1.分句
from pyltp import SentenceSplitter
sents = SentenceSplitter.split('元芳你怎么看?我就趴在窗口上看呗!元芳你怎么这样子了?我哪样子了?')
sents = '\n'.join(sents) #不经过此处处理直接输出会报错 原因是没有给出输出的格式 当然 sents = '|'.join(sents)是用“|”分割的
print(sents)
输出结果:
元芳你怎么看?
我就趴在窗口上看呗!
元芳你怎么这样子了?
我哪样子了?
2.分词
import os
from pyltp import Segmentor
LTP_DATA_DIR = r'C:\Users\22843\AppData\Local\Programs\Python\Python36\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data' # LTP模型目录路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径, 模型名称为'cws.model'
segmentor = Segmentor() #初始化实例
segmentor.load(cws_model_path) #加载模型
words =segmentor.segment('元芳你怎么看') #分词 返回类型值是native的VectorOfString类型,可以使用list转换为Python列表
print(type(words)) #分词类型
words = '|'.join(words)
print(type(words))
print(words)
segmentor.release() #释放模型
输出结果:
<class 'pyltp.VectorOfString'>
<class 'str'>
元芳|你|怎么|看
使用分词外部词典:
首先建立一个外部的词典文件:plain.txt
苯并芘
亚硝酸盐
代码:
import os
from pyltp import Segmentor
LTP_DATA_DIR = r'C:\Users\22843\AppData\Local\Programs\Python\Python36\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data' # LTP模型目录路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径, 模型名称为'cws.model'
segmentor = Segmentor() #初始化实例
segmentor.load_with_lexicon(cws_model_path,'plain.txt') #加载模型
words =segmentor.segment('亚硝酸盐是一种化学物质') #分词 返回类型值是native的VectorOfString类型,可以使用list转换为Python列表
print(type(words)) #分词类型
words = '|'.join(words)
print(type(words))
print(words)
segmentor.release() #释放模型
运行结果:
<class 'pyltp.VectorOfString'>
<class 'str'>
亚硝酸盐|是|一|种|化学|物质
[INFO] 2020-11-20 00:52:40 loaded 2 lexicon entries
3.词性标注
import os
from pyltp import Postagger
LTP_DATA_DIR = r'C:\Users\22843\AppData\Local\Programs\Python\Python36\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data' # LTP模型目录路径
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 分词模型路径, 模型名称为'cws.model'
postagger = Postagger() #初始化实例
postagger.load(pos_model_path) #加载模型
words = ['元芳','你','怎么','看'] #words是分词模块的返回值,也支持Python原来的list
postags = postagger.postag(words) #词性标注
postags = '|'.join(postags)
print(postags)
postagger.release() #释放模型
运行结果:
nh|r|r|v
LTP 使用 863 词性标注集,详细请参考 词性标准集。如下图所示

4.命名实体识别
import os
from pyltp import NamedEntityRecognizer
LTP_DATA_DIR = r'C:\Users\22843\AppData\Local\Programs\Python\Python36\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data' # LTP模型目录路径
ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 分词模型路径, 模型名称为'cws.model'
recognizer = NamedEntityRecognizer() #初始化shili
recognizer.load(ner_model_path) #加载模型
words = ['元芳', '你', '怎么', '看'] # 分词模块的返回值
postags = ['nh', 'r', 'r', 'v'] # 词性标注的返回值
netags = recognizer.recognize(words,postags) #命名实体识别
print(netags)
print(list(netags))
recognizer.release() #模型释放
运行结果:
<pyltp.VectorOfString object at 0x0000025FCEDAA450>
['S-Nh', 'O', 'O', 'O']
LTP 采用 BIESO 标注体系。B 表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,O表示不构成命名实体。
LTP 提供的命名实体类型为:人名(Nh)、地名(Ns)、机构名(Ni)。
B、I、E、S位置标签和实体类型标签之间用一个横线 - 相连;O标签后没有类型标签。
详细标注请参考 命名实体识别标注集。
NE识别模块的标注结果采用O-S-B-I-E标注形式,其含义为
5.依存句法分析
import os
from pyltp import Parser
LTP_DATA_DIR = r'C:\Users\22843\AppData\Local\Programs\Python\Python36\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data' # LTP模型目录路径
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 分词模型路径, 模型名称为'cws.model'
parser = Parser() #初始化实例
parser.load(par_model_path) #加载模型
words = ['元芳', '你', '怎么', '看'] # 分词模块的返回值
postags = ['nh', 'r', 'r', 'v'] # 词性标注的返回值
arcs = parser.parse(words,postags) #句法分析
arcs = '\t'.join('%d:%s'%(arc.head,arc.relation) for arc in arcs)
#arc.head表示依存弧的父节点词的索引。ROOT节点的索引是0,第一个词开始的索引依次为1,2,3...
#arc.relation表示依存弧的关系
print(arcs)
parser.release() #模型释放
运行结果:
4:SBV 4:SBV 4:ADV 0:HED
依存句法关系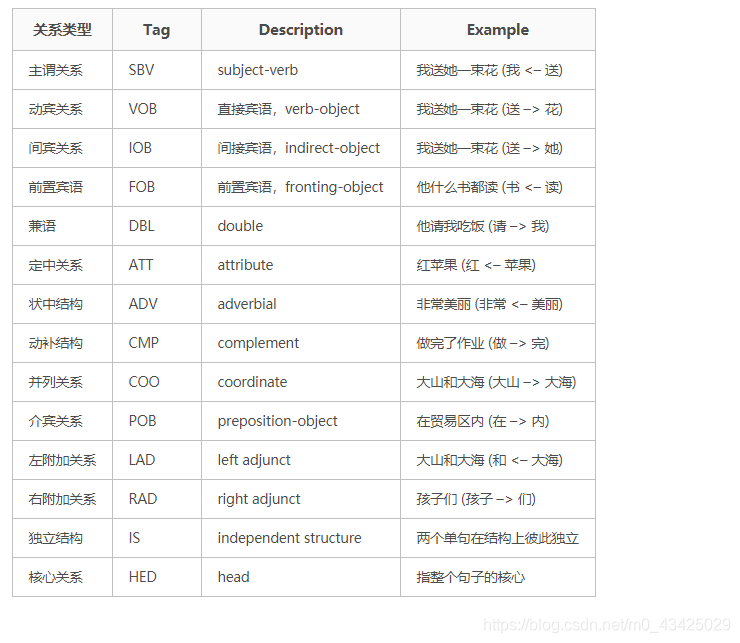
6.词义角色标注
import os
LTP_DATA_DIR='D:\Data\ltp_data_v3.4.0' # ltp模型目录的路径
srl_model_path = os.path.join(LTP_DATA_DIR, 'pisrl_win.model') # 语义角色标注模型目录路径,模型目录为`srl`。注意该模型路径是一个目录,而不是一个文件。
from pyltp import SementicRoleLabeller
labeller = SementicRoleLabeller() # 初始化实例
labeller.load(srl_model_path) # 加载模型
words = ['元芳', '你', '怎么', '看']
postags = ['nh', 'r', 'r', 'v']
# arcs 使用依存句法分析的结果
roles = labeller.label(words, postags, arcs) # 语义角色标注
# 打印结果
for role in roles:
print(role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
labeller.release() # 释放模
运行结果:
[dynet] random seed: 1676210130
[dynet] allocating memory: 2000MB
[dynet] memory allocation done.
3 A0:(1,1)ADV:(2,2)
词义角色关系
完整示例
import os, sys
from pyltp import SentenceSplitter, Segmentor, Postagger, Parser, NamedEntityRecognizer, SementicRoleLabeller
LTP_DATA_DIR = r'C:\Users\22843\AppData\Local\Programs\Python\Python36\Lib\site-packages\pyltp-0.2.1.dist-info\ltp_data' # LTP模型目录路径
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径, 模型名称为'cws.model'
paragraph = '中国进出口银行与中国银行加强合作。中国进出口银行与中国银行加强合作!'
sentence = SentenceSplitter.split(paragraph)[0] # 分句并取第一句
# 分词
segmentor = Segmentor() # 初始化
segmentor.load(os.path.join(LTP_DATA_DIR, 'cws.model')) # 加载模型
words = segmentor.segment(sentence) # 分词
print(list(words))
print('|'.join(words))
# 词性标注
postagger = Postagger() # 初始化
postagger.load(os.path.join(LTP_DATA_DIR, 'pos.model')) # 加载模型
postags = postagger.postag(words)
# postags = postagger.postag(['中国', '进出口', '银行', '与', '中国银行', '加强', '合作', '。'])
print(list(postags))
# 依存句法分析
parser = Parser()
parser.load(os.path.join(LTP_DATA_DIR, 'parser.model'))
arcs = parser.parse(words, postags)
print('\t'.join('%d:%s' % (arc.head, arc.relation) for arc in arcs))
# 命名实体识别
recognizer = NamedEntityRecognizer() # 实例化
recognizer.load(os.path.join(LTP_DATA_DIR, 'ner.model'))
netags = recognizer.recognize(words, postags)
print(list(netags))
# 语义角色标注
labeller = SementicRoleLabeller()
labeller.load(os.path.join(LTP_DATA_DIR, 'pisrl_win.model'))
roles = labeller.label(words, postags, arcs)
for role in roles:
print(role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
segmentor.release() # 释放
postagger.release()
parser.release()
recognizer.release()
labeller.release()
运行结果:
['中国', '进出口', '银行', '与', '中国银行', '加强', '合作', '。']
中国|进出口|银行|与|中国银行|加强|合作|。
['ns', 'v', 'n', 'p', 'ni', 'v', 'v', 'wp']
3:ATT 3:ATT 6:SBV 6:ADV 4:POB 0:HED 6:VOB 6:WP
[dynet] random seed: 921284091
[dynet] allocating memory: 2000MB
['B-Ni', 'I-Ni', 'E-Ni', 'O', 'S-Ni', 'O', 'O', 'O']
[dynet] memory allocation done.
SRL: Model not loaded!
参考博客
https://www.cnblogs.com/huiyichanmian/p/10844285.html
版权声明:本文为m0_43425029原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。