第四周
8、神经网络
8.1 非线性假设
图像识别难,计算机看到的是灰度矩阵/RGB存储量x3
- 8.2 神经元和大脑
假设大脑思维方式不需要成千上万算法,而只需要一个。
躯体感觉皮层进行神经重接(视觉)实验,该皮层也能学会看。
如果人体有同一块脑组织可以处理光、声或触觉信号,也许存在一种学习算法,可以同时处理视觉、听觉和触觉。
8.3 模型展示1
神经元(激活单位),输入/树突,输出/轴突


每一个?都是由上一层所有的?和每一个?所对应的θ决定的。从左到右的算法称为前向传播算法。
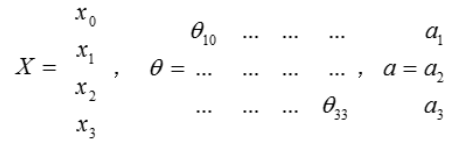
8.4 模型展示2

右半部分其实就是以?0, ?1, ?2, ?3, 按照逻辑回归的方式输出ℎ?(?)
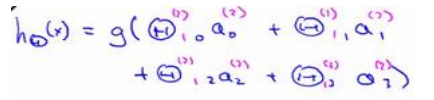
神经网络 vs 逻辑回归
只是把逻辑回归的输入向量变成中间层
- 8.5 特征和直观理解1

单层神经网络和逻辑回归很像。
8.6 样本和直观理解2
若要实现逻辑非,在预计得到非结果的变量前放一个很大的负权重。
将表示 AND 的神经元和表示(NOT x1) AND (NOT x2)的神经元以及表示OR 的神经元进行组合,得到了一个能实现XNOR运算符功能的神经网络如下。

- 8.7 多类分类
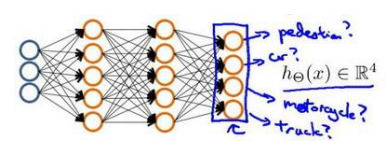
输出层4个神经元分别用来表示4类,也就是每一个数据在输出层都会出现[? ? ? ?]?,且?, ?, ?, ?中仅有一个为1,表示当前类。
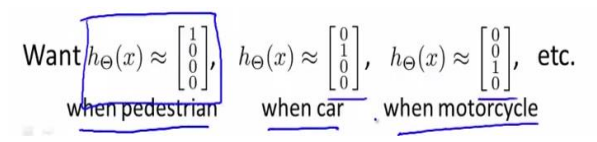
第五周
9、神经网络的学习
9.1 代价函数

9.2 反向传播
信息前向传播,误差反向传播
9.7 综合起来
训练神经网络:
- 参数的随机初始化
- 利用正向传播方法计算所有的ℎ?(?)
- 编写计算代价函数 ?的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
第六周
10、应用机器学习的建议
10.2 评估一个假设
70%数据做训练集,30%数据做测试集
10.3 模型选择和交叉验证集
60%数据训练集:用来训练θ
20%数据交叉验证:选择多项式
20%数据测试集:判断泛化能力


10.4 偏差和方差

训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
10.5 正则化和偏差/方差
选择合适的入,0-10之间呈现2倍关系的值,分为12组试试

Jθ代价函数,Jcv交叉验证误差

10.6 学习曲线
高偏差/欠拟合增加训练集无帮助
高方差/欠拟合有帮助
10.7 决定下一步做什么
模型有较大误差:
- 获得更多的训练实例 —— 解决高方差
- 尝试减少特征的数量 —— 解决高方差
- 尝试获得更多的特征 —— 解决高偏差
- 尝试增加多项式特征 —— 解决高偏差
- 尝试减少正则化程度 λ—— 解决高偏差
- 尝试增加正则化程度 λ—— 解决高方差
较小神经网络计算量小,易出现欠拟合;大型神经网络已出现过拟合。
通常选择较大神经网络并采用正则化,比直接采用小型效果更好。
神经网络层数的选择:通过将数据分为:训练集、交叉验证集和训练集,进行训练
11、机器学习系统的设计
11.2 误差分析
- 从一个简单的能快速实现的算法开始:实现该算法并用交叉验证集数据测试这个算法
- 绘制学习曲线:决定是增加更多数据,或者添加更多特征,还是其他选择
- 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些
11.3 类偏斜的误差度量
查准率=TP/(TP+FP)
查全率=TP/(TP+FN)

11.4 查准率和查全率之间的权衡
阈值越大,判断为真的正确率越高,但是会遗漏更多正样本
用max(F1)选择阈值,会考虑查准率和查全率平均值,但会给其中较低的值更高权重
11.5 机器学习的数据
取得成功的人不是拥有最好算法的人,而是拥有最多数据的人
第七周
12、支持向量机SVM
12.1 优化目标


12.2 大边界的直观理解
支持向量机 = 大间距分类器,具有鲁棒性


正则化参数C,设置的非常大,遇到异常点会更改边界。
C不是太大,会忽略一些异常点,得到更好的边界
回顾? = 1/?,因此:
?较大时,相当于?较小,可能会导致过拟合,高方差。
?较小时,相当于?较大,可能会导致低拟合,高偏差
12.3 大边界分类背后的数学

参数向量?事实上是和决策界是90度正交的。
支持向量机最终可以找到一个较小的?范数。这正是支持向量机中最小化目标函数的目的。
12.4 核函数1
??????????(?, ?(1))就是核函数
![]()
δ^2越大,从顶点移走,特征变量值减小速度会比较慢
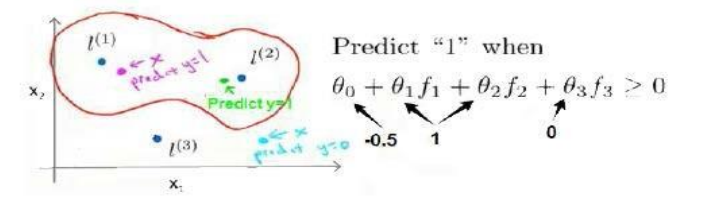

不使用核函数就是线性核函数。
下面是支持向量机的两个参数?和?的影响:
- ? = 1/?
- ?较大时,相当于?较小,可能会导致过拟合,高方差;
- ?较小时,相当于?较大,可能会导致低拟合,高偏差;
- ?较大时,可能会导致低方差,高偏差;
- ?较小时,可能会导致低偏差,高方差。
12.6 使用支持向量机
核函数解决高偏差,可构建复杂的非线性决策边界。
从逻辑回归模型,我们得到了支持向量机模型,在两者之间,我们应该如何选择呢?
逻辑回归和不带核函数的SVM相似。
下面是一些普遍使用的准则:
?为特征数,?为训练样本数。
(1)如果相较于?而言,?要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果?较小,而且?大小中等,例如?在1-1000之间,而?在10-10000之间,使用高斯核函数的支持向量机。
(3)如果?较小,而?较大,例如?在1-1000之间,而?大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机
神经网络有时训练起来比较慢。