1、下载jdk压缩包以及Spark压缩包
以下是jdk1.8和spark3.0的压缩包,需要的可以下载
https://pan.baidu.com/s/1IiPscqdIgHvXOGR1FAFPAA
提取码:84U3
2、将两个压缩包一起上传至linux系统
这里我将它们上传至/opt/module/software中
3、安装JDK
参考文章
https://blog.csdn.net/qq_44838702/article/details/119521183
4、解压
解压spark-3.0.0-bin-hadoop3.2.tgz
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
打开module文件,将spark-3.0.0-bin-hadoop3.2重命名
mv spark-3.0.0-bin-hadoop3.2 spark-local
5、启动Local环境
进入解压缩之后的路径,执行如下命令
bin/spark-shell
启动成功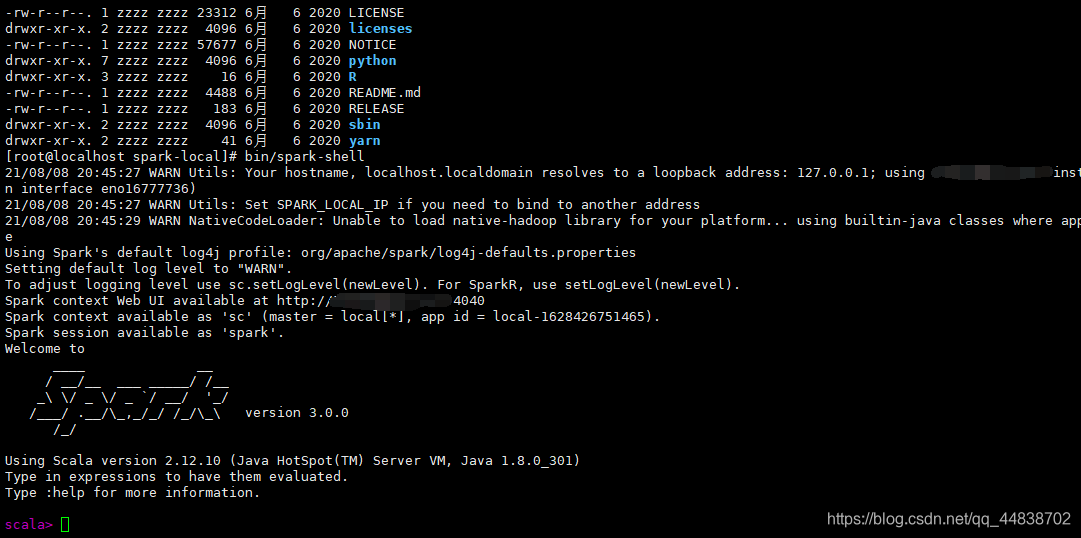
版权声明:本文为qq_44838702原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。