, pool=(i != num_blocks - 1), sn=sn))
self.down_blocks = nn.ModuleList(down_blocks)
self.conv = nn.Conv2d(self.down_blocks[-1].conv.out_channels, out_channels=1, kernel_size=1)
if sn:
self.conv = nn.utils.spectral_norm(self.conv)
self.use_kp = use_kp
self.kp_variance = kp_variance
def forward(self, x, kp=None):
feature_maps = []
out = x
if self.use_kp:
heatmap = kp2gaussian(kp, x.shape[2:], self.kp_variance)
out = torch.cat([out, heatmap], dim=1)
for down_block in self.down_blocks:
feature_maps.append(down_block(out))
out = feature_maps[-1]
prediction_map = self.conv(out)
return feature_maps, prediction_map
class MultiScaleDiscriminator(nn.Module):
"""
Multi-scale (scale) discriminator
"""
def __init__(self, scales=(), **kwargs):
super(MultiScaleDiscriminator, self).__init__()
self.scales = scales
discs = {}
for scale in scales:
discs[str(scale).replace('.', '-')] = Discriminator(**kwargs)
self.discs = nn.ModuleDict(discs)
def forward(self, x, kp=None):
out_dict = {}
for scale, disc in self.discs.items():
scale = str(scale).replace('-', '.')
key = 'prediction_' + scale
feature_maps, prediction_map = disc(x[key], kp)
out_dict['feature_maps_' + scale] = feature_maps
out_dict['prediction_map_' + scale] = prediction_map
return out_dict注意 Discriminator 返回的第一个值是encode模块生成的特称图,第二个参数是针对每一个像素判断其是否为生成图像
同时这里的feature_maps会将downblock的每一个卷积层的输出的特征图都存储起来
MultiScaleDiscriminator是对Discriminator的又一次封装目的是对各个缩放之后的图片都进行处理
generator_loss的关键代码如下
# 检查配置中是否有相关权重的设置
if self.loss_weights['generator_gan'] != 0:
# 获取生成图像的特征图和像素级判别结果
discriminator_maps_generated = self.discriminator(pyramide_generated, kp=detach_kp(kp_driving))
# 获取真实图像的特征图和像素级判别结果
discriminator_maps_real = self.discriminator(pyramide_real, kp=detach_kp(kp_driving))
# 初始化loss值
value_total = 0
# 循环处理不同缩放图像
for scale in self.disc_scales:
key = 'prediction_map_%s' % scale
# 优化意图是所有生成图像素判别结果为1
value = ((1 - discriminator_maps_generated[key]) ** 2).mean()
#loss累加
value_total += self.loss_weights['generator_gan'] * value
loss_values['gen_gan'] = value_total
# 检查配置文件中是否有特征图的匹配权重设置
if sum(self.loss_weights['feature_matching']) != 0:
value_total = 0
for scale in self.disc_scales:
key = 'feature_maps_%s' % scale
for i, (a, b) in enumerate(zip(discriminator_maps_real[key], discriminator_maps_generated[key])):
if self.loss_weights['feature_matching'][i] == 0:
continue
# 优化意图是生成图与真实图的特征一致
value = torch.abs(a - b).mean()
value_total += self.loss_weights['feature_matching'][i] * value
loss_values['feature_matching'] = value_total2.4 Equivariance Loss等方差约束
表示x经过一个变换得到Y
给定一个已经变换
可以将任意图像转化到R
则
(1)
注意
为已知 TPS变换
对(1)式左侧进行泰勒的一阶展开式
(2)
对(1)式右侧进行泰勒的一阶展开式
(3)
对(3)式一阶项进行符合函数求导
将(4)式代入(3)式与(2)式比较需满足对应项相等¶
(5)
(6)
tps变换类Transform
变换的核心组成部分是下面的函数
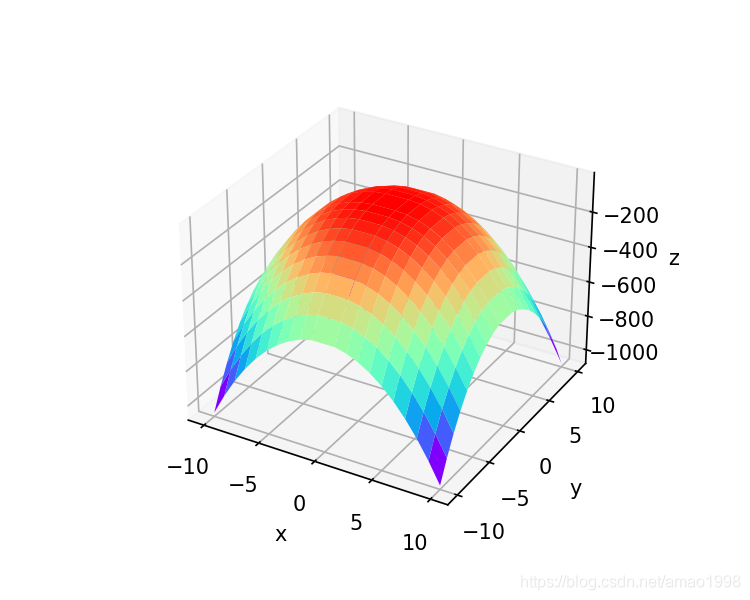
观察该函数的三维图像 1、该图像相当于在一个图片的上方有一个控制点,当控制点向上移动时带动周围的像素产生变形。变形的距离大小取决于点距离控制点的远近。下面图像中时以0点(不含0点)为控制点产生的一个图像,有多个控制点,每一个控制点都控制图像产生一定的像素变换,这种变换可以粗暴的理解为tps,当然在变换时需要乘以一个较小的系数来控制变形的幅度。
x=y=np.concatenate((np.arange(-10,0),np.arange(1,11)))
X,Y=np.meshgrid(x,y)
figure=plt.figure(figsize=(5,4))
ax3d=figure.add_subplot(projection='3d')
ax3d.plot_surface(X, Y, -(X**2+Y**2)*np.log((X**2+Y**2)), rstride=1, cstride=1, cmap=plt.get_cmap('rainbow'))
ax3d.set_xlabel('x')
ax3d.set_ylabel('y')
ax3d.set_zlabel('z')
plt.show()图像如下
Transform 源码如下主要进行tps变换
class Transform:
"""
Random tps transformation for equivariance constraints. See Sec 3.3
"""
def __init__(self, bs, **kwargs): #bs是batch_size
noise = torch.normal(mean=0, std=kwargs['sigma_affine'] * torch.ones([bs, 2, 3]))
self.theta = noise + torch.eye(2, 3).view(1, 2, 3)
self.bs = bs
if ('sigma_tps' in kwargs) and ('points_tps' in kwargs):
self.tps = True
self.control_points = make_coordinate_grid((kwargs['points_tps'], kwargs['points_tps']), type=noise.type())
self.control_points = self.control_points.unsqueeze(0)
self.control_params = torch.normal(mean=0,
std=kwargs['sigma_tps'] * torch.ones([bs, 1, kwargs['points_tps'] ** 2]))
else:
self.tps = False
def transform_frame(self, frame):
grid = make_coordinate_grid(frame.shape[2:], type=frame.type()).unsqueeze(0)
grid = grid.view(1, frame.shape[2] * frame.shape[3], 2)
grid = self.warp_coordinates(grid).view(self.bs, frame.shape[2], frame.shape[3], 2)
return F.grid_sample(frame, grid, padding_mode="reflection")
def warp_coordinates(self, coordinates):
theta = self.theta.type(coordinates.type())
theta = theta.unsqueeze(1)
transformed = torch.matmul(theta[:, :, :, :2], coordinates.unsqueeze(-1)) + theta[:, :, :, 2:]
transformed = transformed.squeeze(-1)
if self.tps:
control_points = self.control_points.type(coordinates.type())
control_params = self.control_params.type(coordinates.type())
distances = coordinates.view(coordinates.shape[0], -1, 1, 2) - control_points.view(1, 1, -1, 2)
distances = torch.abs(distances).sum(-1)
result = distances ** 2
result = result * torch.log(distances + 1e-6)
result = result * control_params
result = result.sum(dim=2).view(self.bs, coordinates.shape[1], 1)
transformed = transformed + result
return transformed
def jacobian(self, coordinates):
new_coordinates = self.warp_coordinates(coordinates)
grad_x = grad(new_coordinates[..., 0].sum(), coordinates, create_graph=True)
grad_y = grad(new_coordinates[..., 1].sum(), coordinates, create_graph=True)
jacobian = torch.cat([grad_x[0].unsqueeze(-2), grad_y[0].unsqueeze(-2)], dim=-2)
return jacobian
def detach_kp(kp):
return {key: value.detach() for key, value in kp.items()}
transform = Transform(1, **config['train_params']['transform_params'])针对(5)式的loss约束可以采用如下思路,真实的目标?D图像映射到R空间然后使用keypoin_detector预测10个关键点再将10个关键的坐标从R映射到真实的目标图像?D
- 首先观察通过tps直接变换原图的情况
- 注意这里的transform的初始化实在forward内部初始化的,因为一旦transform初始化其变形状态也就确定了,为了保持变换的多样性,再forward中进行初始化
transformed_frame = transform.transform_frame(drive)
figure,ax=plt.subplots(1,2,figsize=(6,3))
ax[0].imshow(drive[0].permute(1,2,0).data)
ax[1].imshow(transformed_frame[0].permute(1,2,0).data)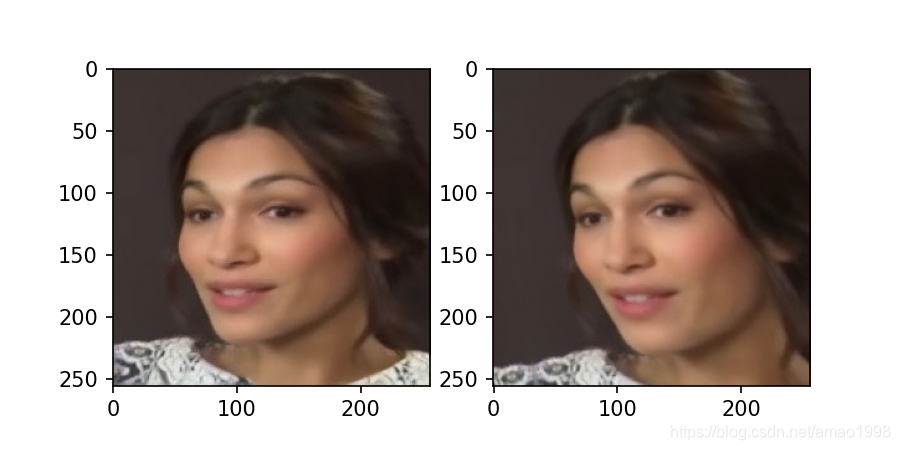
计算关键点损失关键代码如下:
# 初始化transform
transform = Transform(x['driving'].shape[0], **self.train_params['transform_params'])
# 对驱动图像进行tps变换
transformed_frame = transform.transform_frame(x['driving'])
# 抽取变换之后的关键帧
transformed_kp = self.kp_extractor(transformed_frame)
generated['transformed_frame'] = transformed_frame
generated['transformed_kp'] = transformed_kp
## Value loss part
if self.loss_weights['equivariance_value'] != 0:
# 优化意图变形之后的图像抽取关键点与先抽取关键点再进行变形结果应当保持一致
value = torch.abs(kp_driving['value'] - transform.warp_coordinates(transformed_kp['value'])).mean()
loss_values['equivariance_value'] = self.loss_weights['equivariance_value'] * value计算雅各比的相关约束
(6)
针对(6)的雅各比loss可以通过tensorflow自动微分功能求得,为方便求解(6)式可以转化为下面公式
关键代码如下
# 公式7右侧第二项与第三项相乘
jacobian_transformed = torch.matmul(transform.jacobian(transformed_kp['value']),transformed_kp['jacobian'])
# 公式7右侧第一项
normed_driving = torch.inverse(kp_driving['jacobian'])
normed_transformed = jacobian_transformed
# 公式7右侧全部
value = torch.matmul(normed_driving, normed_transformed)
# 公式7左侧
eye = torch.eye(2).view(1, 1, 2, 2).type(value.type())
# 优化目的公式成立
value = torch.abs(eye - value).mean()
# 加权
loss_values['equivariance_jacobian'] = self.loss_weights['equivariance_jacobian'] * value2.5 完整的生成器代码 (FullGenerator)
class GeneratorFullModel(torch.nn.Module):
"""
Merge all generator related updates into single model for better multi-gpu usage
"""
def __init__(self, kp_extractor, generator, discriminator, train_params):
super(GeneratorFullModel, self).__init__()
self.kp_extractor = kp_extractor
self.generator = generator
self.discriminator = discriminator
self.train_params = train_params
self.scales = train_params['scales']
self.disc_scales = self.discriminator.scales
self.pyramid = ImagePyramide(self.scales, generator.num_channels)
if torch.cuda.is_available():
self.pyramid = self.pyramid.cuda()
self.loss_weights = train_params['loss_weights']
if sum(self.loss_weights['perceptual']) != 0:
self.vgg = Vgg19()
if torch.cuda.is_available():
self.vgg = self.vgg.cuda()
def forward(self, x):
kp_source = self.kp_extractor(x['source'])
kp_driving = self.kp_extractor(x['driving'])
generated = self.generator(x['source'], kp_source=kp_source, kp_driving=kp_driving)
generated.update({'kp_source': kp_source, 'kp_driving': kp_driving})
loss_values = {}
pyramide_real = self.pyramid(x['driving'])
pyramide_generated = self.pyramid(generated['prediction'])
if sum(self.loss_weights['perceptual']) != 0:
value_total = 0
for scale in self.scales:
x_vgg = self.vgg(pyramide_generated['prediction_' + str(scale)])
y_vgg = self.vgg(pyramide_real['prediction_' + str(scale)])
for i, weight in enumerate(self.loss_weights['perceptual']):
value = torch.abs(x_vgg[i] - y_vgg[i].detach()).mean()
value_total += self.loss_weights['perceptual'][i] * value
loss_values['perceptual'] = value_total
if self.loss_weights['generator_gan'] != 0:
discriminator_maps_generated = self.discriminator(pyramide_generated, kp=detach_kp(kp_driving))
discriminator_maps_real = self.discriminator(pyramide_real, kp=detach_kp(kp_driving))
value_total = 0
for scale in self.disc_scales:
key = 'prediction_map_%s' % scale
value = ((1 - discriminator_maps_generated[key]) ** 2).mean()
value_total += self.loss_weights['generator_gan'] * value
loss_values['gen_gan'] = value_total
if sum(self.loss_weights['feature_matching']) != 0:
value_total = 0
for scale in self.disc_scales:
key = 'feature_maps_%s' % scale
for i, (a, b) in enumerate(zip(discriminator_maps_real[key], discriminator_maps_generated[key])):
if self.loss_weights['feature_matching'][i] == 0:
continue
value = torch.abs(a - b).mean()
value_total += self.loss_weights['feature_matching'][i] * value
loss_values['feature_matching'] = value_total
if (self.loss_weights['equivariance_value'] + self.loss_weights['equivariance_jacobian']) != 0:
transform = Transform(x['driving'].shape[0], **self.train_params['transform_params'])
transformed_frame = transform.transform_frame(x['driving'])
transformed_kp = self.kp_extractor(transformed_frame)
generated['transformed_frame'] = transformed_frame
generated['transformed_kp'] = transformed_kp
## Value loss part
if self.loss_weights['equivariance_value'] != 0:
value = torch.abs(kp_driving['value'] - transform.warp_coordinates(transformed_kp['value'])).mean()
loss_values['equivariance_value'] = self.loss_weights['equivariance_value'] * value
## jacobian loss part
if self.loss_weights['equivariance_jacobian'] != 0:
jacobian_transformed = torch.matmul(transform.jacobian(transformed_kp['value']),
transformed_kp['jacobian'])
normed_driving = torch.inverse(kp_driving['jacobian'])
normed_transformed = jacobian_transformed
value = torch.matmul(normed_driving, normed_transformed)
eye = torch.eye(2).view(1, 1, 2, 2).type(value.type())
value = torch.abs(eye - value).mean()
loss_values['equivariance_jacobian'] = self.loss_weights['equivariance_jacobian'] * value
return loss_values, generated3 完整判别器代码(Full Discriminator)
class DiscriminatorFullModel(torch.nn.Module):
"""
Merge all discriminator related updates into single model for better multi-gpu usage
"""
def __init__(self, kp_extractor, generator, discriminator, train_params):
super(DiscriminatorFullModel, self).__init__()
self.kp_extractor = kp_extractor
self.generator = generator
self.discriminator = discriminator
self.train_params = train_params
self.scales = self.discriminator.scales
self.pyramid = ImagePyramide(self.scales, generator.num_channels)
if torch.cuda.is_available():
self.pyramid = self.pyramid.cuda()
self.loss_weights = train_params['loss_weights']
def forward(self, x, generated):
pyramide_real = self.pyramid(x['driving'])
pyramide_generated = self.pyramid(generated['prediction'].detach())
kp_driving = generated['kp_driving']
discriminator_maps_generated = self.discriminator(pyramide_generated, kp=detach_kp(kp_driving))
discriminator_maps_real = self.discriminator(pyramide_real, kp=detach_kp(kp_driving))
loss_values = {}
value_total = 0
for scale in self.scales:
key = 'prediction_map_%s' % scale
value = (1 - discriminator_maps_real[key]) ** 2 + discriminator_maps_generated[key] ** 2
value_total += self.loss_weights['discriminator_gan'] * value.mean()
loss_values['disc_gan'] = value_total
return loss_values4 总结
至此模型解读完毕,至于生成数据集和训练过程本文没有涉及,请大家参照官方源码