一、原理
hashmap的底层是由数组和链表实现的,数组大小如果不设置的话默认长度为16。
根据key的值以及其他的一些参数,比如hashSeed来计算出一个hash,然后通过hash和数组长度计算出一个下标。
hashmap存的都是一个个的entry对象,存的时候如果数组对应下标地方没有值,直接放在数组上,如果有值就生成一个链表。当然,如果key重复就直接修改value。
二、初始化
放入hashmap里面的数据其实都是一个个Entry<K,V>,
final K key;
V value;
Entry<K,V> next;
int hash;
创建hashmap对象的时候可以自己指定数组的初始大小和负载因子,如果不指定的话java就会使用默认的16和0.75
源码:
public HashMap() {
//DEFAULT_INITIAL_CAPACITY数组长度 默认为16,DEFAULT_LOAD_FACTOR默认为0.75
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
//如果数组长度小于0,就报异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//如果数组长度大于最大值,就给他赋值为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//如果负载因子小于等于0或者不是数字,就报异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//将负载因子塞入对象属性
this.loadFactor = loadFactor;
//阈值等于数组长度
threshold = initialCapacity;
//hashmap里面init方法为空,linkedhashmap里面init方法不为空
init();
}
三、put方法
源码:
public V put(K key, V value) {
//如果数组为空数组
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为空的话
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
//计算数组长度为大于等于初始化的长度的2的幂次方,比如toSize为10,capacity 就等于16
int capacity = roundUpToPowerOf2(toSize);
//阈值为数组大小*负载因子和最大值加1里面小的那一个
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//创建一个新entry
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
//判断number 是不是大于等于最大值,如果是就赋值为最大值
//如果大于1小于最大值,number为大于等于number的最小的一个2的幂次方,比如number=23,name给它赋值number=32
//如果小于等于1,number为1
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
//这个方法的主要作用就是算出i以下的最大的一个2的幂次方。比如i=23,结果就为16
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
//计算hashseed(就是hash的散列程度)
final boolean initHashSeedAsNeeded(int capacity) {
//判断如果hashSeed不为0,currentAltHashing 就为true(hashSeed默认为0)
boolean currentAltHashing = hashSeed != 0;
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
//根据jvm参数 jdk.map.althashing.threshold 计算初始化ALTERNATIVE_HASHING_THRESHOLD
static final int ALTERNATIVE_HASHING_THRESHOLD;
static {
String altThreshold = java.security.AccessController.doPrivileged(
new sun.security.action.GetPropertyAction(
"jdk.map.althashing.threshold"));
int threshold;
try {
threshold = (null != altThreshold)
? Integer.parseInt(altThreshold)
: ALTERNATIVE_HASHING_THRESHOLD_DEFAULT;
// disable alternative hashing if -1
if (threshold == -1) {
threshold = Integer.MAX_VALUE;
}
if (threshold < 0) {
throw new IllegalArgumentException("value must be positive integer.");
}
} catch(IllegalArgumentException failed) {
throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed);
}
ALTERNATIVE_HASHING_THRESHOLD = threshold;
}
//如果key为null的话
private V putForNullKey(V value) {
//查询数组第一个位置以及上面的链表,如果有key为null的entry,那么直接修改value,并返回修改之前的value,recordAccess方法在hashmap里面为空
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//修改次数加1
modCount++;
addEntry(0, null, value, 0);
return null;
}
//计算数组下标,
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
//把entry加入hashmap里面
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果hashmap里面entry的数量大于等于阈值(数组长度*负载因子)同时key对应数组下标位置不为null,就给hashmap进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容
resize(2 * table.length);
//根据key计算下标
hash = (null != key) ? hash(key) : 0;
//根据hash和新的数组长度计算下标
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//扩容
void resize(int newCapacity) {
//将数组用oldTable存放
Entry[] oldTable = table;
//扩容前数组长度
int oldCapacity = oldTable.length;
//如果扩容前数组长度为最大值MAXIMUM_CAPACITY,阈值就为Integer.MAX_VALUE
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建一个新的entry数组,长度为newCapacity(之前长度的两倍)
Entry[] newTable = new Entry[newCapacity];
//将之前数组的内容插入到新数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//数组指向新数组
table = newTable;
//计算新数组的阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
//将之前数组的内容插入到新数组中,因为是头插法,所以多线程的时候会出现循环链表的情况
void transfer(Entry[] newTable, boolean rehash) {
//新数组长度
int newCapacity = newTable.length;
//for循环遍历老数组,while循环遍历数组上面的链表
for (Entry<K,V> e : table) {
while(null != e) {
//将节点的<下一节点>这个属性赋给next,用于下一次循环
Entry<K,V> next = e.next;
//哈希的散列程度,默认为false
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//计算在新数组中的下标
int i = indexFor(e.hash, newCapacity);
//节点的<下一节点>属性改为新数组的下标所在位置(这个时候节点处于新数组下标位置的上方)
e.next = newTable[i];
//将新数组下标为止赋值为该节点(这个时候该节点就成功的赋值给了新数组下标位置)
newTable[i] = e;
//将之前老数组中该节点的下一节点赋值给变量e,用来再次循环
e = next;
}
}
}
//将数组中的下标位置的节点赋值给变量e,然后把下标所在位置让给新增的entry,变量e的节点为新增节点的下一节点,同时把hashmap数量加1
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
四、get方法
源码:
public V get(Object key) {
//如果key为null
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
//如果key为null
private V getForNullKey() {
//如果hashmap长度为0,返回null
if (size == 0) {
return null;
}
//循环访问数组下标为0的位置上面的链表
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
//如果存在节点key为null,返回对应的value
if (e.key == null)
return e.value;
}
return null;
}
//根据key寻找value
final Entry<K,V> getEntry(Object key) {
//如果hashmap长度为0,返回null
if (size == 0) {
return null;
}
//计算hash
int hash = (key == null) ? 0 : hash(key);
//循环对应下标上面的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//如果hash相等,key的hashcode或者值相等,就返回这个节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
五、remove方法
源码:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
//如果hashmap长度为0,返回null
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
//key的hash对应下标
int i = indexFor(hash, table.length);
//key的hash对应数组下标位置的节点
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
//循环访问链表
while (e != null) {
//把当前节点的下一节点赋值给next变量
Entry<K,V> next = e.next;
Object k;
//如果hash相等并且(key的hashcode相等或者key的值相等),修改次数加1,数量减1
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
//如果prev==e,第一次
if (prev == e)
table[i] = next;
//如果prev!=e
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
这里有个经典的错误:
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
因为初始化的时候会 expectedModCount = modCount;但是如果循环删除的时候使用hashmap的remove方法,会执行modCount++,这就导致expectedModCount = modCount两个不相等,所以如果我们需要使用循环删除,使用HashIterator里面的remove方法就可以了。
六、线程不安全
jdk1.7里面线程不安全体现在扩容的时候转移数据。
扩容之后数据的转移代码如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
我们假设数组长度为3,在下标为1的地方存了3个entry,扩容也放在同一个位置(当然这是不可能的,我这里是为了演示,好画图)
3个entry分别为:
1|2----> key=1,next=2;
2|3----> key=2,next=3;
3|null---->key=3,next=null
线程1和线程2新增的数组分别为newTable1,newTable2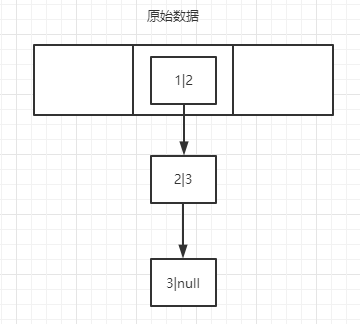
当线程1执行到Entry<K,V> next = e.next;这行的时候突然让出了资源,让线程2执行,这个时候e1=1|2,next1=2|3。
然后线程2执行
第一次循环:
Entry<K,V> next = e.next; -----执行结果-------e2=1|null,next2=2|3,newTable2[1]=null
e.next = newTable[i]; -----执行结果-------e2=1|null,next2=2|3,newTable2[1]=null
newTable[i] = e; -----执行结果-------e2=1|null,next2=2|3,newTable2[1]=e2=1|null
e = next; -----执行结果-------e2=2|3,next2=2|3,newTable2[1]=e2=1|null
第二次循环:
Entry<K,V> next = e.next; -----执行结果-------e2=2|3,next2=3|null,newTable2[1]=1|null
e.next = newTable[i]; -----执行结果-------e2=2|1,next2=3|null,newTable2[1]=1|null
newTable[i] = e; -----执行结果-------e2=2|1,next2=3|null,newTable2[1]=e2=2|1
e = next; -----执行结果-------e2=3|null,next2=3|null,newTable2[1]=2|1
第三次循环:
Entry<K,V> next = e.next; -----执行结果-------e2=3|null,next2=null,newTable2[1]=2|1
e.next = newTable[i]; -----执行结果-------e2=3|2,next2=null,newTable2[1]=2|1
newTable[i] = e; -----执行结果-------e2=3|2,next2=null,newTable2[1]=e2=3|2
e = next; -----执行结果-------e2=null,next2=null,newTable2[1]=e2=3|2
第四次循环:
while(null != e)因为e2=null条件不符合,所以循环结束。
流程如下: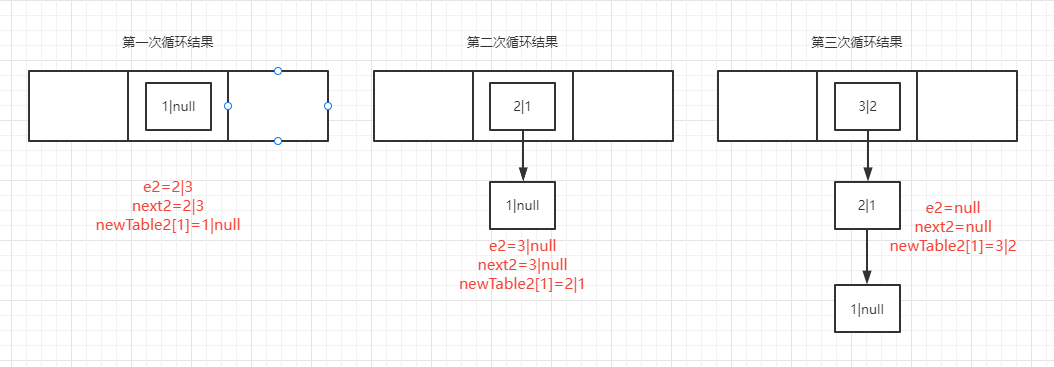
当线程2之行结束之后,线程1开始继续执行
第一次循环:
e.next = newTable[i]; -----执行结果-------e1=1|null,next1=2|1,newTable1[1]=null(原本next1=2|3,但是由于线程2把entry对象修改了,所以现在变成了next1=2|1)
newTable[i] = e; -----执行结果-------e1=1|null,next1=2|1,newTable1[1]=1|null
e = next; -----执行结果-------e1=2|1,next1=2|1,newTable1[1]=1|null
第二次循环:
Entry<K,V> next = e.next; -----执行结果-------e1=2|1,next1=1|null,newTable1[1]=1|null
e.next = newTable[i]; -----执行结果-------e1=2|1,next1=1|null,newTable1[1]=1|null
newTable[i] = e; -----执行结果-------e1=2|1,next1=1|null,newTable1[1]=2|1
e = next; -----执行结果-------e1=1|null,next1=1|null,newTable1[1]=2|1
第三次循环:
Entry<K,V> next = e.next; -----执行结果-------e1=1|null,next1=null,newTable1[1]=2|1
e.next = newTable[i]; -----执行结果-------e1=1|2,next1=2|1,newTable1[1]=2|1
newTable[i] = e; -----执行结果-------e1=1|2,next1=2|1,newTable1[1]=1|2
e = next; -----执行结果-------e1=2|1,next1=2|1,newTable1[1]=1|2
这个时候我们发现一个问题,key为1的entry他的next为2,key为2的entry他的next为1
流程如下: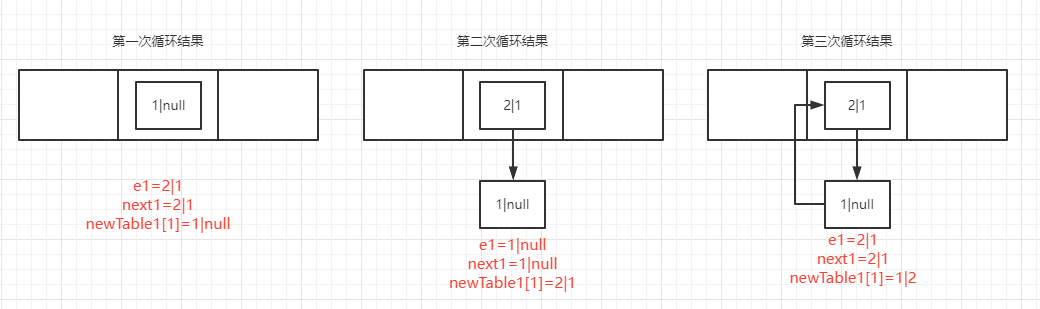
形成了一个循环链表就会一直执行一下,很明显是有问题的,出现这个结果的因为就是用了头插法,转移entry的时候entry的顺序都是相反的。