一个串行程序
在超算上编写一段简单的C语言程序main.c,如下图所示: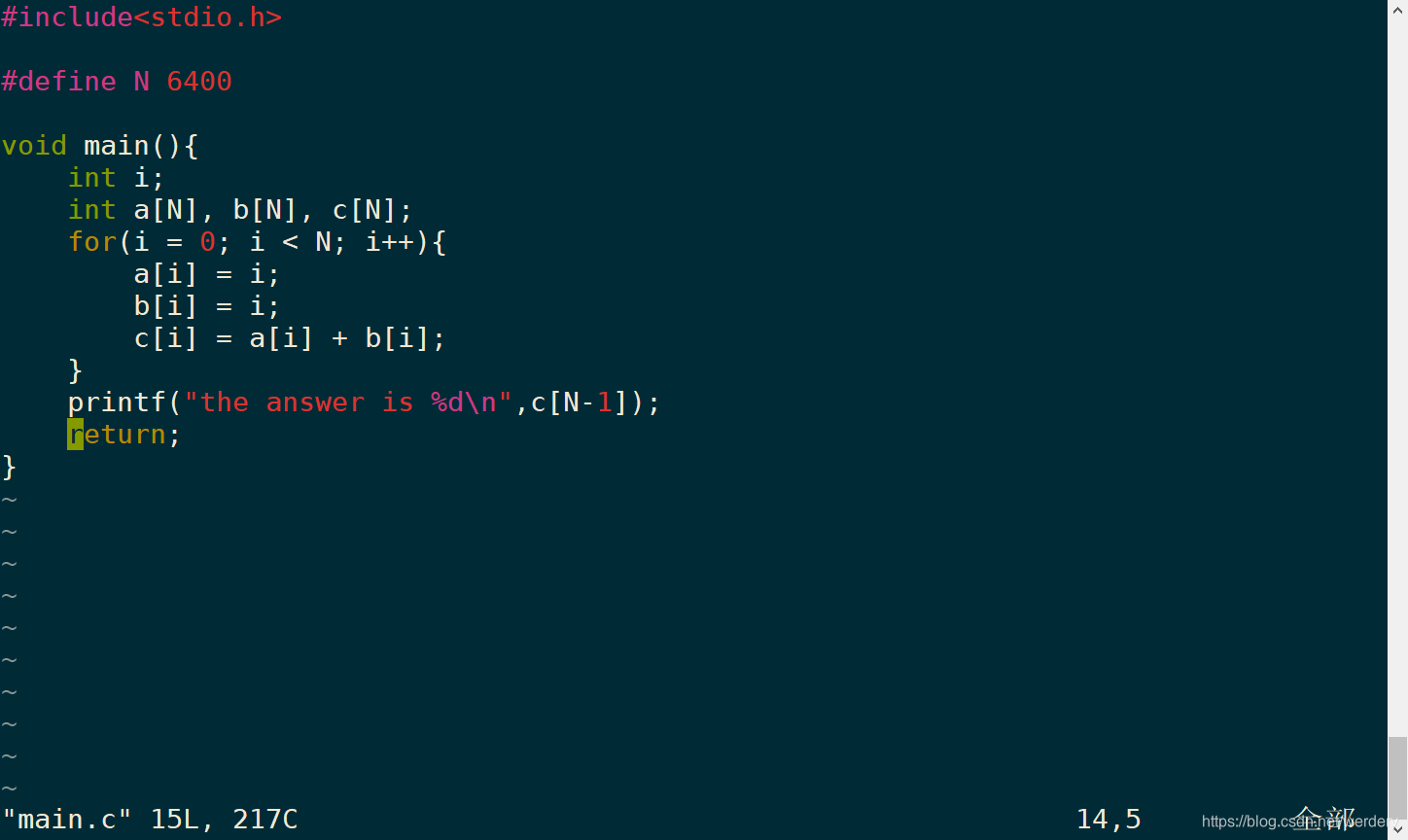
实现a,b两数组的初始化,并把两数组之和赋值给c数组, 最后通过输出c确定该过程的正确性。
通过以下即可生成可执行文件exe.
gcc main.c -o exe
然后执行exe,可见输出如下图:
程序正确执行。
并行了吗?
这个时候给读者抛出一个问题,如果我们登陆的是超算平台,该程序是否已经并行?如果并行了,是多少个进程在并行?如果没有并行,为什么?如何并行?
如果读者不能很好的回答这个问题,大概率是因为对高性能计算集群不太熟悉。一个高性能集群可以简单划分为登陆节点和计算节点。示意图如下所示: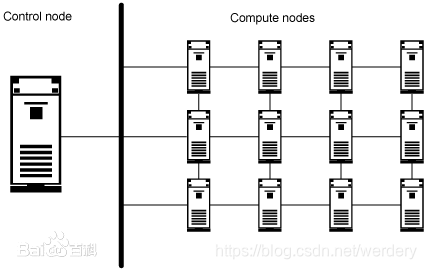
该图为高性能集群的组成示意图,图的左侧为控制节点等同于登陆节点,右侧为计算节点。
当我们通过ssh工具登陆到高性能集群系统时,其实连接的是登陆节点,因此当我们在登陆节点上执行./exe时,是在登陆节点上执行程序。
通过名称我们也可以知道登陆节点并不适合执行程序,应该交由计算节点执行计算任务(在一些特殊情况下,我们也会在登陆节点上执行程序,不建议)。
那么用户如何将一个可执行程序运行在多个计算节点上?已经存在一些作业提交系统比如lsf、pbs、slurm等用于解决这个问题。其中作业指我们需要运行的程序,提交表示提交到计算节点。
以lsf为例,使用以下指令便可以将exe程序提交到queue01队列的10个计算节点上。
bsub -q queue01 -n 10 ./exe
对于队列,写者认为是为了方便集群管理人员分配计算节点所设置的。管理人员将计算节点分配给队列,再将队列分配给用户,通过这种方式管理计算节点的分配。详细的作业提交系统可以参考lsf和pbs的对比。
效率提高了吗?
上述的指令指定了节点数量为10,即进程数为10。其加速比公式为
Sp=Ts/Tp
其中Ts为串行时间,Tp为并行时间,Sp为加速比。理想状态下加速比等于进程数量即Sp=10。可是我们的加速比约等于10了吗?
另外一个衡量指标:并行效率。
Ep=Ts/(p*Tp)
其中p为进程数量,Ep为并行效率,Ep取值范围为0-1,Ep值越高并行效率越高,并行效果越好,理想状态下Ep为1。同理,并行效率接近1吗?
回头仔细想了下我们的串行程序循环执行了6400次,然后在10个节点上,每个节点都循环执行了6400次,显然很多计算属于无用功。
一个典型的并行处理方式:
将for循环平均切分到不同进程上,每个进程只执行for循环的一部分。如下图所示:
那么代码怎么写呢?
似乎需要我们指定,1号进程执行for循环的前1/10部分,2号进程执行for循环的第二个1/10部分,以此类推。
MPI(massage passing interface,消息传递接口)为我们提供了这样的功能。
下图为通过MPI技术将for循环拆分到10个进程上的代码(牢记:一处代码,多处执行):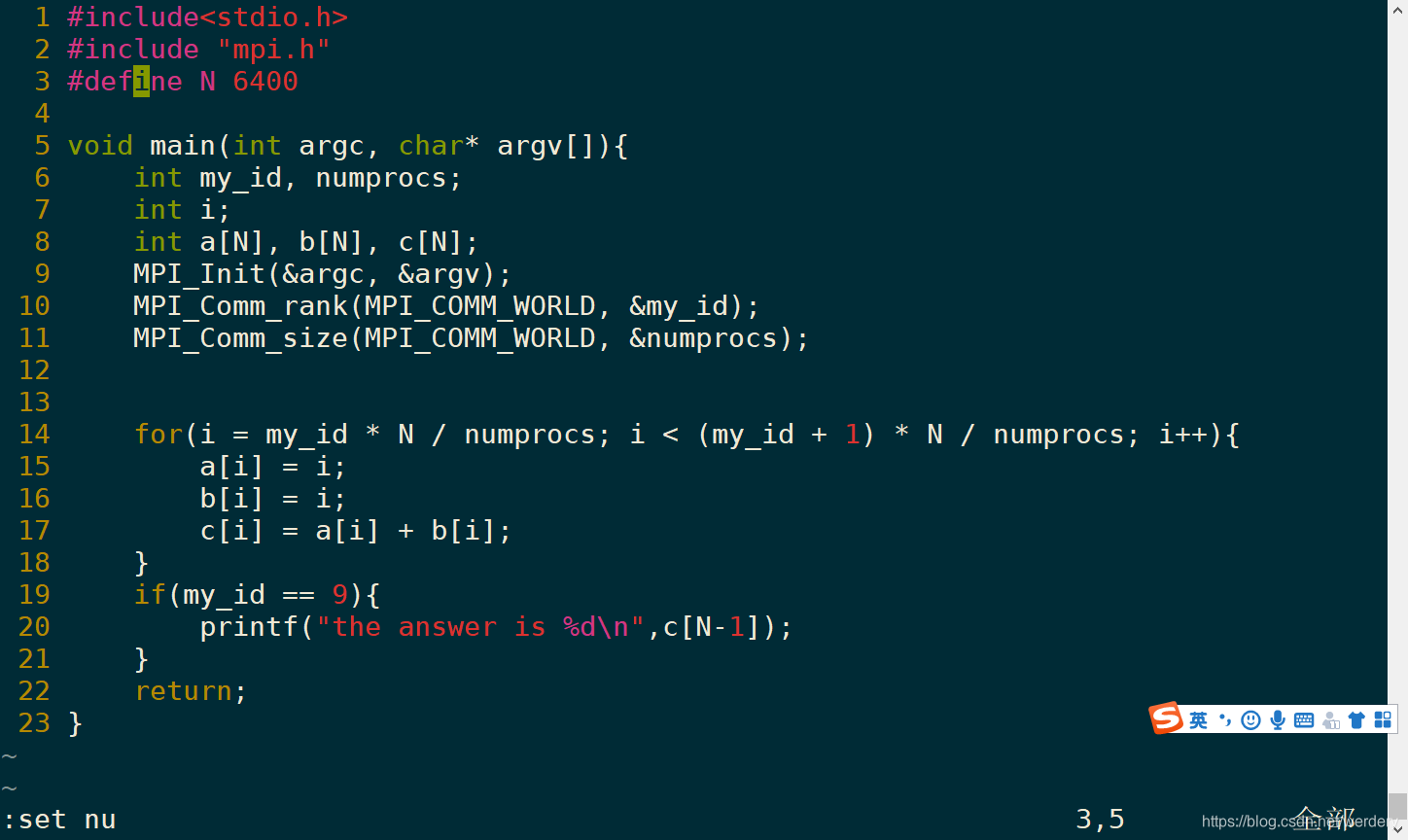
改动包括:
第2行:添加头文件mpi.h
第5行:添加main函数的传入参数
第9-11行:添加MPI初始化以及获取进程id和总进程数。
第14行:将for循环拆分到10个进程上,每个进程仅计算整个循环的1/10。
通过以下命令(mpi提供)编译生成可执行程序,然后提交到10个进程上。
mpicc main.c -o exe
mpirun -n 10 ./exe
程序员可以通过MPI技术告诉每个进程要做什么工作,也可以告诉进程如何互相传输数据,传输多大的数据,因此这些工作可以被称为“消息”,写者认为这也是MPI被称为消息传递接口的原因。
tips:
在编写并行程序的时候牢记一点“一处代码,多处执行”。
并行程序并不是在整个MPI_init后才开始,是整个文件并行的在不同计算节点上运行。
除了MPI之外还可以通过使用openMP自动地拆分for循环。
如何提交并行程序?
前有bsub后有mpirun,选择哪个,有何区别?
对于简单的超算,未安装作业提交系统,可以使用mpirun进行提交。对于安装了作业管理系统的,作业管理系统中融合了mpirun。可以直接通过bsub提交。
因此我们经常使用的指令如下:
mpicc main.c -o exe
bsub -q queue01 -n 10 ./exe