大朋友小朋友们,儿童节快乐鸭!
连享会-空间计量专题研讨班

这篇文章主要回答以下几个问题:为什么要引入空间计量经济学(主要假设SAR模型),SAR模型设定形式、假设条件、参数估计以及假设检验,以及stata应用。本文主要是简述其原理,并不涉及公式的具体推导等,如有不对请多指正。
一、为什么要引入空间计量
举一个例子,因为河流是流动性,因此临近地区的污染很有可能会影响到当地的河流污染,我们应该如何考察临近地区的污染对当地的污染影响呢?更进一步的说,邻近地区对当地的污染影响这一控制变量应该如何表示呢?空间计量通过引入权重矩阵的方式来,可以考察地理相邻地区对当地的影响,也就是所谓的空间溢出效应。
因此引入空间计量主要有2个好处,第一个可以防止空间溢出效应性影响内生性。
第二个可以考察空间溢出的影响的方向,是正向溢出还是负向溢出。
二、SAR模型的基本形式
首先空间计量包括几种spatial lag,可以拓展线性回归模型,允许outcome in one area affected by。
(1)自变量的spatial lag ,被附近地区的自变量影响
(2)因变量的spatial lag,被附近的因变量影响
(3)残差项的spatial lag,被附近的误差项影响
我们通过引入空间权重矩阵的形式
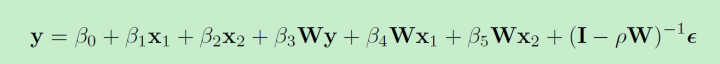
W操作符号和时间序列中的滞后项的作用类似,表示的是附近城市的空间溢出效应。
W权重矩阵应该如何选择呢,举一个例子,让我们考虑the matrix for four fictional places,魔多 (mordor), 指环王小说中一片黑暗血腥的土地,布里镇(bree) 指环王小说的中的一个村庄,霍格莫德村 (hogsmead) ,哈利波特中卖魔法物品的村庄,霍格华兹(hogwarts) ,哈利波特中的学校,
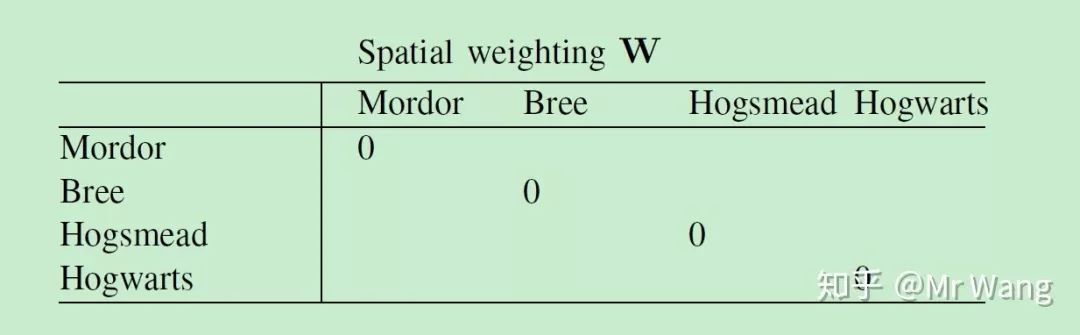
图1
图1:为什么设定摩多对摩多自身的影响是0呢,不应该是1吗,自身对自身溢出的效应应该是1才对,原因在W矩阵主要目的在于识别附近区域对其的影响,对其自身的影响在空间计量的设定中,主要通过添加控制变量的方式来识别其自身对自身的影响。
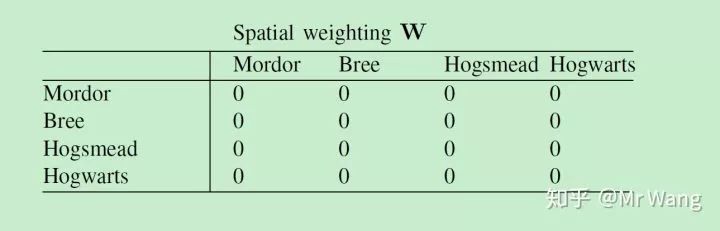
图2:如果空间权重全部设定为0,表明没有空间溢出效应,用普通的线性模型就可以了:
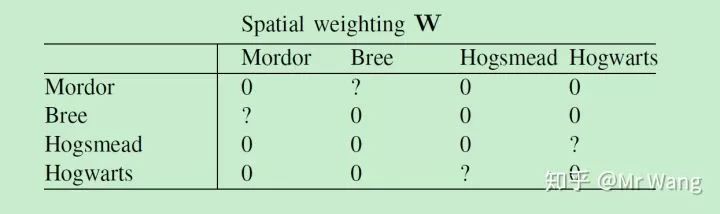
图3:但modor and bree都是一个场景中的地点,hogsmead and hogwart 都是另一个场景的地点,因此同一场景之间很可能具有空间溢出效应,不同场景之间不可能存在空间溢出效应,因此我们将其设定为0,
我们应该如何设定空间溢出效应的大小呢,空间权重矩阵绝对数值的大小是不重要的,重要的是矩阵中元素的比值的大小。
如何设定相对数值的大小呢,这个需要我们根据理论做出一定的猜测,比如说我们认为摩多是个很大的城市,而bree是个很小的村庄,因此我们认为bree对modor的影响会更大,而moder对bree的影响相对小些,而Hogwarts and hogsmead分别是哈利波特中的村庄和学校,因此我们认为其相互溢出的影响效应是相同的。
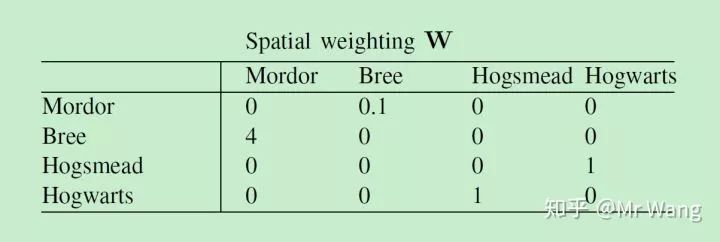
当然你可能质疑我们选择的数字,为什么bree对摩多的溢出效应是4,而不是5呢,不是10呢,对于这个问题,我们无法给出满意的答案,这就是为什么在实际问题中,研究者都选择设定为相邻的城市为1,不相邻的城市为0 ,或者将权重矩阵设定为距离的倒数。
上文我们说过权重矩阵中的绝对数值是不重要的,但是为了更好的解释权重矩阵的系数,最好matrix is scaled appropriately。
part3 SAR模型的假设条件
SAR模型假设附近区域的变量亦会影响到当地的情况,我们需要验证这个假设条件是否成立,莫兰检验是用来检验空间相关性的一个检验,其检验的基本原理是,

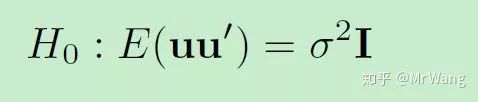
我们主要想假设残差项之间是否存在相关性,通过构造如下统计量的方式来检验H0
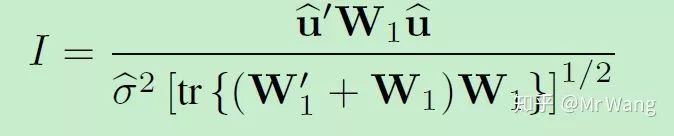
part4 模型的估计方法
主要有两种估计参数的方法,分为为系gs2sls 和ml的估计方法,感兴趣的同学可以自行了解。
part5 stata应用
首先举几个用stata命令做SAR模型回归的例子:
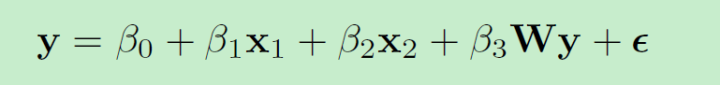
对于上述公式,我们采用stata以下命令进行回归,
spregerss y x1 x2 ,gl2sls dvarlag(W) // 注释gl2sls表示参数估计方法

spregress y x1 x2 ,gl2sls dvarlag(W) ivarlag(w:x1)
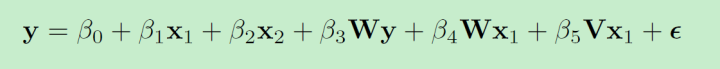
spregress y x1 x2 ,gl2sls dvarlag(W) ivarlag(w:x1) ivarlag(v:x2)
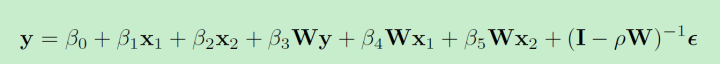
spregress y x1 x2 ,gl2sls dvarlag(W) ivarlag(w:x1 x2) errorlag(w)
下面有一个问题,我们应该如何设定空间权重矩阵呢?这是SAR模型的关键所在。
首先需要注意,空间权重矩阵必须每个矩阵元素都有数值,要不然无法估计。我们常见的数据类型主要有3种:
data with shapefiles.
data without shapefiles but including location information
data without shapefiles or location information
并且sp可以用于面板数据和横截面数据,需要在数据前面对地理位置进行排序,gen id=_n

通过spset area_id year将矩阵设定为空间矩阵,如同面板数据一样。针对第一种类型的数据 data with shapefiles,if you had a shapefiles ,你可以通过以下命令创建空间权重矩阵。
spmatrix create contiguity Wc(即01的形式)
spmatrix cteate idistance wd (距离的方式来创造权重矩阵)
创造空间权重矩阵主要分为以下几个步骤:
step1 :找到以及下载一个标准格式的shapefiles
step2: 将shapefile 转换成stata格式
step3: 观察转换的数据
step 4:创造或者找出一个comon id varialbe 方便合并数据
step5: 采用merge命令合并数据
网上有很多直接转换成stata格式的中国地图,各位可以自行下载,step1 ,step2先跳过.
step3 :观察转换的数据,spset

我们可以看出spatial-init id 以及坐标变量是重要的,其他地图信息是可以省略的step4 创建或者找到一个comon id variabel方便合并数据,step 5将坐标数据合并到你的数据集,采用merge命令。
连享会-空间计量专题研讨班