之前矿难买了个星际蜗牛C款机箱,两块红盘存储数据,没想到红盘质量这么差,从上年初到现在断断续续出现UNC错误,这这周崩了,记录下修复过程:
群晖系统在内部用的软raid管理,新插入一个硬盘初始化后,它一般会格式化为3个分区,一般前两个和系统相关,最后一个作为存储盘,下图是我的这个坏道硬盘的分区情况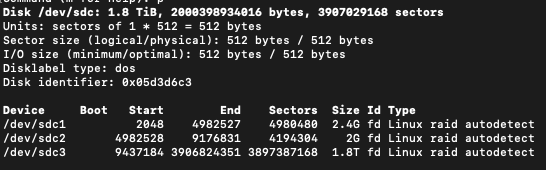
注意看哪个Type是raid类型的,这时候还不能直接使用。
当系统有多个硬盘时,每个硬盘都是这样的分区,每个硬盘的第一个分区一起,会组成raid1模式阵列(一份资料存多处),这样的话,每个硬盘上都有一份系统文件备份,这也是为什么群晖的机器拔掉一个硬盘,系统仍然正常运行的原因,看下图: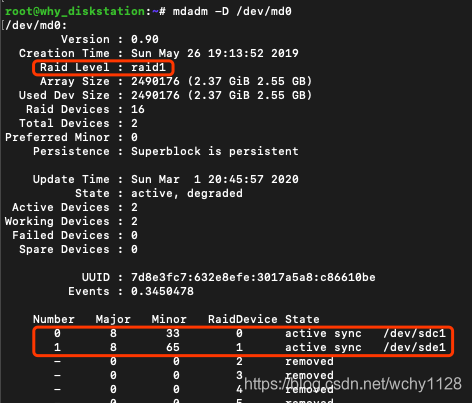
磁盘软阵列组成后,这时候的磁盘阵列相当于硬盘,还需要给它分区。
群晖系统使用了lvm管理分区,先分出卷组,然后在卷组里添加卷,实际上web界面的存储空间管理里面,存储池对应的就是卷组,存储空间对应的就是卷。我的机器两块硬盘,创建了两个卷组,每个卷组里有几个卷,我用lvm命令列出来卷组和卷如下: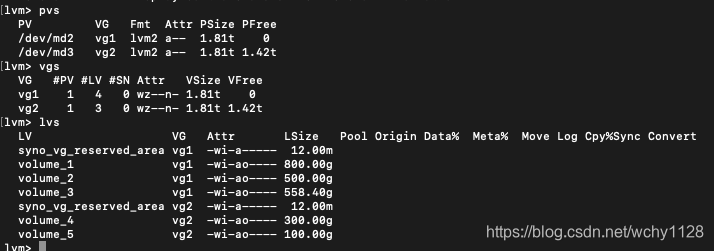
创建卷时,会指定文件格式,现在群晖推荐btrfs文件系统。一般碰到的都是文件系统的错误,这个具体要根据/var/log/disk.log 和 scemd.log查看什么问题。我遇到的比较复杂一些。
首先修复btrfs文件系统, 使用命令是:
btrfs-find-root /dev/vg1/volume_1 &> /tmp/test.txt
注意这个文件系统的卷路径因人而异,我的坏盘区域是vg1卷组下的volume_1/volume_2/volume_3,所以是这个路径,这个命令用于查找问题block。
一般发现的是这样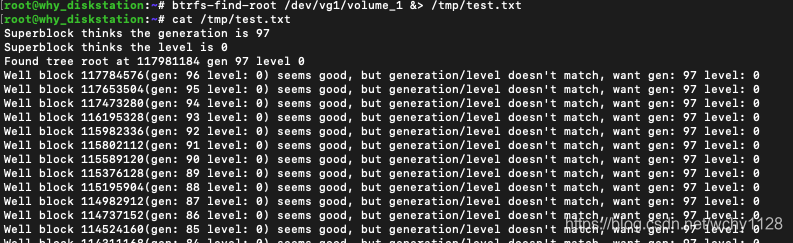
选第一个开始修复:
btrfs check --repair -r 117784576 -s 0/1/2
需要注意–repair加上后,是有风险的,可能修复失败,文件系统更乱,所以在做修复前一定做好硬盘备份,-s后面随意选一个,失败再换,一般这条执行后,没有‘abort’/‘failed’就是成功了
如果执行时遇到报错 "RDWR"关键词的,需要执行清cache命令
btrfs check --clear-space-cache v2
不断的将所有block修复完后,btrfs文件系统一般就搞定了。这时候运气好,重启dsm一般存储空间都在,不丢失而且只读模式也恢复成读写模式了。
运气不好,可能修复文件系统的过程影响了软raid格式,具体需要查看log, 很不幸,我就遇到了。查看scemd.log发现了/dev/md2 RAID crash这种关键词,所以我又重建了我硬盘第三分区/dev/sdc3的raid格式。具体比较取巧:
1、拔掉坏盘
2、重启机器
3、热插上坏盘
4、运行命令:
mdadm -Cf -e1.2 /dev/md2 -n1 -l1 /dev/sdc3
完成重建后,可以做个检查, -e后面是版本,1.2和0.9可以自行尝试
mdadm -D /dev/md2
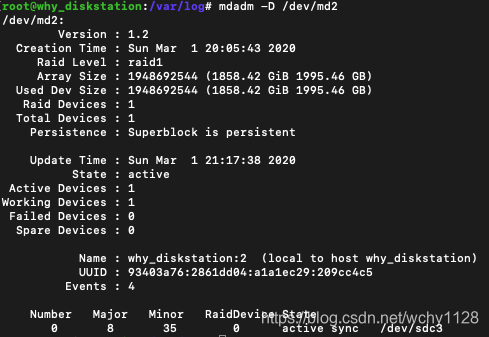
重启机器后不再报存储空间损毁。不过修复的过程还是对系统造成了影响,dsm提示修复系统,修复过程就是RAID同步的过程,见下图,可以看到,我的坏盘是sdc硬盘,md0里sde1的数据在向sdc1同步。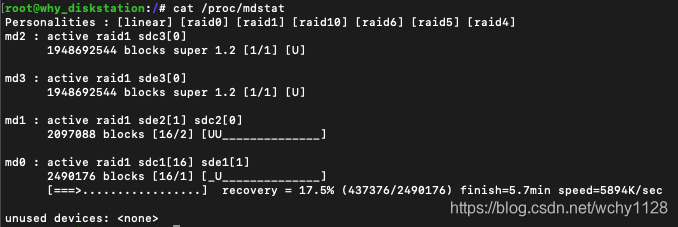
总结:
群晖的linux对硬盘坏道比较敏感,因为文件系统日志式的,可以及时检测到硬盘坏道,如果发现有报告损毁,还是及时备份数据,换硬盘吧。数据无价