代码部分参见:李宏毅机器学习作业10——Adversarial Attack_iwill323的博客-CSDN博客
目录
Attack Approach:FGSM(Fast Gradient Sign Method)
Speech Processing:侦测一段声音是不是被合成出来的
Natural Language Processing:控制QA结果
Network 在一般的情况下得到高的正确率是不够的,它要在有人试图想要欺骗它的情况下,也得到高的正确率,所以就要能够对恶意攻击采取一定的防御措施。本节将介绍对抗攻击的概念、方法和防御措施
Adversarial Attack的概念和分类
概念
对抗攻击的概念是给正常输入加入特殊的杂讯,形成一个带有攻击性的输入,当其进入模型之后,输出的内容是错误的。被加杂讯的照片叫做 Attacked Image,还没有被加杂讯的照片一般就叫做Benign Image。一般加入的杂讯是很小的,人的肉眼是看不出来的,下图中的攻击图片是夸张了的
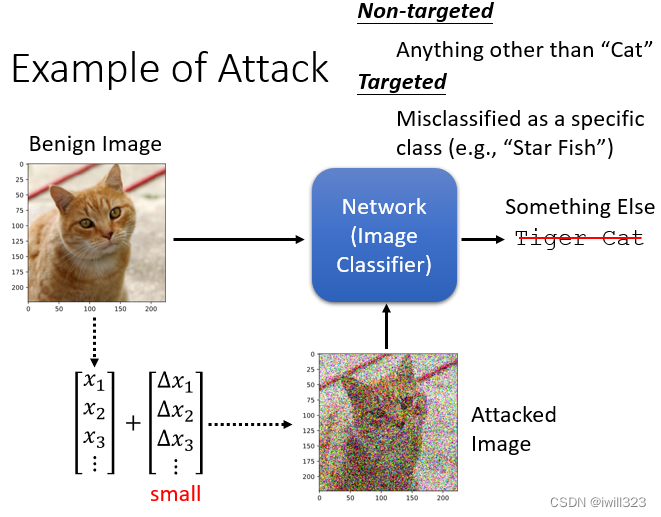
攻击前分类的信心分数(置信度)是 0.64,攻击后分类的信心分数是100 %,即反而可能上升

分类
是否知道模型参数
- 白盒攻击(White Box Attack):已知模型参数
- 黑盒攻击(Black Box Attack):未知模型参数
是否有攻击得到的目标
- 没有目标的攻击(Non-targeted Attack):原来的答案是猫,只要你能够让 Network 的输出不是猫就算是成功
- 有目标的攻击(Targeted Attack):希望 Network不止它输出不能是猫,还要输出某一指定的别的东西,比如说,把猫错误判断成一隻海星才算是攻击成功。
白盒攻击
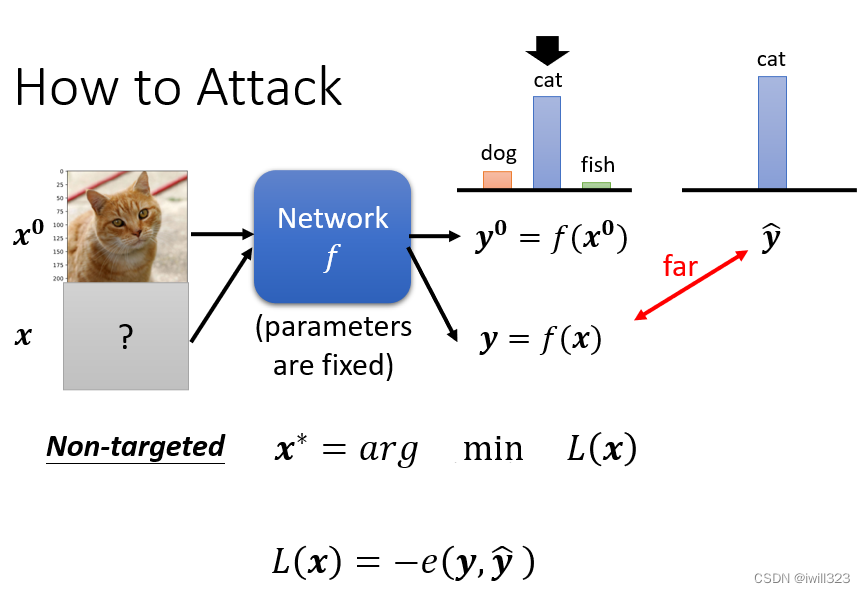
Network是一个函数f,输入是一张图片,我们叫它x0,输出是一个 Distribution,分类的结果叫y0。被攻击的模型参数是固定的,攻击者是修改不了模型的,只能修改输入内容。
Non-Targeted Attack
如果是 Non-Targeted Attack,要找到一张新的图片x, 经过Network输出是 y,正确的答案叫做 ŷ,希望 y 跟 ŷ 的差距越大越好。loss函数就是y和ŷ的负cross entropy,这一项越小越好,代表 y 跟 ŷ的 Cross Entropy 越大
Targeted Attack
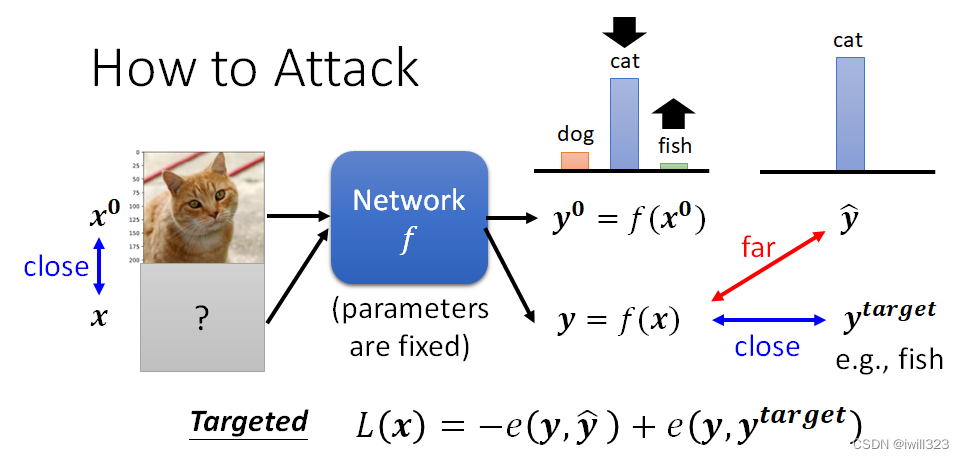
如果是目标攻击。用ytarget代表目标,ŷ 其实是一个 One-Hot Vector,ytarget也是一个 One-Hot Vector,希望 y 不止跟 ŷ 越远越好,还要跟ytarget越近越好。
Non-perceivable
加入的杂讯越小越好,也就是新找到的图片跟原来的图片要越相近越好。所以我们在解这个Optimization 的 Problem 的时候,还会多加入一个限制
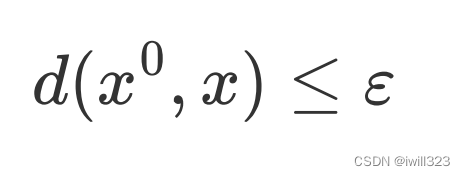
希望 x 跟x0之间的差距小於某一个 Threshold,这个閾值是人类可以感知的极限,如果x0 跟 x 之间的差距大於 Σ,人就会发现有一个杂讯存在。让x0 跟 x 的差距小於等於 Σ,就可以產生一张图片,人类看起来 x 跟 x0是一模一样的,但產生的结果对 Network 来说是非常不一样的
d(x0, x) 的计算方法
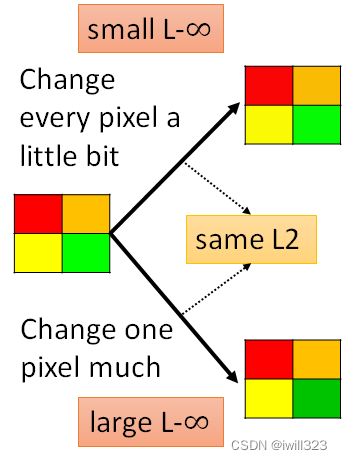
计算d(x0, x)有两个方法。第一种L2:将∆?每一维的差值的平方相加,要开根号也是可以的;第二种L-∞:将∆?中绝对值最大元素作为差异大小。∆?是正常输入和恶意输入的差值(也就是杂讯)

第二种方法L∞更加符合人类的感知情况,所以攻击者一般会考虑采用L-infinity。为什么呢?以方块图来说明,右上角的正方形中四个方块都有微小变化,右下角的正方形中只有绿色方块发生变化。并且令两者对原正方形做差,有相同的L2值,但右下角L-∞更大,右上角L-∞比较小,因為 L-∞ 只在意最大的变化量。而从人肉眼观察来看,能明显看出右下角的变化,所以限制最大的差值(L-∞)也许能够更好地将恶意输入伪装成正常输入。
刚才举的例子是影像上的例子,如果要攻击的对象是一个跟语音相关的系统,那什麼样的声音讯号对人类来说听起来有差距,那就不见得是 L2 跟 L-Infinity 了,要研究人类的听觉系统,看看人类对什麼频态的变化特别敏感,根据人类的听觉系统来制定比较适合的 x 跟 x0之间距离的衡量方式,这个部分需要用到 Domain Knowledge
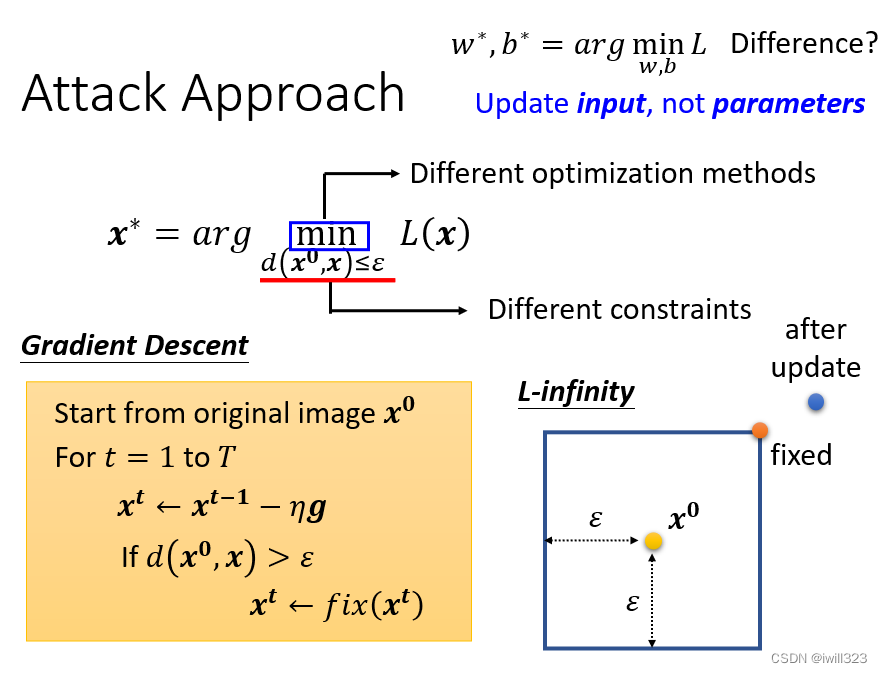
攻击方法的实现
和以前模型里面的函数不同,之前的是固定输入,调整参数来使loss最小,现在是固定模型参数,调整输入来使loss最小,还是用的梯度下降的方法:将正常的输入x当作初始化值,再迭代更新x,迭代过程是算出loss对输入x的偏微分g,乘上学习率后再更新x。更新完参数以后,如果xt和x的差距大於 ε,就把xt改回符合限制。
假设现在用的是 L-Infinity,那么x 可以存在的范围只有方形框。在更新完x之后,如果x在这个正方形外(蓝色的点),那么就用正方形上最近的点(橙色的点)来替代。
当然,这只是多数方法中的一个,攻击方法可以使用不一样的优化函数,不一样的限制条件,但是本质思想就是这样的。
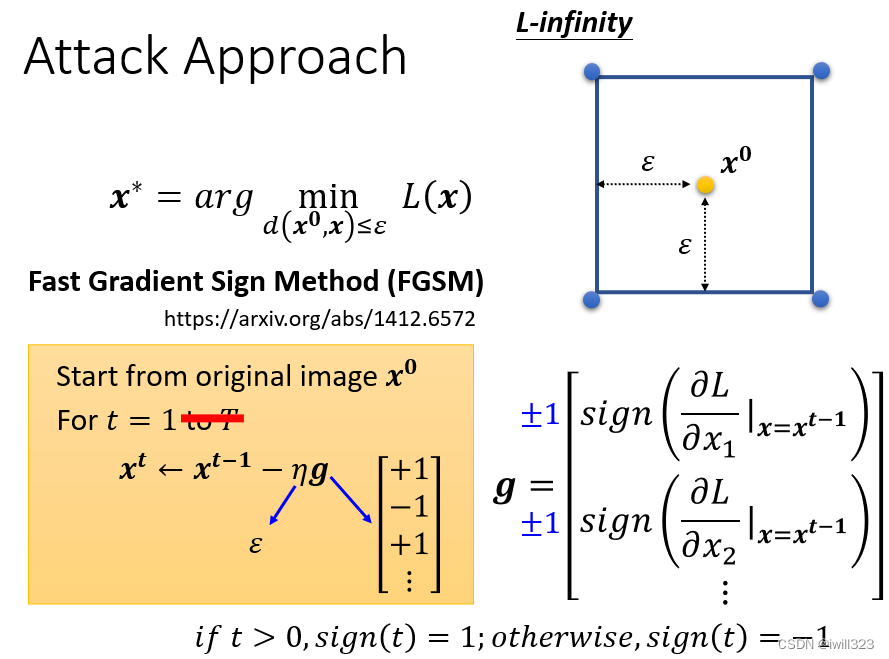
Attack Approach:FGSM(Fast Gradient Sign Method)
这个方法重点在于只要更新一次x,一击就找出一个可以攻击成功的 Image,不需要迭代多次。
不直接用Gradient Descent 的值,给它取一个 Sign,梯度g的输出只有1和-1两种可能,而学习率设为“感知上限”ε表示,更新一次的x必定会在方框的四个角落上,这个一击往往就可以必杀。
def fgsm(model, x, y, loss_fn, epsilon=epsilon):
x,y = x.to(device), y=y.to(device)
x_adv = x.detach().clone() # 克隆x是因为x的值会随着x_adv的改变而改变
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y)
loss.backward()
# fgsm: use gradient ascent on x_adv to maximize loss
grad = x_adv.grad.detach()
x_adv = x_adv + epsilon * grad.sign() # 不会越界,所以不用clip
return x_advIterative FGSM:假如迭代要多重复几轮,结果会更好,但是x很大概率会跑出方框的范围,这时只要用方框四个角落最近的点来代替即可。

# set alpha as the step size in Global Settings section
# alpha and num_iter can be decided by yourself
alpha = 0.8/255/std
def ifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=20):
x_adv, y = x.to(device), y=y.to(device)
for i in range(num_iter):
x_adv = x_adv.detach().clone()
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y)
loss.backward()
# fgsm: use gradient ascent on x_adv to maximize loss
grad = x_adv.grad.detach()
x_adv = x_adv + alpha * grad.sign()
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv
黑箱攻击black box attack
做 FGSM 在计算 Gradient 的时候,需要知道模型的参数才有办法计算这个 Gradient,在 Image 上加上 Noise。知道模型参数的攻击叫做白箱攻击,不知道模型参数的攻击叫做黑箱攻击。黑箱攻击容易实现无目标攻击,但是很难实现目标攻击。
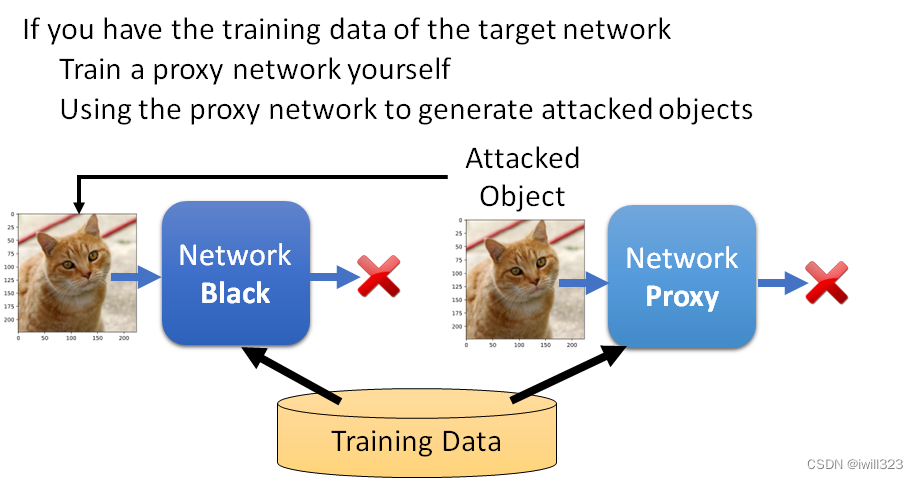
有被攻击网络的训练资料时
假设你知道这个 Network是用什麼样的训练资料训练出来的话,自己来训练一个proxy网络,都是用同样的训练资料训练出来,也许它们就会有一定程度的相似度。将proxy网络当作被攻击对象,来生成带有攻击性的输入,再把这个训练出来的图片输入到不知道参数的 Network中,就实现了攻击。本质思想就是将黑箱攻击转变成白箱攻击。
没有被攻击网络的训练资料时
没有训练资料的时候,把一堆图片丢进去得到输出,再把输入输出的成对资料拿去训练一个模型,训练出一个类似的模型,当做 Proxy Network 进行攻击。
攻击结果
单一攻击
下图的对角线是属于白箱攻击,准确率都为0%,成功率是百分之百。非对角线属于黑箱攻击,比如拿 ResNet-152 当做是 Proxy Network,去攻击 ResNet-50,得到的正确率是 18 %。黑箱攻击模型,最终的正确率比白箱攻击还要高,但是其实这些正确率也都非常低,都是低於 50 %,所以显然黑箱攻击也有一定的成功的可能性。

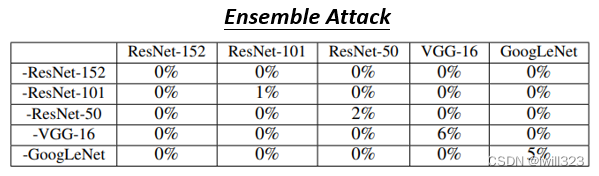
聚合攻击
可以采用Ensemble 的 Network,下图网络前面带上负号意思是proxy不用这个网络而用其余的四个网络来训练,找一个攻击的 Image,在负号网络以外的模型都是成功的,所以对角线是黑箱攻击,非对角线是白箱攻击。可以发现,当找一个 Attacked Image可以成功骗过多个 Network 的时候,骗过一个不知道参数的黑箱的 Network非常容易成功
下面的ptcv_get_model是一个模型库,给ensembleNet初始化一个模型名字列表,便能添加ptcv_get_model里面的模型,在forward方法中依次运行这些模型,然后输出结果的平均
class ensembleNet(nn.Module):
def __init__(self, model_names):
super().__init__()
# ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,可以类似List那样进行append和extend操作
self.models = nn.ModuleList([ptcv_get_model(name, pretrained=True) for name in model_names])
# self.models.append(undertrain_resnet18) 可以append自己训练的代理网络
def forward(self, x):
emsemble_logits = None
# sum up logits from multiple models
for i, m in enumerate(self.models):
emsemble_logits = m(x) if i == 0 else emsemble_logits + m(x)
return emsemble_logits/len(self.models)为什么攻击这么容易
为什么在A网络上攻击成功了,恶意攻击用在B网络上也能成功呢?
下图横轴是在 VGG-16 上面可以攻击成功的方向,纵轴是一个随机的方向,深蓝色的区域是图片会被辨识成小丑鱼的图片的范围。
图片是高维向量,把这个高维向量在高维的空间中往纵轴方向移动(加上一个 Noise),基本上 Network 还是会觉得它是小丑鱼的图片,不管对每一个 Network 来说都是如此。攻击VGG-16成功的方向特别窄,图片往攻击VGG-16 的方向稍微移动一下,其他 Network也有蛮高的机率可以攻击成功。
攻击会成功这件事情不是只有对 Deep Learning 有一样的问题,对 Linear 的 Network、对 SVM 也都有类似的问题。大多数学者认为,攻击会这麼容易成功的原因未必出现在模型上面,可能是出现在资料上。在有限的资料上,机器学到的就是这样子的结论,当我们有足够的资料,也许就有机会避免 Adversarial Attack。

而Ian Goodfellow认为,对抗样本的产生是因为模型线性程度过高,对抗样本存在于线性空间,决策边界是线性的,当穿过边界进入对抗空间内后(沿着和梯度方向能形成很大内积的方向),便得到了对抗样本,参见:
CS231n 笔记- 对抗模型和对抗训练_iwill323的博客-CSDN博客_对抗模型
其他攻击方法
one pixel attack
只要改动图片的一个像素点,就能使得辨识系统出错。并没有非常地 Powerful

universal adversarial attack
用一个 Signal就成功攻击所有的图片。通用恶意攻击,某一个杂讯恶意性强大,不管什麼样的影像都可以攻击成功,都能使辨识系统出错。

Speech Processing:侦测一段声音是不是被合成出来的
一段显然的合成声音讯号加上这个微小的杂讯以后,同一个侦测合成的系统,会觉得刚才那段声音是真实的声音,而不是合成的声音。

Natural Language Processing:控制QA结果
在所有文章末尾贴上,Why How Because To Kill American People,接下来不管你问它什麼问题,它的答案都是 To Kill American People,

Attack Approaches
真实世界攻击
人脸识别
一个男的戴上副眼镜以后,人脸辨识系统就会觉得他是右边这一个知名艺人。攻击人脸辨识系统需要考虑的因素:
1、我们在观看一个东西的时候可以从多个角度去看,考虑三维的各个角度都要能使辨识系统出错。
2、考虑摄像头的解析度极限,如果加入的杂讯太小以至于摄像头解析不出来,那么这个杂讯就等于是白加了。
3、考虑电脑和现实中的色差。印出来后,某一些顏色会偏掉,如果训练出来的眼镜有现实中印不出来的颜色,那么这副眼镜还是起不到攻击作用。

标识辨识
在标识上贴上贴纸,导致辨识错误。

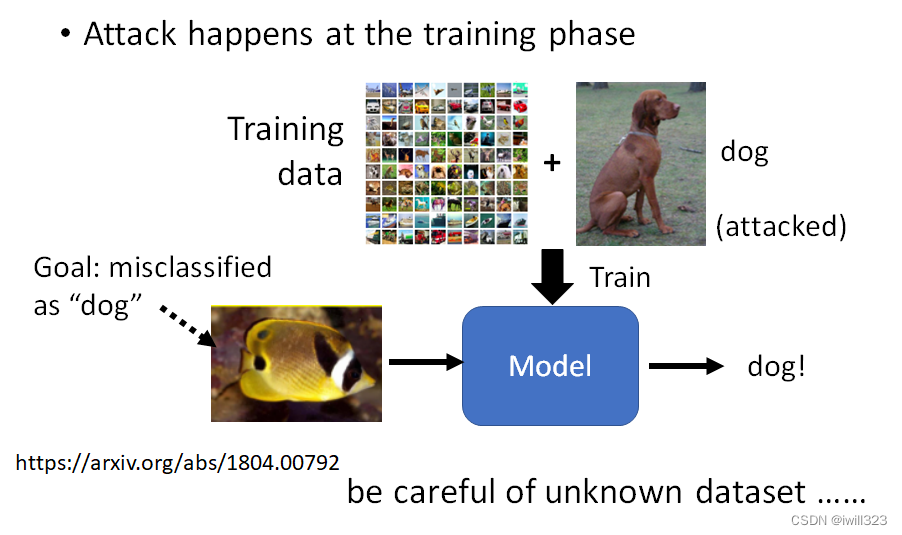
训练阶段发起攻击
对训练资料做手脚,在训练资料裡面加一些看上去正常的图片,而它的标註也都是正常的,拿这个样子的资料进行训练,在测试的阶段就会辨识错误,而且只会对某一张图片辨识错误,对其他的图片还是没有问题
而且这种方式的攻击只对某一特征有问题,而其他东西的分类都是正常的,所以训练结果一般看起来也正常,很难察觉自己被攻击了。所以不要随便用来路不明的训练资料。还是有某一些限制的,并不是说随便什麼模型,随便什麼训练方式,这种开后门的方法都可以攻击成功
防御措施
Passive defence(被动防御)
被动防御是不去改动模型的,通过处理输入内容实现防御。因为攻击讯号都很特殊且小,不是什么noise都能攻击的,所以稍微处理下输入就能降低攻击的威力。
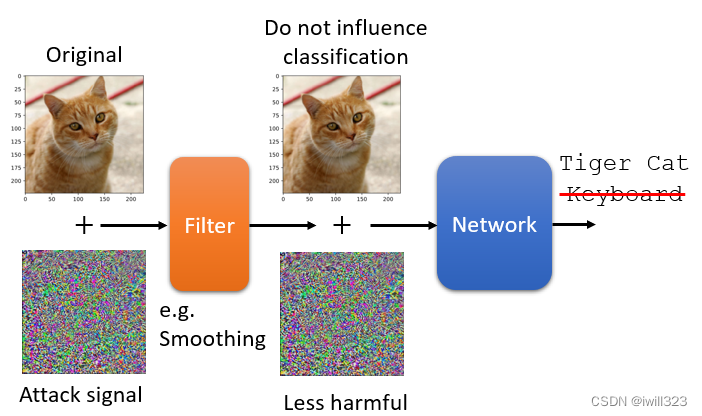
第一种方法:图片模糊化
把图片稍微做一点模糊化,可能就达到非常好的防御效果了。
解释:Adversarial Attack只有某一个方向上的攻击讯号才能够成功,并不是随便 Sample 一个 Noise都可以攻击成功。当加上模糊化以后,攻击成功的讯号失去攻击的威力,但是不太会影响影像辨识的结果。
副作用:使Confidence分数降低。

第二种方法:图片压缩
比如图片存成 JPEG 档,会造成失真,攻击的讯号受到的影响是比较大,就可以保护你的模型

下面使用imgaug.augmenters进行图像压缩。先将攻击图像还原为0-255像素值的图像格式,然后进行图像压缩,放入被攻击的模型
import imgaug.augmenters as iaa
# pre-process image
x = transforms.ToTensor()(adv_im)*255
x = x.permute(1, 2, 0).numpy()
x = x.astype(np.uint8)
# TODO: use "imgaug" package to perform JPEG compression (compression rate = 70)
compressed_x = iaa.arithmetic.compress_jpeg(x, compression=70)
logit = model(transform(compressed_x).unsqueeze(0).to(device))[0]
predict = logit.argmax(-1).item()
prob = logit.softmax(-1)[predict].item()
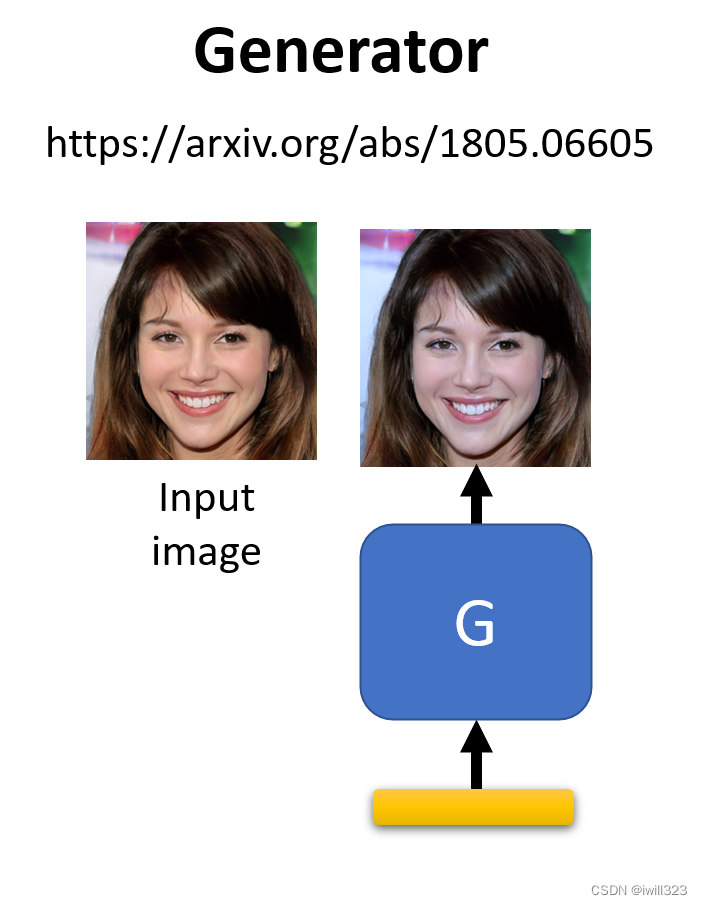
第三种方法:用generator重新生成输入图片
要求 Generator 输出一张图片,这张图片跟输入给Image Classifier 的图片越接近越好,Generator
在训练的时候从来没有看过这些杂讯,可能无法復现出这些非常小的杂讯,微小的杂讯就不见了
第四种方法:加入随机化
被动的防御有一个非常大的弱点,假设人家不知道你有用这一招,它就非常有效,一旦人家知道你用什麼招数,那这种被动防御的方法就会瞬间失去效用。比如模糊化这件事等於就是在Network 前面多加了一层,所以假设别人知道你的 Network 前面多加这一层,把多加这一层放到攻击的过程中,它就可以產生一个 Signal,可以躲过模糊化这种防御方式。
还有一种再更强化被动防御的方法就是加上随机性,自己都不知道自己的下一招是什麼,在做这个
Defense 的时候啊加上各种不同的 Defense 的方式,比如随机放大缩小图片,随机贴图(贴的位置也是随机的)......
这种随机防御也是有问题,假设你各种随机的可能性都已经被知道的话,那别人只要用 Universal Attacks找一个 Attack 的 Signal 可以攻破所有图片的变化方式的话,Randomization 的方式还是有可能被突破
 Proactive defence(主动防御)
Proactive defence(主动防御)
主动防御的思想就是训练出一个见多识广的模型,见识过各种各样的攻击。
给一堆训练资料,然后通过攻击算法故意弄坏输入,再将弄坏的输入与正确输出对应上,最后用正常的输入和弄坏的输入一起去训练模型,然后看看这个模型呢有没有什麼漏洞,然后把漏洞填起来,不断地找漏洞,找到就把它填起来。这个方法其实类似于data augmentation(资料增强)
主动防御的缺点:不能挡住新算法的攻击,如果今天攻击你 Model 的方法并没有在 Adversarial
Training 的时候被考虑过,那 Adversarial Training也不见得能够挡住新的 Attack 的 Algorithm;需求的资料多,对计算能力要求高。
