时隔大半年终于想起来,我这个帖子还没发!
daydayupupupup:Python编程100例(上)zhuanlan.zhihu.com话不多说,直接上题:
#51.学习使用按位与&
print(0&0,0&1,1&0,1&1)
print("5 & 3=",5&3) #101,011---1
print("4 & 3=",4&3) #100,011----0
print("45 & 30=",45&30) #101101,011110----1100转化为十进制为12#52.学习使用按位或|
print(0|0,0|1,1|0,1|1)
print("5 | 3= %d"%(5|3)) #101,011---111=7
print("4 | 3= %d"%(4|3)) #100,011---111=7
print("45 | 30= %d"%(45|30)) #101101,011110---111111=63#53.学习使用按位异或^
print(0^0,0^1,1^0,1^1)
print("5 ^ 3= %d"%(5^3)) #101,011---110=6
print("4 ^ 3= %d"%(4^3)) #100,011---111=7
print("45 ^ 30= %d"%(45^30)) #101101,011110---110011=51#54.取一个整数a从右端开始的4~7位(针对二进制数)
a=int(input("请输入一个大于等于64的整数:"))
c=a>>4
b=0 #0
b=~b #1
b=b<<4 #10000
b=~b #1111
print(bin(a),bin(b),bin(c),bin(c&b))#55.按位取反
print(~5) #源码00000101 反码11111010二进制的-6#56.利用circle画⚪---(turtle库)
import turtle
turtle.setup(600,300,100,100) #长600宽300,画板位置距离左上角(0,0) 100,100
turtle.up() #不会在画板上留下痕迹
turtle.goto(100,100) #直接去到(100,100)点
turtle.down()
turtle.pensize(10)
turtle.pencolor("pink")
turtle.circle(10) #半径为10的圆#57.学会用line画直线
import matplotlib.pyplot as plt
plt.plot([0,1],[2,5]) #(0,2)和(1,5)两点之间的连线
plt.show()#58.学会用rectangle画矩形
from tkinter import *
root=Tk() #创建画布
cv=Canvas(root,background="white")
cv.pack(fill=BOTH,expand=YES) #填充画布
cv.create_rectangle(30,30,300,100,outline='red') #从(30,30)开始绘制长方形#60.计算字符串的长度
mystring="Hello world"
print("the length of mystring is: %d"%len(mystring))#61. 打印杨辉三角
a=[]
for i in range(1,11):
b=[]
for j in range(1,i+1):
if j<i:
b.append(j)
elif j==i:
b.append(1)
a.append(b)
a #先创建首尾为1的列表
for i in range(3,10):
for j in range(1,i-1):
a[i][j]=a[i-1][j-1]+a[i-1][j] #修改部分列表元素
a
for i in range(0,10):
for j in range(0,i+1):
if j<i:
print(a[i][j],end=' ') #打印a中的元素
elif j==i:
print(1,end='n') #62.查找字符串
string='I love coding!'
print(string.find('love'))
print(string.find('cod')) #c字符的位置
print(string.find('ve')) #v字符的位置#63.椭圆(利用极坐标的思想)
a=4 #椭圆的长半轴长
b=2 #椭圆的短半轴长
from math import pi
from math import *
t=np.linspace(0,2*pi,200)
x=[]
y=[]
for i in t:
x.append(a*cos(i))
y.append(b*sin(i))
from matplotlib import pyplot as plt
plt.plot(x,y)
#64.画矩形(不想用Tkinter)
#双层循环,当y=+-1时,x打满✳,y在+-1之间时,x只在端点打印✳
for y in np.linspace(-1,1,5):
for x in np.arange(-2,3):
if y==1 or y==-1:
print('* ',end='')
elif x==-2 or x==2:
print('* ',end='')
else:
print(' ',end='')
print('n') 
#65.绘制组合图形(略)
#66.输入3个数,按大小顺序输出
#输入3个数,按大小顺序输出
a=int(input('输入第1个数:'))
b=int(input('输入第2个数:'))
c=int(input('输入第3个数:'))
#将3个数依次比较大小,通过交换,保持a为最小值,c为最大值
if a>b:
t=a
a=b
b=t
if a>c:
t=a
a=c
c=t
if b>c:
t=b
b=c
c=t
print(a,b,c)#67.交换位置:输入数组,最大的与第一个元素交换,最小的与最后一个元素交换,输出数组
import numpy as np
import math
b=[2,7,5,3,9,4,11]
bmax=max(b)
bmin=min(b)
imax=b.index(max(b))
imin=b.index(min(b))
b[imax]=bmin
b[imin]=bmax
b#68.旋转数列:有n个整数,使其前面各数顺序向后移m个位置,最后m个数变成最前面的m个数
n=[1,2,3,4,5,6,7,8,9,10]
#提取前m个数据,假设m=3
m=n[:3] #1,2,3
(n+m)[3:]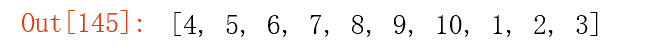
#说明:取出前m个元素添加到原列表的后面,再去掉最前m个元素即可,应该没比这简单的吧,hhhh。
#69.报数:有n个人围成一圈,顺序排号。从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号的那位。
#70.写一个函数,求一个字符串的长度。
def lens(string):
return len(string)
lens('mystring')#71.编写input()和output()函数输入,输出5个学生的数据记录。
import pandas as pd
def inputstu():
students=[]
for i in range(5):
print("开始输入第%d"%i+"个学生的信息!")
student={'name':input('姓名:'),'age':input('年龄:'),'score':input('成绩:')}
students.append(student)
return pd.DataFrame(students)
def outputstu(s):
for i in range(5):
print(s.iloc[i,:])
if __name__=='__main__':
s=inputstu()
outputstu(s)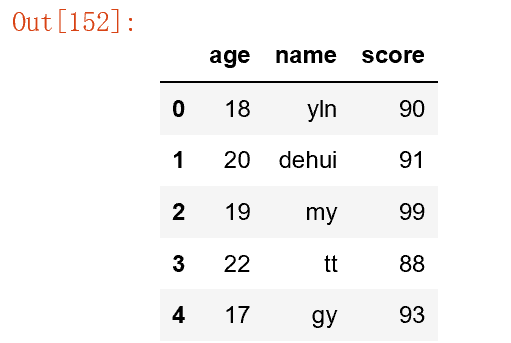
#72.创建一个列表
#创建长度为n的列表
n=int(input('想创建的列表长度:'))
mylist=[0]*n
print('依次输入列表元素')
for i in range(n):
mylist[i]=input()
mylist#73.反向输出一个列表
mylist.reverse()
mylist#74.列表的排序及连接
mylist.sort(reverse=True) #逆序
mylist
a=list('hello')
b=list('world')
a+b
a.extend(b)#75.略
#76. 编写函数:输入n为偶数时,调用函数求1/2+1/4+…+1/n,当输入n为奇数时,调用函数1/1+1/3+…+1/n。
n=int(input("输入1个正整数:"))
from math import *
s=0
for i in range(int(pow(2,not(n%2))),n+2,2): #奇数和偶数只会影响起始点
s+=1/i
s#77.遍历列表
mylist=[1,2,'a','b','c',3]
for i in range(len(mylist)):
print(mylist[i])#78.利用字典找出年龄最大的人

#79.字符串排序
mylist=['aaab', 'baaa','aabb', 'abab ']
mylist.sort()
mylist#80. 猴子分桃
海滩上有一堆桃子,五只猴子来分。第一只猴子把这堆桃子平均分为五份,多了一个,这只猴子把多的一个扔入海中,拿走了一份。第二只猴子把剩下的桃子又平均分成五份,又多了一个,它同样把多的一个扔入海中,拿走了一份,第三、第四、第五只猴子都是这样做的,问海滩上原来最少有多少个桃子?

#81.求未知数
809*??=800*??+9*?? 其中??代表的两位数, 809*??为四位数,8*??的结果为两位数,9*??的结果为3位数。求??代表的两位数,及809*??后的结果。
for i in range(10,100):
a=809*i
b=800*i+9*i
if a==b and a<10000 and i*9>100 and 8*i<=99:
print('809*%d'%i+'=800*%d'%i+'+9*%d'%i+'=%d'%a)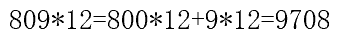
#82.八进制转化为十进制

#83.求0,1,2,...,7所能组成的奇数的个数
digits=range(0,8)
s=4 #一位数的奇数个数
S=4 #总的奇数个数,初始值
for i in range(2,9):
s=(len(digits)-1)*pow(8,i-2)*4
print("%d位数的奇数个数:"%i,int(s))
S=S+s
print("总的奇数个数:",S)#84.连接字符串(str.join(item))
#将abc逗号分隔形成新的字符串
','.join('abc') #85.输入一个奇数,判断最少几个9除以该数的结果为整数。
odd=int(input('输入一个奇数:'))
s=9
flag=True
i=1
while flag:
i=i+1
s=s+9*pow(10,i-1)
if s%odd==0:
flag=False
print(i,s)#86.连接字符串(略)
#87.访问类成员
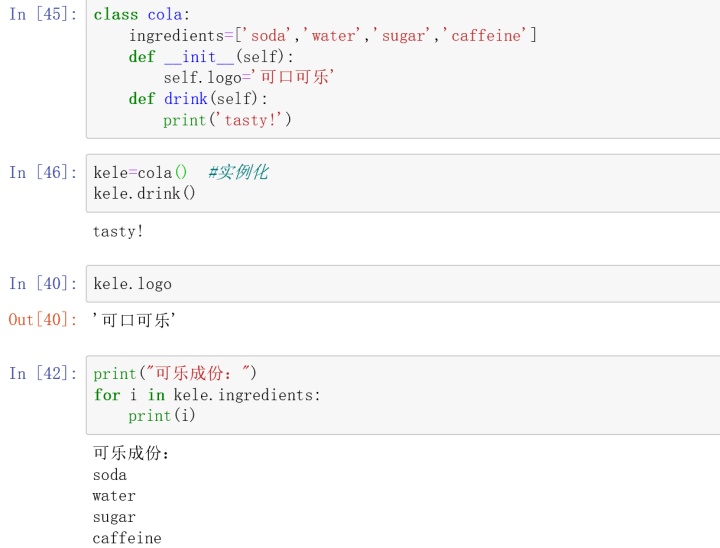
class cola:
ingredients=['soda','water','sugar','caffeine']
def __init__(self):
self.logo='可口可乐'
def drink(self):
print('tasty!')
kele=cola() #实例化
kele.drink()
kele.logo
print("可乐成份:")
for i in kele.ingredients:
print(i)#88.打印星号
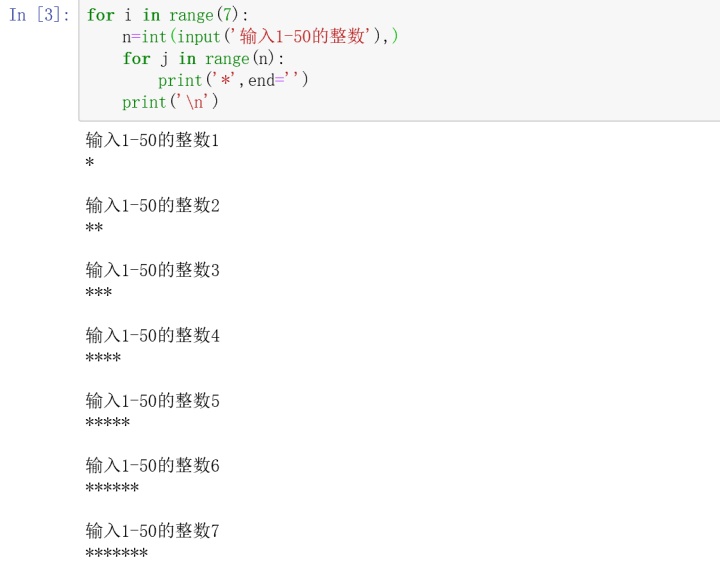
#89.解码
某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。
n=input("输入四位的整数:")
b=[]
for i in range(4):
a=(int(n[i])+5)%10 #每个数字加5,取10的余数
b.append(str(a))
b[3],b[0]=b[0],b[3] #交换1,4位
b[1],b[2]=b[2],b[1] #交换2,3位
print("".join(b))#90.列表详解
mylist=[1,28,36,43,5,6,3,2,41,23]
mylist.pop() #将列表中最后一个元素的删除
mylist
odd_or_even=[i%2 for i in mylist] #对列表中的每个元素进行操作
odd_or_even#91.time模块

#92.如何计算程序耗时情况
start=time.time()
for i in range(300):
print(i,end=',')
end=time.time()
print("n耗时:",end-start)#93.时间函数举例,程序耗时
import time
if __name__=='__main__':
t0=time.perf_counter()
p0=time.process_time()
for i in range(10):
time.sleep(2) #延时2秒
print(time.perf_counter()-t0) #会包含sleep休眠时间,适用测量短持续时间
print(time.process_time()-p0) #不包含sleep休眠时间#94.时间函数举例(time,ctime,localtime)
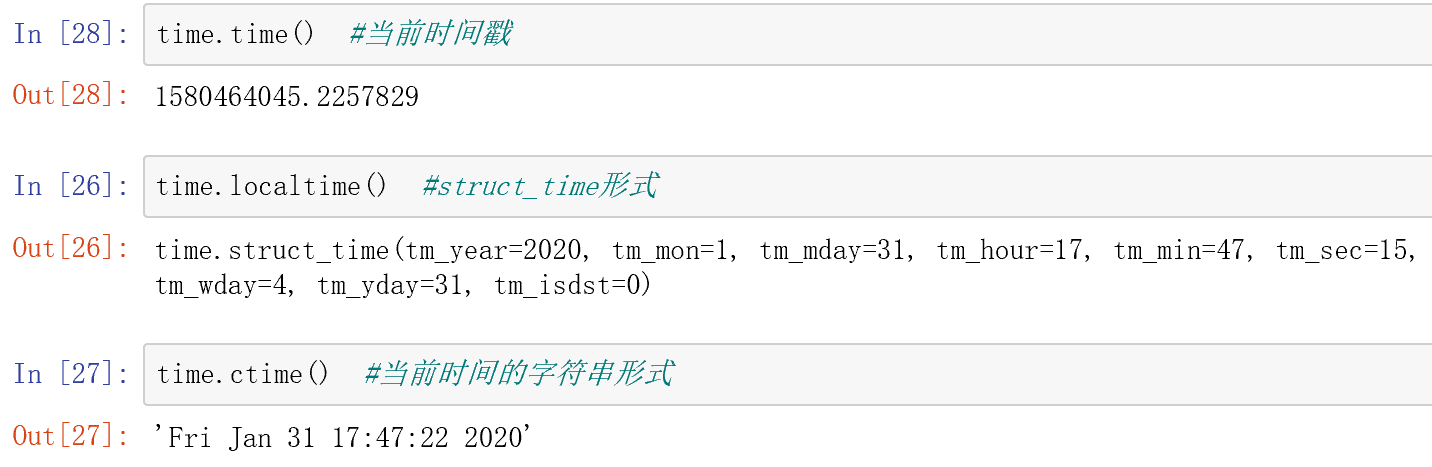
#95.转换时间格式(strptime和strftime)

#96.计算字符串中子字符串出现的次数(re,正则)
longstr='sb2bsbab2b2b2k2j2b2ba2bsaab'
import re
pat='2b'
res=re.compile(pat).findall(longstr)
print(res)
len(res)
#简单方法
longstr.count('2b')#97.从⌨输入字符,逐个写到文件上,直至输入#结束
if __name__=='__main__':
filename='example.txt'
f=open(filename,'w')
ch=input('输入字符,以#号结束:n')
while ch!='#':
f.write(ch)
ch=input('')
f.close()#98.从键盘输入一个字符串,将小写字母全部转化成大写字母,然后输入到磁盘文件test中保存。
if __name__=='__main__':
filename='test.txt'
f=open(filename,'w')
ch=input('输入字符串:n')
chnew=''
for i in ch:
if i.islower(): #判断是否为小写字母
i=i.upper() #是则转化为大写
print(i)
chnew+=i
print(chnew)
f.write(chnew)
f.close()#99.有两个磁盘文件A和B,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列), 输出到一个新文件C中。


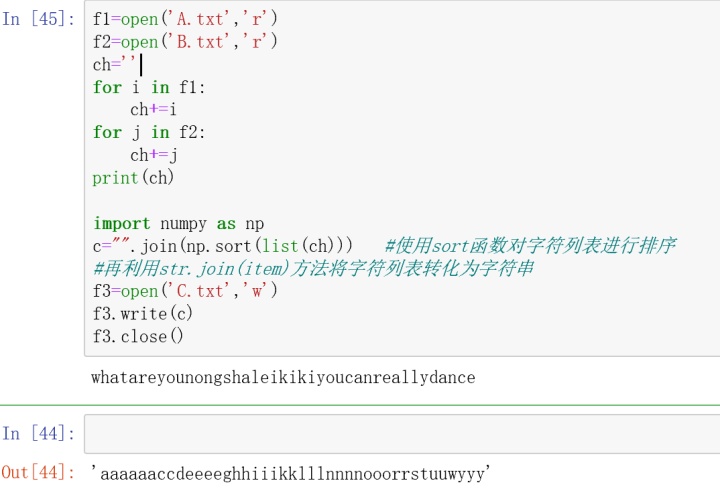
f1=open('A.txt','r')
f2=open('B.txt','r')
ch=''
for i in f1:
ch+=i
for j in f2:
ch+=j
print(ch)
import numpy as np
c="".join(np.sort(list(ch))) #使用sort函数对字符列表进行排序
#再利用str.join(item)方法将字符列表转化为字符串
f3=open('C.txt','w')
f3.write(c)
f3.close()#100.列表转字典
dict(zip(['a','b','c'],[1,2,3]))- - - - - - - - - - -补充知识 - - -- - -- - - - - - - -- -
"""
Created on Fri Dec 13 14:13:00 2019
Python的一些基本操作
@author: lina
"""
import os
os.getcwd()
os.chdir('E:Spider') #改变工作路径
#读取数据
from pandas import read_csv
data=read_csv("E:Rdatak.csv")
#变量
height=1.57
weight=50
weight/height**2 #20.28
#数据类型
type(height)
type(True)
#注意
x=['a','b','c']
y=x
y[1]='z'
print(x,y) #xy同时发生变化
x=['a','b','c']
y=list(x)
y[1]='z'
print(x,y) #仅y发生变化
#列表方法
fam=['liz',1.73,'emma',1.68,'mom',1.71,'dad',1.80]
fam.index('emma') #emma元素对应的索引
fam.count('mom') #列表元素计数
#字符方法
sister='liz is a beautiful girl'
sister.capitalize() #字符串首字母大写
sister.replace('liz','lisa')
#字典的相关操作
pop=[30.55,2.77,39.21]
countries=['china','america','canada']
pop[countries.index('china')] #china对应的人口
#将列表转化为字典
world=dict(zip(countries,pop))
world['china']
#字典添加元素
world['singapore']=18.6
world
#删除字典元素
del world['canada']
world
#字典元素的打印
for key,value in world.items():
print(key+':'+str(value))Numpy库
#numpy库,简单快速,计算
import numpy as np
np.array([1,'2',3]) #数组只能有一种数据类型
[1,2,3]+[1,2,3] #[1,2,3,1,2,3]
np.array([1,2,3])+np.array([1,2,3]) #np.array([2,4,6])
a=np.array([1,2,3])
a[a>2] #array([3])
a>2 #false,false,true
#二维数组
import numpy as np
np_height = np.array([1.73, 1.68, 1.71, 1.89, 1.79])
np_weight = np.array([65.4, 59.2, 63.6, 88.4, 68.7])
np_2d=np.hstack([np_height,np_weight]) #横向叠加10*1
np_2d=np.vstack([np_height,np_weight]) #纵向叠加2*5
np_2d.shape
#数组元素的打印
for i in np.nditer(np_2d):
print(i)
np_2d[1][2] #第二行第三个元素
np.median(np_2d[0]) #身高的中位数
np.corrcoef(np_2d[0],np_2d[1]) #身高和体重的相关系数
from math import sqrt
np.mean(np_2d[1]) #体重的平均数
sqrt(np.var(np_2d[1])) #体重的标准差10.145
#生成5个服从均值为69,标准差为10的正态分布随机数
np.round(np.random.normal(69,10,5),2) #保留两位小数Pandas库
dict = {
"country":["Brazil", "Russia", "India", "China", "South Africa"],
"capital":["Brasilia", "Moscow", "New Delhi", "Beijing", "Pretoria"],
"area":[8.516, 17.10, 3.286, 9.597, 1.221],
"population":[200.4, 143.5, 1252, 1357, 52.98] }
import pandas as pd
brics=pd.DataFrame(dict)
brics.index=['BR','RU','IN','CN','SA']
#提取数据框的某列
brics["country"]
type(brics["country"]) #Series类型
brics[['country']]
type(brics[['country']]) #DataFrame类型
brics.loc[:,['country','area']]
#提取数据框的行
brics[:3] #前三行
brics.loc["RU"] #Series类型
brics.loc[["RU"]] #DataFrame类型
#提取数据框的某行某列
brics.loc[["RU"],['country','area']]
#对比:多维数组提取某行某列元素 arrayxx[row,column]
brics_arr=np.array(brics)
brics_arr.shape
brics_arr[1,[0,2]]
#iloc替换loc,指定索引值
brics.iloc[:,[0,2]] #提取国家和面积列
brics.iloc[:3,:] #前三行
brics.iloc[1,:] #提取第2行
#提取满足某些条件的行和列
#1.挑选面积大于8的国家
ishuge=brics.loc[:,'area']>8 #brics["area"]>8 bool型
brics.loc[:,'country'][ishuge]
brics[ishuge]
#2.挑选面积大于8的国家,而蜗牛属小于200
brics[np.logical_and(brics["area"]>8,brics["population"]<200)]
for lab,row in brics.iterrows():
print(lab,':',row['country'])
for lab,row in brics.iterrows():
brics.loc[lab,'name_length']=len(row['country'])
print(brics)
del brics["name_length"] #删除指定列
brics["name_length"]=brics["country"].apply(len) #计算每个国家名字符串的长度
print(brics)